This is an anti-scam assistant deployed on Rokid smart glasses. It uses three input channels—voice, image, and conversational text—to issue high-risk warnings while a scam is still in progress, and then switches to a recovery workflow after a user has already transferred money. It solves a major limitation of traditional anti-fraud tools: they only support post-incident lookup and cannot interrupt the scam in real time. Keywords: Rokid, fraud detection, multimodal workflow.
Technical Specifications Snapshot
| Parameter | Details |
|---|---|
| Runtime Device | Rokid smart glasses |
| Build Platform | Lingzhu platform |
| Input Modes | Voice, image, conversational text |
| Output Constraints | Risk level, scam type, reason, recovery guidance |
| Interaction Features | Real-time alerts, automatic first-round photo capture, short pop-up messages |
| Coordination Protocol | Audio transcription + image analysis + workflow node orchestration |
| GitHub Stars | Not disclosed in the source |
| Core Dependencies | LLM nodes, camera plugin, search plugin, speech transcription |
This system is designed to interrupt scams in progress, not just look them up afterward
The most important moment in the original case is that the glasses display “High Risk” directly during the call. That means the system’s value does not come from knowledge base retrieval. It comes from real-time intervention. Traditional anti-fraud apps usually depend on users to proactively search for answers, but under high-pressure social engineering, victims rarely pause to verify what they are being told.
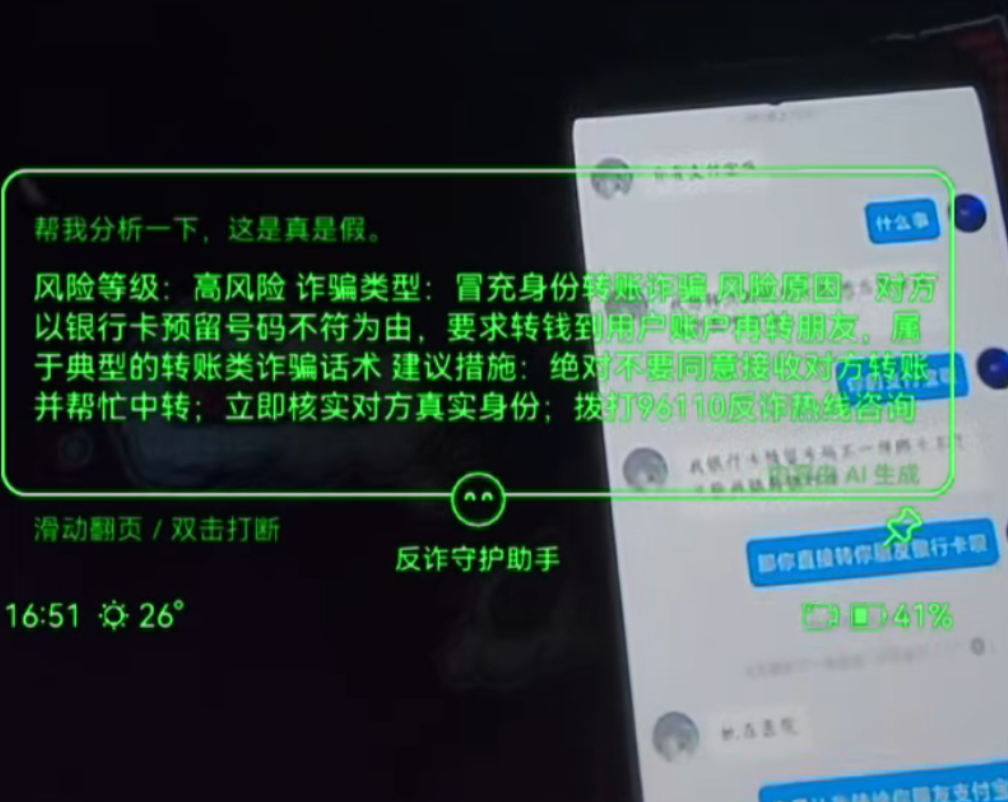 AI Visual Insight: The image shows alert text such as “High Risk” and “identity impersonation transfer scam” directly overlaid in the AR view. This indicates that the recognition result has been compressed into instantly readable short text and can interrupt the foreground experience during a live call.
AI Visual Insight: The image shows alert text such as “High Risk” and “identity impersonation transfer scam” directly overlaid in the AR view. This indicates that the recognition result has been compressed into instantly readable short text and can interrupt the foreground experience during a live call.
Scenarios like this require the system to perceive and judge risk before the user does
The author emphasizes that the project was not created to chase trends. It was designed specifically for continuous scam patterns such as “customer service,” “account anomaly,” and “test transfer” narratives. The real detection target is not a single keyword. It is the combination of multiple dangerous signals appearing together.
risk_signals = ["验证码", "马上操作", "不要告诉别人", "转账测试"]
text = "你的账户异常,现在马上操作,把验证码发我,不要告诉别人"
# Raise the risk level immediately when multiple high-risk signals appear together
score = sum(1 for s in risk_signals if s in text)
level = "高风险" if score >= 2 else "低风险"
print(level)This logic shows that the core of the system is not single-keyword matching. It escalates risk based on combined features.
The solution uses multimodal input to compensate for the fact that users rarely report scams proactively
The project keeps only three input types on the Lingzhu platform: voice, image, and dialogue. This is a disciplined constraint, but it is enough to cover the most common information carriers during a scam. In particular, automatic photo capture in the first interaction round is a key design decision for wearable anti-fraud scenarios.
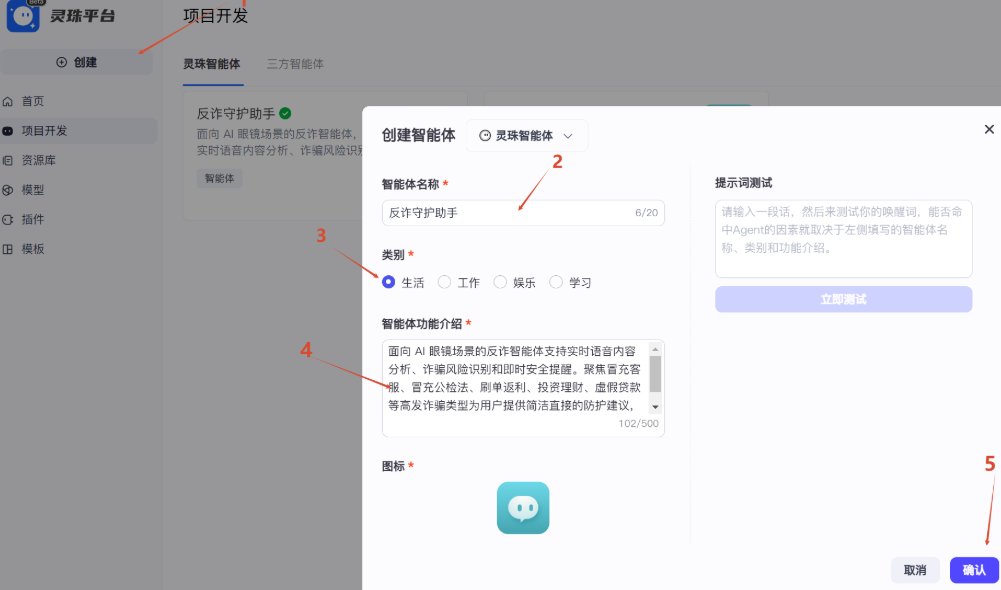 AI Visual Insight: The interface shows the base configuration entry points for the agent, which indicates that this is not just a single prompt. It is a complete agent-style application with input channels, capability bindings, and output constraints.
AI Visual Insight: The interface shows the base configuration entry points for the agent, which indicates that this is not just a single prompt. It is a complete agent-style application with input channels, capability bindings, and output constraints.
 AI Visual Insight: The diagram emphasizes two fixed fields—”risk level” and “scam type”—showing that the output template is structurally constrained. This prevents the model from generating verbose, vague, and non-actionable natural language.
AI Visual Insight: The diagram emphasizes two fixed fields—”risk level” and “scam type”—showing that the output template is structurally constrained. This prevents the model from generating verbose, vague, and non-actionable natural language.
The rules are not learned through training but iterated manually over time
The author explicitly states that the rules are handwritten. For example, changing “collect on behalf + forward” from low risk to high risk is a typical experience-based correction. This approach may not look elegant, but it fits high-consequence scenarios better because it is explainable, auditable, and fast to patch.
def classify_transfer_case(has_collect, has_forward):
# Collecting funds and forwarding them is a typical money-mule pattern and should be escalated immediately
if has_collect and has_forward:
return "高风险", "中转洗钱/代收转发诈骗"
return "中低风险", "需继续观察"This code reflects the idea of a manually maintained rule base rather than fully relying on model self-learning.
Image and voice capabilities improve coverage, but they also introduce boundary problems
Image input makes it possible for the glasses to “see.” Users may not proactively submit screenshots, but the camera can capture chat pages, QR codes, verification-code messages, or transfer screens. For passive warning, this is a major advantage.
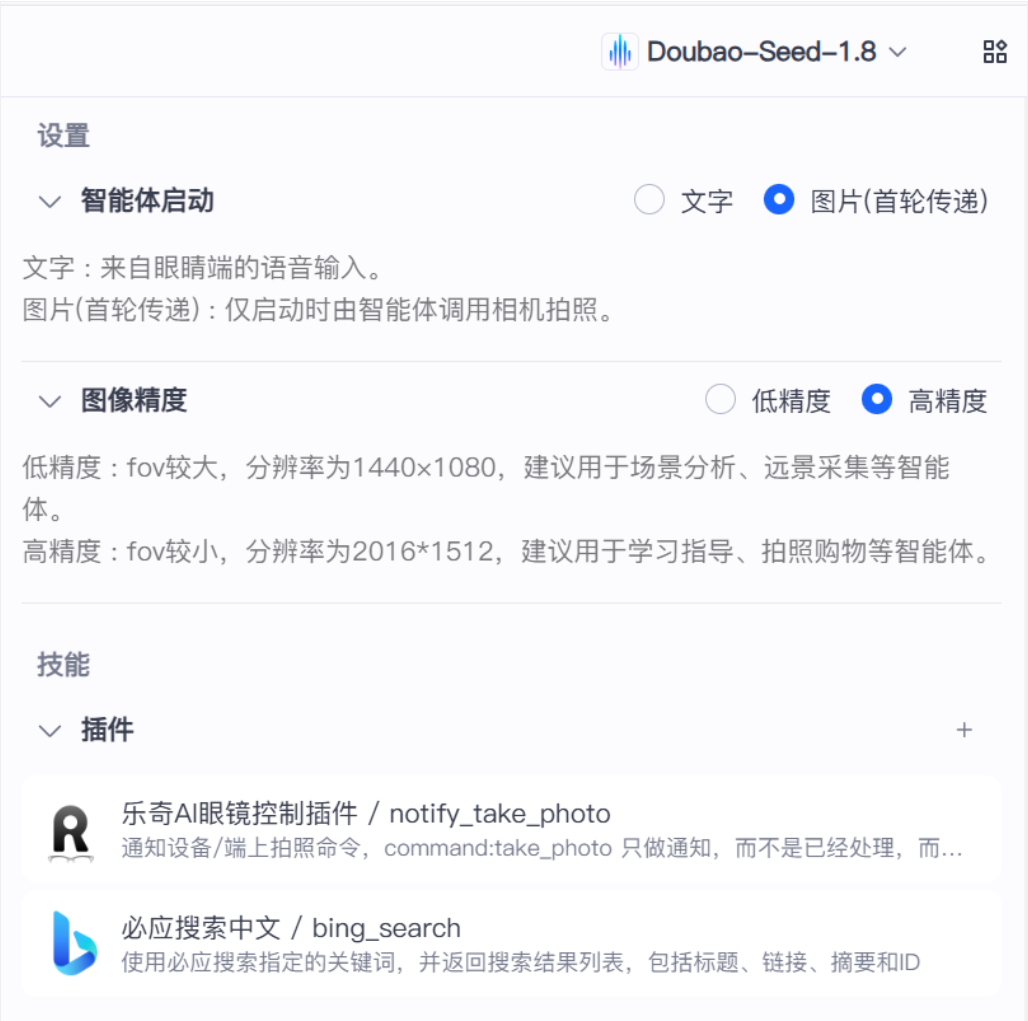 AI Visual Insight: This image highlights the camera’s ability to continuously sample the surrounding environment. It suggests that the system can warn not only based on content deliberately submitted by the user, but also by extracting scam language from visible external text.
AI Visual Insight: This image highlights the camera’s ability to continuously sample the surrounding environment. It suggests that the system can warn not only based on content deliberately submitted by the user, but also by extracting scam language from visible external text.
However, the author also points out that the system cannot accurately determine whether the current scene actually belongs to the user. That creates a false-positive boundary: the system may detect dangerous text, but that text may not truly be relevant to the user.
Low latency is the minimum requirement for usability, not a nice-to-have feature
Speech transcription still has a 1 to 2 second delay, which is already tight in a payment scenario. That means the system must judge early instead of waiting for the full semantic loop to complete. The output message must also stay extremely short while still preserving one clear reason.
result = {
"risk_level": "高风险",
"reason": "对方索要验证码", # The explanation must be short and actionable
"action": "立即停止操作"
}This kind of compact output structure fits AR overlays well and does not slow user comprehension.
Once a loss has occurred, the system must switch from warning mode to recovery mode
The most valuable upgrade in the second half of the project is the extraction of a dedicated recovery workflow for the question: “What should I do if I already transferred the money?” At this stage, the goal is no longer to decide whether risk exists. It is to determine whether damage has already happened. This is a critical step for anti-fraud products moving from detection into response.
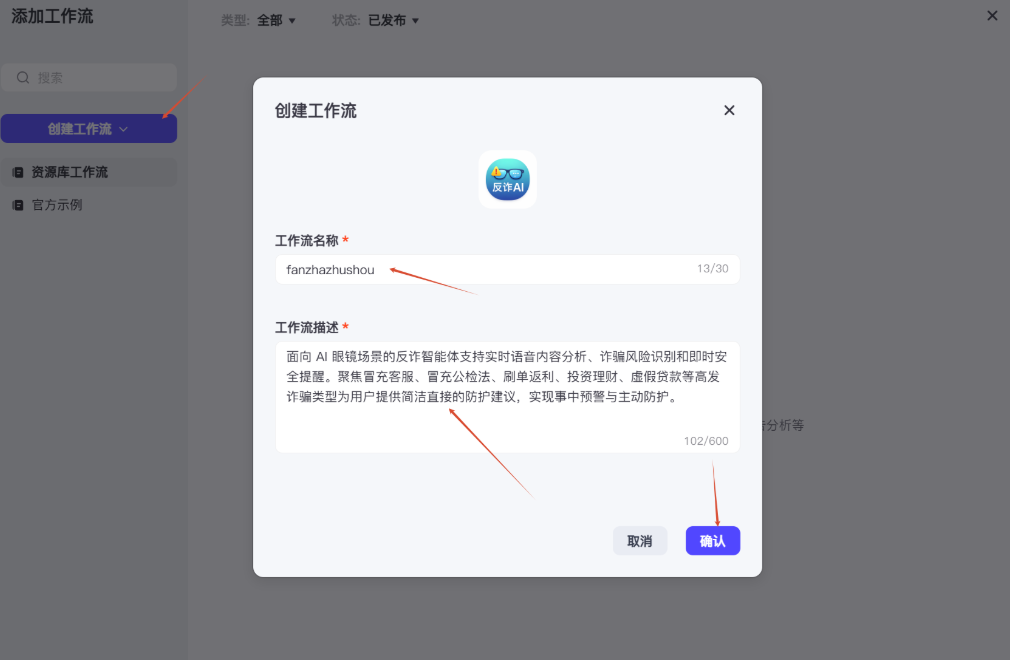 AI Visual Insight: The image shows the node-based workflow orchestration interface on the Lingzhu platform. It indicates that the system has evolved from single-turn Q&A into a process-driven application with state routing, node passing, and final result return.
AI Visual Insight: The image shows the node-based workflow orchestration interface on the Lingzhu platform. It indicates that the system has evolved from single-turn Q&A into a process-driven application with state routing, node passing, and final result return.
 AI Visual Insight: The screen shows a separate LLM node handling recovery judgment, which means the workflow has explicitly split “risk detection” and “recovery guidance generation” into separate process steps for easier maintenance and extension.
AI Visual Insight: The screen shows a separate LLM node handling recovery judgment, which means the workflow has explicitly split “risk detection” and “recovery guidance generation” into separate process steps for easier maintenance and extension.
The input is split into text variables and image variables
The text variable receives USER_INPUT, and the image variable receives USER_INPUT_IMAGE. The value of this design is that even if the user does not explicitly say “I was scammed,” the visual context may already reveal severe risk.
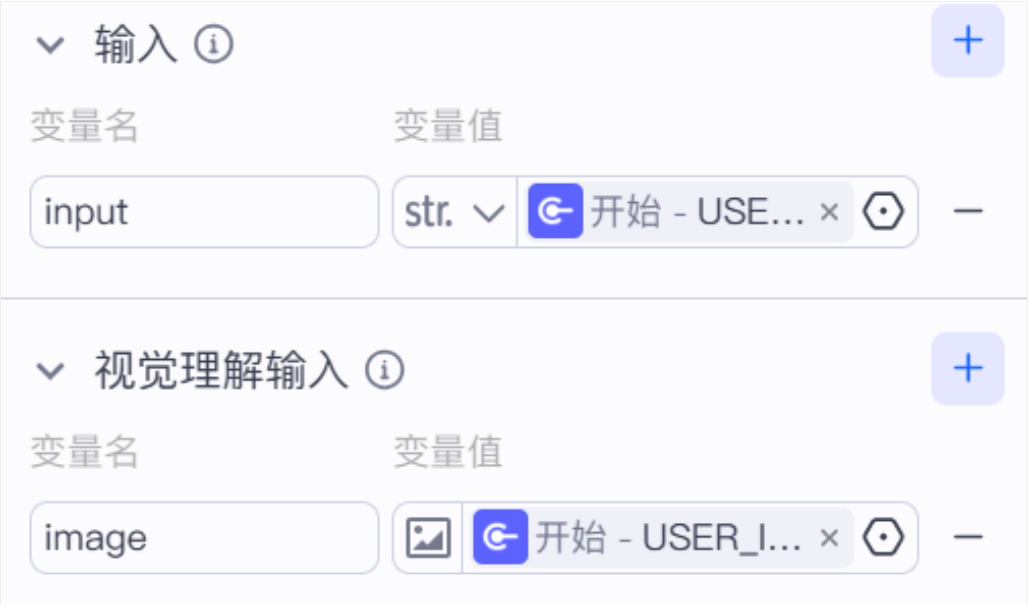 AI Visual Insight: This image shows text and image variables bound separately to the workflow start node, demonstrating that the system models multimodal data explicitly at the workflow layer instead of mixing everything implicitly into one prompt.
AI Visual Insight: This image shows text and image variables bound separately to the workflow start node, demonstrating that the system models multimodal data explicitly at the workflow layer instead of mixing everything implicitly into one prompt.
def route_case(text, image_detected):
# If money has already been transferred or key credentials have been exposed, enter the recovery workflow
keywords = ["已经转账", "验证码发过去了", "银行卡给他了"]
if any(k in text for k in keywords) or image_detected:
return "remedy_workflow"
return "risk_alert_workflow"This logic reflects the system’s core routing strategy: warning and recovery are two different paths.
The system prompt and output structure are tightly constrained to ensure actionable results
The model prompt prioritizes one judgment above all: whether damage has already happened. Once it detects a transfer, verification code disclosure, or leakage of bank card or identity information, it should immediately enter recovery guidance instead of continuing with vague reminders to “stay cautious.”
 AI Visual Insight: The image shows that the model prompt includes priority conditions for “loss already occurred” scenarios, meaning the prompt acts as a workflow decision-maker rather than a generic chat instruction.
AI Visual Insight: The image shows that the model prompt includes priority conditions for “loss already occurred” scenarios, meaning the prompt acts as a workflow decision-maker rather than a generic chat instruction.
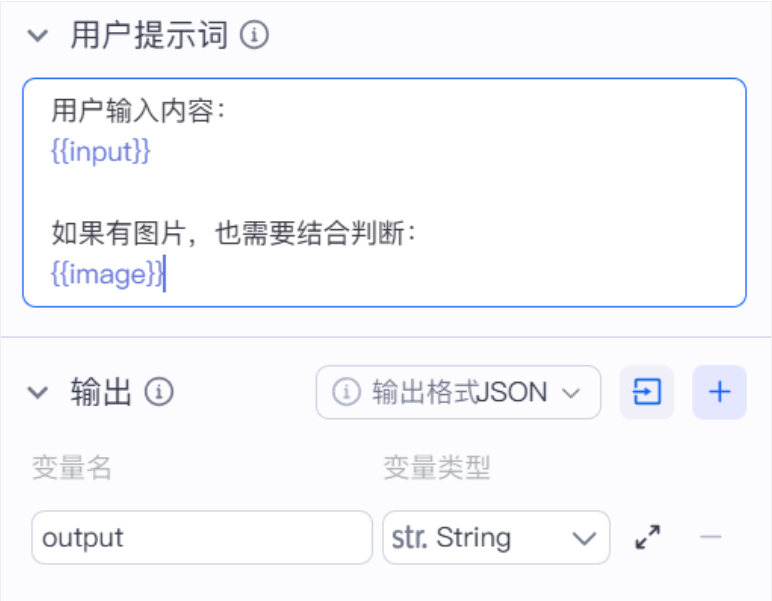 AI Visual Insight: The output keeps only a single string variable, but inside it still contains risk status, level, reason, and recovery guidance. This shows that the front-end display is intentionally simplified while semantic structure remains intact.
AI Visual Insight: The output keeps only a single string variable, but inside it still contains risk status, level, reason, and recovery guidance. This shows that the front-end display is intentionally simplified while semantic structure remains intact.
A minimum viable recovery output should include five fields
output = {
"risk_status": "已发生损失",
"risk_level": "高风险",
"reason": "用户已完成转账并泄露验证码",
"remedy": ["停止继续操作", "保留证据", "联系银行止付", "拨打96110或110"],
"glass_hint": "高风险,立即止付并报警"
}This type of result works both for detailed explanation on a larger screen and for generating a short, executable hint on the glasses.
Runtime testing shows that the system already forms a closed loop from detection to response
The author validates the recovery workflow using simulated inputs such as “I already transferred the money,” and the system can output the next recommended actions. This shows that the project has moved beyond a proof of concept into a prototype that can be tested and demonstrated.
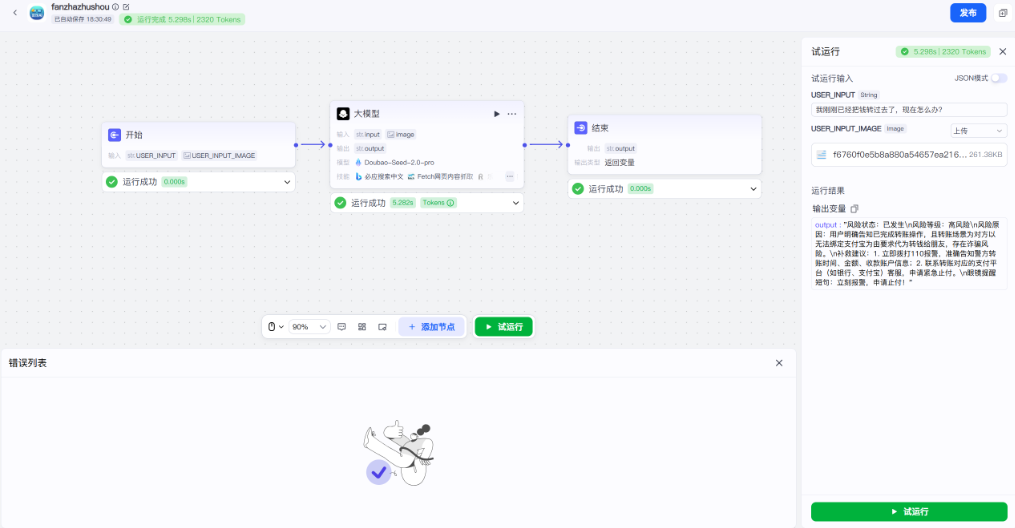 AI Visual Insight: This image shows the result panel after successful workflow execution, indicating that input handling, node reasoning, and output return have already formed a complete chain suitable for prototype validation and scenario demos.
AI Visual Insight: This image shows the result panel after successful workflow execution, indicating that input handling, node reasoning, and output return have already formed a complete chain suitable for prototype validation and scenario demos.
 AI Visual Insight: The screen shows the system outputting recovery instructions when the condition “money already transferred” is met, proving that the agent not only detects risk but also provides immediate emergency guidance for ordinary users.
AI Visual Insight: The screen shows the system outputting recovery instructions when the condition “money already transferred” is met, proving that the agent not only detects risk but also provides immediate emergency guidance for ordinary users.
The engineering takeaway is that wearable AI is better suited to time-critical, high-intervention scenarios
The most valuable part of this solution is not how powerful the model is. It is how tightly the design fits the scenario. Smart glasses naturally provide a visual entry point, an audio entry point, and an instant display output. For tasks that must produce results in the moment—such as fraud prevention, navigation, alerts, and translation—this type of device is clearly better suited than passive mobile apps.
FAQ
Q1: Why does this project use handwritten rules instead of relying entirely on a large model for judgment?
A1: Fraud detection is a high-consequence scenario, and the cost of misjudgment is high. Handwritten rules are explainable, auditable, and quick to correct. They are especially suitable for strong-pattern behaviors such as “collect and forward” schemes and requests for verification codes.
Q2: Why is image input a critical capability?
A2: Users usually do not proactively capture and submit evidence, but smart glasses can automatically see chats, QR codes, and transfer screens. Image input gives the system passive perception and lets it move the warning point earlier in the interaction.
Q3: What is the biggest technical limitation of this solution right now?
A3: First, speech transcription still has a 1 to 2 second delay. Second, the system has difficulty confirming whether what the camera sees is truly related to the user, which affects false-positive control and context attribution.
AI Readability Summary
This article reconstructs an anti-fraud agent built with Rokid smart glasses and the Lingzhu platform. It focuses on multimodal input, combined-signal risk judgment, low-latency alerts, and a post-transfer recovery workflow. It is especially relevant for developers working on AI risk control, wearable computing, and real-time interaction.