[AI Readability Summary] The core of data mining is extracting actionable knowledge from massive datasets to solve the problem of having plenty of data but little decision clarity. This article breaks down 10 classic algorithms across three main tracks—association analysis, classification, and clustering—and provides minimal implementation ideas. Keywords: data mining, machine learning, cluster analysis.
Technical Specifications Snapshot
| Parameter | Details |
|---|---|
| Domain | Data Mining / Machine Learning / Data Analysis |
| Implementation Languages | Python, SQL (example level) |
| Common Protocols/Paradigms | Batch Processing, Supervised Learning, Unsupervised Learning |
| Typical Tasks | Classification, Clustering, Association Rules, Ranking |
| GitHub Stars | Not provided in the source; this is not open-source project documentation |
| Core Dependencies | scikit-learn, pandas, numpy |
Data mining is fundamentally about discovering reusable patterns from data
Data mining is not just about “digging through data.” It is the process of extracting patterns, relationships, and probabilities from historical samples for prediction, segmentation, recommendation, or decision support. It usually sits between data cleaning and business application.
For developers, the most effective way to understand data mining is not to memorize definitions, but to first distinguish three task types: use classification for data with known labels, clustering for unlabeled data that needs automatic grouping, and association analysis for discovering co-occurrence relationships.
A minimal data mining workflow looks like this
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# X represents features, and y represents known labels
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Train a basic classification model with a decision tree
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# Evaluate model performance on the test set
score = model.score(X_test, y_test)
print(score)This code shows the most basic classification mining workflow: split the data, train the model, and output the result.
Classic algorithms can be organized into a problem-oriented mental map
The source content covers 10 high-frequency algorithms, making it a useful entry-level map for data mining. If you only memorize names, confusion comes quickly. If you remember them by the problems they solve, transfer learning becomes much easier.
- Association Analysis: Apriori
- Ranking and Link Analysis: PageRank
- Ensemble Classification: AdaBoost
- Decision Tree Classification/Regression: C4.5, CART
- Probabilistic Classification: Naive Bayes
- Maximum-Margin Classification: SVM
- Neighbor-Based Voting Classification: KNN
- Unsupervised Clustering: K-Means, EM
 AI Visual Insight: This image presents a layered conceptual framework for data mining algorithms. It is typically used to categorize algorithms such as classification, clustering, and association analysis by task type, helping readers build a mapping between algorithms, problem types, and business scenarios.
AI Visual Insight: This image presents a layered conceptual framework for data mining algorithms. It is typically used to categorize algorithms such as classification, clustering, and association analysis by task type, helping readers build a mapping between algorithms, problem types, and business scenarios.
Start by understanding the three most common ways of thinking
PageRank solves the problem of “who matters more.” It does not only count how many nodes point to a target node, but also weighs the importance of the referring nodes themselves. That makes it suitable for web page ranking, node influence analysis, and propagation modeling on graph structures.
Apriori solves the problem of “what frequently appears together.” Support measures frequency, confidence measures conditional probability, and lift measures whether an association is genuinely meaningful. Typical use cases include product bundling and joint recommendation.
AdaBoost solves the problem of “how to combine multiple weak models into a strong one.” It continually increases the weight of samples misclassified in the previous round so that later models focus more on hard cases, improving overall classification performance round by round.
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
# Use a weak learner as the base classifier
base_model = DecisionTreeClassifier(max_depth=1) # A one-level stump used as a weak classifier
model = AdaBoostClassifier(estimator=base_model, n_estimators=50)
# After training, multiple weak classifiers are weighted into a strong model
model.fit(X_train, y_train)This code demonstrates the core idea of AdaBoost: repeatedly stack weak learners and focus on previously misclassified samples.
 AI Visual Insight: This image typically shows the iterative Boosting workflow: sample weight updates, sequential training of weak classifiers, and final weighted aggregation of outputs. The key technical point is that misclassified samples receive more attention in subsequent rounds.
AI Visual Insight: This image typically shows the iterative Boosting workflow: sample weight updates, sequential training of weak classifiers, and final weighted aggregation of outputs. The key technical point is that misclassified samples receive more attention in subsequent rounds.
The core of classification algorithms is assigning a clear label to a new sample
C4.5 and CART both belong to the decision tree family. C4.5 is more focused on classification tasks and repeatedly selects features with higher gain ratio for splitting. CART is more general-purpose and can output either class labels or continuous numerical predictions.
Naive Bayes works well for text classification and high-dimensional sparse feature scenarios. It infers class probabilities based on Bayes’ theorem. Although its feature independence assumption is strong, it remains efficient and stable in tasks such as spam detection and sentiment analysis.
SVM does not only try to “separate” classes. It aims to separate them with the maximum possible margin. When sample boundaries are complex, it can also use kernel functions to map data into higher-dimensional space, making it well suited for small-sample, high-dimensional problems.
KNN is intuitive, but its computational cost depends on distance search
KNN has no explicit training process. During prediction, it directly finds the nearest K neighbors and uses voting to classify the sample. It is simple to implement, but highly sensitive to feature scaling, distance metrics, and the choice of K.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
# Standardize features first to prevent scale differences from affecting distance calculations
scaler = StandardScaler()
X_train_std = scaler.fit_transform(X_train)
X_test_std = scaler.transform(X_test)
# Use the 5 nearest neighbors for voting-based classification
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train_std, y_train)
print(model.score(X_test_std, y_test))This code reflects the key prerequisite of KNN: normalize feature scales first, then classify based on neighborhood voting.
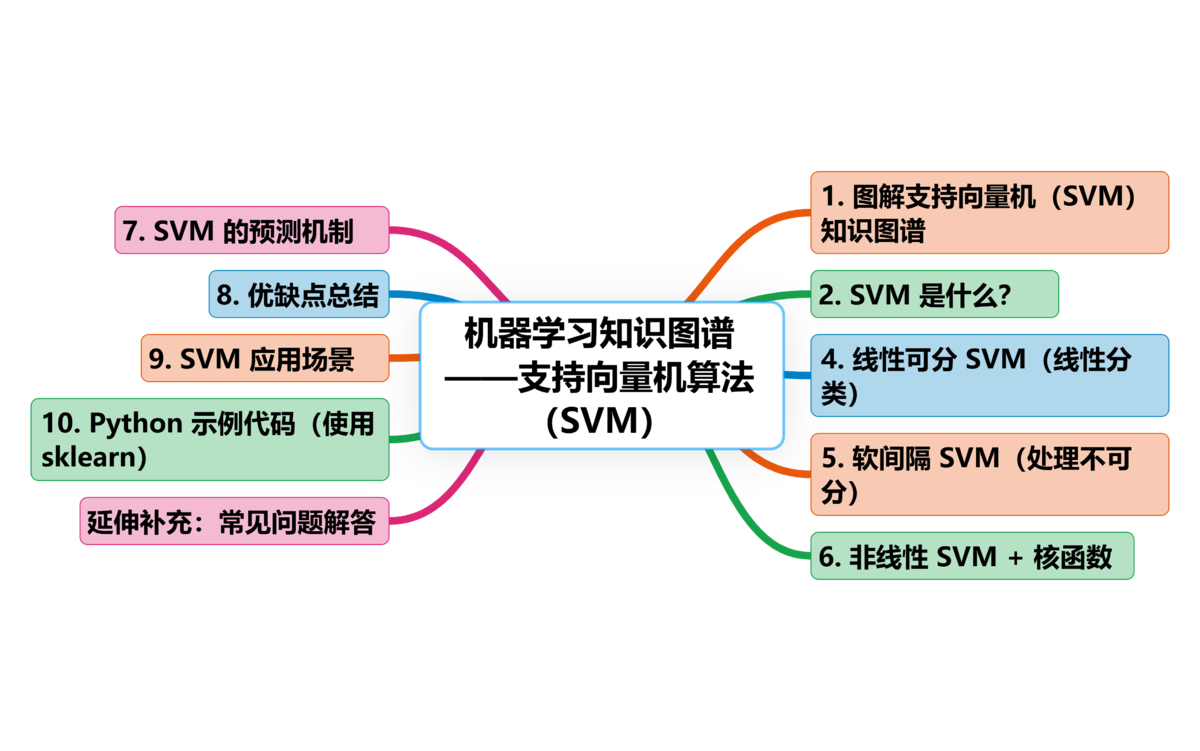 AI Visual Insight: This image is typically used to illustrate either the maximum-margin hyperplane in Support Vector Machines or the neighborhood partitioning effect in KNN. If it is an SVM diagram, the emphasis is on the distance between support vectors and the decision boundary. If it is a KNN diagram, the emphasis is on the class distribution of neighbors around a new sample.
AI Visual Insight: This image is typically used to illustrate either the maximum-margin hyperplane in Support Vector Machines or the neighborhood partitioning effect in KNN. If it is an SVM diagram, the emphasis is on the distance between support vectors and the decision boundary. If it is a KNN diagram, the emphasis is on the class distribution of neighbors around a new sample.
Clustering algorithms are suitable for unlabeled data that still needs automatic grouping
K-Means is the most common unsupervised clustering algorithm. It iteratively repeats the cycle of assigning samples to the nearest centroid and updating centroid positions, making points within a cluster more similar and points across clusters more distinct. It is well suited for user segmentation, store grouping, and product profiling.
EM is more flexible than K-Means. K-Means performs hard assignment, where each sample belongs to exactly one cluster. EM performs soft assignment and outputs the probability that a sample belongs to different clusters, making it more suitable for fuzzy boundaries and mixed-distribution data.
from sklearn.cluster import KMeans
# Partition samples into 3 clusters
model = KMeans(n_clusters=3, random_state=42)
clusters = model.fit_predict(X)
# Output the cluster ID for each sample
print(clusters)This code shows the minimal usage of K-Means: predefine the number of clusters, then let iterative optimization complete the grouping automatically.
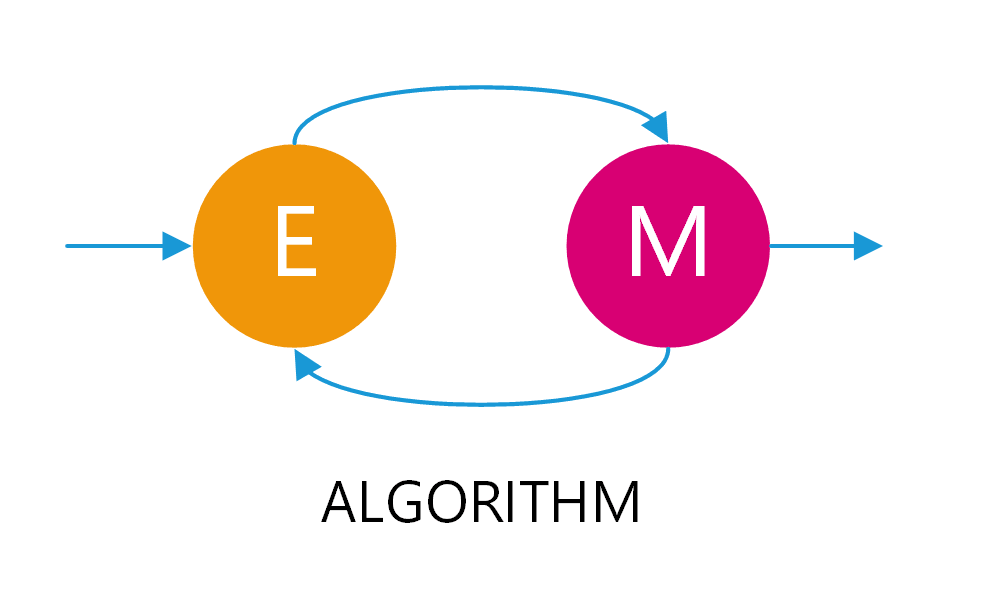 AI Visual Insight: This image usually shows either centroid movement during clustering or probability distribution fitting. If it corresponds to EM, the focus is on the iterative optimization loop in which the E-step computes posterior probabilities of latent variables and the M-step updates parameters.
AI Visual Insight: This image usually shows either centroid movement during clustering or probability distribution fitting. If it corresponds to EM, the focus is on the iterative optimization loop in which the E-step computes posterior probabilities of latent variables and the M-step updates parameters.
Algorithm selection should prioritize task constraints over popularity
If your goal is to predict categories, start with C4.5, CART, Naive Bayes, SVM, KNN, or AdaBoost. If your goal is to discover co-occurrence relationships, start with Apriori. If your goal is automatic grouping, begin with K-Means and EM.
In real-world deployment, data preparation is often more important than the model itself. Missing values, outliers, label noise, and inconsistent feature scales all directly affect mining performance. Many failed projects are not caused by weak algorithms, but by insufficient input data quality.
FAQ
1. What is the relationship between data mining and machine learning?
Data mining is the goal: it emphasizes discovering knowledge from data. Machine learning is the method: it emphasizes enabling models to learn patterns from data. Many data mining tasks are completed using machine learning algorithms, but the two are not exactly the same.
2. Which algorithms should beginners learn first?
Start with decision trees, Naive Bayes, KNN, K-Means, and Apriori. Together, these algorithms cover the three main tracks of classification, clustering, and association analysis, and their concepts are intuitive enough to help you build a complete mental model.
3. Why can the same dataset produce very different results with different algorithms?
Because different algorithms make different assumptions. SVM depends on margin maximization, KNN depends on distance, Naive Bayes depends on probabilistic independence assumptions, and K-Means depends on centroid-based cluster structure. Once the data distribution changes, the results can change significantly.
Core Summary: This article uses a structured approach to explain the core concepts of data mining and 10 classic algorithms, including PageRank, Apriori, AdaBoost, C4.5, CART, Naive Bayes, SVM, KNN, K-Means, and EM, helping developers quickly build a conceptual framework for classification, clustering, and association analysis.