The core goal of Redis persistence is to preserve the high performance of an in-memory database while safely flushing data to disk to prevent data loss after restarts or crashes. This article focuses on RDB, AOF, and hybrid persistence, and answers three common pain points: performance overhead, data recovery, and corrupted file handling. Keywords: Redis persistence, RDB, AOF.
Technical specification snapshot
| Parameter | Description |
|---|---|
| Core topic | Redis persistence mechanisms |
| Language | C, Shell configuration, command line |
| Protocol/Model | RESP, file snapshots, append-only logs |
| Typical files | dump.rdb, appendonly.aof |
| Key mechanisms | fork, Copy-On-Write, AOF rewrite |
| Core dependencies | Linux process model, file system, disk I/O |
| Applicable scenarios | Cache recovery, crash recovery, master-replica synchronization |
| Star count | Not provided in the source input |
Redis persistence solves the volatility of memory first
Redis achieves high performance through in-memory reads and writes, but memory is inherently non-persistent. Once the process exits, the machine restarts, or power fails unexpectedly, purely in-memory data is lost.
For that reason, Redis does not abandon performance in pursuit of absolute durability. Instead, it adds a disk-based copy outside the in-memory service model. At runtime, Redis primarily reads and writes memory, and after a restart, it reconstructs the in-memory state from disk files.
Redis persistence follows three main paths
- RDB: Generates point-in-time snapshots and is suitable for periodic backups.
- AOF: Appends operation logs by command and is suitable for more real-time recovery.
- Hybrid persistence: Combines fast RDB recovery with the incremental logging capability of AOF.
# Trigger an RDB snapshot manually
SAVE # Generate a snapshot synchronously; blocks the service
BGSAVE # Generate a snapshot in the background; recommended
# Enable AOF
appendonly yesThis configuration set shows the three basic entry points into Redis persistence: synchronous snapshots, asynchronous snapshots, and append-only logging.
RDB is essentially a snapshot of memory at a point in time
RDB serializes the current key-value state in Redis memory into a binary file. The default common filename is dump.rdb. It records the result, not the process.
Its advantages are compact files, fast recovery, and suitability for backups and full master-replica synchronization. Its drawback is that if data has not been flushed between two snapshots, an unexpected crash can cause that data to be lost.
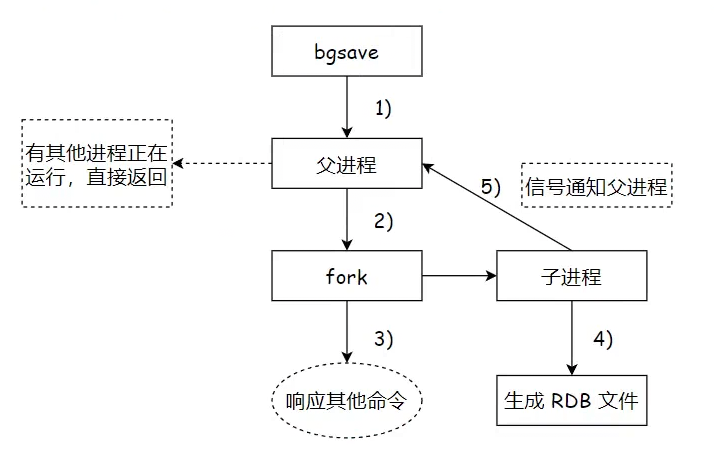 AI Visual Insight: The diagram shows the typical parent-child process model of
AI Visual Insight: The diagram shows the typical parent-child process model of bgsave: the parent process continues handling client requests, while the child process writes the current memory state into a snapshot file. This reflects Redis’s design choice of isolating disk I/O through multi-process execution.
BGSAVE depends on fork, and fork does not mean the entire memory is copied immediately
When bgsave runs, the Redis parent process calls fork to create a child process. The child inherits the parent’s address space view and then writes the current dataset into the RDB file.
Many engineers worry that large-memory instances will incur a massive copy cost during fork. In practice, the operating system usually uses Copy-On-Write. That means only modified memory pages are actually copied.
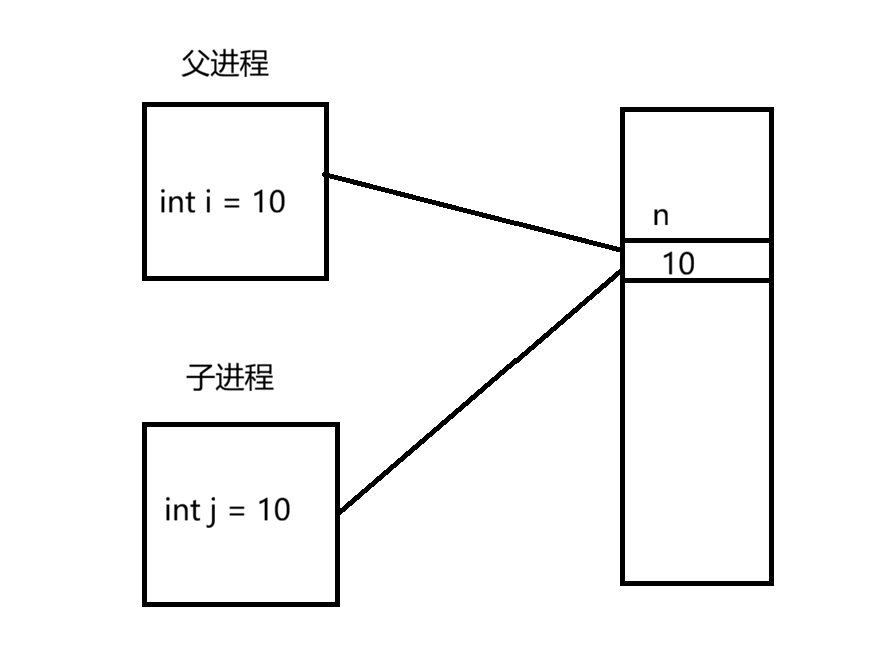 AI Visual Insight: The diagram shows that after
AI Visual Insight: The diagram shows that after fork, the parent and child processes initially share the same physical memory pages, and their page tables point to the same data pages. This explains why bgsave does not immediately duplicate the full dataset at startup.
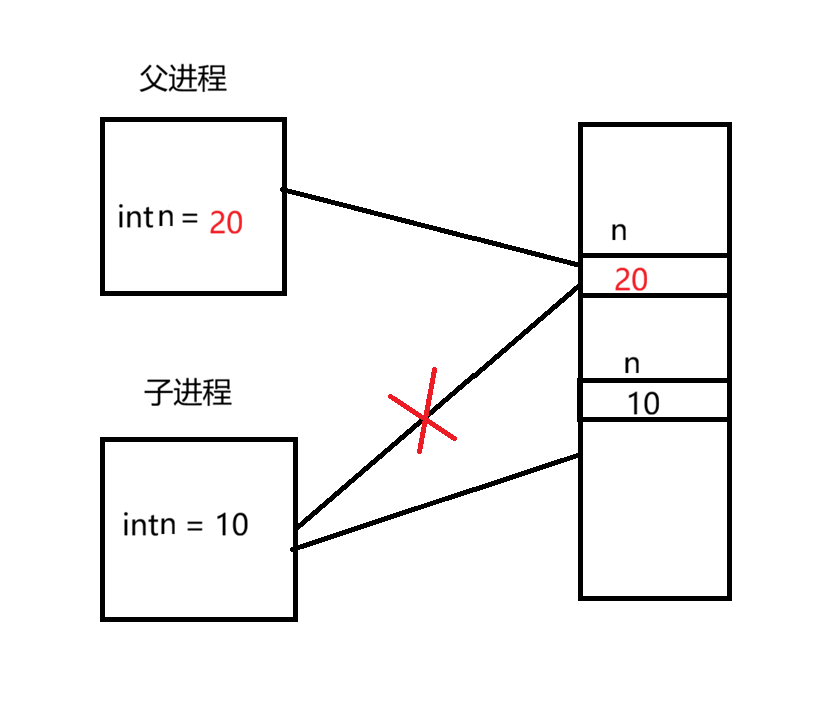 AI Visual Insight: The diagram shows that when either side modifies memory, page copying is triggered and the originally shared page is split into independent physical pages. This means that under heavy write workloads,
AI Visual Insight: The diagram shows that when either side modifies memory, page copying is triggered and the originally shared page is split into independent physical pages. This means that under heavy write workloads, bgsave can introduce extra memory pressure and page-copy overhead.
# Example automatic snapshot rules in redis.conf
save 900 1 # Trigger if at least 1 change occurs within 900 seconds
save 300 10 # Trigger if at least 10 changes occur within 300 seconds
save 60 10000 # Trigger if at least 10000 changes occur within 60 secondsThese rules show that RDB is not real-time persistence. It is a compromise strategy based on time windows and the number of modifications.
The RDB file generation and replacement mechanism improves availability
When Redis generates an RDB file, it does not overwrite the old file directly. Instead, it first writes to a temporary file, and after the write completes, it replaces the old file with the new one. This avoids leaving behind an incomplete snapshot if generation stops midway.
If the service shuts down normally, Redis often triggers one final persistence operation before exit. If the process is terminated with kill -9 or the machine loses power, Redis has no chance to flush additional data, so any data after the last snapshot may be lost.
 AI Visual Insight: The diagram highlights where the working directory and the RDB filename are defined in the Redis configuration file, showing that the actual snapshot file path is determined jointly by
AI Visual Insight: The diagram highlights where the working directory and the RDB filename are defined in the Redis configuration file, showing that the actual snapshot file path is determined jointly by dir and dbfilename.
RDB file corruption can directly affect startup recovery
RDB uses a binary format. If content in the middle of the file is corrupted, Redis may fail directly during startup loading. If corruption occurs only near the end, some versions or scenarios may still load part of the data, but the result is not fully predictable.
For that reason, production environments should pay attention to log directories, validation tools, and backup pipelines, especially for high-risk operations such as cross-machine copying, compressed transfer, and manual editing.
 AI Visual Insight: The diagram shows the entry point for the Redis-provided RDB inspection tool, indicating that the official recommendation is to validate and assess repair options first when a file is abnormal, rather than starting an instance directly with a corrupted file.
AI Visual Insight: The diagram shows the entry point for the Redis-provided RDB inspection tool, indicating that the official recommendation is to validate and assess repair options first when a file is abnormal, rather than starting an instance directly with a corrupted file.
# Check whether an RDB file is valid
redis-check-rdb /var/lib/redis/dump.rdb
# Check whether an AOF file is valid and try to fix it
redis-check-aof --fix /var/lib/redis/appendonly.aofThese tools act as the first safety gate in the Redis data recovery workflow and are well suited for incident troubleshooting and offline repair.
AOF trades operation logs for finer-grained data safety
AOF stands for Append Only File. Instead of storing a snapshot at a specific point in time, it appends every write command to the end of the file in protocol format. When Redis restarts, it replays these commands in order to restore the latest state.
Compared with RDB, the main advantage of AOF is that the recovery target is much closer to the real dataset just before the failure. The cost is a larger file, longer replay time, and the need to balance fsync frequency against performance.
 AI Visual Insight: The diagram shows where
AI Visual Insight: The diagram shows where appendonly yes is configured, making it clear that AOF is an explicitly enabled feature. Once enabled, Redis prioritizes loading AOF instead of RDB during startup recovery.
AOF uses a buffer and fsync policies to control performance overhead
Redis does not immediately write every incoming write command directly to disk. Instead, it first writes commands into the AOF buffer and then flushes them to disk in batches according to the configured policy. This significantly reduces the number of disk writes.
There are three common policies: always is the safest but slowest; everysec is usually the engineering default compromise; no lets the operating system decide when to flush, which offers better performance but also higher risk.
appendonly yes
appendfsync everysec # Flush to disk once per second; balances performance and reliability
# appendfsync always # Flush after every command; safest but most expensive
# appendfsync no # Let the operating system schedule flushingThis configuration defines the reliability boundary of AOF: the amount of data loss you can tolerate determines how frequently you should flush.
AOF rewrite replaces recording the full history with recording the final result
AOF keeps growing because it retains many intermediate operations. For example, if one key is updated with SET multiple times, only the final state matters during recovery. To address this, Redis provides the AOF rewrite mechanism to reduce file size.
Rewrite does not modify the old AOF file in place. Instead, Redis rebuilds a shorter new AOF file from the final state currently stored in memory. In essence, this is similar to an RDB snapshot, except the output format still follows the AOF protocol text format.
 AI Visual Insight: The diagram shows the asynchronous rewrite path of
AI Visual Insight: The diagram shows the asynchronous rewrite path of bgrewriteaof: the child process rebuilds a new AOF from the current in-memory state, while the parent process continues handling new requests, which prevents the main thread from blocking on large-file compaction.
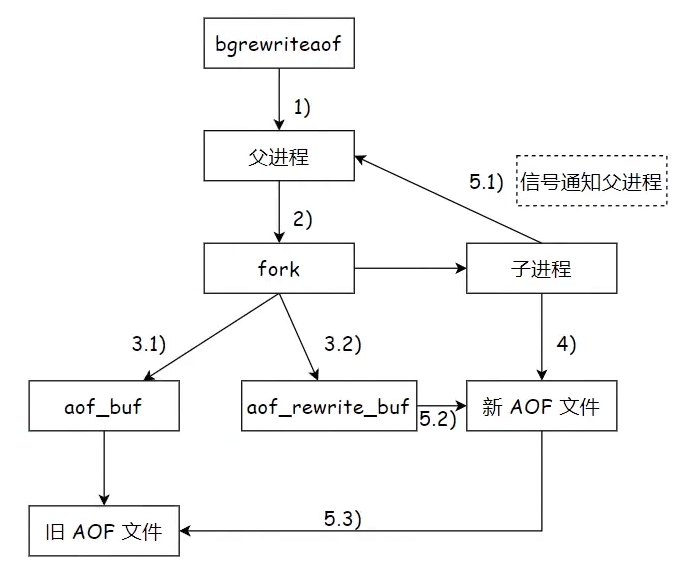 AI Visual Insight: The diagram shows that during rewrite, the parent process maintains an additional
AI Visual Insight: The diagram shows that during rewrite, the parent process maintains an additional aof_rewrite_buf buffer to record write commands received after fork. After the child process finishes, Redis appends those commands to the new file to ensure that no data is lost during the rewrite window.
Hybrid persistence balances recovery speed and data completeness
Hybrid persistence writes the current full in-memory state to the beginning of the new AOF file in RDB binary format during AOF rewrite, and then appends incremental AOF commands afterward.
The benefit is clear: during loading, Redis restores most of the data quickly first, and then replays a shorter incremental log. Compared with pure AOF, startup is faster. Compared with pure RDB, the recovered data is more complete.
The selection principles in production must align with business goals
If you care more about backup size, cold recovery speed, and full master-replica synchronization efficiency, RDB still provides strong value. If you care more about data completeness during crashes, AOF is usually the better fit.
In most modern production environments, a common approach is to enable AOF or hybrid persistence first, while retaining appropriate RDB capabilities for backup and disaster recovery. The real key is not which one is more advanced, but which one better matches your recovery objectives.
FAQ
1. If both RDB and AOF files exist, which one does Redis load first?
Redis loads AOF first. AOF usually contains data that is closer to the state immediately before the failure, so its recovery completeness is higher than RDB.
2. Why is it not recommended to run SAVE frequently?
SAVE generates a snapshot synchronously on the main thread, which blocks client requests during execution. In production, BGSAVE is preferred because it moves the persistence work to a child process.
3. If Redis crashes during AOF rewrite, is all data lost?
No. The old AOF file continues to receive writes. Redis replaces it only after the new file is fully generated and the rewrite buffer has been appended, so a failed rewrite usually does not break the existing recovery chain.
AI Readability Summary: This article systematically reconstructs Redis persistence knowledge by explaining how RDB snapshots, AOF append-only logs, and hybrid persistence work, including their trigger conditions, fork and Copy-On-Write behavior, file recovery, and rewrite workflows. It helps developers make the right trade-offs among performance, reliability, and recovery speed.