Kafka’s real complexity is not whether you can send or consume messages, but how you balance reliability, throughput, and scalability. This article focuses on three core mechanisms—Producer ACK settings, Consumer APIs, and replica assignment—to clarify difficult configuration choices, consumption models, and partition layout decisions. Keywords: Kafka, ACK, partition assignment.
Technical Specification Snapshot
| Parameter | Description |
|---|---|
| Core System | Apache Kafka |
| Primary Languages | Java / Scala |
| Communication Protocol | TCP, Kafka proprietary binary protocol |
| Article Focus | ACK mechanisms, Consumer APIs, partition replica assignment |
| GitHub Stars | Not provided in the source |
| Core Dependencies | Broker, Producer, Consumer, ISR, replica mechanism |
Kafka’s reliability and performance trade-offs begin with the ACK mechanism
How you define a successful Producer send directly determines message loss risk and end-to-end latency. Kafka exposes this choice explicitly through the acks parameter, so it is not just a syntax-level setting—it is a reliability strategy.
acks=0 maximizes throughput but gives up acknowledgments
When acks=0, the Producer does not wait for any response from the Broker after sending a message. The client immediately proceeds to the next batch, which minimizes blocking on the network path and usually delivers the highest throughput.
This mode fits monitoring events, non-critical logs, and replayable data. The downside is equally direct: if the network fluctuates or the Broker experiences a brief failure, messages may be lost without the application noticing.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "0"); // Do not wait for any acknowledgment; optimize for the lowest latency
props.put("retries", 0); // Commonly paired with a low-reliability strategyThis configuration demonstrates Kafka’s send strategy at the lowest acknowledgment level.
acks=1 is the default compromise
When acks=1, the Producer receives an acknowledgment as soon as the Leader partition writes the message successfully. This gives the system baseline reliability without waiting for all replicas to finish synchronization.
It works well for most general-purpose workloads, such as order events, activity streams, and asynchronous notifications. However, if the Leader fails immediately after the write and the Followers have not yet replicated the message, the message can still be lost.
acks=all is the preferred choice for high-reliability workloads
acks=-1 or acks=all means the Producer treats a send as successful only after the in-sync replicas in the ISR confirm the write. This is Kafka’s strongest reliability semantic on the production side.
The trade-off is higher write latency and a more noticeable drop in throughput. For scenarios such as finance, payments, and inventory deduction—where message loss is difficult to tolerate—you should prioritize this mode and combine it with idempotence and retry settings.
props.put("acks", "all"); // Wait for acknowledgment from the in-sync replicas in the ISR
props.put("retries", 3); // Automatically retry transient failures
props.put("enable.idempotence", true); // Enable idempotence to reduce duplicate-write riskThis configuration shows that high-reliability sending usually depends on more than ACK alone; it also requires idempotence working alongside it.
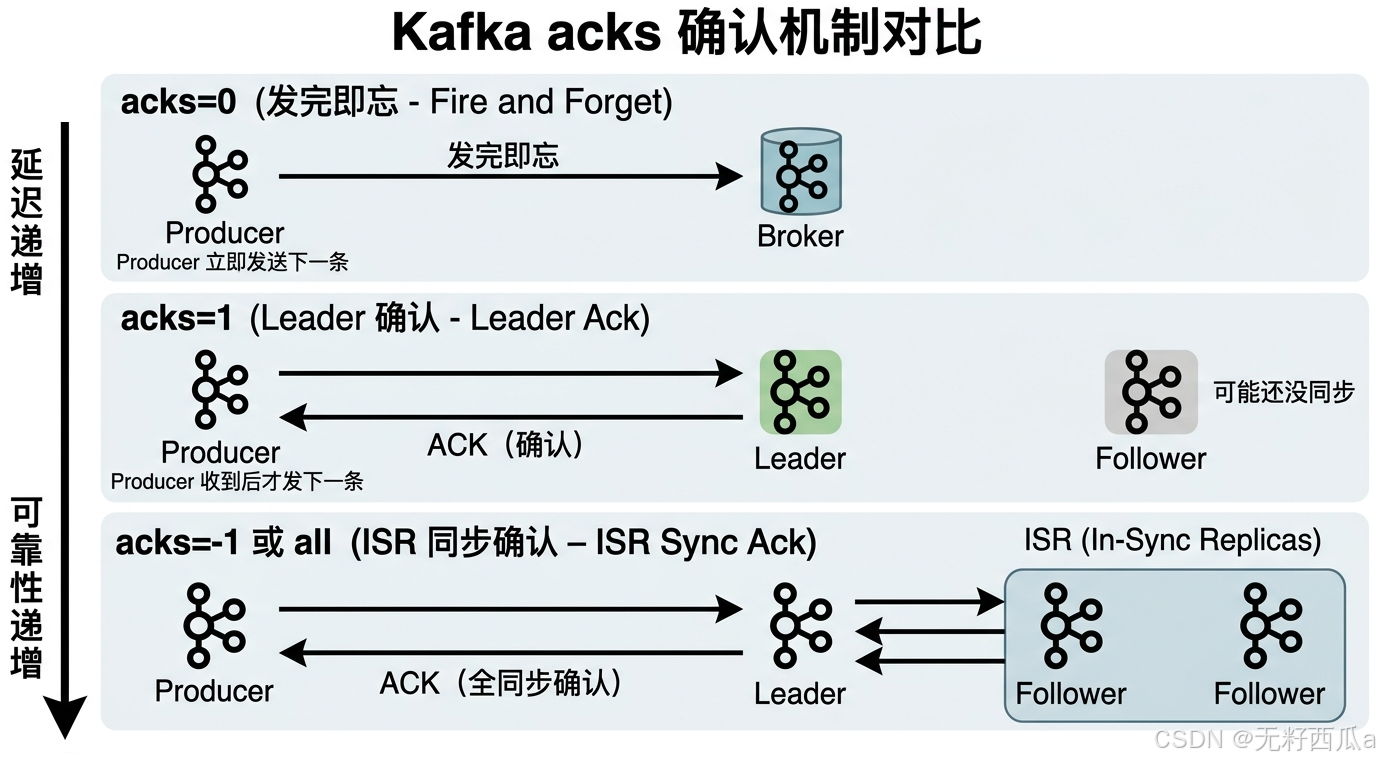 AI Visual Insight: This diagram visually compares the confirmation paths for
AI Visual Insight: This diagram visually compares the confirmation paths for acks=0, acks=1, and acks=all across the Producer, Leader, and Follower roles. It highlights the core trade-off: the broader the replica acknowledgment scope, the stronger the message durability and the higher the write latency.
Kafka’s Consumer API design reflects a trade-off between automation and control
Kafka historically provided both the High-level API and the Simple Consumer API. The difference is not just the level of abstraction. It is a choice between letting the framework manage state and letting the application manage state directly.
The Simple Consumer API provides the finest-grained control
The Simple API targets single-Broker connections. The client must maintain offsets, Broker metadata, exception recovery, and failover on its own. It hides almost none of the complexity, which is exactly why it offers the most flexibility.
When you need to target a specific Partition, rewind to a particular offset range, or build a custom consumption framework, this low-level capability becomes valuable. The cost is significantly higher development and operational overhead.
The High-level API is better suited to standard business consumption
The High-level API encapsulates cluster access, offset commits, and group coordination. Developers only need to focus on subscribing to topics and processing messages instead of managing large amounts of low-level state directly.
More importantly, it supports Consumer Groups, which gives Kafka both queue-style consumption and broadcast-style consumption. That capability is a common requirement in application architecture.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("order-topic")); // Subscribe to the topic; the framework handles partition assignment
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value()); // Process the fetched message
}
}This code shows how the high-level consumer API hides the details of partition discovery and state management.
Consumer Groups determine whether messages are consumed competitively or broadcast
Within the same group.id, multiple Consumers share the partitions of a Topic, and each message is processed by only one instance in the group. This is effectively a queue model and is ideal for horizontally scaling consumption capacity.
When Consumers with different group.id values subscribe to the same Topic, each group receives the full message stream independently. That is equivalent to a broadcast model and is useful when multiple downstream systems—such as auditing, risk control, and recommendation engines—must process the same event in parallel.
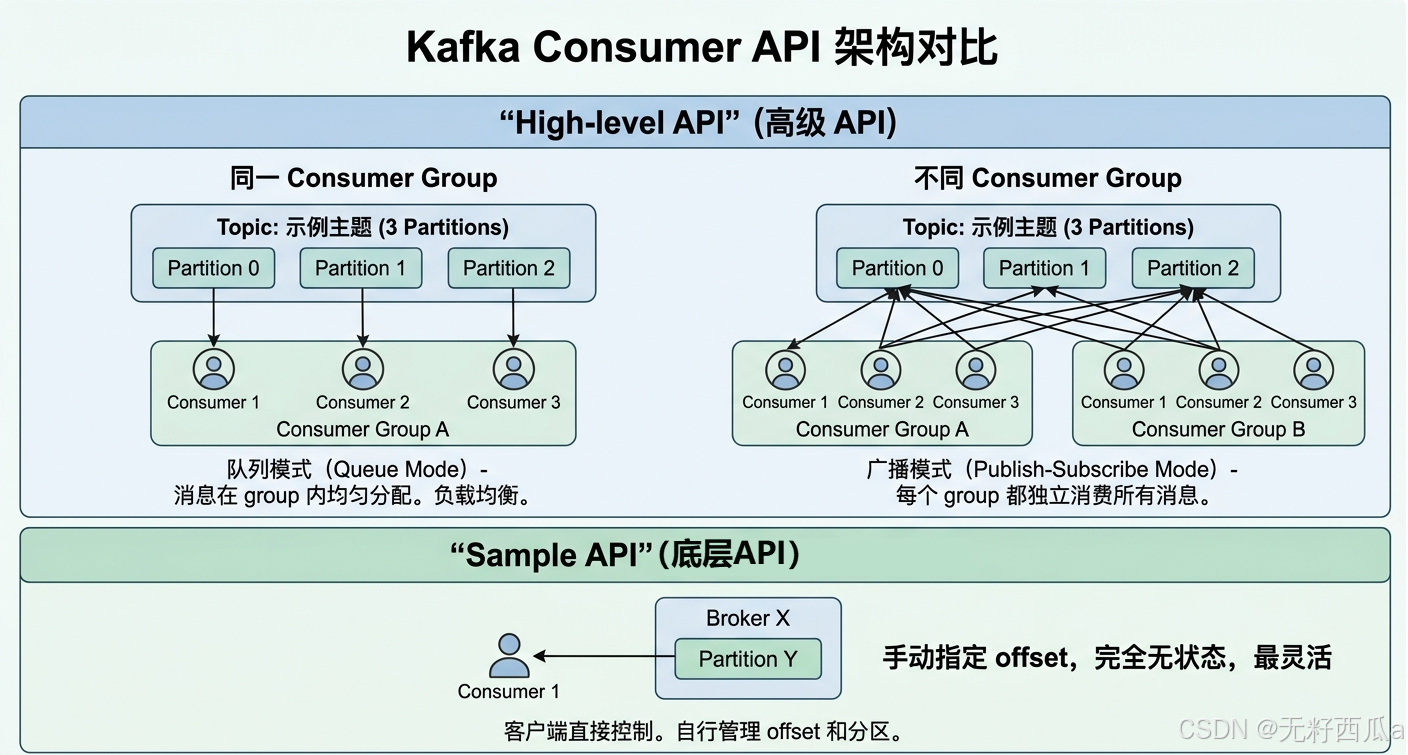 AI Visual Insight: This diagram shows the differences between the low-level consumer interface and the high-level consumer interface in connection scope, state management, and group coordination. It also emphasizes how Consumer Groups distribute Topic partitions evenly across consumers.
AI Visual Insight: This diagram shows the differences between the low-level consumer interface and the high-level consumer interface in connection scope, state management, and group coordination. It also emphasizes how Consumer Groups distribute Topic partitions evenly across consumers.
Topic replica assignment rules determine cluster balance and fault tolerance
When Kafka creates a Topic, it must distribute multiple replicas of each Partition across different Brokers. The goal is not randomness for its own sake, but balanced placement, avoidance of single points of failure, and reduced hot spots.
The replication factor is constrained first by the number of Brokers
The replication factor cannot exceed the total number of Brokers. This is the most basic physical limit. Otherwise, Kafka cannot place multiple replicas of the same partition on different nodes, and fault tolerance becomes impossible by definition.
A random starting point for the first replica spreads Topics more evenly
Kafka first chooses a random Broker for the first replica of the first partition. This prevents all Topics from always starting placement on the same fixed node and reduces long-term skew.
Subsequent partitions use a rotation strategy to achieve even distribution
The first replica of each remaining partition shifts forward from the previous position in sequence and wraps around at the end of the Broker list. This round-robin layout makes Leader replica distribution more balanced.
Broker: B1 B2 B3
Partition0: B2 B3 B1
Partition1: B3 B1 B2
Partition2: B1 B2 B3This example shows how a random starting point plus cyclic shifting spreads replicas evenly across three Brokers.
Remaining replicas are further dispersed through an offset-based strategy
Beyond the first replica, Kafka continues to spread the remaining replicas using an offset-based approach similar to nextReplicaShift. The goal is to avoid concentrating similar replicas on a small number of nodes while also ensuring that replicas of the same partition never overlap.
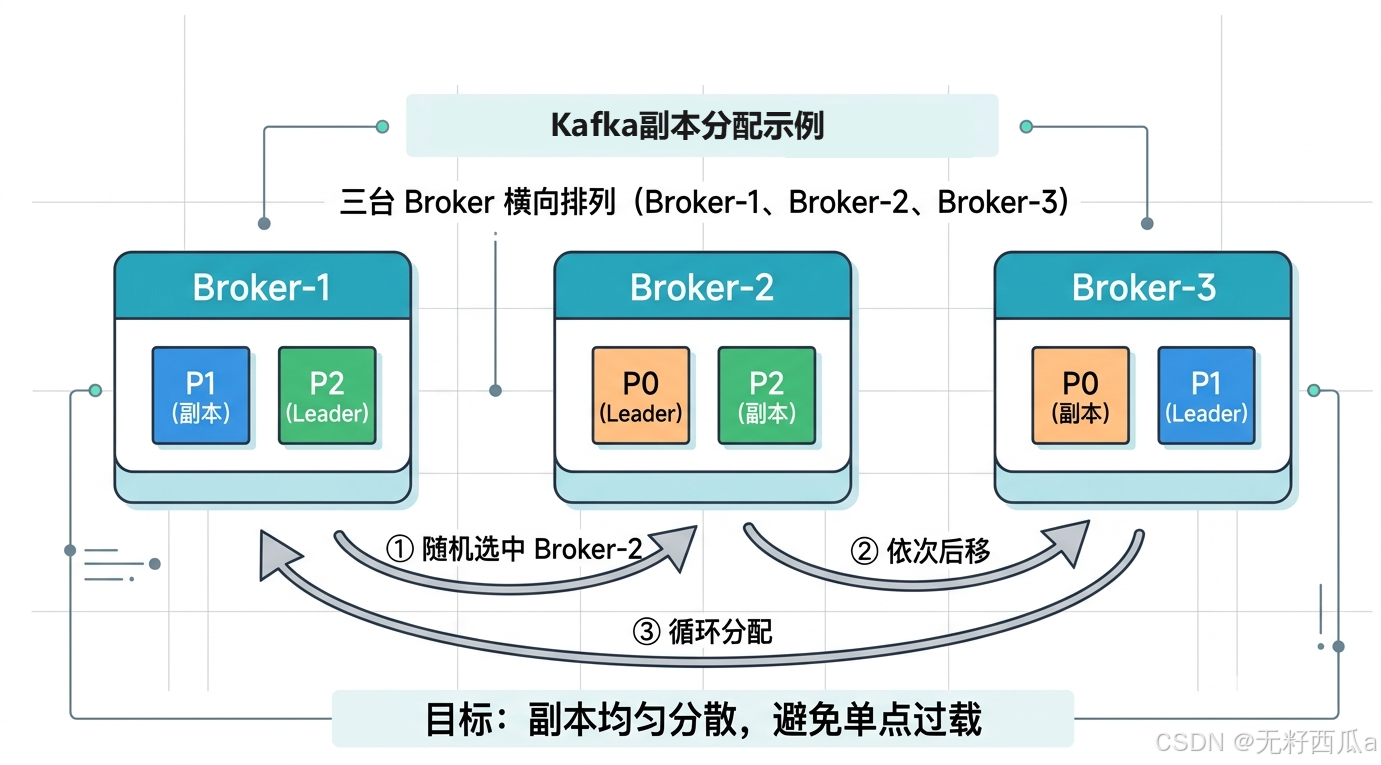 AI Visual Insight: This diagram shows how Leader replicas and Follower replicas for different partitions are interleaved across multiple Brokers after Topic creation. It illustrates how the combination of a random starting point, sequential shifting, and replica dispersion achieves both load balancing and fault isolation.
AI Visual Insight: This diagram shows how Leader replicas and Follower replicas for different partitions are interleaved across multiple Brokers after Topic creation. It illustrates how the combination of a random starting point, sequential shifting, and replica dispersion achieves both load balancing and fault isolation.
In practice, you should evaluate these three mechanisms together
If your workload emphasizes throughput, you can choose acks=1 or an even lower acknowledgment strategy and use the high-level API to build the consumption pipeline quickly. If your workload emphasizes strong reliability, you should use acks=all, set an appropriate replication factor, and maintain a well-distributed Broker layout.
From an architectural perspective, ACK determines how durable writes are, the Consumer API determines how easy consumption is to manage, and partition assignment rules determine how well the cluster withstands pressure. Only together do they define Kafka’s production-grade operating boundary.
FAQ
Does Kafka acks=all guarantee zero message loss?
No. It can only significantly reduce the probability of message loss. If replicas in the ISR fail at the same time, disks encounter issues, or errors occur in the client processing chain, data risk can still exist. That is why teams usually combine it with idempotence, retries, and application-level deduplication.
Why do most applications use the High-level API more often?
Because it hides complex details such as offset management, Broker discovery, and group coordination. It lowers development cost and covers the vast majority of subscription-based consumption scenarios, which makes it more suitable for production engineering.
Why does Kafka try to spread replicas across different Brokers?
The core purpose is to improve fault tolerance and load balancing. If multiple replicas of the same partition are concentrated on a single machine or a small subset of nodes, a node failure will significantly reduce that partition’s availability and recovery capability.
Core Summary: This article systematically breaks down Kafka’s three ACK modes, two consumer API models, and the placement rules for Topic partition replicas across Brokers, helping developers make clearer trade-offs among reliability, throughput, and operability.