[AI Readability Summary] Redis is a high-performance in-memory NoSQL database designed for low-latency reads and writes. Its core strengths include support for multiple data structures, persistence and recovery, and strong suitability for high-concurrency caching, session management, and hot-data acceleration. Keywords: Redis, NoSQL, Cache.
| Parameter | Description |
|---|---|
| Language | C (server-side), with Java/Python client access |
| Protocol | RESP / TCP |
| Stars | Not provided in the source |
| Core Dependencies | gcc, make, tcl, jedis, redis-py |
Redis is an in-memory NoSQL database built for high-concurrency workloads
Redis is a key-value NoSQL database, but it is far more than a simple cache. It stores data in memory, which gives it naturally low latency, and it supports structures such as String, Hash, List, Set, and ZSet. That makes it well suited for caching, leaderboards, sessions, counters, and message distribution.
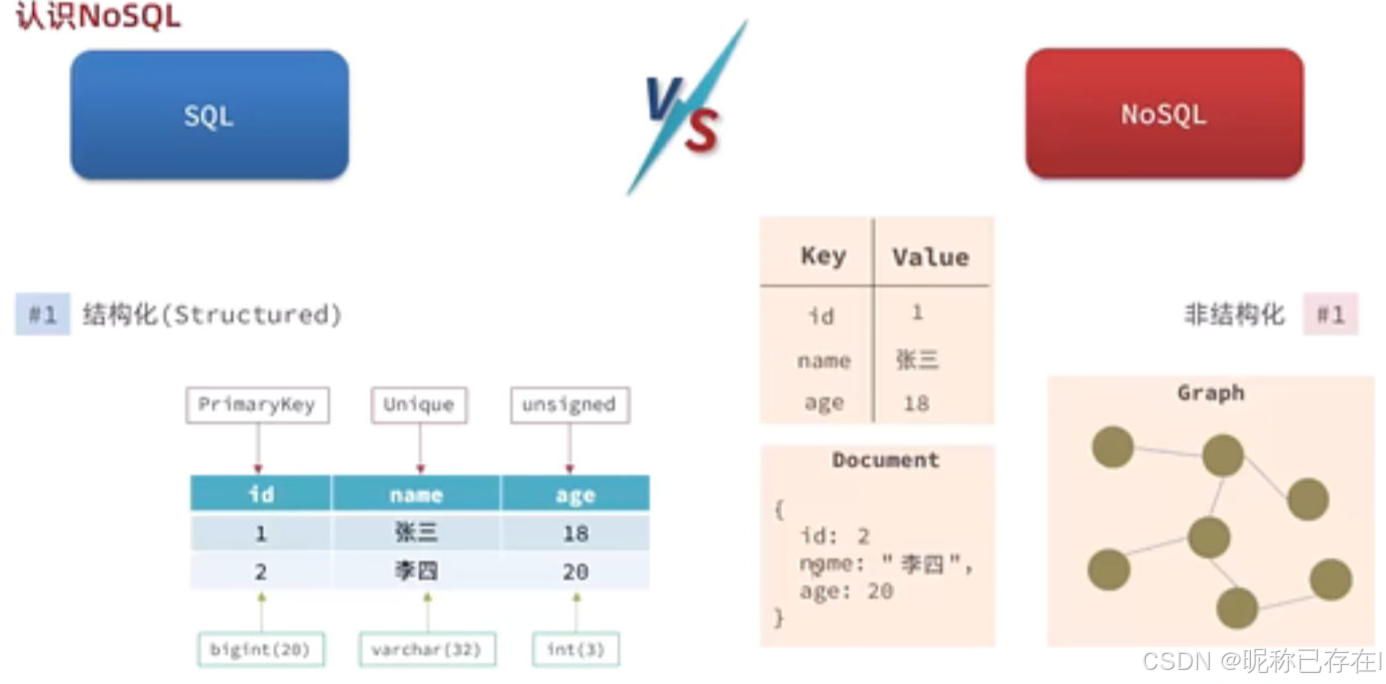 AI Visual Insight: This diagram illustrates the broader conceptual boundaries of NoSQL. It typically contrasts relational and non-relational databases in terms of scaling models, schema constraints, and access patterns, helping readers understand where Redis fits in the technology landscape.
AI Visual Insight: This diagram illustrates the broader conceptual boundaries of NoSQL. It typically contrasts relational and non-relational databases in terms of scaling models, schema constraints, and access patterns, helping readers understand where Redis fits in the technology landscape.
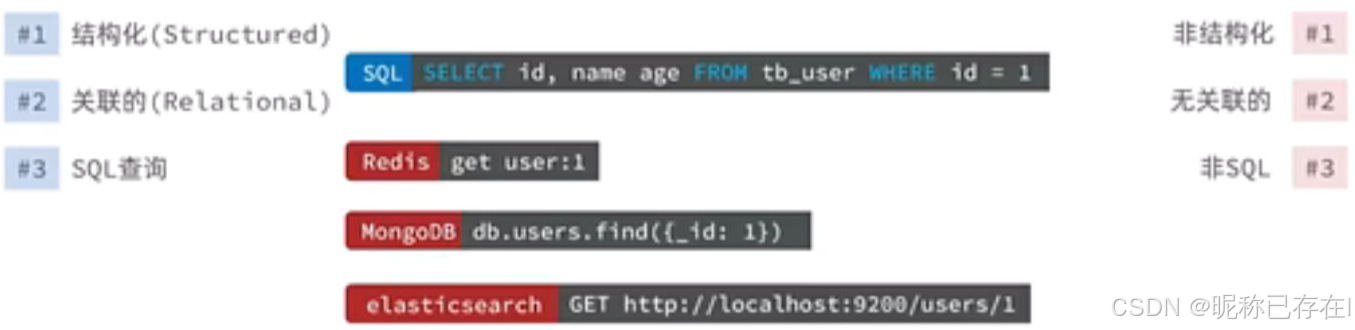 AI Visual Insight: This diagram further emphasizes NoSQL’s flexible data model and horizontal scalability. It is commonly used to explain scenarios involving unstructured data, distributed node expansion, and weak transaction models.
AI Visual Insight: This diagram further emphasizes NoSQL’s flexible data model and horizontal scalability. It is commonly used to explain scenarios involving unstructured data, distributed node expansion, and weak transaction models.
Redis delivers both speed and flexibility as its core value
Compared with relational databases, Redis gives up complex joins and strict schema constraints in exchange for higher throughput. Its engineering value extends beyond caching to foundational capabilities such as distributed locks, rate limiting, delayed queues, and real-time analytics.
Redis deployment is best done on Linux
For production environments, Linux should be your first choice. The main installation dependencies are the build toolchain and tcl. Installing Redis from source is straightforward and also helps you understand where the binaries and configuration files live.
# Install build dependencies
sudo apt update
sudo apt install -y build-essential tcl
# Extract and compile Redis
tar xzf redis-6.2.21.tar.gz
cd redis-6.2.21
make && sudo make install # Compile and install into the system pathThese commands compile Redis from source and perform a basic installation.
Redis startup should be designed together with configuration governance
The default startup mode works well for local debugging, but production environments should explicitly load redis.conf. The most important settings include bind, port, daemonize, requirepass, maxmemory, and the log level.
# Start Redis with the default settings
redis-server
# Health check: PONG means the service is available
redis-cli ping
# Start Redis with a specific configuration file
redis-server /etc/redis/redis.confThese commands demonstrate three common startup patterns: default launch, connectivity verification, and configuration-based startup.
Running Redis as a service improves maintainability
On Linux, you should manage Redis with systemd so you can enable startup on boot, automatic restarts after failure, and centralized log handling. If you enable daemonize yes, the systemd service type usually uses forking.
Redis data structure design determines its adaptability
Redis is often called a “data structure server” because it is not a single-model key-value store. Instead, it provides data models optimized for different scenarios. Developers should choose the right structure first, then design the key space around it.
String works well for counters, cached objects, and state flags
String is the most basic Redis data type. It supports commands such as set, mget, and incr, and it is commonly used for verification codes, access counters, and distributed sequence numbers.
# Write multiple key-value pairs in one operation
mset k1 1 k2 2 k3 3
# Atomically increment a numeric value
incr k1 # Core logic: useful for implementing counters
mget k1 k2 k3These commands show batch writes and atomic increment operations with String.
Hash is better suited for lightweight objects
Hash works well for object-like data such as user profiles and product attributes. Compared with serializing an entire JSON document, Hash lets you read and update individual fields, which reduces network overhead.
List, Set, and ZSet cover queues, deduplication, and sorting respectively
List is a good fit for message queues and timelines. Set is useful for tags, friend relationships, and set operations such as intersections and unions. ZSet sorts members by score, which makes it ideal for leaderboards, priority queues, and delayed tasks.
# Insert leaderboard data
zadd stus 99 lih 80 hei 66 ta 88 lina
# Read the first 3 entries in ascending score order
zrange stus 0 2 # Core logic: returns members from low score to high score
# Read the first 3 entries in descending score order
zrevrange stus 0 2These commands demonstrate a typical leaderboard use case for ZSet.
Redis integration at the application layer usually relies on standard clients
Jedis is a common choice in Java, while redis-py is widely used in Python. The key to client integration is not simply whether it connects, but whether you define connection pooling, timeouts, authentication, and serialization strategies in advance.
import redis.clients.jedis.Jedis;
public class RedisDemo {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost");
// If password authentication is enabled, call auth first
jedis.set("site", "redis"); // Core logic: write a string key-value pair
System.out.println(jedis.get("site"));
}
}This example shows the smallest viable Redis read/write flow in Java using Jedis.
import redis
r = redis.Redis(host='127.0.0.1', port=6379, password='123123', decode_responses=True)
r.ping() # Core logic: verify that the connection works
r.hset('user:1001', mapping={'name': 'Li Si', 'age': '32'})
r.expire('user:1001', 300) # Set an expiration time to test automatic cleanup
print(r.hgetall('user:1001'))This example demonstrates how to connect to Redis in Python, write a Hash, and set a TTL.
Redis persistence strategy must serve data safety goals
Redis is memory-first by design, so data may be lost after a restart. For that reason, persistence is a production requirement. Common options include RDB snapshots, AOF logs, and a hybrid mode that combines both.
RDB is better for fast recovery and backup archiving
RDB generates in-memory snapshots under specified conditions, usually written to dump.rdb. Its strengths are fast recovery and compact file size. Its weakness is that data written between two snapshots can be lost.
# Typical RDB trigger strategy
save 900 1
save 300 10
save 60 10000
# Check persistence status
redis-cli INFO PersistenceThis configuration defines RDB snapshot thresholds and checks background save status.
AOF is better for stronger write durability
AOF appends write commands to a log and restores data by replaying that log on restart. The recommended setting is everysec, which balances performance and durability. If both RDB and AOF are enabled, Redis will usually prefer AOF during recovery.
Redis cache issues under high concurrency require layered governance
In cache design, the three most common problems are cache penetration, cache breakdown, and cache avalanche. None of these are Redis failures by themselves. They happen when cache strategy and traffic patterns do not match.
Cache penetration should block invalid requests first
Cache penetration happens when requested data exists in neither the cache nor the database. Common solutions include parameter validation, caching null values, and Bloom filters. The core goal is to prevent invalid traffic from overwhelming the database.
Cache breakdown should protect the rebuild process for hot keys
Cache breakdown occurs when a single hot key expires. Typical solutions include mutex locks, logical expiration, and asynchronous refresh, so one thread rebuilds the cache while the others wait or return stale data.
String key = "cache:shop:" + id;
String val = redis.get(key);
if (val != null) {
return val; // Core logic: return immediately on a cache hit
}
Boolean locked = redis.setnx("lock:shop:" + id, "1", 10);
if (locked) {
// Core logic: only the thread that gets the lock can rebuild the cache
// Query the database and repopulate the cache
}This pseudocode shows the basic mutex-lock pattern for rebuilding a hot key.
Cache avalanche requires architectural defense rather than isolated fixes
Cache avalanche happens when many keys expire at the same time or when the cache layer becomes unavailable as a whole. The mitigation strategy should include randomized expiration times, multi-level caching, Redis high availability, rate limiting, circuit breaking, and degraded fallback pages, so the database does not absorb the entire traffic spike.
Redis and Kafka serve different roles
Redis excels at low-latency reads and writes with real-time access. Kafka excels at high-throughput event accumulation and asynchronous consumption. A simple way to frame it is this: Redis is optimized for fast reads and fast access, while Kafka is optimized for durable writes and reliable delivery. In real systems, they often work together rather than replace each other.
FAQ
1. Should production Redis prioritize RDB or AOF?
If you care more about fast recovery and smaller backup size, prioritize RDB. If you care more about data integrity, enable AOF with everysec. In most production environments, a combined RDB+AOF persistence strategy is recommended.
2. How do I quickly choose among the five core Redis data structures?
Use String for counters and simple caching. Use Hash for object fields. Use List for queues. Use Set for deduplication and relationship collections. Use ZSet for leaderboards and score-based ordering.
3. How can I systematically prevent cache avalanche?
At a minimum, you should randomize TTL values, keep hot keys non-expiring or use logical expiration, add local cache fallback, enable Redis high availability, apply database rate limiting, and implement service degradation so that all traffic does not fall back to the database at once.
Core takeaway: This article reconstructs the core Redis knowledge system from end to end. It covers Redis’s place in the NoSQL ecosystem, Linux installation, the five primary data structures, Java and Python integration, RDB and AOF persistence, and practical governance strategies for cache penetration, breakdown, and avalanche. It is a strong primer for both developers and operations engineers who want a complete mental model of Redis.