[AI Readability Summary] This PyTorch-based hybrid movie recommendation project combines ContentBranch for content understanding with CFBranch for collaborative filtering representations. The goal is to improve similar-movie recommendations and mitigate cold-start issues. It addresses the weak generalization of pure content-based recommendation and the sparsity limitations of standalone collaborative filtering. Keywords: hybrid recommendation, PyTorch, movie recommendation.
Technical Specifications at a Glance
| Parameter | Description |
|---|---|
| Primary Language | Python 3.9 |
| Deep Learning Framework | PyTorch |
| Data Source | Kaggle TMDB Top 10000 Movies 2026 |
| Modeling Paradigm | Content-Based + Collaborative Filtering |
| Feature Processing | TF-IDF, TruncatedSVD, MultiLabelBinarizer, MinMaxScaler |
| Loss Function | MSE + Alignment Loss |
| Optimizer | AdamW |
| Learning Rate Scheduler | CosineAnnealingLR |
| License | CC 4.0 BY-SA (as stated in the original article) |
| GitHub Stars | Not provided in the source |
| Core Dependencies | torch, pandas, numpy, scikit-learn, matplotlib |
This project demonstrates a hybrid recommendation approach that is closer to real-world production practice
Built on TMDB movie data, this project implements a dual-branch recommendation model. The content branch learns from movie text, genres, and numerical features, while the collaborative branch learns implicit relational representations from movie IDs. A fusion layer then outputs a normalized score.
Compared with plain TF-IDF similarity retrieval, this design preserves content semantics while also introducing item-level embeddings. That makes it more valuable in engineering scenarios such as similar-movie retrieval, diversity control, and cold-start mitigation.
 AI Visual Insight: This image serves as the article’s thematic cover illustration, highlighting the intersection of recommendation systems and movie analysis. Visually, it typically represents the technical context of “content understanding + user preference modeling,” making it a suitable introductory graphic for a hybrid recommendation task.
AI Visual Insight: This image serves as the article’s thematic cover illustration, highlighting the intersection of recommendation systems and movie analysis. Visually, it typically represents the technical context of “content understanding + user preference modeling,” making it a suitable introductory graphic for a hybrid recommendation task.
The data layer first solves the problem of trainability
The raw dataset includes fields such as overview, genre_ids, vote_average, vote_count, popularity, and release_date. The author first removes records with missing critical fields, then structures category, year, and popularity information so that downstream feature engineering can proceed directly.
import pandas as pd
import ast
# Load the raw movie data
df = pd.read_csv("tmdb_top_10k_movies_2026.csv")
# Remove samples with missing critical fields to ensure valid training targets
df = df.dropna(subset=["overview", "title", "vote_average"]).reset_index(drop=True)
# Safely parse the genre list field to avoid failures caused by dirty data
def safe_parse(x):
try:
return ast.literal_eval(x) if isinstance(x, str) else []
except:
return []
# Extract structured genre and year features
df["genre_ids_parsed"] = df["genre_ids"].apply(safe_parse)
df["release_year"] = pd.to_datetime(df["release_date"], errors="coerce").dt.year.fillna(0).astype(int)This code cleans the raw movie table into a structured sample set that can be used for training.
Content feature engineering defines the upper bound of ContentBranch representations
This project encodes movie summaries, genre labels, and structured numerical features into a unified representation. For text, it uses TF-IDF with 1-2 grams, then reduces the result to 100 dimensions with TruncatedSVD to reduce high-dimensional sparse noise. Genres are encoded with multi-label binarization, while ratings, popularity, and year are normalized.
The resulting content_features matrix contains semantic, categorical, and statistical signals at the same time. Compared with using only titles or genre labels, this concatenated input is better suited for stable embedding learning in a deep network.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
from sklearn.preprocessing import MultiLabelBinarizer, MinMaxScaler
import numpy as np
# Vectorize text by extracting semantic patterns from movie overviews
vectorizer = TfidfVectorizer(max_features=5000, stop_words="english", ngram_range=(1, 2))
tfidf_matrix = vectorizer.fit_transform(df["overview"].fillna(""))
# Reduce sparse text features into a low-dimensional semantic space
svd = TruncatedSVD(n_components=100, random_state=42)
text_features = svd.fit_transform(tfidf_matrix)
# Multi-label encode genres
mlb = MultiLabelBinarizer()
genre_features = mlb.fit_transform(df["genre_ids_parsed"])
# Normalize numerical features
scaler = MinMaxScaler()
numeric_features = scaler.fit_transform(df[["vote_average", "vote_count", "popularity", "release_year"]])
# Concatenate the final content features
content_features = np.hstack([text_features, genre_features, numeric_features]).astype(np.float32)This code builds the input representation for content-side learning in the hybrid recommender.
 AI Visual Insight: This image likely shows dimensional statistics or processing results after feature engineering. It can help verify whether text, genre, and numerical features were concatenated as expected, and it also reflects the transformation from sparse inputs to lower-dimensional representations.
AI Visual Insight: This image likely shows dimensional statistics or processing results after feature engineering. It can help verify whether text, genre, and numerical features were concatenated as expected, and it also reflects the transformation from sparse inputs to lower-dimensional representations.
The implicit rating target teaches the model both similarity and quality signals
The project does not have a real user-item interaction matrix, so it constructs an implicit target:
implicit_score = vote_average × log1p(vote_count)
This target is important because it prevents the model from overemphasizing high-rated movies with very few votes, while also avoiding the opposite problem of favoring popularity alone at the expense of quality.
The normalized target is then used as a regression objective so that the model learns overall movie attractiveness. This is a weakly supervised recommendation strategy that works well when user behavior data is unavailable but ranking capability is still required.
The dual-branch architecture is the most important design in this article
ContentBranch uses a multi-layer fully connected network to compress content features into a low-dimensional embedding. CFBranch uses nn.Embedding to learn a dedicated vector for each movie. HybridRecommender concatenates the two outputs and passes them through a fusion head to produce the final score.
More importantly, the author adds an alignment loss to align the directions of the content embeddings and collaborative embeddings. This reduces the risk of the two branches learning disconnected representation spaces and improves consistency in the shared semantic space.
import torch
import torch.nn as nn
import torch.nn.functional as F
class ContentBranch(nn.Module):
def __init__(self, input_dim, embed_dim=64):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, 256),
nn.GELU(),
nn.Linear(256, 128),
nn.GELU(),
nn.Linear(128, embed_dim)
)
def forward(self, x):
return self.encoder(x) # Output the content embedding
class CFBranch(nn.Module):
def __init__(self, n_movies, embed_dim=64):
super().__init__()
self.item_emb = nn.Embedding(n_movies, embed_dim)
def forward(self, ids):
return self.item_emb(ids) # Output the collaborative filtering embedding
class HybridRecommender(nn.Module):
def __init__(self, content_dim, n_movies, embed_dim=64):
super().__init__()
self.content_branch = ContentBranch(content_dim, embed_dim)
self.cf_branch = CFBranch(n_movies, embed_dim)
self.fusion = nn.Sequential(
nn.Linear(embed_dim * 2, 64),
nn.GELU(),
nn.Linear(64, 1),
nn.Sigmoid()
)
def forward(self, content_vec, movie_ids):
ce = self.content_branch(content_vec) # Content branch output
cfe = self.cf_branch(movie_ids) # Collaborative branch output
score = self.fusion(torch.cat([ce, cfe], dim=1)).squeeze(1)
return score, ce, cfeThis code defines a hybrid recommendation model composed of a content branch, a collaborative branch, and a fused prediction head.
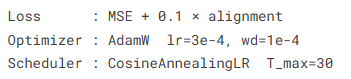 AI Visual Insight: This figure most likely shows the model architecture, training outputs, or parameter statistics. Its main value is to illustrate the relationship between the dual-branch network and the fusion layer, making it easier to verify whether the hierarchical design of ContentBranch, CFBranch, and the final scoring head matches expectations.
AI Visual Insight: This figure most likely shows the model architecture, training outputs, or parameter statistics. Its main value is to illustrate the relationship between the dual-branch network and the fusion layer, making it easier to verify whether the hierarchical design of ContentBranch, CFBranch, and the final scoring head matches expectations.
The training strategy reflects an engineering preference for stable convergence
During training, the model uses MSE as the primary loss and alignment loss as a regularization term, together with AdamW, cosine annealing, and gradient clipping. This combination provides a more stable optimization path for embedding learning tasks.
Based on the training curves described in the source article, both training loss and validation loss decrease steadily, and the alignment loss converges as well. This suggests that the two branches reach a good balance between predictive performance and semantic consistency.
# Primary loss: mean squared error between predicted scores and target scores
mse_loss = nn.MSELoss()
def alignment_loss(ce, cfe):
# L2-normalize both branch vectors, then compute cosine distance
ce = F.normalize(ce, p=2, dim=1)
cfe = F.normalize(cfe, p=2, dim=1)
return (1 - (ce * cfe).sum(dim=1)).mean()
def hybrid_loss(pred, target, ce, cfe, alpha=0.1):
main = mse_loss(pred, target) # Prediction error
align = alignment_loss(ce, cfe) # Cross-branch alignment error
return main + alpha * alignThis code shows that the model jointly optimizes score fitting and representation consistency across the two branches.
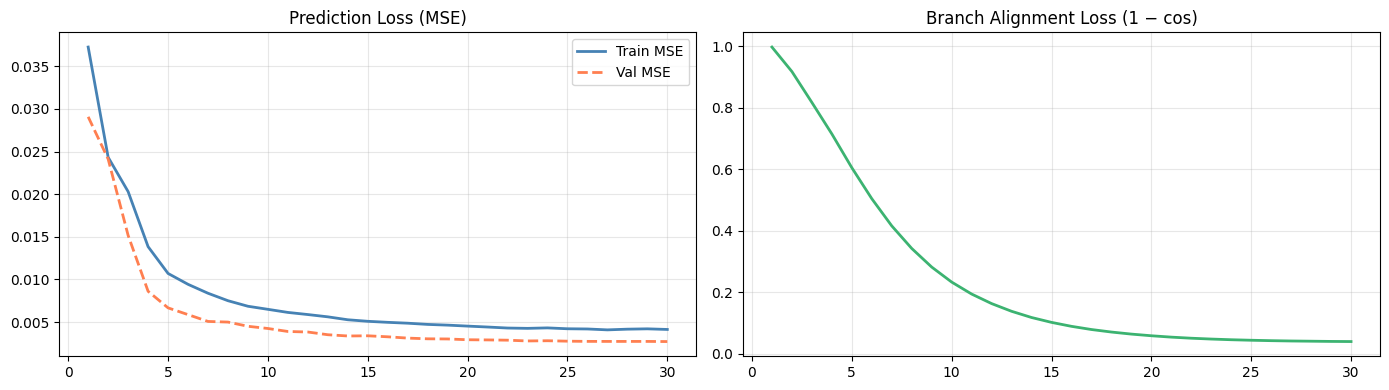 AI Visual Insight: This image is likely a training-versus-validation loss plot or an alignment loss curve. It helps assess whether the model converges, whether overfitting appears, and whether the alignment mechanism continuously reduces embedding discrepancies between the two branches.
AI Visual Insight: This image is likely a training-versus-validation loss plot or an alignment loss curve. It helps assess whether the model converges, whether overfitting appears, and whether the alignment mechanism continuously reduces embedding discrepancies between the two branches.
The inference stage is where the value of hybrid representations becomes clear
During inference, the author separately extracts content_embs, cf_embs, and hybrid_embs, and then performs Top-K recommendation using vector similarity. This makes it possible to compare the recommendation differences across all three modes and verify whether the fused representation outperforms either single branch alone.
In the example, the hybrid mode usually balances semantic relevance and genre consistency better than using either content or collaborative filtering in isolation. For recommender systems, that means the results are less homogeneous than pure content-based recommendation and more interpretable than pure ID embeddings.
 AI Visual Insight: This figure shows a recommendation results table or similarity outputs under different modes. By comparing retrieval behavior across content, collaborative, and hybrid embeddings, it helps verify whether the hybrid representation produces more stable similar-movie ranking.
AI Visual Insight: This figure shows a recommendation results table or similarity outputs under different modes. By comparing retrieval behavior across content, collaborative, and hybrid embeddings, it helps verify whether the hybrid representation produces more stable similar-movie ranking.
The scope and limitations of this approach should also be made explicit
Its strengths are simplicity, interpretability, and suitability for weakly supervised scenarios or datasets without user behavior logs. However, it is not a full industrial recommender system, because it does not include an explicit user tower, sequential behavior modeling, or a recall-ranking-re-ranking pipeline.
To extend it further, you could introduce user embeddings, click logs, BPR or pairwise loss, multi-task learning, or replace the text encoder with a BERT-style model to improve long-text understanding.
FAQ
1. Why can this model mitigate the cold-start problem?
Because ContentBranch directly models movie summaries, genres, and statistical metadata. Even if a new movie has little or no interaction data, the model can still generate a usable embedding as long as its content fields are complete.
2. What problem does alignment loss solve here?
It encourages the content branch and collaborative branch to learn representations with more consistent directions, reducing fragmentation between the two subspaces. As a result, the fused embedding is usually more stable and better suited for similarity retrieval.
3. Is this project ready for direct production deployment?
It is better suited as a prototype or an educational implementation. For production use, you should add user-side features, online feature serving, a retrieval pipeline, A/B testing, and real-time feedback mechanisms.
Core Summary: This article reconstructs and explains a PyTorch-based hybrid movie recommendation system that combines content feature modeling with collaborative filtering embeddings. By introducing alignment loss to improve representation consistency, it is well suited for movie recommendation, cold-start mitigation, and similar-content retrieval scenarios.