This article focuses on two core problems from the 2026 Northeast China Mathematical Modeling League. It distills the modeling pipeline for Problem A—population clustering, forecasting, and policy evaluation—and the integer programming framework for Problem B—staffing and scheduling optimization—to help teams make a fast and informed topic selection. Keywords: mathematical modeling, population forecasting, scheduling optimization.
Technical Snapshot
| Parameter | Details |
|---|---|
| Domain | Mathematical Modeling, Population Analysis, Operations Research Optimization |
| Core Languages | Python, MATLAB, R |
| Typical Protocols/Paradigms | Census Data Analysis, Time Series Forecasting, MILP/ILP |
| GitHub Stars | Not provided in the original source; not applicable |
| Core Dependencies | scikit-learn, pandas, statsmodels, PuLP, Gurobi/CPLEX |
This problem analysis helps teams quickly narrow down their topic choice
The value of the original analysis is not that it provides a standard answer, but that it offers a clear modeling entry point for both problems. Problem A leans toward data-driven analysis and population system modeling, while Problem B focuses on discrete optimization and scheduling. These two problems require very different team skill profiles.
For most teams, topic selection should not depend only on how familiar the problem statement feels. You should also evaluate data cleaning cost, model interpretability, and how easily the work can be turned into a strong paper. If your team is stronger in statistical analysis and machine learning, Problem A is usually the safer option. If your team is stronger in operations research and solver-based optimization, Problem B is more likely to produce structured highlights.
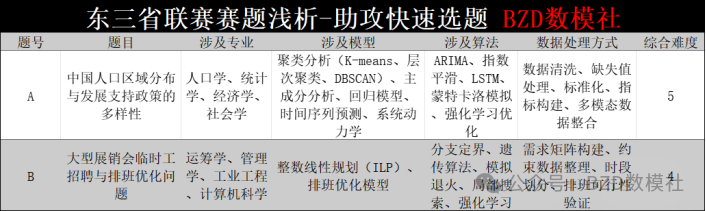 AI Visual Insight: The figure gives an intuitive comparison of problem difficulty and expected participant distribution. The key takeaway is that Problems A and B have roughly similar overall difficulty, with Problem A being slightly harder. This visual signal suggests that the problem setters kept complexity relatively balanced, so teams should choose based on methodological readiness rather than perceived difficulty alone.
AI Visual Insight: The figure gives an intuitive comparison of problem difficulty and expected participant distribution. The key takeaway is that Problems A and B have roughly similar overall difficulty, with Problem A being slightly harder. This visual signal suggests that the problem setters kept complexity relatively balanced, so teams should choose based on methodological readiness rather than perceived difficulty alone.
A minimal decision framework for topic selection
# Quickly recommend a problem based on the team's skill profile
team = {
"data_analysis": 8, # Data analysis capability
"optimization": 6, # Operations research capability
"writing": 7 # Technical writing capability
}
if team["data_analysis"] >= team["optimization"]:
choice = "Problem A" # Focuses on census data, clustering, forecasting, and policy analysis
else:
choice = "Problem B" # Focuses on scheduling optimization, integer programming, and robust scheduling
print(f"Recommended for priority evaluation: {choice}")This snippet shows how to convert a team’s skill structure into an executable first-pass topic selection strategy.
Problem A is better suited to a complete paper built around population structure modeling
Problem A focuses on regional population distribution in China and the diversity of development support policies. Its main advantage is that it naturally supports a complete narrative: classify first, explain next, forecast afterward, and finally compare policy scenarios. This aligns well with the standard four-part structure of a modeling paper.
The key to Question 1 is regional classification. You can build a feature matrix using indicators such as gender composition, age structure, educational attainment, urban-rural composition, and migrant population characteristics, then apply standardization and clustering. K-Means is suitable for producing quick results, hierarchical clustering is easier to interpret, and Gaussian Mixture Models work better when regional boundaries are ambiguous.
The recommended technical route for Problem A should connect classification, drivers, forecasting, and policy
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
X = census_features # Multidimensional census feature matrix
X_std = StandardScaler().fit_transform(X) # Standardize features to remove scale effects
labels = KMeans(n_clusters=4, random_state=42).fit_predict(X_std) # Regional clusteringThis code demonstrates the most common clustering entry point for Question 1 of Problem A.
Question 2 can use panel regression, grey relational analysis, or correlation analysis to identify driving factors. If you want the paper to be more interpretable, you can incorporate SHAP or structural equation modeling to clearly explain the pathway linking education, migration, urbanization, and population change.
Question 3 depends heavily on forecast horizon stratification. For short-term forecasting, ARIMA or grey models are practical choices. For medium- and long-term forecasting, Leslie matrices or system dynamics are usually better because they explicitly represent age structure, fertility, and the transmission mechanism of aging. This is often the key differentiator in high-scoring solutions for Problem A.
High-scoring work on Problem A usually comes from policy quantification rather than forecasting alone
Policy analysis should not stop at statements like “higher fertility will increase population.” A more robust approach maps policy effects into model parameter changes, such as fertility elasticity, migration-rate adjustments, or childcare subsidy conversion factors, and then compares population trajectories under baseline and policy scenarios.
# Illustration of a policy scenario in a Leslie matrix
fertility_base = [0.02, 0.08, 0.05]
policy_factor = 1.12 # The policy increases fertility by 12% in target age groups
fertility_policy = [f * policy_factor for f in fertility_base] # Policy-adjusted fertility ratesThis snippet shows how to convert policy effects into computable model parameters.
Problem B is better suited to a verifiable optimization model centered on integer programming
Problem B focuses on temporary worker recruitment and scheduling optimization for a large trade fair. At its core, this is a workforce scheduling problem. Its strengths are clear constraints, a well-defined objective, and highly verifiable results, which makes it especially suitable for teams that can quickly build credible ILP or MILP models.
Question 1 is the basic 10-day linked scheduling model. Each worker is assigned to one fixed group, works 8 days, rests 2 days, and works 8 consecutive hours each day. You can model each group independently at first. The decision variables are straightforward, which makes this a good baseline formulation.
The difficulty of Problem B grows rapidly once the constraints are relaxed
Question 2 allows workers to switch groups across days. Question 3 allows a worker to serve two groups on the same day, with a mandatory 2-hour break in between. This means the model evolves from a local ILP into a global MILP, and it may even require column generation, set covering, or branch-and-price techniques for efficient solution.
# Pseudocode: staffing demand constraints
for day in days:
for hour in hours:
model += sum(x[w, day, group, shift] for w in workers for group in groups for shift in shifts
if covers(shift, hour)) >= demand[day][group][hour] # Active staff must meet hourly demandThis snippet expresses the core coverage constraint in Problem B: every hourly demand must be covered by valid shifts.
Question 3 offers the largest scoring upside because it naturally introduces set covering, robust optimization, and fairness-aware multi-objective modeling. If the paper can also quantify how many hires are saved through cross-group scheduling, the engineering value becomes much more convincing.
 AI Visual Insight: This image is a promotional poster for a competition support community. Its main message is that participants can receive solution ideas and code support during the contest. From an information design perspective, it targets in-competition coaching scenarios and reflects how strongly these contests depend on reusable modeling templates, solver experience, and paper organization skills.
AI Visual Insight: This image is a promotional poster for a competition support community. Its main message is that participants can receive solution ideas and code support during the contest. From an information design perspective, it targets in-competition coaching scenarios and reflects how strongly these contests depend on reusable modeling templates, solver experience, and paper organization skills.
From a competition strategy perspective, Problem A emphasizes integrated analysis while Problem B emphasizes engineering optimization
Problem A tests data organization, variable interpretation, and narrative-driven conclusions, so it fits teams that are strong at analytical writing. Problem B tests constraint abstraction, model implementation, and computational validation, so it fits teams that are strong at algorithmic problem solving. If your team has limited time, choose the direction where your existing code base is stronger.
A practical rule of thumb is this: if you already have templates for clustering, time series, and regression analysis, Problem A will move faster. If you already have experience with PuLP, Gurobi, or OR-Tools, Problem B is more likely to produce stable results within 48 hours.
FAQ
1. Where do teams most easily lose points on Problem A?
The most common weakness in Problem A is a disconnect between forecasting and policy analysis. If you only perform clustering and trend extrapolation without mapping policy variables into forecast model parameters, the paper will feel fragmented.
2. Does Problem B require a commercial solver?
Not necessarily. Small-scale instances can be validated with PuLP or OR-Tools. However, if Question 3 leads to a large variable space, Gurobi or CPLEX can significantly improve solution efficiency and result quality.
3. How should teams make the final choice between the two problems?
Base the decision on your team’s existing assets. If you are strong in statistical modeling, visualization, and interpretability, choose Problem A. If you are strong in integer programming, scheduling models, and solver tuning, choose Problem B. Do not switch to an unfamiliar method stack just because it seems more advanced.
AI Readability Summary: This article reconstructs the problem landscape of the 2026 Northeast China Mathematical Modeling League. It focuses on Problem A’s regional population classification and policy evaluation, as well as Problem B’s temporary worker recruitment and scheduling optimization. It extracts practical model combinations, innovation points, and selection advice to help teams quickly assess difficulty and choose an appropriate technical route.