GPT-image-2 represents the current generation of high-quality AI image models. Its strengths lie in Chinese text rendering, complex UI reconstruction, and highly consistent visual generation, significantly reducing the long-standing text-to-image issues of garbled text, distorted layouts, and costly manual rework. Keywords: GPT-image-2, AI image generation, DeepSider.
| Parameter | Specification |
|---|---|
| Model Name | GPT-image-2 |
| Primary Capabilities | Text-to-image, poster generation, UI screenshot generation, knowledge diagrams, stylized images |
| Access Methods | DeepSider browser extension / Web access |
| Language Support | Friendly to Chinese prompts, strong multilingual copy rendering |
| Protocol / Interaction | Browser extension, Web service |
| Public Momentum | Described in the source material as a current SOTA-level image generation model |
| Star Count | Not provided in the source material |
| Core Dependencies | Browser extension environment, DeepSider service |
GPT-image-2 has significantly improved the long-standing controllability issues in AI image generation
The biggest problem with traditional AI image generation was never whether it could draw, but whether it could reliably draw the right thing. This was especially true for Chinese posters, information-dense UIs, and promotional visuals with typography, where errors such as misspelled text, garbled characters, misaligned elements, and semantic drift were common.
The conclusion from the source material is clear: GPT-image-2 delivers noticeable improvements in text rendering, composition integrity, scene reconstruction, and aesthetic quality. It has moved from a lottery-like generation experience toward output that is close to delivery-ready.
 AI Visual Insight: This image establishes the overall tone of the model’s capabilities. It is typically used to convey generation quality, detail density, and visual completeness. In the context of an evaluation, it emphasizes high-fidelity image output rather than a flashy display of a single style.
AI Visual Insight: This image establishes the overall tone of the model’s capabilities. It is typically used to convey generation quality, detail density, and visual completeness. In the context of an evaluation, it emphasizes high-fidelity image output rather than a flashy display of a single style.
A minimal prompt workflow is enough to validate its core capabilities
Please generate a promotional poster for a tech product:
- Subject: AI browser assistant
- Style: Minimalist, futuristic, blue-purple gradient
- Copy: Support a Chinese headline with clear typography
- Output requirement: Suitable for the hero section of a product introduction pageThis prompt quickly validates GPT-image-2’s ability to understand Chinese copy, commercial composition, and product-oriented visual language as a whole.
DeepSider provides a low-barrier entry point for using GPT-image-2
According to the source material, DeepSider has already integrated this model and offers an access path that is friendly to mainstream developers and content creators: users can register domestically, no Plus subscription is required, there are no extra network hurdles, and a limited free quota is available.
This means the model is not just a lab-grade capability anymore. It is starting to take the shape of a production tool that teams can use in daily workflows. For teams that need to validate visual concepts quickly, this substantially lowers the adoption barrier.
 AI Visual Insight: This image looks more like a generation sample from a real business copy scenario. Key evaluation points include whether the headline typography is stable, whether the information hierarchy is clear, and whether the text-image layout matches standard promotional design conventions.
AI Visual Insight: This image looks more like a generation sample from a real business copy scenario. Key evaluation points include whether the headline typography is stable, whether the information hierarchy is clear, and whether the text-image layout matches standard promotional design conventions.
 AI Visual Insight: This image reflects the extension or web access interface. From a technical perspective, it shows that GPT-image-2 has been packaged as an end-user-facing capability, reducing the cost of API integration and environment setup.
AI Visual Insight: This image reflects the extension or web access interface. From a technical perspective, it shows that GPT-image-2 has been packaged as an end-user-facing capability, reducing the cost of API integration and environment setup.
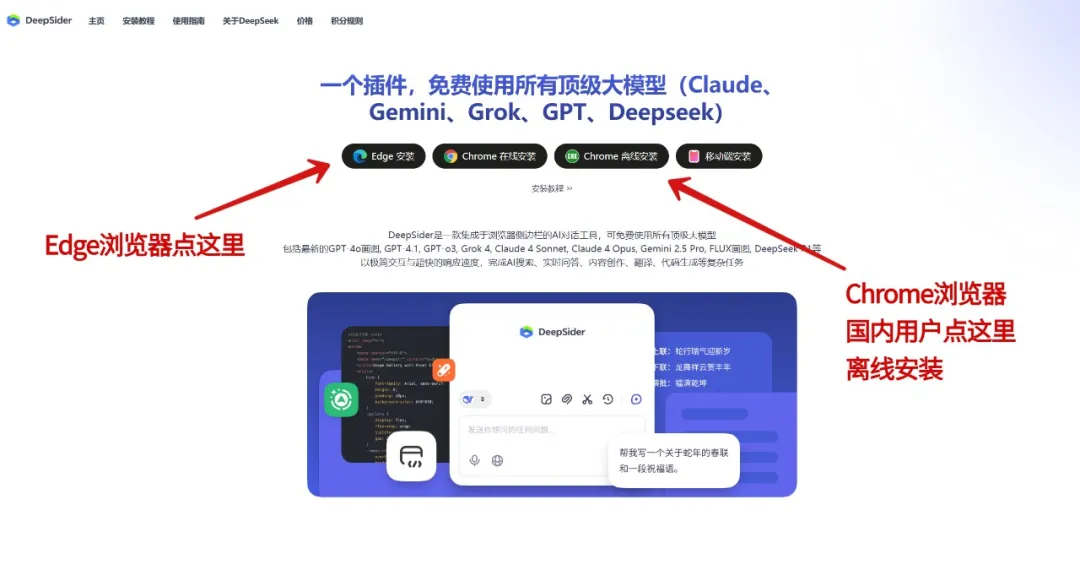 AI Visual Insight: This image shows the browser extension installation or activation flow, indicating that the usage path is already integrated into the Chrome and Edge ecosystem and is suitable for high-frequency use and embedded workflow adoption.
AI Visual Insight: This image shows the browser extension installation or activation flow, indicating that the usage path is already integrated into the Chrome and Edge ecosystem and is suitable for high-frequency use and embedded workflow adoption.
Calling it through a browser extension is currently the most direct way to use it
# 1. Open the official website
https://deepsider.ai
# 2. Install the browser extension
# Supports Chrome / Edge
# 3. After signing in, select GPT-image-2
# 4. Enter a Chinese prompt and generate the imageThis workflow shows that GPT-image-2 is effectively plug-and-play and is well suited for non-ML developers who want to put it into practice quickly.
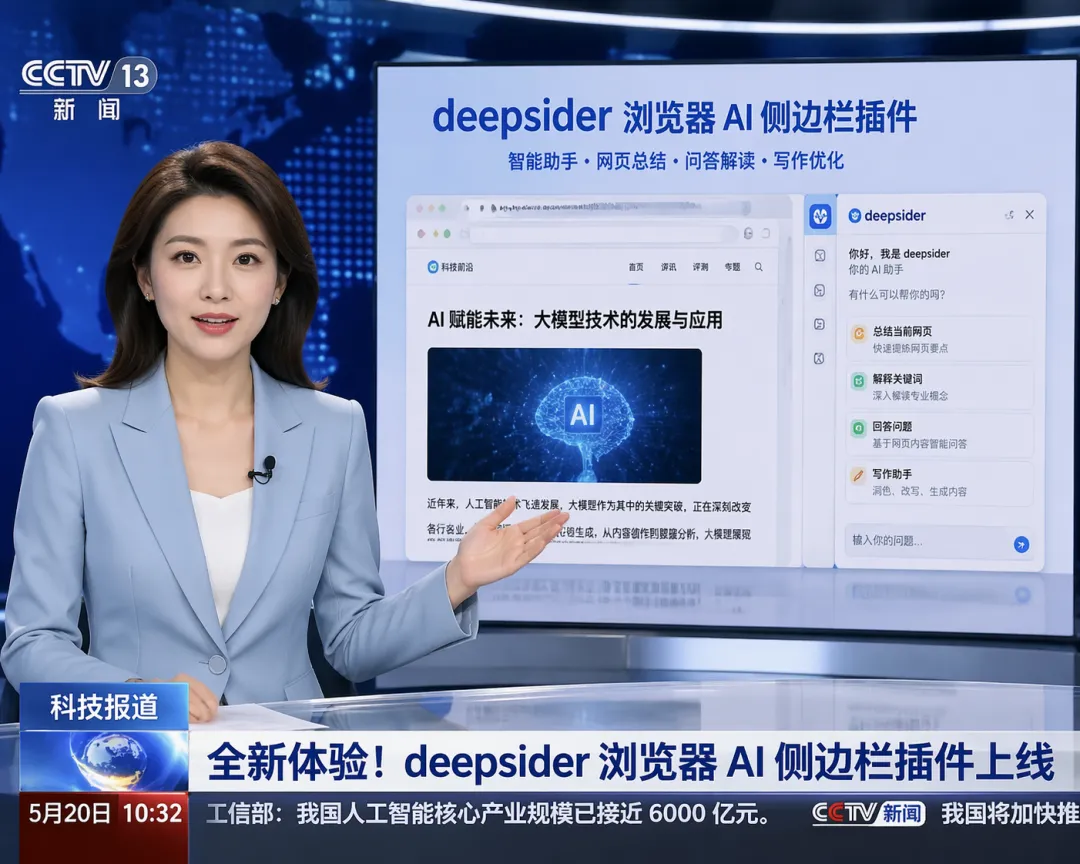
GPT-image-2 is most compelling in complex interfaces and information-dense visuals
The most prominent example in the original article is “live-stream screenshot generation.” The difficulty of this type of task is not the illustration itself, but multi-element consistency: avatars, comments, likes, floating messages, buttons, hierarchy, and brand context all need to work together at the same time.
The value of GPT-image-2 is that it does not just generate “an image that looks like a UI.” It can generate “an interface image with product sensibility and narrative logic.” That is critically important for product prototypes, marketing assets, short-video covers, and virtual scene construction.
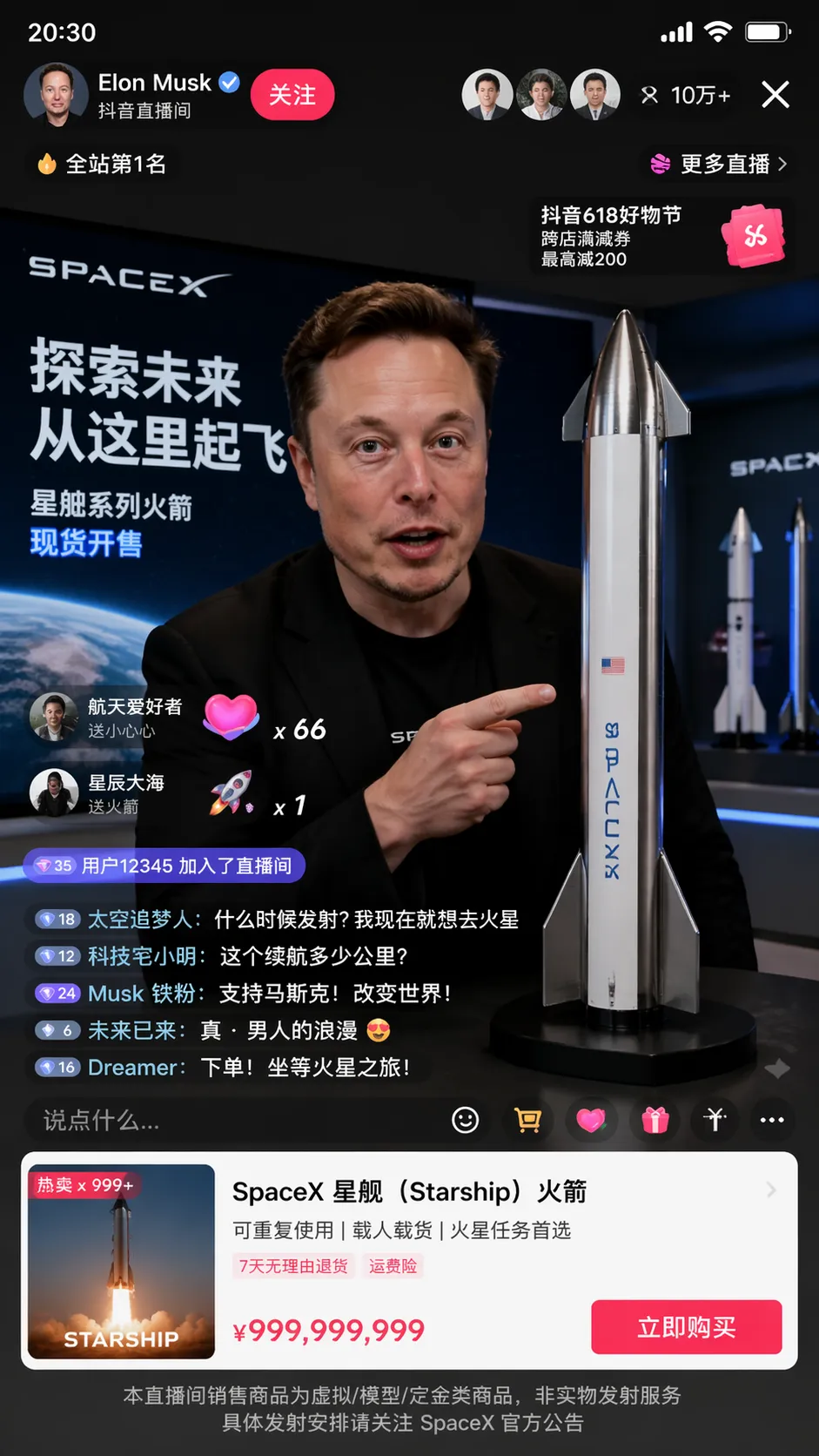 AI Visual Insight: This image should demonstrate screenshot-style generation for a live-stream or social interface. Key things to inspect include the layering of information panels, the layout of the button area, the density of floating comments and interaction elements, and whether the overall result feels close to a real app screenshot.
AI Visual Insight: This image should demonstrate screenshot-style generation for a live-stream or social interface. Key things to inspect include the layering of information panels, the layout of the button area, the density of floating comments and interaction elements, and whether the overall result feels close to a real app screenshot.
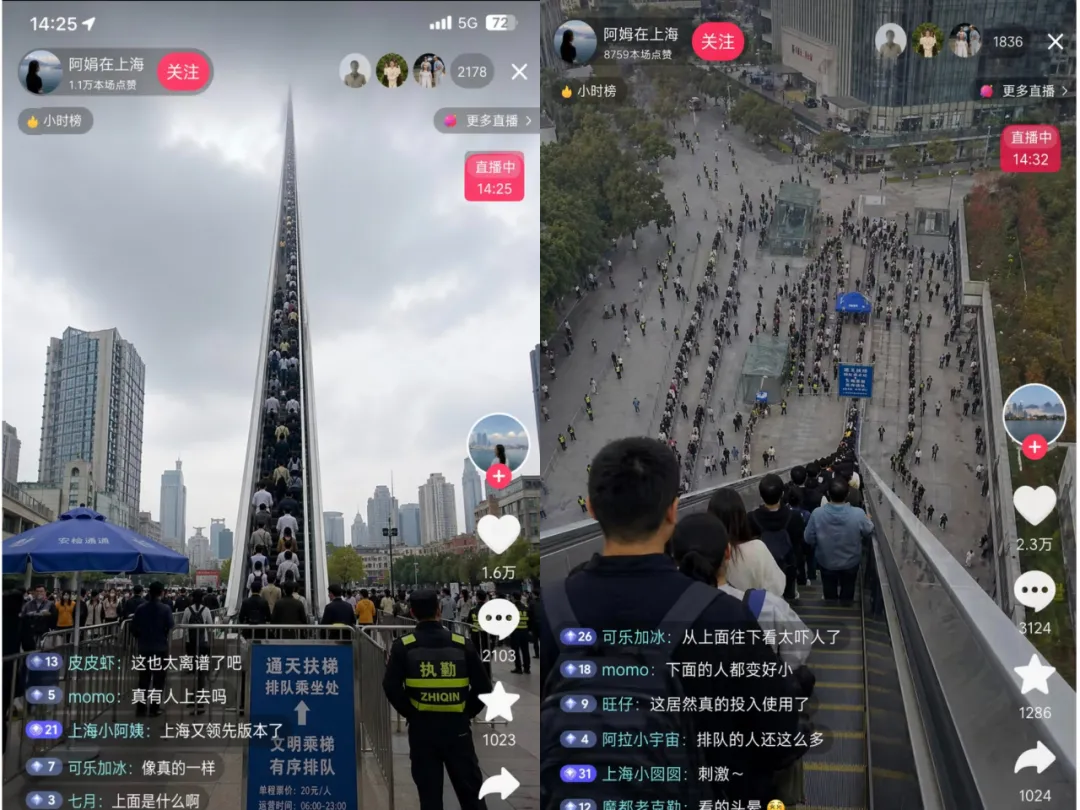 AI Visual Insight: This image highlights the model’s control over local details in complex pages, especially the consistency of text blocks, thumbnails, status bars, and recommendation feed cards. These details directly determine whether the image feels usable.
AI Visual Insight: This image highlights the model’s control over local details in complex pages, especially the consistency of text blocks, thumbnails, status bars, and recommendation feed cards. These details directly determine whether the image feels usable.
 AI Visual Insight: This image likely further demonstrates UI composition across different scenarios. Technically, it reflects strong stability in component reuse, visual style consistency, and semantic filling.
AI Visual Insight: This image likely further demonstrates UI composition across different scenarios. Technically, it reflects strong stability in component reuse, visual style consistency, and semantic filling.
The model already covers two high-value domains: commercial design and knowledge communication
GPT-image-2 is highly practical for posters, website visuals, interior design concepts, and knowledge diagrams. Its key advantage is not that a single image simply looks good, but that it reduces repeated manual revision cycles and produces drafts that are immediately discussable, reusable, and potentially deliverable.
For small and mid-sized teams, this means lower collaboration costs across design, operations, product, and engineering, because a single prompt can turn an idea into a visual object that everyone can evaluate.
 AI Visual Insight: This type of poster is typically used to evaluate the model’s higher-end aesthetic capability. Focus on subject lighting, color rhythm, background layering, and whether the reserved text area has a commercial design feel.
AI Visual Insight: This type of poster is typically used to evaluate the model’s higher-end aesthetic capability. Focus on subject lighting, color rhythm, background layering, and whether the reserved text area has a commercial design feel.
 AI Visual Insight: This image likely contains a more complex layout or narrative structure, reflecting the model’s performance in multi-subject composition, focal organization, and brand-style visual consistency.
AI Visual Insight: This image likely contains a more complex layout or narrative structure, reflecting the model’s performance in multi-subject composition, focal organization, and brand-style visual consistency.
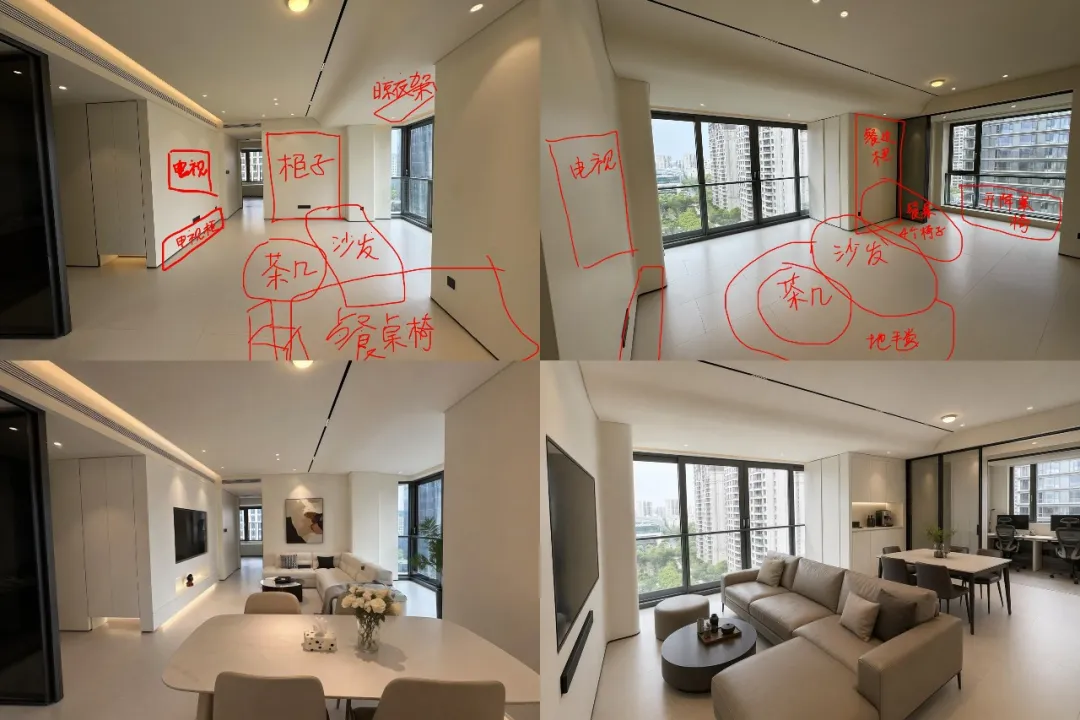 AI Visual Insight: This image demonstrates interior space generation. Focus on material rendering, spatial perspective, lighting logic, and whether the furniture layout matches the standards of real interior design mockups.
AI Visual Insight: This image demonstrates interior space generation. Focus on material rendering, spatial perspective, lighting logic, and whether the furniture layout matches the standards of real interior design mockups.
 AI Visual Insight: The core evaluation points here are product prominence, promotional copy readability, background atmosphere, and conversion-oriented design. It is well suited for assessing the model’s fit for e-commerce marketing scenarios.
AI Visual Insight: The core evaluation points here are product prominence, promotional copy readability, background atmosphere, and conversion-oriented design. It is well suited for assessing the model’s fit for e-commerce marketing scenarios.
 AI Visual Insight: This image should reflect hero-section design capability for website-like pages. Key factors include modular layout, whitespace control, brand consistency, and the minimalist visual order commonly seen in premium product pages.
AI Visual Insight: This image should reflect hero-section design capability for website-like pages. Key factors include modular layout, whitespace control, brand consistency, and the minimalist visual order commonly seen in premium product pages.
Scientific diagrams and structured knowledge visualization are an underrated direction
prompt = """
Generate a scientific knowledge diagram:
Topic: multimodal large model workflow;
Include an input layer, encoding layer, reasoning layer, and output layer;
Require clear Chinese labels, correct arrow relationships, and an academic visual style.
"""
# Core logic: turn complex concepts into structured visual explanations
print(prompt)This example shows that GPT-image-2 is well suited for turning abstract knowledge into visual assets that can be used in demos and teaching.
 AI Visual Insight: This image highlights structured infographic generation capability. It usually requires the model to handle hierarchical headings, arrow relationships, module borders, and color coding at the same time, making it a test of both logic and visual control.
AI Visual Insight: This image highlights structured infographic generation capability. It usually requires the model to handle hierarchical headings, arrow relationships, module borders, and color coding at the same time, making it a test of both logic and visual control.
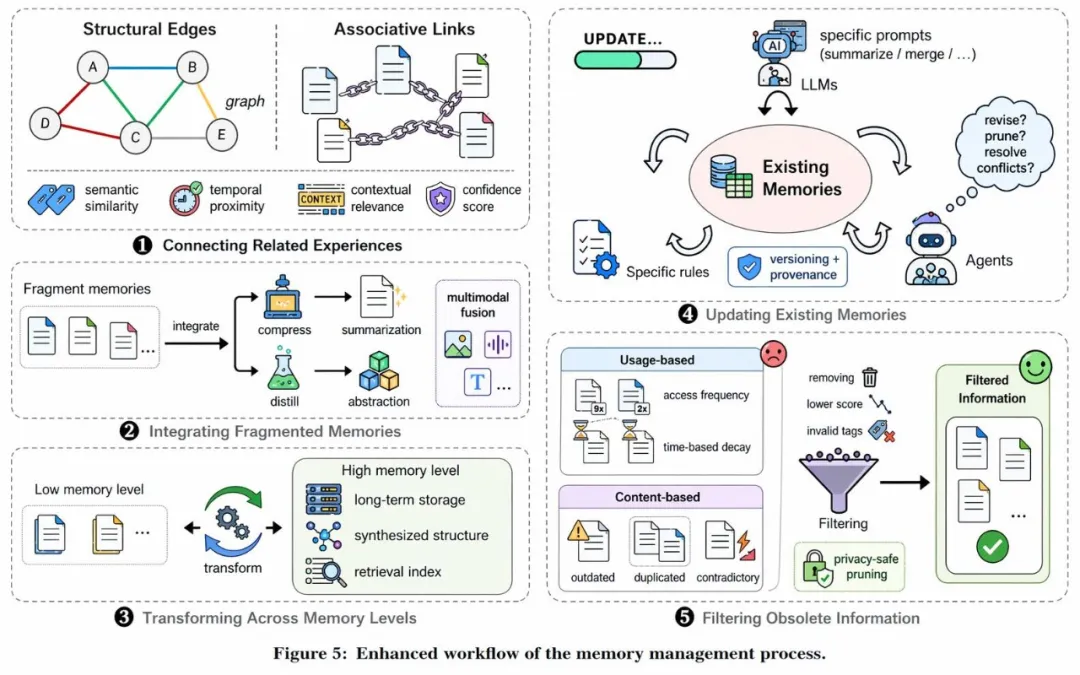 AI Visual Insight: This image is closer to a professional scientific illustration. Key indicators include terminology labeling accuracy, component relationship clarity, experimental workflow readability, and adherence to journal-style conventions.
AI Visual Insight: This image is closer to a professional scientific illustration. Key indicators include terminology labeling accuracy, component relationship clarity, experimental workflow readability, and adherence to journal-style conventions.
Entertainment-oriented examples show that style transfer and photorealistic simulation are already mature
The source material also showcases old photos, handwritten manuscripts, and Pixar-style portraits. The significance of these examples is not just that they are fun, but that they show the model has strong style generalization capability and can switch across realism, vintage aesthetics, hand-drawn visuals, and animation.
When this style transfer capability combines with strong text rendering, the model’s application boundary expands even further, including branded character content, IP concept art, visual novel assets, and interactive marketing creatives.
 AI Visual Insight: This image emphasizes period realism. Check whether film grain, faded tones, clothing details, and the exposure and texture characteristics typical of historical photography feel natural.
AI Visual Insight: This image emphasizes period realism. Check whether film grain, faded tones, clothing details, and the exposure and texture characteristics typical of historical photography feel natural.
 AI Visual Insight: This image may show vintage generation across different people or scenes. The core question is whether the style remains consistent and convincingly non-modern.
AI Visual Insight: This image may show vintage generation across different people or scenes. The core question is whether the style remains consistent and convincingly non-modern.
 AI Visual Insight: This type of image mainly validates the model’s ability to simulate paper texture, handwriting stroke variation, sketch structure, and the irregularity of human writing. It is especially suitable for knowledge notes and creative draft scenarios.
AI Visual Insight: This type of image mainly validates the model’s ability to simulate paper texture, handwriting stroke variation, sketch structure, and the irregularity of human writing. It is especially suitable for knowledge notes and creative draft scenarios.
 AI Visual Insight: This image demonstrates animation-style transfer capability. Focus on exaggerated facial proportions, soft lighting, stylized materials, and consistency in emotional expression.
AI Visual Insight: This image demonstrates animation-style transfer capability. Focus on exaggerated facial proportions, soft lighting, stylized materials, and consistency in emotional expression.
Developers should treat GPT-image-2 as visual production infrastructure rather than a point tool
A more important conclusion from the source material is that GPT-image-2’s value lies not only in “generating one image,” but in serving as a unified entry point for prototyping, content production, knowledge communication, and creative experimentation.
If a team already has copywriting, operations, frontend, or product workflows, the best practice is not to experiment with it in isolation. Instead, embed it into requirement reviews, marketing asset creation, proposal presentations, and knowledge capture processes to build reusable prompt assets.
A prompt template suitable for team adoption looks like this
Task goal: Generate a visual draft that can be used directly in a business review
Scenario type: E-commerce poster / UI screenshot / scientific diagram / interior design rendering
Visual style: Minimalist / realistic / tech-forward / vintage film
Copy language: Chinese
Hard requirements: Clear text, complete structure, clear visual hierarchy, optimized for 16:9
Prohibited issues: Garbled text, misspellings, overlapping elements, low-resolution appearanceTemplates like this help teams convert experience into standardized inputs, which improves reproducibility and generation stability.
FAQ
What is the most important technical advantage of GPT-image-2?
Its most important strengths are Chinese text rendering, complex interface generation, and high-completion composition quality. It reduces the most common issues in traditional text-to-image workflows, including garbled text, misalignment, and heavy post-editing.
How can a regular developer try GPT-image-2 at the lowest possible cost?
Based on the source material, the current access path is through DeepSider’s web interface or browser extension. After installation, users can directly enter Chinese prompts and generate images without complex deployment.
Is it better suited for entertainment use cases or productivity scenarios?
It can support both, but the higher-value use cases are clearly on the productivity side, including e-commerce posters, product prototypes, knowledge diagrams, scientific illustrations, and website visual drafts. These scenarios better demonstrate its deliverability.
AI Readability Summary: This article reconstructs the core capabilities and practical usage path of GPT-image-2, focusing on high-value scenarios such as Chinese text rendering, complex UI generation, scientific diagrams, and e-commerce posters. It also explains how to access the model through DeepSider and provides quick-start examples and selection guidance.