This article focuses on an efficient preparation path for the 2026 Huazhong Cup Mathematical Modeling Challenge. It systematically breaks down the modeling patterns, algorithm stacks, paper delivery requirements, and 96-hour collaboration rhythm for A/B/C problems to address the core pain points of slow topic selection, fragmented modeling, weak results, and rushed writing. Keywords: Huazhong Cup, mathematical modeling, A/B/C problems.
The technical specification snapshot provides a quick overview
| Parameter | Details |
|---|---|
| Domain | College mathematical modeling competitions |
| Primary Languages | Python, MATLAB |
| Common Submission Formats | PDF paper submission, code package submission, result table submission |
| Competition Duration | 96 hours of continuous work |
| Typical Problem Types | Problem A: mechanistic modeling, Problem B: operations optimization, Problem C: data mining |
| Core Dependencies | Pandas, Scikit-learn, Matplotlib, Seaborn, Gurobi, CPLEX, FEniCS |
| Resource Types | Papers, source code, result tables, visualization charts |
| Star Count | Not provided in the source material |
The competition is fundamentally a high-intensity technical delivery process
The Huazhong Cup is not just about solving a problem. It is a complete, time-constrained engineering process that includes problem abstraction, model solving, experimental validation, and technical writing. The main challenge lies not only in algorithmic depth, but in whether the team can quickly align on a unified technical direction.
From the distribution of problem types, Problem A focuses on continuous systems and mechanistic analysis, Problem B emphasizes discrete optimization and scheduling, and Problem C is centered on data-driven modeling and forecasting. Without predefined templates, many teams spend the first 12 hours wavering between directions, which directly compresses the time available for solving and writing.
Inputs and deliverables should be templated in advance
A mature team should prepare four default outputs: a PDF paper, runnable code, result tables, and interpretable visualizations. What truly separates strong teams is not whether they know a specific algorithm, but whether they can advance the model, experiments, and paper in parallel.
from pathlib import Path
# Core logic: prebuild the competition directory to avoid file chaos during the contest
base = Path("huazhong_cup_project")
folders = ["data", "src", "figures", "paper", "results"]
for name in folders:
(base / name).mkdir(parents=True, exist_ok=True) # Create a standardized directory structure
print("Project structure initialized")This code quickly creates a standard competition project skeleton and reduces collaboration friction during the event.
A/B/C problem types require three completely different methodologies
Problem A usually requires mechanistic modeling first, then numerical stability
Problem A often appears in physics, engineering, heat transfer, flow, or dynamical systems scenarios. The key is not to pile up complicated formulas, but to first identify control variables, boundary conditions, and reasonable assumptions, then decide whether to use ordinary differential equations, partial differential equations, or an approximate discrete model.
If the problem includes continuous spatial variation, finite difference methods, finite element methods, and Runge-Kutta methods are common choices. Scoring for this type of problem usually emphasizes modeling assumptions, parameter interpretation, and error analysis rather than simply obtaining a numerical answer.
Problem B is essentially a contest of constraint modeling and solver capability
Problem B often involves scheduling, transportation, routing, and resource allocation, making it naturally close to NP-hard problems. A recommended workflow is to translate business language into decision variables, objective functions, and constraint sets, then decide whether to use MILP, heuristics, or a hybrid strategy.
If the problem size is manageable, prioritize Gurobi or CPLEX for exact solutions. If the search space is too large, use heuristic methods such as genetic algorithms, simulated annealing, or particle swarm optimization to improve efficiency. The most common mistake here is missing constraints, which can make the result look strong while remaining impossible to execute.
import pulp
# Core logic: build a linear programming example that minimizes scheduling cost
model = pulp.LpProblem("schedule", pulp.LpMinimize)
x = pulp.LpVariable.dicts("x", [1, 2, 3], lowBound=0, cat="Integer")
model += 2*x[1] + 3*x[2] + 4*x[3] # Objective function: minimize total cost
model += x[1] + x[2] + x[3] >= 10 # Demand constraint: total workload must be at least 10
model.solve()
print({k: v.value() for k, v in x.items()})This code illustrates the standard Problem B modeling skeleton of variables, objective, and constraints.
Problem C depends more on data quality than on model names
Problem C usually attracts the largest number of participants, but the true performance ceiling is often determined not by how advanced the model sounds, but by data cleaning, feature engineering, and validation strategy. Many teams jump straight to XGBoost or LSTM while ignoring outliers, missing values, and time leakage.
A high-quality workflow usually looks like this: define the prediction or classification target, complete a data audit, build statistical and business features, then perform cross-validation and error interpretation. If you also add SHAP, feature importance analysis, or residual analysis, the paper becomes much more convincing.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
# Core logic: read the data and complete a basic modeling workflow
file_path = "data/train.csv"
df = pd.read_csv(file_path)
df = df.dropna() # Clean missing values to ensure stable training
X = df.drop(columns=["target"])
y = df["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train) # Train the model
print("Model training completed")This code reflects the basic data pipeline for Problem C: clean, split, and train.
Teams must adopt a phased execution strategy within 96 hours
A practical approach is to divide the competition into four stages. Use the first 6 hours for problem selection, problem decomposition, and risk assessment. Within 24 hours, build the baseline model and complete the first round of results. Between hours 48 and 72, focus on algorithm optimization, additional visualizations, and paper revisions. Reserve the final 12 hours only for finalization and formatting checks.
If the team still has not locked in its main model by hour 36, it becomes very difficult to ensure paper quality. Strong teams typically assign one person to lead the modeling direction, one person to maintain code and data, and one person to write the paper in parallel, instead of relying on the high-risk approach of consolidating everything at the end.
The dynamic programming tool shown in the image reflects a task-splitting mindset
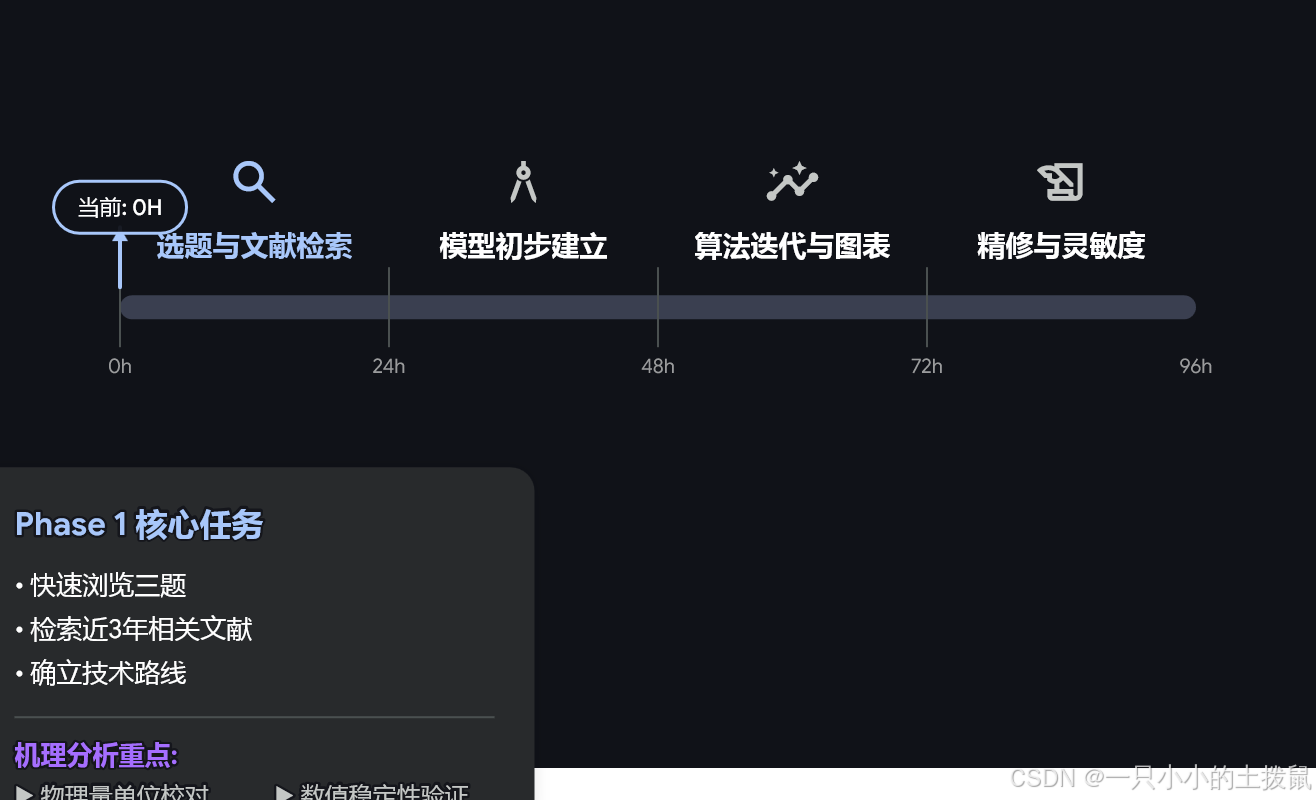 AI Visual Insight: This image shows a preparation path planning interface. Its core value is not a specific algorithm formula, but a way to map topic preference, time resources, and method cost into executable branches. It is useful early in the competition when deciding the priority of A/B/C problems and splitting modeling, programming, and writing into parallel task streams to reduce losses caused by serial team dependencies.
AI Visual Insight: This image shows a preparation path planning interface. Its core value is not a specific algorithm formula, but a way to map topic preference, time resources, and method cost into executable branches. It is useful early in the competition when deciding the priority of A/B/C problems and splitting modeling, programming, and writing into parallel task streams to reduce losses caused by serial team dependencies.
Treating the preparation workflow as a dynamic programming problem is highly valuable. Choices made at each stage affect the remaining available time and the future solution space. For example, if the early mechanistic assumptions for Problem A are unstable, the later numerical solution may collapse entirely. If feature engineering for Problem C starts too late, the return on hyperparameter tuning also drops.
Paper quality determines whether the model’s value becomes visible
High-scoring papers usually follow a stable structure: problem restatement, assumptions, notation, model development, solution process, error analysis, sensitivity analysis, strengths and limitations, and generalization. Among these sections, the abstract and conclusion most strongly shape the judges’ first impression, so they must present clear conclusions, concrete metrics, and reproducible contributions.
Each figure in the paper should serve an argumentative purpose rather than a decorative one. Convergence curves should demonstrate convergence behavior, heatmaps should explain correlations, and error comparison charts should support claims of model superiority. If an image does not contribute to the analysis, it is better to omit it.
The update timeline reflects the standard production pipeline for competition materials
The original material mentions milestones such as 6-hour topic selection guidance, 24-hour baseline formulas, 48-72 hour core algorithms, and an 84-hour final draft check. In essence, this is a content production pipeline for competition deliverables. The same rhythm also works well for individual preparation, especially when practicing with reusable templates in advance.
 AI Visual Insight: This image is more oriented toward team or community promotion. It contains branding and operational information rather than direct modeling details, so it should not be treated as technical evidence.
AI Visual Insight: This image is more oriented toward team or community promotion. It contains branding and operational information rather than direct modeling details, so it should not be treated as technical evidence.
The FAQ section answers the most common competition questions
Q1: How should teams quickly choose among Huazhong Cup Problems A/B/C?
A: Start by checking the data form and the complexity of constraints. Choose A if the problem clearly involves continuous mechanisms, choose B if it has many constraints and a well-defined objective, and choose C if it provides anonymized data for prediction or analytical tasks. Prioritize the track where your team already has code and workflow experience.
Q2: What most commonly causes a team to collapse during the competition?
A: It is usually not a lack of algorithms, but a failure to establish a unified direction in the first 12 hours. Typical issues include hesitation in problem selection, inconsistent variable definitions, disconnects between code and paper, and mismatches between result tables and conclusions.
Q3: How can a paper earn stronger evaluations?
A: Make sure the abstract includes the four essentials: problem, method, results, and contribution. The main body should include error analysis and sensitivity analysis. Figures and tables must support the argument. Conclusions should be quantified and should avoid vague statements such as “the effect is good.”
[AI Readability Summary]
This article reconstructs the original Huazhong Cup mathematical modeling material and focuses on the modeling paradigms, algorithm selection, code organization, and 96-hour collaboration rhythm for Problems A, B, and C. It also adds guidance on paper production, a dynamic-programming-style preparation path, and a developer-focused FAQ, making it suitable for teams that want to quickly build an executable competition strategy.