Technical Specification Snapshot
| Parameter | GPT Image 2 | Nano Banana 2 |
|---|---|---|
| Model Paradigm | Native multimodal autoregressive Transformer | Multimodal image generation model |
| Primary Strengths | Text rendering, spatial reasoning, multi-image consistency | Fast generation, visual quality, image editing |
| Typical Pain Points Addressed | Accurate Chinese text, controllable complex layouts, production-ready commercial design | Fast, but weaker on complex text and logical layouts |
| Language Support | Multilingual, with strong Chinese performance | Multilingual, with average stability on long text |
| License | Not explicitly disclosed in the source material | Not explicitly disclosed in the source material |
| GitHub Stars | Not applicable | Not applicable |
| Core Dependencies | Transformer, MoE, unified token space, recursive verification mechanism | Multimodal generation and editing pipeline |
This comparison shows that the model paradigm has changed
The most important takeaway is not leaderboard scores. GPT Image 2 moves beyond “generating images” and toward “understanding design.” It no longer focuses only on visual appeal. It also targets semantic alignment, structural correctness, and output stability.
For developers and content teams, this means the evaluation standard for AI image generation has changed. The highest-value models are not the ones that occasionally produce a stunning image. They are the ones that can reliably complete high-constraint tasks such as infographics, e-commerce detail pages, and educational diagrams.
 AI Visual Insight: This image presents an overall comparison of model capabilities and highlights GPT Image 2’s lead in comprehensive evaluation, generation quality, and task completion. It works well as a visual index for the architectural analysis and scenario validation that follow.
AI Visual Insight: This image presents an overall comparison of model capabilities and highlights GPT Image 2’s lead in comprehensive evaluation, generation quality, and task completion. It works well as a visual index for the architectural analysis and scenario validation that follow.
Traditional diffusion models are not just slow. They are hard to control.
Diffusion models usually suffer from three core weaknesses: semantic loss, black-box generation, and fragmented multimodal processing. After a complex prompt passes through multiple stages, the model often preserves the theme while losing critical details. This is especially visible in Chinese typography and precise layout control.
When a user asks for “a red label in the top-right corner, a QR code area at the bottom, and the title in Heiti,” a diffusion model often returns only an approximation. It can generate atmosphere, but it struggles to execute layout logic consistently. That is the main barrier to commercial deployment.
prompt_spec = {
"title": "新手养花完全指南",
"layout": ["顶部标题", "中部四季分类", "底部养护提示"], # Define the structural skeleton first
"style": "淡绿底色,手绘插画",
"constraints": ["中文清晰", "分类准确", "信息层级明确"] # Constraints matter more than style
}
# High-constraint generation tasks should plan structure before rendering
print(prompt_spec)This code shows that high-quality image prompts are essentially more like structured task specifications than natural-language inspiration alone.
GPT Image 2 performs end-to-end reasoning through a unified token space
The key breakthrough in GPT Image 2 is that it processes text tokens and image tokens inside a unified representation space. When the model interprets “9 o’clock,” it does not only understand the meaning of the phrase. It can also plan the visual position of the clock hands within the image.
This design delivers two direct benefits. First, it reduces semantic loss caused by cross-module handoffs. Second, it places text, composition, and spatial relationships inside the same reasoning chain. As a result, the model can execute complex instructions more completely.
MoE and recursive verification work together to improve stability
The source material also mentions two important components: sparsely activated Mixture of Experts (MoE) and a recursive output verification mechanism. The former improves efficiency across different task types, while the latter reduces failure rates in complex scenarios.
This design closely resembles an engineering workflow of “plan first, execute next, then self-check.” That is why GPT Image 2’s advantage is not a single standout result. Its average output quality is higher, which makes it especially suitable for process-driven content production.
def generate_with_verify(prompt: str) -> str:
draft = "first_render" # First-pass draft generation
aligned = False
# Simulate recursive verification until semantic constraints are satisfied
while not aligned:
aligned = "文字正确" in prompt and "布局明确" in prompt
if not aligned:
draft = "rerender_with_constraints"
return draftThis code abstracts the “generate, validate, and rerender” mechanism and explains where stability comes from in commercial scenarios.
The biggest capability gains appear first in Chinese text rendering and spatial layout
The original article places “text rendering” at the top of the capability improvements, and that is a reasonable choice. Historically, text has been the hardest part of AI image generation to deploy in Chinese-language scenarios, especially for long titles, complex characters, and multi-section layouts.
GPT Image 2 matters because it treats text as a semantic object rather than a texture overlay. That allows it to plan content and layout before generation. For posters, courseware, product detail pages, and diagrams, this matters more than a simple increase in image quality.
Multi-image consistency makes serialized content production-ready
Another critical point is multi-image consistency. Character drift, color drift, and perspective drift directly break continuity in comics, brand posters, and storyboard scripts. GPT Image 2 significantly reduces these deviations through shared style parameters and visual constraints.
This means it starts to support batch production instead of relying on one-off luck. For content factories, brand teams, and educational publishing workflows, that difference determines whether the model can enter a formal production pipeline.
Practical comparisons show GPT Image 2 is stronger on high-constraint tasks
In infographic testing, GPT Image 2 does not win by being flashier. It wins by being clearer. Category relationships, title hierarchy, and image-text alignment are more complete, which makes the output much closer to truly publishable content.
 AI Visual Insight: This image shows a complete vertical infographic layout with a title area, content columns, illustrative visuals, and a unified background color system. It demonstrates the model’s integrated control over information hierarchy, reading flow, and visual consistency.
AI Visual Insight: This image shows a complete vertical infographic layout with a title area, content columns, illustrative visuals, and a unified background color system. It demonstrates the model’s integrated control over information hierarchy, reading flow, and visual consistency.
 AI Visual Insight: The image is visually attractive in color and illustration style, but from an information-design perspective, it is weaker in content grouping, title constraints, and text readability. This suggests the model leans more toward visual generation than structured information expression.
AI Visual Insight: The image is visually attractive in color and illustration style, but from an information-design perspective, it is weaker in content grouping, title constraints, and text readability. This suggests the model leans more toward visual generation than structured information expression.
E-commerce, storyboards, and scientific diagrams create a wider performance gap
E-commerce detail pages require strong conversion-oriented logic. Short-video storyboards require shot language. Scientific diagrams require accurate terminology and directional labeling. None of these tasks can be solved by simply drawing something that “looks right.” They require structure, text, and logic to work together.
The source examples show that GPT Image 2’s advantage on these tasks is closer to document-style generation. Nano Banana 2 may still be faster or more visually striking in some cases, but it is weaker for high-precision content production.
 AI Visual Insight: The image clearly reflects a standard e-commerce layout with a product hero visual, pricing area, selling-point modules, and promotional information. It shows that the model generated not just an image, but also understood a conversion-oriented page structure.
AI Visual Insight: The image clearly reflects a standard e-commerce layout with a product hero visual, pricing area, selling-point modules, and promotional information. It shows that the model generated not just an image, but also understood a conversion-oriented page structure.
 AI Visual Insight: This image centers on shot segmentation, narration notes, camera movement markers, and visual pacing. It shows that the model can generate a visual document close to a production script rather than a simple scene illustration.
AI Visual Insight: This image centers on shot segmentation, narration notes, camera movement markers, and visual pacing. It shows that the model can generate a visual document close to a production script rather than a simple scene illustration.
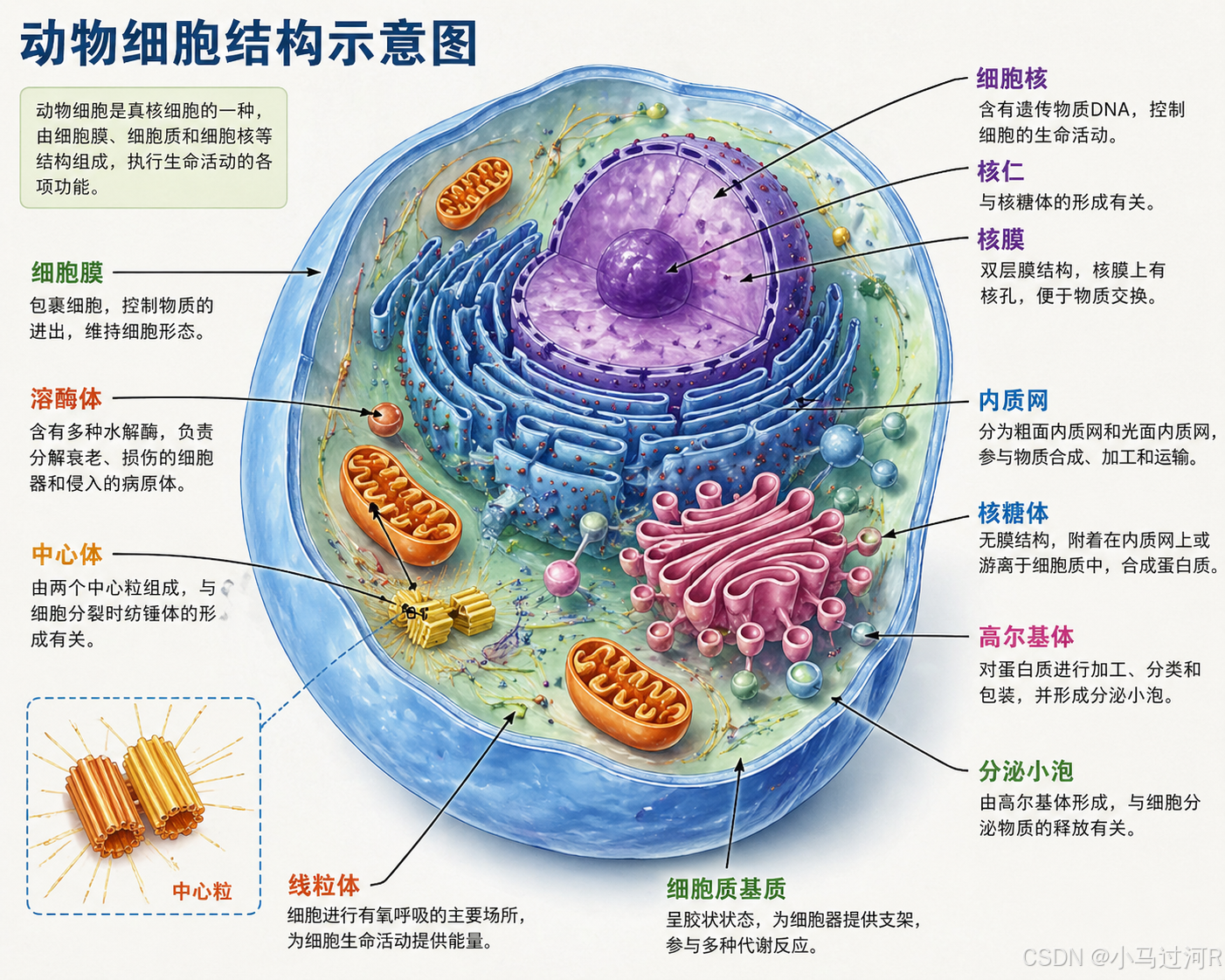 AI Visual Insight: The image combines cell structures, directional arrows, and Chinese labels in a classic textbook-style information design. It suggests the model can balance anatomical accuracy, labeling conventions, and instructional readability in scientific visualization.
AI Visual Insight: The image combines cell structures, directional arrows, and Chinese labels in a classic textbook-style information design. It suggests the model can balance anatomical accuracy, labeling conventions, and instructional readability in scientific visualization.
These models are pushing AI image generation toward formal production systems
If the previous generation of models functioned as creative assistance tools, GPT Image 2 looks more like a content production engine. It is suitable for tasks with explicit constraints, delivery standards, and batch-consistency requirements.
This shift will change how design, operations, education, and product teams collaborate. In the future, prompts will no longer just “describe an idea.” They will increasingly resemble visual task specifications, while the model becomes an executable visual reasoning layer.
def choose_model(task_type: str) -> str:
if task_type in ["信息图", "电商详情页", "科学示意图", "分镜脚本"]:
return "GPT Image 2" # Prefer for high-constraint, logic-heavy tasks
return "Nano Banana 2" # Use when speed or visual ideation matters moreThis code provides a simple selection strategy: choose GPT Image 2 first for logic-dense tasks, and consider Nano Banana 2 for inspiration-driven work.
Developers should focus less on which model is stronger and more on which model fits the workflow
From an engineering perspective, model selection should return to four metrics: text accuracy, layout adherence, consistency, and rework cost. If the output must enter a business pipeline directly, stability matters more than occasional brilliance.
That is why GPT Image 2 matters. It moves AI image generation from “looks usable” to “ready for delivery.” This is the fundamental reason it has more value than purely visual-first models in real business scenarios.
FAQ
Why is GPT Image 2 better suited than traditional diffusion models for commercial design?
Because it emphasizes unified semantic understanding, structural planning, and result verification. It can complete tasks with text, layout, and multi-element constraints more reliably, which lowers rework cost.
What scenarios are still a good fit for Nano Banana 2?
If the task leans more toward visual exploration, rapid image generation, or concept ideation, Nano Banana 2 still has value. It may retain an advantage in speed and immediate visual experimentation.
How can development teams integrate this type of model into a content workflow?
Start by templatizing prompts into four sections: structure, copy, style, and constraints. Then add human review checkpoints to evaluate text correctness and layout usability.
[AI Readability Summary]
This article reconstructs the technical comparison between GPT Image 2 and Nano Banana 2 based on the original evaluation. It explains the shift from diffusion-based generation to a native multimodal autoregressive architecture, analyzes the advantages in text rendering, spatial reasoning, multi-image consistency, and commercial design, and summarizes the best-fit use cases and likely direction of future evolution.