[AI Readability Summary]
Ollama v0.21.0 significantly strengthens the
launchworkflow, adding Hermes Agent and Copilot CLI integration while fixing Gemma4 rendering and cache issues, MLX fused computation, and context continuity bugs. It addresses pain points such as repeated launch config rewrites, unclear Windows onboarding, and inconsistent model performance. Keywords: Ollama, Hermes, MLX.
Technical specification snapshot
| Parameter | Information |
|---|---|
| Project Name | ollama |
| Version | v0.21.0 |
| Primary Language | Go |
| Typical Interfaces/Protocols | CLI, HTTP API |
| Repository | github.com/ollama/ollama |
| Stars | Not provided in the source |
| Release Date | 2026-04-17 |
| Core Dependency Areas | Hermes Agent, Copilot CLI, MLX, Gemma4 |
This release centers on workflow improvements and stability
Ollama v0.21.0 is not a narrow patch release. It delivers a coordinated update across the CLI launch entry point, agent integration, model rendering, cache management, and the MLX execution path. For developers, the practical value is clear: easier adoption and fewer pitfalls at the same time.
The two most important threads in the release are the expanded launch system and the low-level Gemma4/MLX fixes. The former improves the developer experience, while the latter improves runtime stability and model performance.
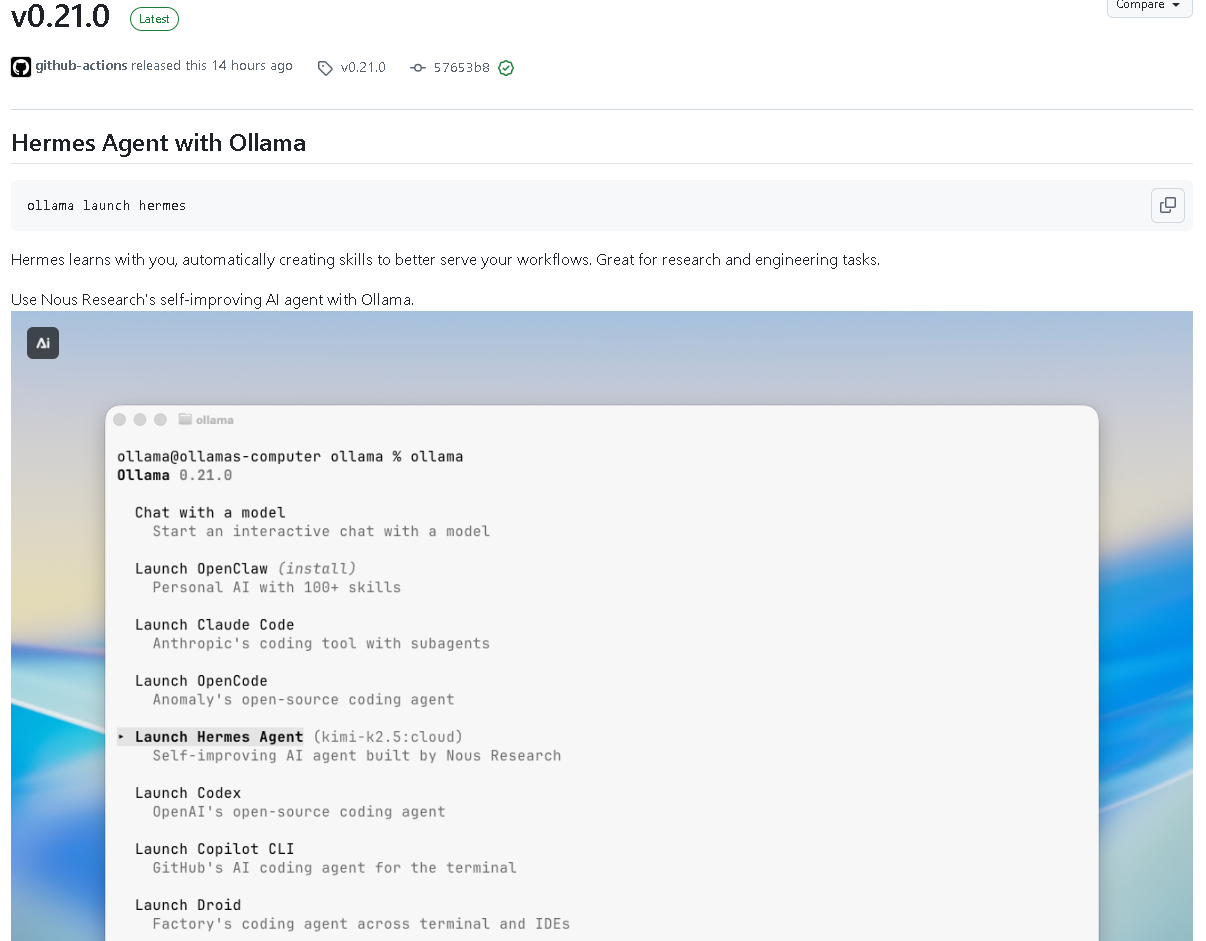
 AI Visual Insight: This screenshot appears to show the Ollama release page or version changelog view. The key information is concentrated around the version number, release date, and change list, indicating that this update is designed for release-note-driven reading and quick verification of new features and fixes.
AI Visual Insight: This screenshot appears to show the Ollama release page or version changelog view. The key information is concentrated around the version number, release date, and change list, indicating that this update is designed for release-note-driven reading and quick verification of new features and fixes.
A minimally visible upgrade entry point has now taken shape
# Start Hermes Agent with Ollama integration
ollama launch hermes
# Continue integrating other toolchains through the launch system
ollama launchThis command sequence shows the most direct new entry point in v0.21.0: it moves Ollama beyond a model runner and toward an agent workflow entry layer.
The addition of Hermes Agent expands Ollama’s task boundary
The newly added launch: add hermes makes ollama launch hermes a clear official entry point. According to the release notes, Hermes is a self-improving AI agent that can learn during use and generate new skills, making it better suited for research and engineering tasks.
This means Ollama is no longer focused only on local model invocation. It is beginning to support more complete agent orchestration scenarios. For teams that need research assistance, engineering automation, and multi-step execution, this entry point matters.
 AI Visual Insight: This image shows the middle section of the release changelog, emphasizing entries related to launch and integration capabilities. It helps readers confirm that Hermes, Copilot CLI, OpenClaw, and related items were introduced as part of the same coordinated release rather than as isolated patches.
AI Visual Insight: This image shows the middle section of the release changelog, emphasizing entries related to launch and integration capabilities. It helps readers confirm that Hermes, Copilot CLI, OpenClaw, and related items were introduced as part of the same coordinated release rather than as isolated patches.
Hermes means more than just a new command
# Typical usage: use launch as the unified entry point
ollama launch hermes # Start the Hermes workflowThe value behind this command is a unified entry point, unified configuration, and a unified recommendation mechanism, not simply the addition of another plugin name.
The launch system is evolving from a launcher into an integration hub
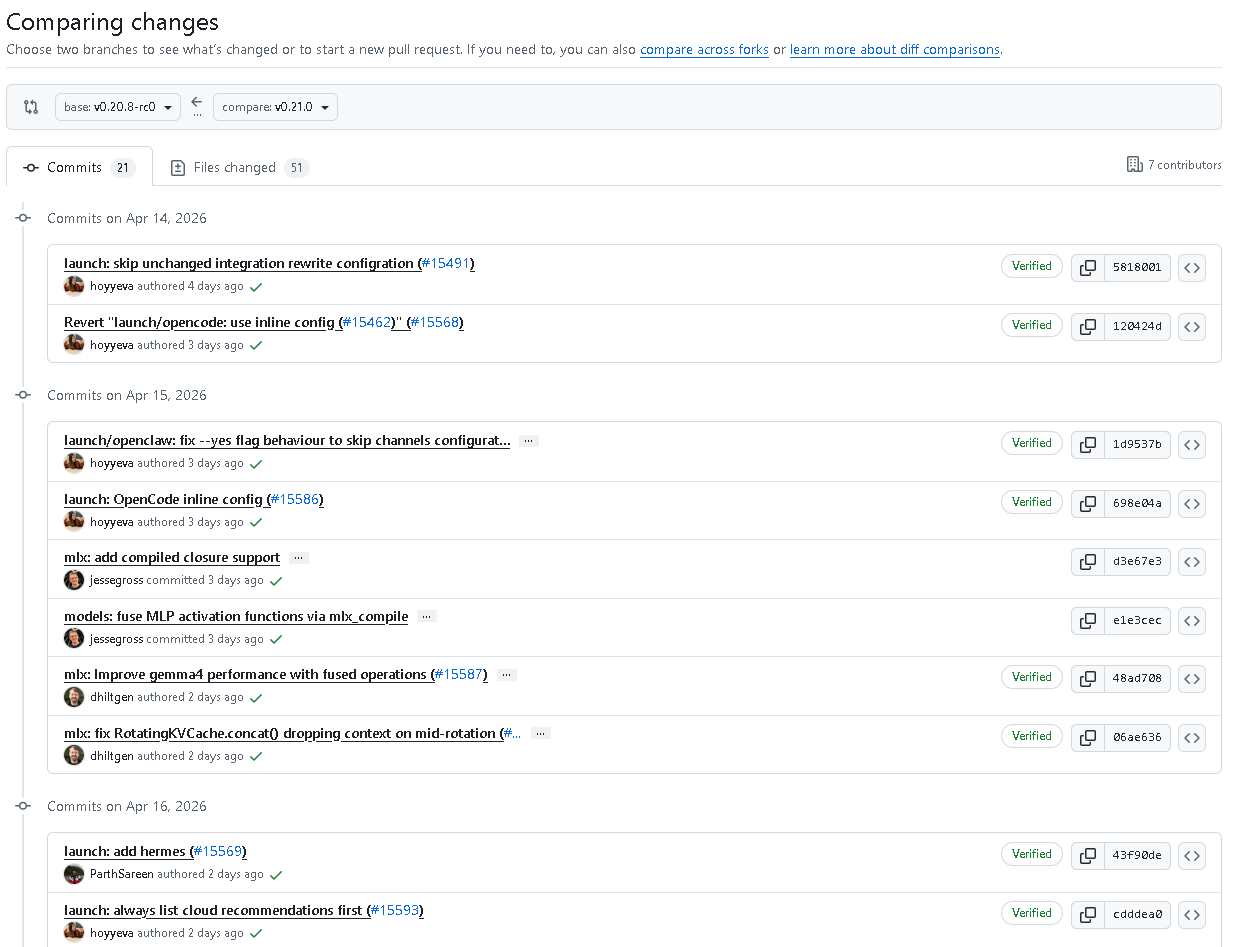
The v0.21.0 improvements to launch are highly concentrated. First, unchanged integration rewrites and managed-single rewrites are skipped, which reduces redundant writes. Second, cloud recommendations are prioritized, which suggests that the project is guiding users toward more complete capability bundles.
Third, the behavior of OpenClaw’s --yes flag has been fixed so automatic confirmation can skip channel configuration. Fourth, on Windows, the flow no longer hands off abruptly and instead shows direct WSL guidance, reducing the cognitive cost of environment switching.
You can understand the configuration stability improvements with pseudocode
# Skip rewriting when the configuration is unchanged # English comment: avoid unnecessary writes
if new_config == old_config:
skip_rewrite()
else:
write_config(new_config)This logic captures the main goal behind several “skip unchanged rewrite” updates in this release: reduce side effects and improve predictability.
Copilot CLI has been added to the unified launch integration path
cmd/launch: add Copilot CLI integration is another high-value update. It shows that Ollama is bringing command-line AI tooling into a unified integration layer, allowing developers to coordinate different assistant capabilities with less context switching.
The significance of this type of integration is not just that the tools can connect. It is that launch becomes the unified entry point for tool discovery, configuration persistence, and recommendation ranking. For users who want local models to work alongside external CLI assistants, the integration value is much higher than manual assembly.
 AI Visual Insight: This image shows the latter part of the update list, focusing on Gemma4 and MLX fixes. It indicates that this release not only strengthens upper-layer entry points but also repairs model execution details, forming a dual upgrade pattern of improved onboarding plus reinforced internals.
AI Visual Insight: This image shows the latter part of the update list, focusing on Gemma4 and MLX fixes. It indicates that this release not only strengthens upper-layer entry points but also repairs model execution details, forming a dual upgrade pattern of improved onboarding plus reinforced internals.
A developer-oriented workflow might look like this
# Manage optional integrations through launch
ollama launch # View recommendations and available integrations
# Choose Hermes, Copilot CLI, or other capabilitiesThis suggests that Ollama is trying to bring fragmented toolchains into a single interaction surface.
Gemma4 fixes focus on rendering, precision, and cache consistency
Gemma4 receives the most concentrated model-level fixes in this release. The updates include using different rendering strategies based on model size, preserving source precision in router projection, conditionally handling empty blocks, and using a logical view for cache handling along with additional cache fixes.
Together, these items point to one goal: reduce inconsistent behavior across templates and execution paths. For model users, the most obvious benefits are more stable results, more reliable caching, and rendering logic that better matches model-scale characteristics.
The key Gemma4 changes can be grouped into three categories
1. Rendering split: differentiated handling based on model size
2. Precision retention: router projection preserves source precision
3. Cache fixes: logical view + additional fixesThese three categories cover the presentation layer, compute layer, and state layer, making this a textbook example of a systematic repair pass.
MLX fixes show continued investment in the performance path
The MLX-related updates include compiled closure support, fusing MLP activation functions through mlx_compile, improving Gemma4 performance with fused operations, and fixing RotatingKVCache.concat() so it no longer loses context during mid-rotation.
The most important fix here is the KV cache context-loss issue, because bugs of this kind directly affect consistency in long-context generation. Combined with the image generation lookup fix, this shows that MLX work in this release targets both operator efficiency and functional correctness.
You can understand the goal of fused operations with a simplified example
# Fuse multiple steps into fewer execution units # English comment: reduce intermediate overhead
x = linear(x)
x = activation(x)
# On the optimized path, these operations may be compiled into a fused formThis example reflects the core purpose of mlx_compile and fused operations: reduce intermediate tensor overhead and scheduling cost.
The concurrency fix in the create flow closes a stability gap
create: avoid gc race with create may not be the most visible change in the release, but it has high engineering value. It fixes a potential race condition between the create flow and garbage collection, reducing the likelihood of issues caused by poorly timed resource cleanup.
Fixes like this rarely appear in feature demos, but they directly affect production usability, especially in scenarios involving frequent model creation, resource switching, or automated deployment.
The real developer value of this upgrade is easy to frame
If you care about agent workflows, Hermes is the top highlight. If you rely heavily on command-line AI tools, the Copilot CLI integration deserves close attention. If you depend on Gemma4 or the MLX path, this release is better understood as a stability upgrade that you should seriously evaluate.
Overall, v0.21.0 pushes Ollama further from a local model runtime framework toward a local AI workflow entry layer. That transition is a key part of how it strengthens its competitiveness in the AI developer tooling stack.
FAQ
Q1: What is the most important feature to try first in Ollama v0.21.0?
A: Start with ollama launch hermes. It marks Ollama’s formal move into the agent workflow entry layer instead of remaining only a model runner.
Q2: What is the direct day-to-day impact of the launch improvements?
A: The immediate impact is fewer redundant configuration writes, clearer Windows guidance, and higher-priority cloud recommendations. The overall startup experience becomes more stable and more predictable.
Q3: Why do the Gemma4 and MLX fixes matter?
A: Because they affect rendering logic, cache consistency, context continuity, and execution efficiency. When these issues occur, they directly degrade model quality and system stability.
Core Summary: Ollama v0.21.0 focuses on strengthening the launch system and fixing low-level stability issues. It adds Hermes Agent integration and Copilot CLI support, improves OpenCode, OpenClaw, cloud recommendations, and Windows WSL guidance, and delivers concentrated fixes for Gemma4 rendering, caching, precision, and the MLX performance path.