Elasticsearch simdvec is the low-level SIMD kernel library in Elasticsearch’s vector retrieval path. Its core value is to push distance computation close to hardware limits while sustaining high throughput under cache misses and main-memory access. It removes Java vector search bottlenecks across multi-format quantization, bulk scoring, and cross-architecture optimization. Keywords: Elasticsearch, SIMD, vector search.
Technical specifications show the project’s execution model
| Parameter | Details |
|---|---|
| Project | Elasticsearch simdvec |
| Core languages | C++, Java |
| Invocation model | Panama FFI |
| Target architectures | x86 AVX2/AVX-512, ARM NEON |
| Typical scenarios | HNSW, IVF, reranking, disk scoring |
| Supported vector types | float32, int8, bfloat16, int4, binary, BBQ |
| Reference comparisons | FAISS, jvector, NumKong |
| Repository popularity | No standalone Star count provided in the source; code is merged into the main Elasticsearch repository |
| Core dependencies | JDK 25.0.2, JMH 1.37, GCC 14, Google Benchmark |
simdvec is designed for maximum performance, not generality
Every vector query in Elasticsearch repeatedly executes distance computations. Whether the system is traversing an HNSW graph, scanning IVF candidates, or reranking results, the hot path is always the same: score one query vector against a large set of candidate vectors.
That means the bottleneck is not only algorithmic complexity. It also includes instruction throughput, cache hit rate, the ability to hide memory latency, and the quality of SIMD implementations across different quantized data types. simdvec exists to push this path as close to hardware limits as possible.
 AI Visual Insight: This image serves as the article’s main visual. It emphasizes simdvec’s role as Elasticsearch’s vector distance computation engine and highlights its strong connection to low-level CPU SIMD optimization, vector retrieval execution paths, and high-performance search infrastructure.
AI Visual Insight: This image serves as the article’s main visual. It emphasizes simdvec’s role as Elasticsearch’s vector distance computation engine and highlights its strong connection to low-level CPU SIMD optimization, vector retrieval execution paths, and high-performance search infrastructure.
simdvec was built in-house because generic solutions do not cover the full requirement set
Elastic initially evolved from Lucene’s Panama Vector API path, but it quickly ran into practical limits. The issue was not that float32 was too slow. The issue was that production-grade vector retrieval requires support for multiple quantization formats, bulk scoring, direct reads from mmap-backed memory, and stable performance across both x86 and ARM.
Existing libraries usually cover only part of that surface area. Some are strong at single-pair computation but do not provide bulk APIs. Some are highly optimized for x86 but lack native ARM NEON kernels. Others prioritize numerical precision at the cost of high-dimensional throughput. Building simdvec in-house was fundamentally about reclaiming control over Elasticsearch’s own performance path.
// Simplified example: score multiple vectors at once to hide memory latency
for (int d = 0; d < dims; d += 16) {
prefetch(doc_ptr + d + 64); // Prefetch the next document vector segment to reduce cache misses
q = load_query_block(query + d); // Load the query vector block only once
acc0 += dot(q, load_doc_block(doc0 + d)); // Accumulate multiple candidate vectors in parallel
acc1 += dot(q, load_doc_block(doc1 + d));
}This snippet captures simdvec’s core idea: share query loads, accumulate in parallel, and actively hide memory latency.
simdvec stands out in the ecosystem because it is complete
The original article compares simdvec with three reference points: jvector, FAISS, and NumKong. They represent the Java Vector API path, the traditional high-performance ANN kernel path, and the large-scale handwritten SIMD kernel path.
What makes simdvec distinctive is not that it always wins every single benchmark. Its real strength is that it closes the loop for Elasticsearch’s production workloads: it supports all mainstream vector types, can be called from Java with low overhead, and balances both single-pair computation and bulk scoring.
The benchmarking methodology is directly comparable
simdvec and jvector were benchmarked with JMH, including FFI invocation overhead. FAISS and NumKong were measured with Google Benchmark on native C/C++ paths. The metric was normalized to ns/op, and hardware performance counters were used to confirm that SIMD instructions were actually active.
 AI Visual Insight: This image shows the benchmark software environment, including JDK, JMH, GCC, and Google Benchmark versions. It demonstrates that the results come from a reproducible engineering stack rather than abstract estimation, which makes the comparison practically useful.
AI Visual Insight: This image shows the benchmark software environment, including JDK, JMH, GCC, and Google Benchmark versions. It demonstrates that the results come from a reproducible engineering stack rather than abstract estimation, which makes the comparison practically useful.
simdvec is already close to top-tier implementations in single-pair vector computation
In the 1024-dimensional float32 dot-product benchmark, FAISS AVX-512 on x86 runs at roughly 23 ns, while simdvec AVX-512 runs at roughly 28 ns. The gap mainly does not come from a weaker kernel. It comes from the single-digit nanosecond cost introduced by Java FFI.
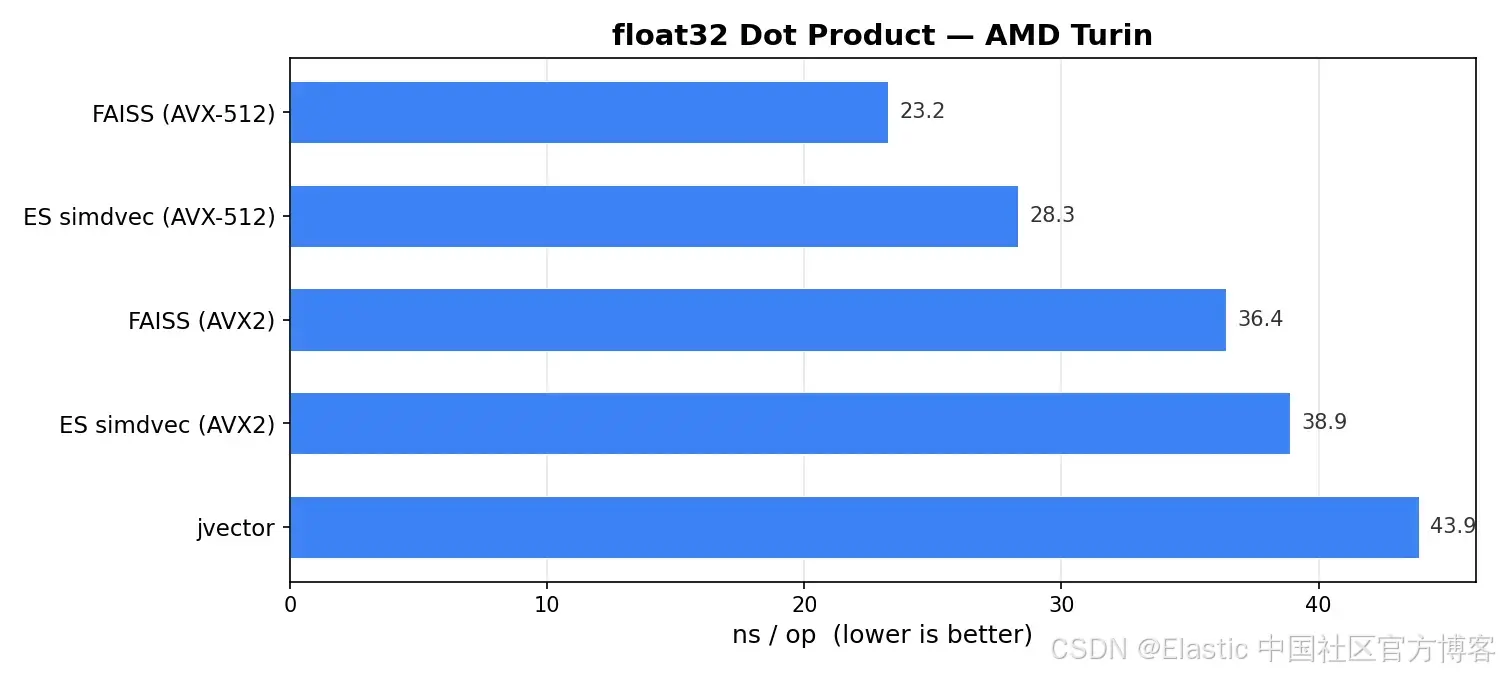 AI Visual Insight: This image compares float32 single-pair scoring latency on x86. It shows the nanosecond-level differences across AVX-512 and AVX2 implementations, and highlights that simdvec remains close to FAISS’s native ceiling even after introducing FFI.
AI Visual Insight: This image compares float32 single-pair scoring latency on x86. It shows the nanosecond-level differences across AVX-512 and AVX2 implementations, and highlights that simdvec remains close to FAISS’s native ceiling even after introducing FFI.
On ARM, simdvec actually leads. Its hand-tuned NEON kernel reaches about 70 ns, outperforming jvector at about 110 ns and FAISS at about 156 ns. This shows that Elastic invested in genuinely deep native optimization for ARM environments such as Graviton.
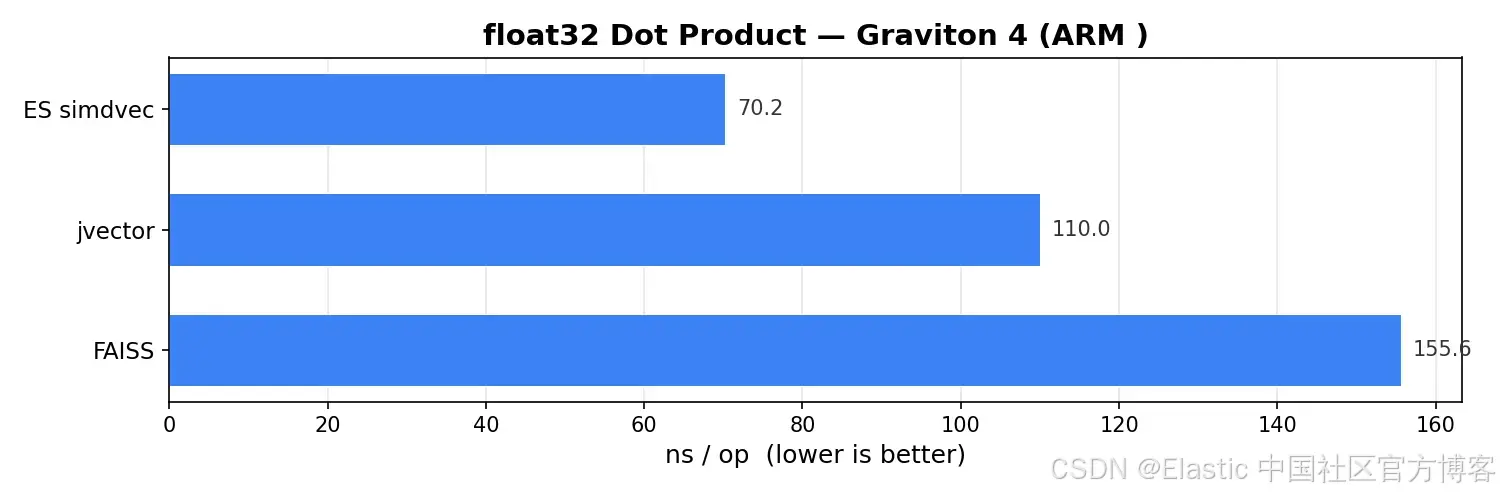 AI Visual Insight: This image presents float32 single-pair scoring results on ARM. Technically, it shows that explicit NEON intrinsics can significantly reduce per-vector latency on aarch64 compared with approaches that rely on auto-vectorization or the Java Panama path.
AI Visual Insight: This image presents float32 single-pair scoring results on ARM. Technically, it shows that explicit NEON intrinsics can significantly reduce per-vector latency on aarch64 compared with approaches that rely on auto-vectorization or the Java Panama path.
int8 and quantized vector formats are where simdvec delivers even more value
Production retrieval does not stay on float32 alone. int8 can reduce memory usage by 4x, bfloat16 by 2x, and BBQ by as much as 32x. More compression means more candidates fit in memory and cache pressure drops, but kernel implementation becomes much more complex.
In int8 single-pair scoring, NumKong has a slight edge at low dimensions because pure C invocation overhead is lower. But as dimensionality increases, simdvec gradually catches up and overtakes it through more efficient cascade unrolling. The crossover point falls roughly between 768 and 1536 dimensions.
 AI Visual Insight: This image compares int8 single-pair scoring across dimensions and architectures. It reveals the tradeoff between call overhead and kernel unrolling strategy: low-dimensional performance is dominated by interface cost, while high-dimensional performance is dominated by SIMD kernel efficiency.
AI Visual Insight: This image compares int8 single-pair scoring across dimensions and architectures. It reveals the tradeoff between call overhead and kernel unrolling strategy: low-dimensional performance is dominated by interface cost, while high-dimensional performance is dominated by SIMD kernel efficiency.
// Call the native SIMD kernel from Java through Panama FFI
float score = SimdVecBindings.dotInt8(
queryAddress, // Query vector memory address
docAddress, // Candidate vector memory address
dims // Vector dimensionality
);This call demonstrates the key engineering choice behind simdvec: keep the Java ecosystem, but push the heavy computation down into native code.
The real performance gap comes from bulk scoring, not single-pair throughput
A fast single-pair kernel does not automatically make real-world retrieval fast. HNSW, IVF, and reranking all require continuous scoring over hundreds or thousands of candidates. At that point, the bottleneck shifts from arithmetic execution to whether the system can efficiently reuse the query vector, reduce memory wait time, and sustain throughput across cache boundaries.
simdvec’s bulk scoring is not just a simple loop wrapper. It uses a multi-accumulator architecture: load a query block once, accumulate against multiple document vectors at the same time, and proactively prefetch future cache lines.
simdvec’s advantage expands under large working sets
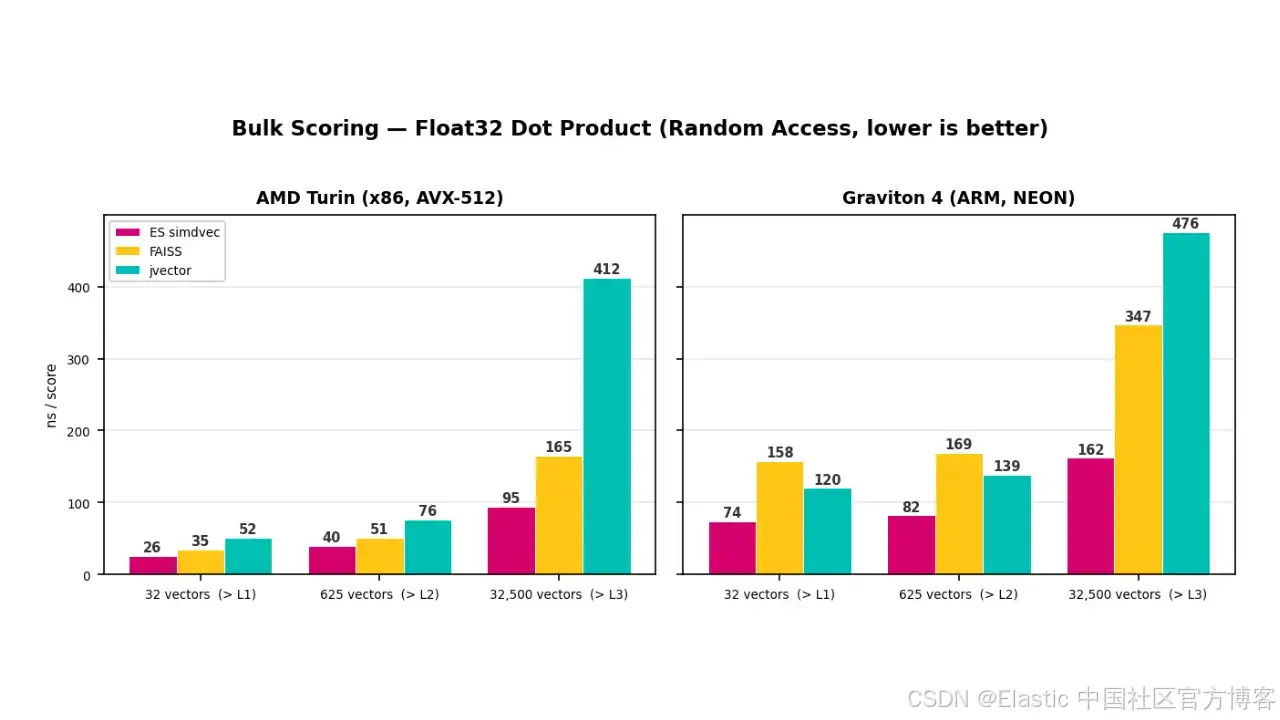
In float32 bulk experiments, the working set grows from cache-resident sizes to sizes beyond L3. On x86, simdvec reaches roughly 95 ns/vector at the largest scale, compared with roughly 165 ns for FAISS and roughly 412 ns for jvector. On ARM, the figures are roughly 162 ns, 347 ns, and 476 ns respectively.
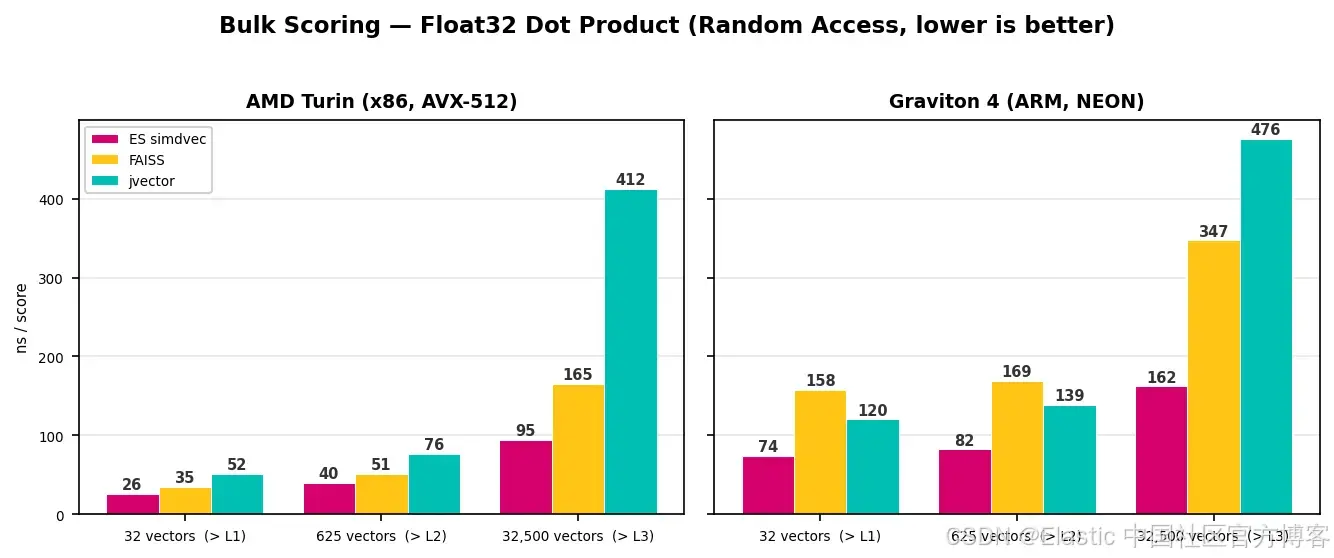 AI Visual Insight: This image shows latency changes in float32 bulk scoring under different cache-pressure levels. It clearly illustrates that simdvec maintains a smoother degradation curve after exceeding L3 cache, which proves that its optimization focus is memory access, not just arithmetic units.
AI Visual Insight: This image shows latency changes in float32 bulk scoring under different cache-pressure levels. It clearly illustrates that simdvec maintains a smoother degradation curve after exceeding L3 cache, which proves that its optimization focus is memory access, not just arithmetic units.
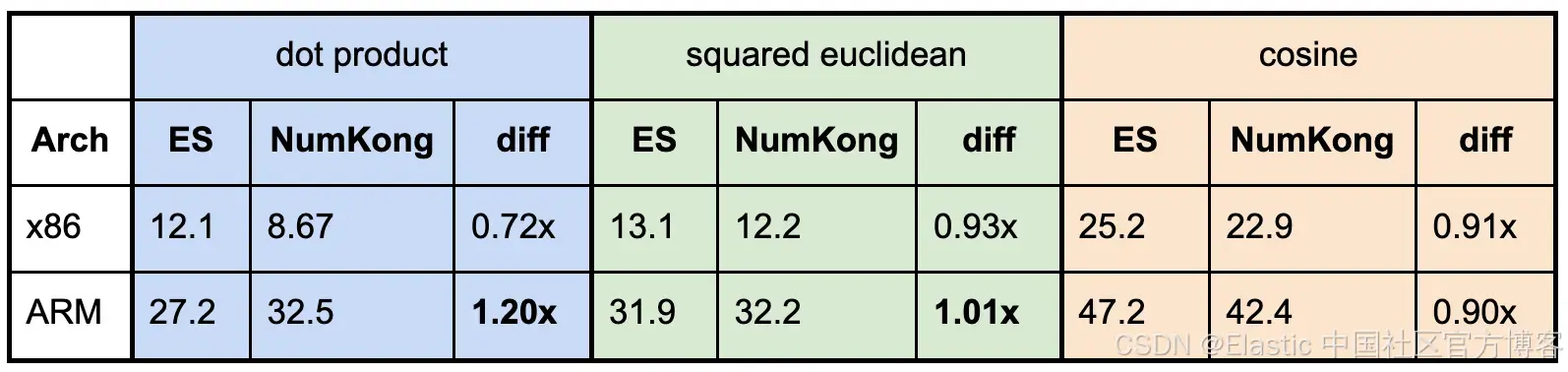
int8 bulk scoring shows the same trend. On x86, simdvec improves over NumKong by roughly 1.2x to 1.9x. On ARM, the gain is roughly 1.7x to 1.9x. Most importantly, the closer the workload gets to production scale, the more stable the advantage becomes.
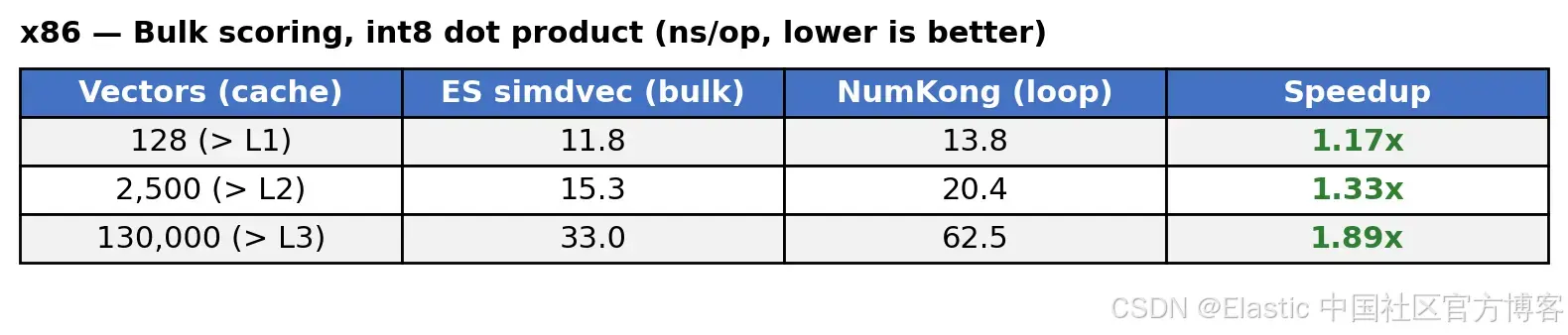 AI Visual Insight: This image reflects how int8 bulk scoring changes with data size on x86. It shows that explicit prefetching and query-vector amortization significantly reduce average per-vector processing time once cache locality breaks down.
AI Visual Insight: This image reflects how int8 bulk scoring changes with data size on x86. It shows that explicit prefetching and query-vector amortization significantly reduce average per-vector processing time once cache locality breaks down.
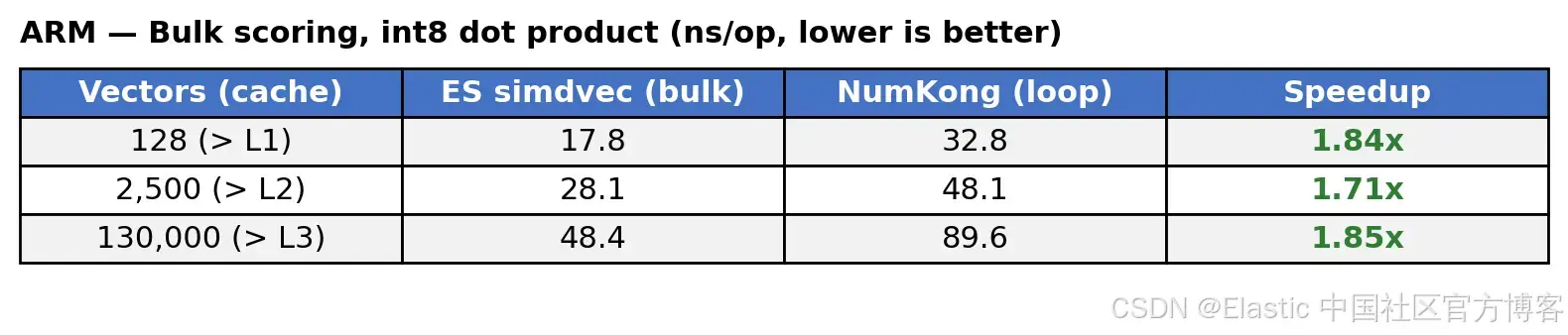 AI Visual Insight: This image presents int8 bulk scoring results on ARM. Its core technical message is that interleaving multiple vector streams increases memory-level parallelism during out-of-order execution, which helps sustain throughput during main-memory access.
AI Visual Insight: This image presents int8 bulk scoring results on ARM. Its core technical message is that interleaving multiple vector streams increases memory-level parallelism during out-of-order execution, which helps sustain throughput during main-memory access.
x86 and ARM require different optimization strategies
One of the most valuable conclusions in the article is that hiding memory latency cannot rely on a single strategy across all CPUs. x86 benefits more from explicit prefetching: pull future data into L1 early and reduce cache misses. ARM depends more on interleaved loads, allowing the out-of-order engine to track multiple memory streams at once.
 AI Visual Insight: This image shows hardware counter changes after enabling explicit prefetching on x86. It indicates a clear drop in cache misses and a rise in IPC, proving that prefetching translates directly into throughput gains in DRAM-bound scenarios.
AI Visual Insight: This image shows hardware counter changes after enabling explicit prefetching on x86. It indicates a clear drop in cache misses and a rise in IPC, proving that prefetching translates directly into throughput gains in DRAM-bound scenarios.
 AI Visual Insight: This image shows how interleaved loading reduces backend stalls on ARM. It suggests that the gain on ARM comes mainly from better pipeline utilization rather than simply reducing cache misses.
AI Visual Insight: This image shows how interleaved loading reduces backend stalls on ARM. It suggests that the gain on ARM comes mainly from better pipeline utilization rather than simply reducing cache misses.
for (int d = 0; d < dims; d += 16) {
v0 = load(doc0 + d); // Interleaved load of the first vector block
v1 = load(doc1 + d); // Interleaved load of the second vector block
v2 = load(doc2 + d); // Interleaved load of the third vector block
v3 = load(doc3 + d); // Interleaved load of the fourth vector block
// Let the CPU keep working on other vectors while one memory stream is waiting
}This pseudocode summarizes the ARM path: it is not about fetching data faster, but about keeping execution units from going idle.
Elasticsearch users will see the gains directly in latency and throughput
A single vector query often includes millions of distance computations. Saving a few nanoseconds here compounds into lower P99 latency, higher QPS, and lower hardware cost in a high-concurrency cluster.
More importantly, simdvec is not a one-time optimization. As new quantization formats and new hardware platforms enter Elasticsearch, they can gain dedicated SIMD kernels from day one. That gives Elasticsearch vector retrieval a durable performance moat that can keep evolving.
FAQ
Q1: Why doesn’t simdvec simply reuse FAISS?
A1: Because Elasticsearch needs more than high-performance float32 single-pair scoring. It also needs int8, bfloat16, BBQ, bulk scoring, direct mmap reads from disk, Java FFI integration, and native ARM optimization. FAISS does not cover that full requirement set in one package.
Q2: Doesn’t FFI cancel out the gains of native SIMD?
A2: No. The original article’s conclusion is that FFI overhead is only a few nanoseconds. In high-dimensional or bulk-scoring scenarios, that cost is quickly amortized by a more efficient SIMD kernel and better memory-access optimization.
Q3: Where does simdvec’s biggest performance advantage come from?
A3: Not from making a single dot product marginally faster, but from hiding memory latency at scale through query amortization, explicit prefetching, and interleaved loading. The advantage is most obvious once the working set exceeds CPU cache.
The conclusion is already clear
simdvec’s real breakthrough is not posting the absolute best result in a single benchmark. It is building a complete SIMD engine around Elasticsearch’s real query path: one that spans multiple data types, multiple architectures, bulk scoring, and main-memory latency.
For modern vector search systems, that matters more than isolated benchmark wins. In production, the winner is the system that can keep the CPU busy even after cache misses begin.
AI Readability Summary: This article reconstructs and analyzes Elasticsearch’s in-house simdvec vector kernel, explaining how AVX-512, NEON, bulk scoring, explicit prefetching, and interleaved loading reduce latency across HNSW, IVF, and reranking workloads. It also shows why simdvec performs especially well on ARM and under large-scale memory-bound access patterns.