FlashAttention uses IO-aware tiled computation to keep the core attention operations on on-chip SRAM as much as possible, avoiding repeated writes of the N×N attention matrix to HBM. The result is significantly higher speed and lower memory usage. It addresses the bandwidth bottleneck in long-sequence training. Keywords: FlashAttention, IO-Aware, Online Softmax.
Technical snapshot
| Parameter | Details |
|---|---|
| Core topic | Exact attention optimization with FlashAttention |
| Primary languages | Python, CUDA, PyTorch |
| Key protocols/interfaces | Scaled Dot-Product Attention, PyTorch SDPA |
| Typical hardware | NVIDIA A100 / H100 |
| GitHub stars | Not provided in the source input; refer to the flash-attn repository |
| Core dependencies | torch, flash-attn, CUDA |
FlashAttention delivers value by moving less data, not by doing less math
The standard attention formula is not the problem. The issue is the execution path. QK^T first produces an N×N score matrix, then applies softmax, and finally multiplies by V. This pipeline causes intermediate matrices S and P to be read from and written to HBM repeatedly.
As sequence length grows, HBM bandwidth becomes the bottleneck before Tensor Core throughput does. In other words, the GPU spends much of its time waiting for data instead of performing fused multiply-add operations. That is where FlashAttention begins its optimization.
The GPU memory hierarchy determines the ceiling of attention performance
 AI Visual Insight: This figure highlights the hierarchical difference between off-chip HBM and on-chip SRAM. The key point is that SRAM has limited capacity but extremely low latency and very high bandwidth, which makes it ideal for local tiled Q/K/V computation. This hardware property is the foundation that makes FlashAttention possible.
AI Visual Insight: This figure highlights the hierarchical difference between off-chip HBM and on-chip SRAM. The key point is that SRAM has limited capacity but extremely low latency and very high bandwidth, which makes it ideal for local tiled Q/K/V computation. This hardware property is the foundation that makes FlashAttention possible.
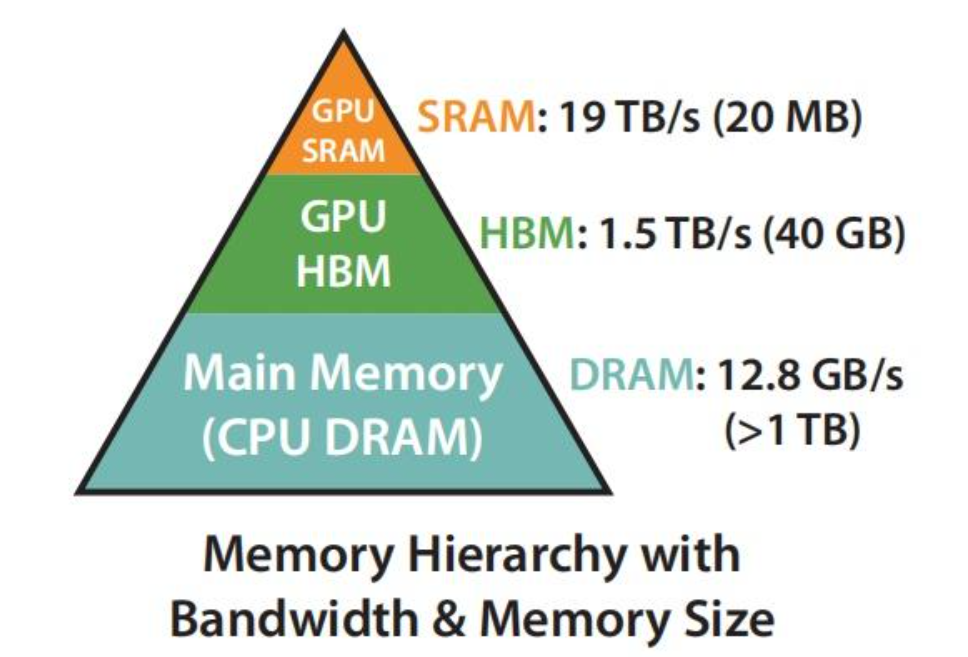 AI Visual Insight: This figure compares the capacity, location, and access characteristics of the two memory types. It shows why attention optimization cannot focus on FLOPs alone; it must also account for the cost of moving data between off-chip and on-chip memory.
AI Visual Insight: This figure compares the capacity, location, and access characteristics of the two memory types. It shows why attention optimization cannot focus on FLOPs alone; it must also account for the cost of moving data between off-chip and on-chip memory.
On GPUs such as the A100, floating-point throughput has increased much faster than memory bandwidth. As long as arithmetic intensity is not high enough, the workload falls into the memory-bound region. Standard attention is a textbook example of this pattern.
import math
N, d = 2048, 64
bytes_fp16 = 2
compute_flops = 4 * N * N * d # Main compute cost of QK^T and PV
io_bytes = 4 * N * N * bytes_fp16 # Repeated reads and writes of S and P
intensity = compute_flops / io_bytes # Arithmetic intensity
print(f"Arithmetic intensity: {intensity:.1f} FLOPs/Byte") # Lower values are more likely to be bandwidth-boundThis code estimates the arithmetic intensity of standard attention and shows why it easily becomes bandwidth-bound.
FlashAttention rewrites a large matrix problem into an on-chip streaming pipeline through tiling
FlashAttention does not change the mathematical result of attention. It only changes the execution order. It partitions Q, K, and V into tiles, loads small blocks into SRAM, completes score computation, normalization, and output accumulation on-chip, and writes back only the final O and a small amount of statistics.
This approach provides two key benefits. First, it no longer writes the N×N S and P matrices back to HBM. Second, it replaces a large amount of off-chip memory traffic with much higher-bandwidth on-chip access. In that sense, FlashAttention is an IO-aware algorithm, not an approximation algorithm.
Tiled computation requires softmax to work tile by tile as well
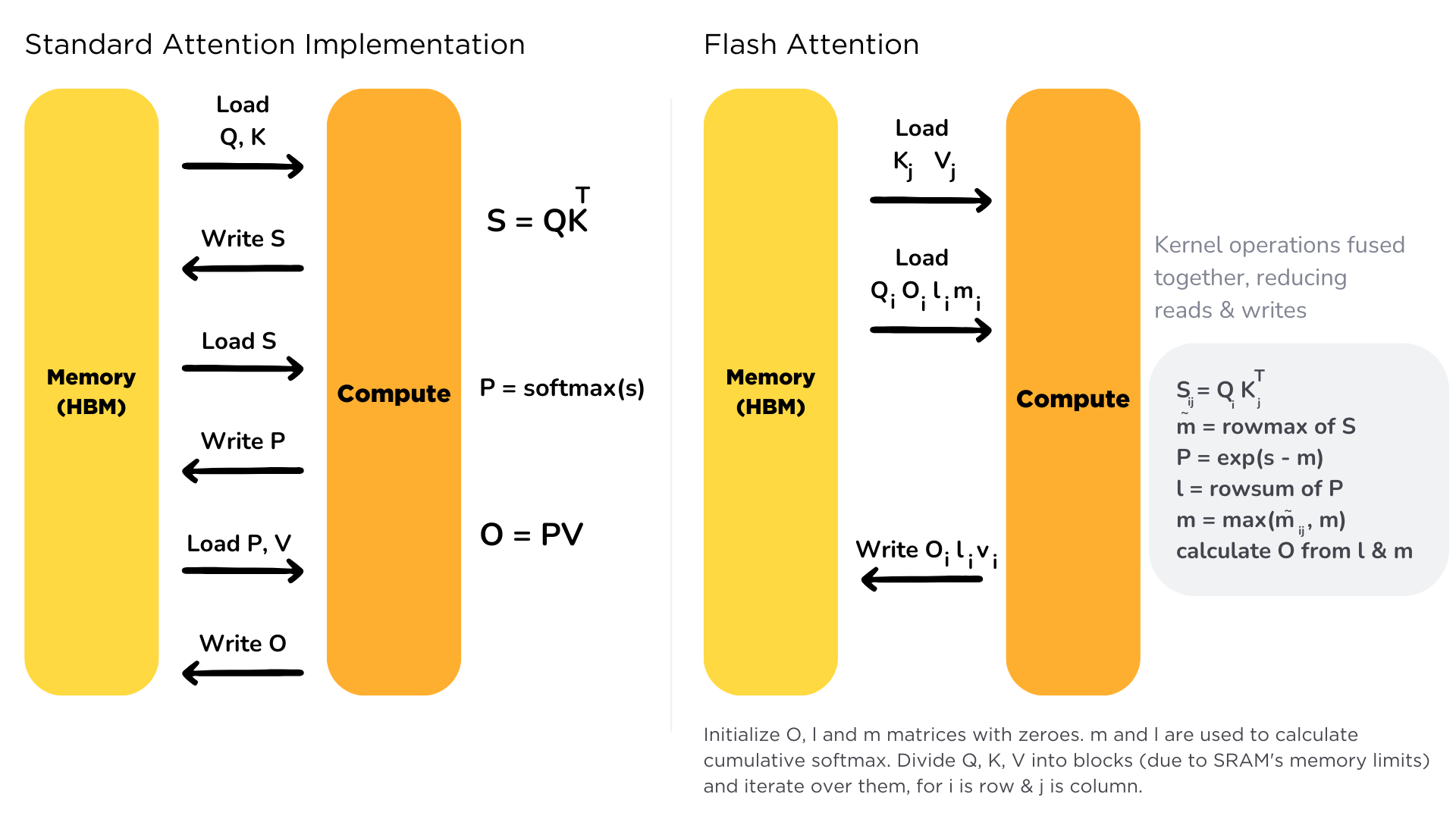 AI Visual Insight: This figure shows how attention shifts from full-matrix computation to a tile-level pipeline. The key detail is that each tile completes local score computation, normalization, and output accumulation on-chip, avoiding the materialization of the full attention matrix.
AI Visual Insight: This figure shows how attention shifts from full-matrix computation to a tile-level pipeline. The key detail is that each tile completes local score computation, normalization, and output accumulation on-chip, avoiding the materialization of the full attention matrix.
The challenge is that softmax depends on a global denominator. Looking at a single tile alone, you cannot directly know the normalized result across all keys in the row. FlashAttention solves this with Online Softmax, which maintains a running maximum m and a normalization accumulator l across tiles.
import math
def online_softmax_update(m_prev, l_prev, scores_block):
m_block = max(scores_block) # Local maximum of the current block
m_new = max(m_prev, m_block) # Update the global maximum
l_new = l_prev * math.exp(m_prev - m_new) + sum(
math.exp(x - m_new) for x in scores_block
) # Rescale old and new blocks to a shared reference before accumulation
return m_new, l_newThis code demonstrates the core update rule of Online Softmax. It guarantees that tiled computation remains mathematically equivalent to standard softmax.
FlashAttention updates statistics and outputs online during the forward pass
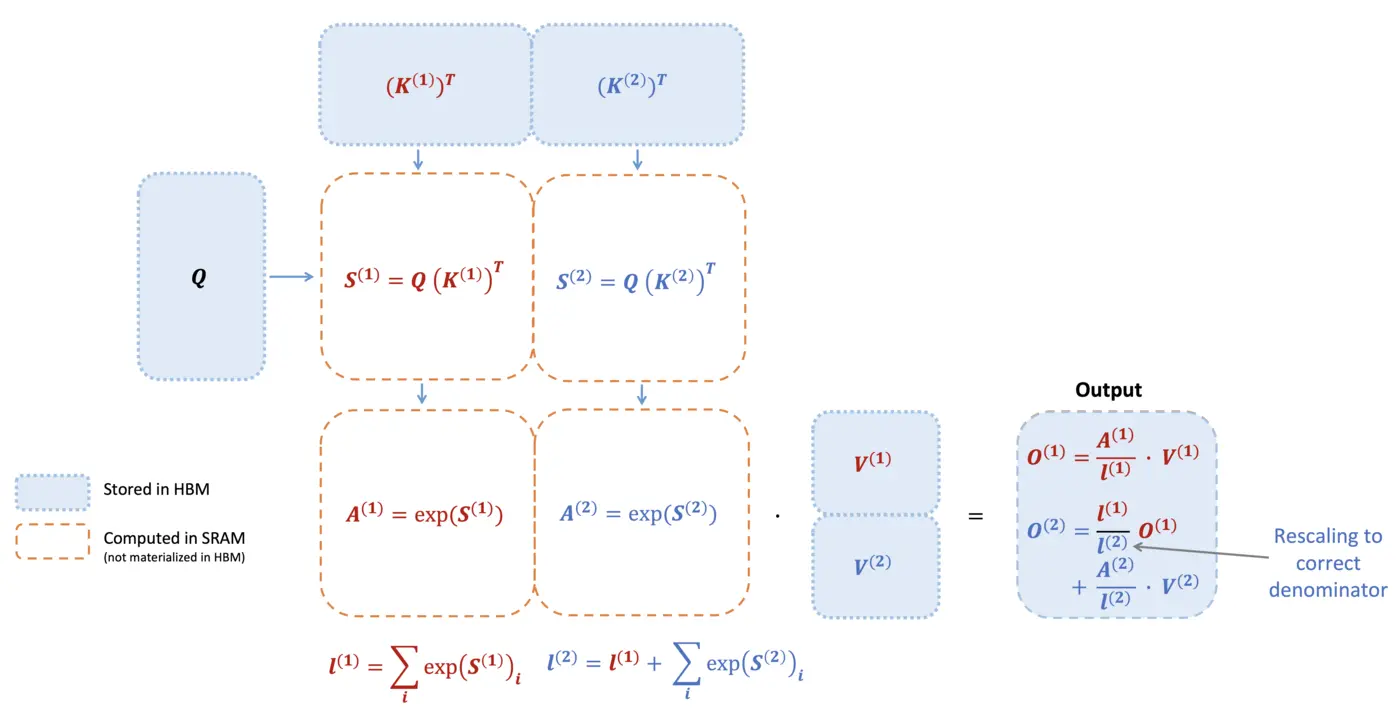 AI Visual Insight: This figure illustrates the double-loop structure: the outer loop iterates over K/V blocks, and the inner loop iterates over Q blocks. It emphasizes that each iteration must update the row maximum, normalization factor, and output tile, which is central to the algorithm’s correctness.
AI Visual Insight: This figure illustrates the double-loop structure: the outer loop iterates over K/V blocks, and the inner loop iterates over Q blocks. It emphasizes that each iteration must update the row maximum, normalization factor, and output tile, which is central to the algorithm’s correctness.
The forward pass does not store the full S and P. Instead, it maintains m, l, and O for each row. Every time it sees a new K/V block, it adjusts the scaling factor for the previous output and then adds the contribution of the current block.
import torch
import math
def flash_attention_forward(Q, K, V, block_size=64):
N, d = Q.shape
scale = 1.0 / math.sqrt(d)
O = torch.zeros_like(Q)
l = torch.zeros(N, device=Q.device)
m = torch.full((N,), -float('inf'), device=Q.device)
for j in range(0, N, block_size):
K_j = K[j:j+block_size]
V_j = V[j:j+block_size]
for i in range(0, N, block_size):
Q_i = Q[i:i+block_size]
S_ij = Q_i @ K_j.T * scale # Compute only the score matrix for the current tile
m_tilde = S_ij.max(dim=-1).values
P_tilde = torch.exp(S_ij - m_tilde[:, None])
l_tilde = P_tilde.sum(dim=-1)
m_new = torch.maximum(m[i:i+block_size], m_tilde)
alpha = torch.exp(m[i:i+block_size] - m_new)
beta = torch.exp(m_tilde - m_new)
l_new = alpha * l[i:i+block_size] + beta * l_tilde
O[i:i+block_size] = (
alpha[:, None] * l[i:i+block_size, None] * O[i:i+block_size]
+ beta[:, None] * (P_tilde @ V_j)
) / l_new[:, None] # Rescale the previous output and accumulate the current block contribution
l[i:i+block_size], m[i:i+block_size] = l_new, m_new
return OThis teaching example shows the minimal core of the FlashAttention forward pass: tiled computation, Online Softmax, and output rescaling.
Memory usage drops to O(N) because the backward pass uses recomputation
Standard attention usually caches S and P during training, which gives it a memory complexity close to O(N²). FlashAttention instead stores only the output and log-sum-exp statistics, then recomputes local scores block by block during the backward pass.
This introduces extra computation, but it saves much more expensive HBM traffic and intermediate tensor storage. On modern GPUs, reducing memory movement is usually more important than reducing computation, so the end-to-end result is still faster.
The improvement in IO complexity is the real reason behind the 3x speedup
The HBM traffic of standard attention can be approximated as O(N²), while FlashAttention reduces it to O(N²d/M), where M represents available on-chip memory. As long as M is much larger than d, memory traffic drops substantially.
Across published papers and engineering benchmarks, FlashAttention commonly delivers about 2-3x training speedup and roughly 5-20x memory savings. The longer the sequence, the more visible the benefit usually becomes, because the pressure from N² intermediate matrices appears earlier and more severely.
In practice, the most useful entry point is PyTorch’s SDPA interface
import torch
import torch.nn.functional as F
Q = torch.randn(2, 8, 1024, 64, device='cuda', dtype=torch.float16)
K = torch.randn(2, 8, 1024, 64, device='cuda', dtype=torch.float16)
V = torch.randn(2, 8, 1024, 64, device='cuda', dtype=torch.float16)
with torch.backends.cuda.sdp_kernel(
enable_flash=True, # Prefer the FlashAttention kernel
enable_math=False,
enable_mem_efficient=False,
):
O = F.scaled_dot_product_attention(Q, K, V)This example shows the most direct way to invoke FlashAttention in PyTorch 2.x, and it fits most training and inference scenarios.
FlashAttention-2 and FlashAttention-3 push hardware affinity even further
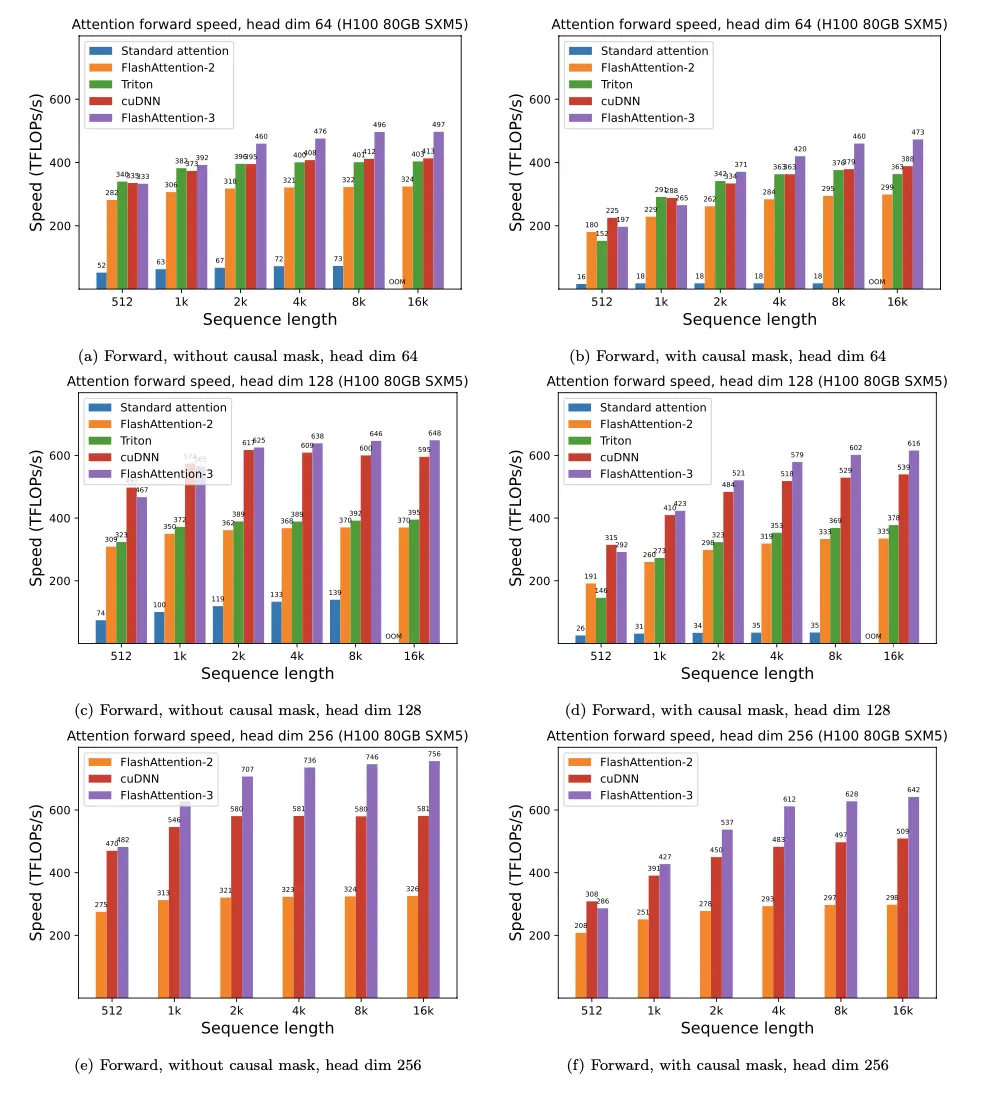 AI Visual Insight: This figure shows how FA-2 restructures parallel work assignment. The focus is on using warps and SMs more evenly, reducing warp idle time and synchronization overhead, and improving Tensor Core utilization.
AI Visual Insight: This figure shows how FA-2 restructures parallel work assignment. The focus is on using warps and SMs more evenly, reducing warp idle time and synchronization overhead, and improving Tensor Core utilization.
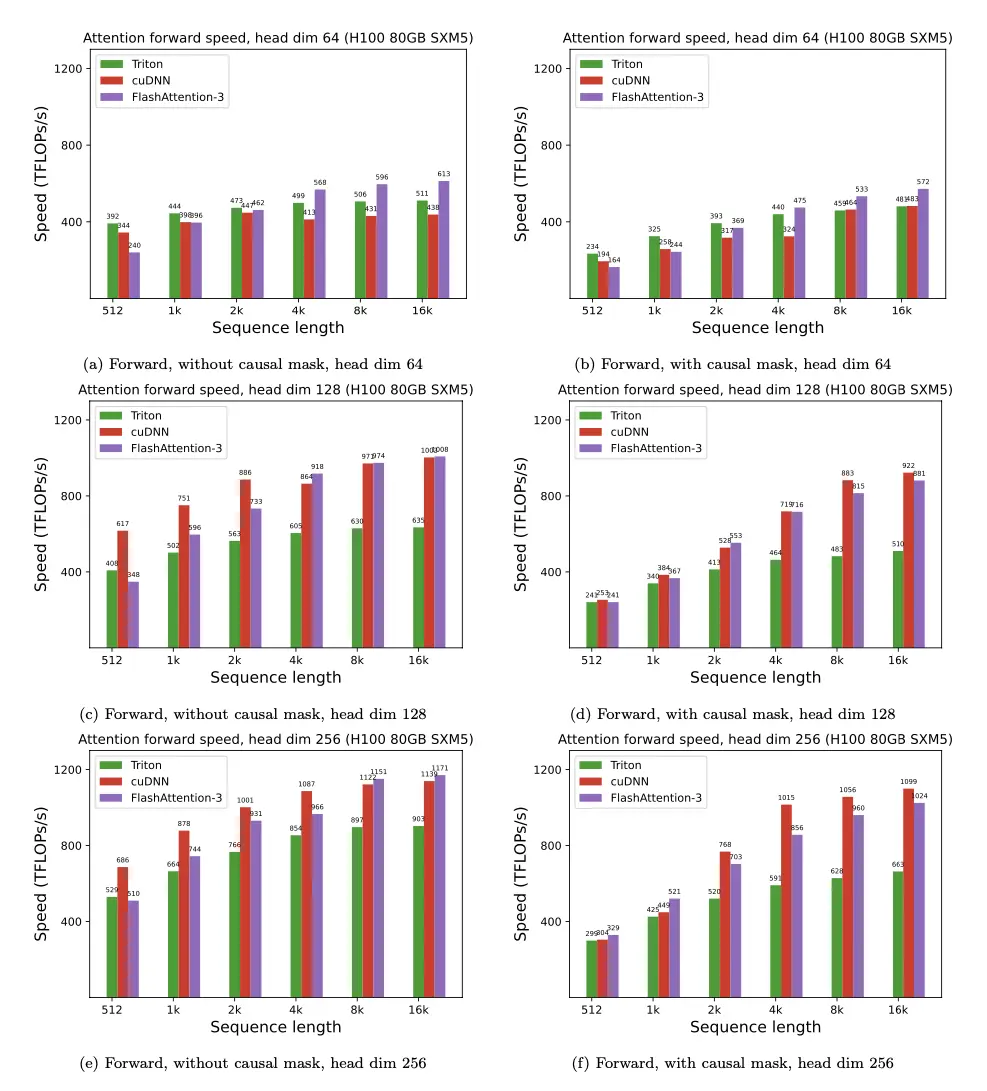 AI Visual Insight: This figure emphasizes task partitioning along the query dimension and parallel execution across multiple blocks, showing that FA-2 improves performance not only through operator fusion but also through better execution scheduling.
AI Visual Insight: This figure emphasizes task partitioning along the query dimension and parallel execution across multiple blocks, showing that FA-2 improves performance not only through operator fusion but also through better execution scheduling.
FA-2 mainly addresses parallel partitioning and the overhead of non-matmul operations, making GPU core utilization more balanced. FA-3 targets the H100 specifically, introducing asynchronous pipelining, TMA, and lower-precision execution paths to push bandwidth and throughput even further.
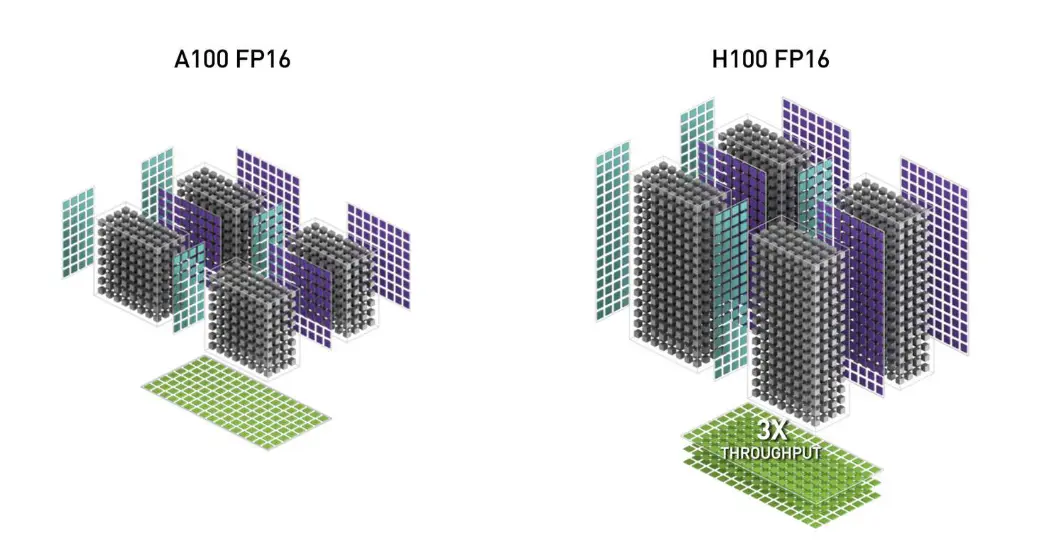 AI Visual Insight: This figure points to new Hopper capabilities such as TMA, WGMMA, and FP8 support. These features allow attention computation to overlap with asynchronous data movement, significantly reducing wait time.
AI Visual Insight: This figure points to new Hopper capabilities such as TMA, WGMMA, and FP8 support. These features allow attention computation to overlap with asynchronous data movement, significantly reducing wait time.
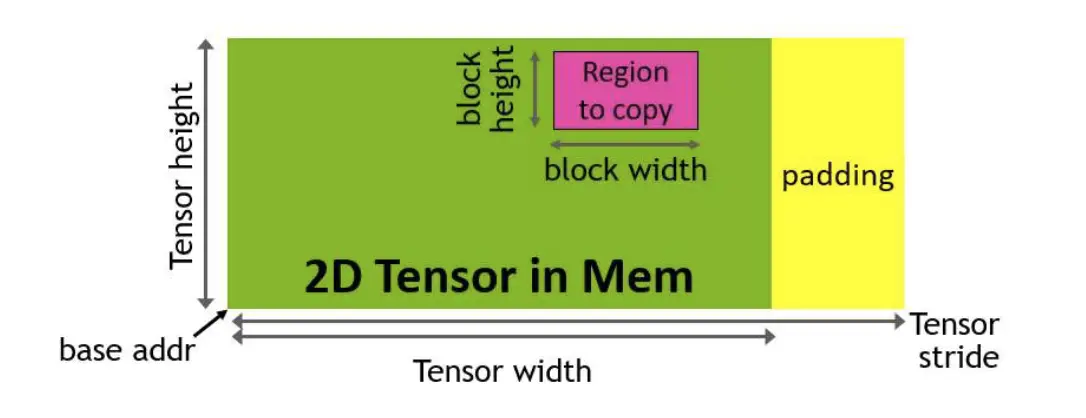 AI Visual Insight: This figure shows a pipeline where data loading and computation overlap in parallel. The technical focus is producer-consumer scheduling that hides memory latency behind concurrent compute.
AI Visual Insight: This figure shows a pipeline where data loading and computation overlap in parallel. The technical focus is producer-consumer scheduling that hides memory latency behind concurrent compute.
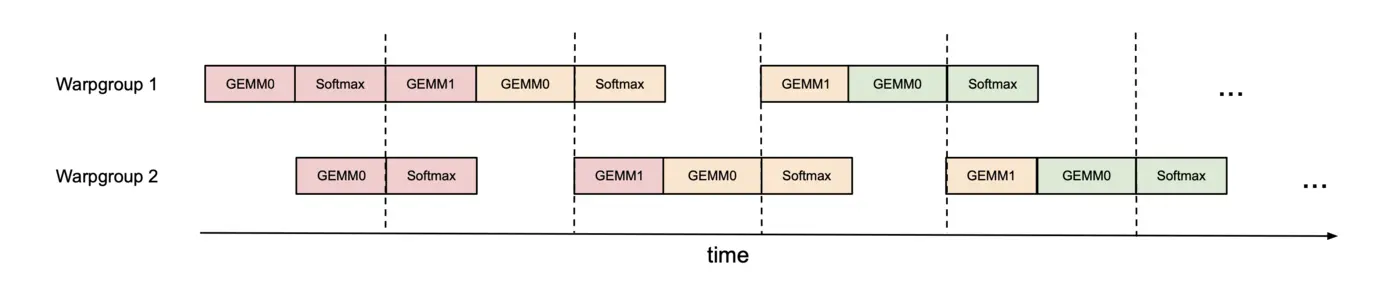 AI Visual Insight: This figure describes two warpgroups that alternate GEMM and softmax execution through synchronization barriers. This is a typical low-level scheduling optimization used to improve execution unit occupancy.
AI Visual Insight: This figure describes two warpgroups that alternate GEMM and softmax execution through synchronization barriers. This is a typical low-level scheduling optimization used to improve execution unit occupancy.
The conclusion is that FlashAttention has become infrastructure-level optimization for long-context training
If your model still uses a traditional attention kernel for long sequences, the bottleneck is probably not the model architecture but the memory access path. The value of FlashAttention is that it makes exact attention come much closer to hardware-optimal execution for the first time.
For developers, the most important takeaway is not memorizing the formulas but understanding why it is fast: not because it computes less, but because it writes fewer large matrices, relies less on HBM, and keeps more work inside SRAM.
FAQ
Why is FlashAttention not an approximation algorithm?
It does not modify the attention objective function. It only reorders the computation. With Online Softmax and tiled accumulation, the final output remains mathematically equivalent to standard softmax attention.
Why can FlashAttention reduce memory complexity from O(N²) to O(N)?
Because it no longer stores the full attention matrices S and P during training. Instead, it stores per-row statistics and outputs. When needed during backpropagation, it recomputes local tiles, so intermediate storage drops from matrix scale to vector scale.
When is FlashAttention most worth enabling?
It provides the biggest benefit for long-sequence training, memory-constrained workloads, and models with many multi-head attention layers. As sequence length increases and HBM pressure rises, its speed and memory advantages usually become more obvious.
[AI Readability Summary] This article explains FlashAttention from the GPU memory hierarchy, the IO bottleneck of standard attention, and the mechanics of tiling and Online Softmax. It shows why FlashAttention can preserve exact computation while still delivering 2-3x speedup and 5-20x memory savings, and it also covers PyTorch integration plus the evolution toward FA-2 and FA-3.