This article walks through the full path from LLM fundamentals to production engineering. It focuses on prompt engineering, native model integration, embedding models and RAG, and the orchestration value of LangChain. It addresses common developer pain points around context limits, private knowledge integration, and complex task decomposition. Keywords: LLM, RAG, LangChain
Technical Specifications at a Glance
| Item | Details |
|---|---|
| Primary Languages | Python, Bash |
| Integration Protocols | HTTP/REST, SDK, Local API |
| Article Popularity | Approximately 2.5k views, 81 likes, 82 saves |
| Core Dependencies | openai, curl, Ollama, LangChain |
 AI Visual Insight: This image serves as the article cover and emphasizes the end-to-end workflow of LLM application development. It is typically used to establish a learning path from fundamentals to practice rather than to depict a specific system architecture.
AI Visual Insight: This image serves as the article cover and emphasizes the end-to-end workflow of LLM application development. It is typically used to establish a learning path from fundamentals to practice rather than to depict a specific system architecture.
Building LLM Applications Requires More Than a Single API Call
Large language models have moved beyond demo-stage capabilities and into engineering reality. The real challenge developers face is not whether a model can answer, but whether its answers are stable, controllable, and traceable.
Raw LLM interfaces are powerful, but they also come with four built-in limitations: limited context windows, no access to private knowledge, difficulty decomposing complex tasks, and unstable output formats. This is exactly why application frameworks and RAG emerged.
The Essential Difference Between Traditional Models and LLMs Defines Their Capability Boundaries
Traditional models are usually trained for a single task, such as classification, prediction, or detection. They rely on explicitly labeled data, use smaller parameter sizes, and generalize across a limited range of scenarios.
LLMs, by contrast, are general-purpose language models trained on massive neural networks. Their core task is to predict the next token based on context. Scaling up model size gives them stronger knowledge compression and better task transfer ability.
 AI Visual Insight: This image is used as an entry point for comparing traditional models with large language models. It typically uses a flow or structural diagram to show differences in input scope, task generality, and training scale.
AI Visual Insight: This image is used as an entry point for comparing traditional models with large language models. It typically uses a flow or structural diagram to show differences in input scope, task generality, and training scale.
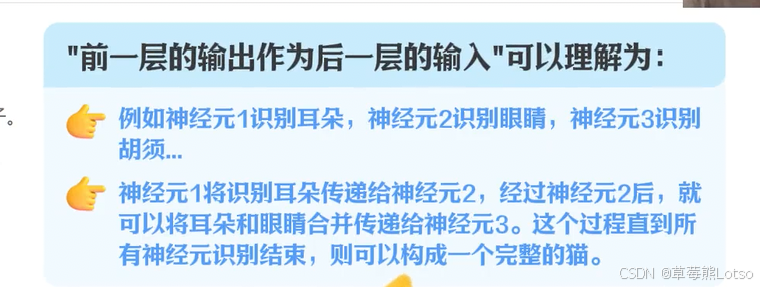 AI Visual Insight: This image focuses on neural network structure and may show multi-layer node connections, weight propagation, and feature extraction. It helps explain why parameter scale determines model expressiveness.
AI Visual Insight: This image focuses on neural network structure and may show multi-layer node connections, weight propagation, and feature extraction. It helps explain why parameter scale determines model expressiveness.
Self-Supervised Learning Gives LLMs General Language Ability
The key to LLMs is not just that they are large, but that their training method changed. Self-supervised learning does not depend on manual item-by-item labeling. Instead, it uses massive text corpora for fill-in-the-blank-style training, allowing the model to learn patterns directly from context.
This means a model can absorb grammar, semantics, knowledge relationships, and expression patterns from public corpora. As a result, it adapts well across question answering, summarization, translation, and code generation tasks.
# Use pseudocode to illustrate the basic training objective of an LLM
text = "LangChain helps developers build LLM apps"
tokens = tokenize(text) # Split text into tokens
input_tokens = tokens[:-1] # Use the preceding context as input
label = tokens[-1] # Use the last token as the prediction target
loss = model.predict(input_tokens, label) # Core logic: predict the next token from prior contextThis code shows the minimal training objective of a language model: predict the next token from context.
Prompt Engineering Directly Determines Output Quality
In most applications, the prompt is not a supplementary detail. It is the control layer. Clear roles, goals, steps, constraints, and output formats significantly reduce the chance of model drift.
CO-STAR is a highly practical structured prompting framework: Context, Objective, Steps, Tone, Audience, Response. It works well for customer support, analysis, writing, and structured extraction.
Few-Shot Prompting and Chain-of-Thought Improve Stability for Complex Tasks
Few-shot prompting uses one to three examples to help the model learn the required format faster. Chain-of-thought prompting guides the model to reason before answering, which is useful for math, logic, and multi-step decisions.
prompt = """
You are a data analysis assistant.
Task: Extract the product, sentiment, and issue from customer feedback.
Example:
Feedback: Battery life is far too short.
Output: product=battery; sentiment=negative; issue=insufficient battery life
Feedback: The left earbud stopped producing sound after one week.
Please analyze step by step and then provide a structured result.
"""
print(prompt) # Core logic: constrain output format with examples and reasoning stepsThis code shows how to combine example-based constraints and step-by-step reasoning in a single prompt.
 AI Visual Insight: This image is used to demonstrate the effect of chain-of-thought prompting. It typically presents the layered relationship among the question, reasoning process, and final answer, highlighting the accuracy gains of thinking before responding.
AI Visual Insight: This image is used to demonstrate the effect of chain-of-thought prompting. It typically presents the layered relationship among the question, reasoning process, and final answer, highlighting the accuracy gains of thinking before responding.
Native Integration Methods Define Deployment Cost and Control
There are currently three mainstream integration paths: cloud APIs, official SDKs, and local deployment. Each involves trade-offs in usability, privacy, latency, and maintenance cost.
API calls are the best fit for fast integration. SDKs further encapsulate authentication, serialization, and response parsing. Local deployment fits scenarios that require strong privacy, offline availability, and predictable cost. A typical option is Ollama.
Cloud APIs Are Best for the Fastest Business Validation
curl "https://api.openai.com/v1/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"input": "Explain RAG in one sentence"
}'This command demonstrates the smallest viable cloud-based model invocation.
SDKs Make Code Easier to Maintain and Encapsulate
from openai import OpenAI
client = OpenAI(api_key="your-api-key") # Initialize the client
response = client.responses.create(
model="gpt-5",
input="Introduce the role of LangChain" # Core logic: submit the user task directly
)
print(response.output_text) # Extract the model's text outputThis code shows the advantage of an SDK in abstracting away low-level HTTP details.
Local Deployment Solves Privacy and Offline Availability Requirements
ollama run deepseek-r1:1.5b # Pull and run a local model, suitable for getting started and testingThis command starts an open-source model locally and represents the shortest path to private deployment.
 AI Visual Insight: This image centers on the Ollama deployment interface or workflow. It typically shows model download, startup, terminal interaction, and local service exposure, illustrating a lightweight entry point for local inference.
AI Visual Insight: This image centers on the Ollama deployment interface or workflow. It typically shows model download, startup, terminal interaction, and local service exposure, illustrating a lightweight entry point for local inference.
Embedding Models Are the Infrastructure Behind RAG and Semantic Search
LLMs generate text. Embedding models represent text. The latter encode text into high-dimensional vectors so that semantic similarity becomes mathematically computable.
This step does not solve a writing problem. It solves a retrieval problem. Only after finding the most relevant private document chunks for a user’s question does the model have a chance to produce a trustworthy answer.
The Core RAG Workflow Is Retrieve First, Then Generate
RAG usually includes seven steps: document loading, chunking, vectorization, storage, retrieval, reranking, and generation. Enterprise knowledge base QA, document assistants, and internal support systems all depend on this pipeline.
query = "What is the new paid parental leave policy introduced this year?"
chunks = ["Employees are granted 5 additional days of paid parental leave", "The reimbursement policy has been adjusted to an annual cap"]
# Core logic: simulate semantic retrieval of the most relevant chunk
matched_context = chunks[0]
answer_prompt = f"Answer based on the following material: {matched_context}. Question: {query}"
print(answer_prompt)This code demonstrates the key RAG action of injecting retrieved results into the generation prompt.
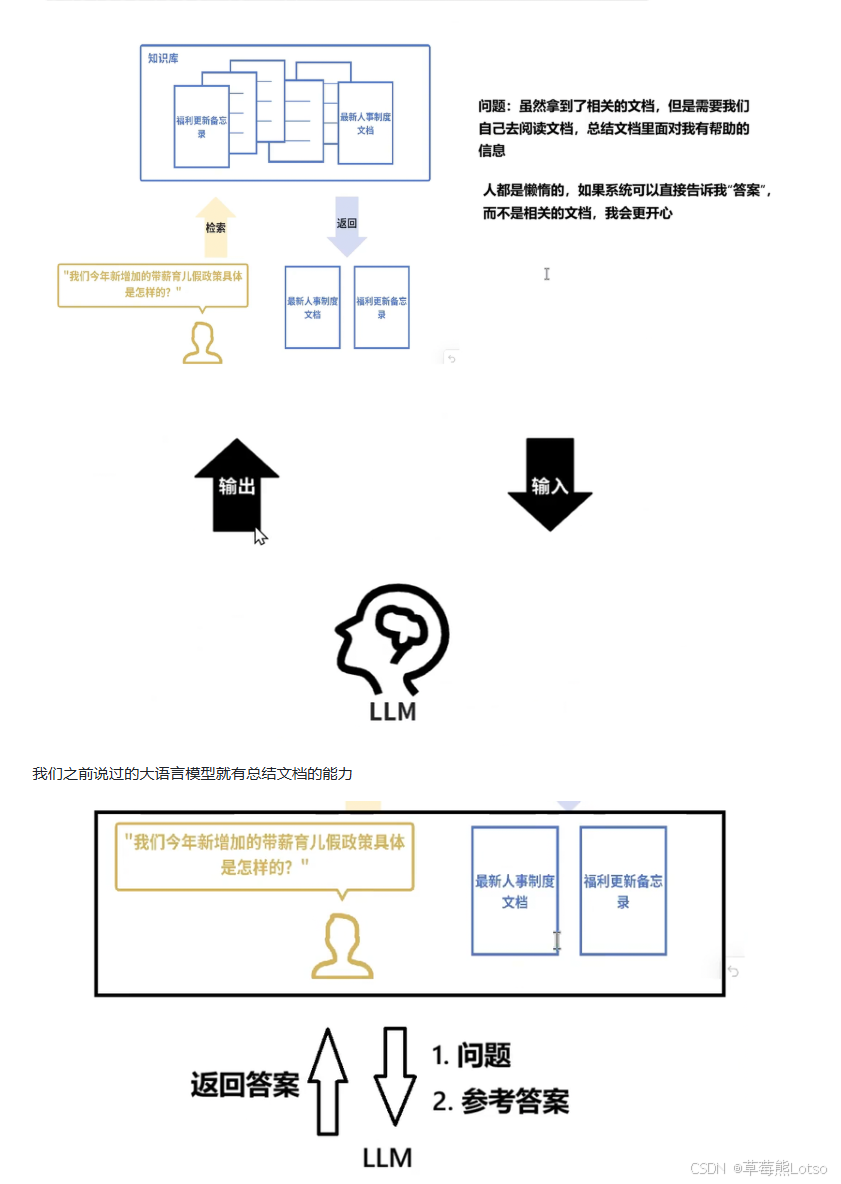 AI Visual Insight: This image typically presents the RAG data flow, including the user question, vector retrieval, knowledge chunk recall, and LLM answer generation. It is a key structural diagram for understanding enterprise-grade question answering systems.
AI Visual Insight: This image typically presents the RAG data flow, including the user question, vector retrieval, knowledge chunk recall, and LLM answer generation. It is a key structural diagram for understanding enterprise-grade question answering systems.
LangChain Turns Disconnected Capabilities Into a System
If a native LLM is the engine, LangChain is more like the transmission system. It does not replace the model. Instead, it organizes models, prompts, retrievers, tools, memory, and output parsers into reusable applications.
Its core value appears in four areas: unified interface abstraction, modular RAG components, agent task orchestration, and structured output control. This is especially important for multi-model switching and complex business workflows.
LangChain Is Well Suited to Real Tasks That Require Workflow Orchestration
Consider a multi-stage workflow such as reading a PDF, splitting text, performing vector retrieval, generating a summary, and outputting JSON. If you handwrite this directly with native code, maintenance cost rises quickly.
LangChain decomposes these steps into standardized components, allowing developers to focus more on business rules and less on repeated model adaptation, state passing, and parsing logic.
# Pseudocode: illustrate the chain-style invocation pattern used by LangChain
question = "Summarize the employee parental leave policy"
context = "Employees are granted 5 additional days of paid parental leave"
result = {
"question": question,
"context": context,
"summary": "The company added 5 days of paid parental leave" # Core logic: structured output is easier for downstream systems to consume
}
print(result)This code explains why structured output is a critical capability for production AI applications.
 AI Visual Insight: This image should show how LangChain connects models, vector databases, tools, and the application layer, highlighting its architectural role as an orchestration layer in the middle.
AI Visual Insight: This image should show how LangChain connects models, vector databases, tools, and the application layer, highlighting its architectural role as an orchestration layer in the middle.
The Development Focus Has Shifted From Model Capability to System Capability
In modern LLM development, the deciding factor is not whether you integrated an LLM. It is whether you built a stable, trustworthy, and low-maintenance application pipeline. Understanding fundamentals sets the upper bound; engineering abstraction determines delivery efficiency.
For developers, the recommended learning path is to first understand the division of labor between LLMs and embeddings, then master prompts and RAG, and finally move into orchestration practice with LangChain or similar frameworks.
FAQ
Why can’t prompt engineering alone solve enterprise knowledge QA?
Because prompts cannot invent private knowledge that falls outside the model’s training cutoff. Enterprise documents, policies, and product data must first be retrieved and then injected into context. That is why RAG is necessary.
How should I choose between local deployment and a cloud API?
If you prioritize development speed and access to high-performance models, start with a cloud API. If you prioritize data privacy, offline availability, and cost control, choose local deployment. Most teams eventually adopt a hybrid architecture.
Is LangChain the same thing as RAG?
No. RAG is an application pattern, while LangChain is an engineering framework. LangChain can implement RAG, but it also supports broader capabilities such as agents, tool calling, memory management, and structured output.
Core Summary: This article reconstructs the LLM application development workflow from a developer’s perspective. It covers large language model fundamentals, prompt engineering, API/SDK/local deployment, embedding models and RAG, and explains how LangChain addresses context limits, private knowledge access, and task orchestration.