This article focuses on the engineering implementation of Agent and Multi-Agent systems: why agents go beyond pure LLMs, how they complete complex tasks through planning, tool calling, and memory, and how platforms such as Coze, Workflow, and OpenManus fit into production practice. Keywords: Agent, Multi-Agent, Coze.
Technical Snapshot
| Parameter | Details |
|---|---|
| Core topics | Agent, Multi-Agent, Workflow, Coze |
| Primary languages | Python, Prompt DSL |
| Interaction protocols | API, MCP, RAG retrieval calls |
| Article metrics | 192 views, 6 likes |
| Core dependencies | Large language models, external tool APIs, vector retrieval, workflow orchestration |
Agents are the key transition from language models to action systems
Traditional LLMs are strong at generation but weak at execution. Prompts can change how a model answers, but they cannot truly operate in the external world—for example, setting an alarm, checking the latest papers, executing code, or completing an automated check-in.
The value of an Agent lies in upgrading a large language model from something that can only “talk” into something that can “act.” It uses the LLM as the decision-making core, then connects it to tools, environments, and state management so the model can decompose tasks, process execution feedback, and correct itself dynamically.
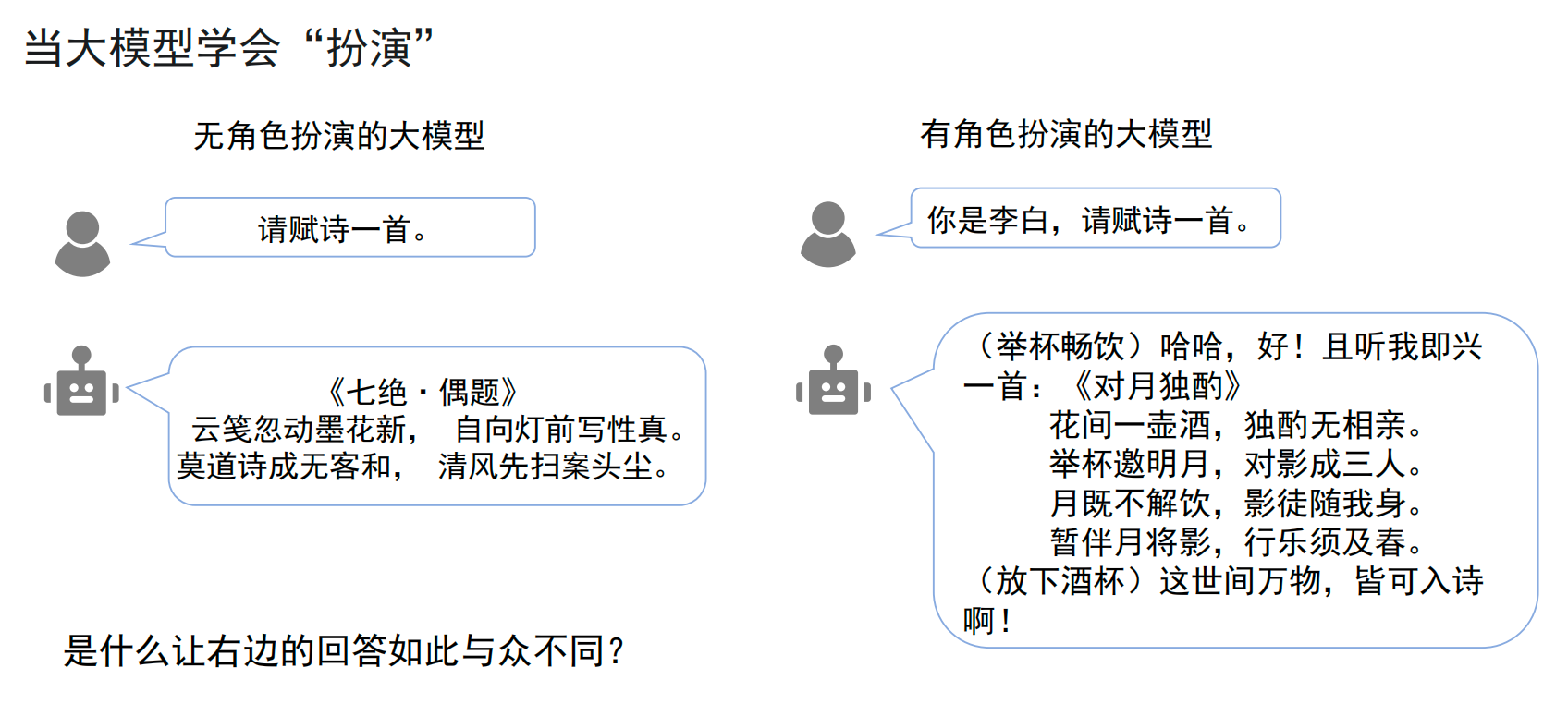 AI Visual Insight: The image highlights that a pure Prompt-based approach stays at the language generation layer, while an Agent architecture introduces external tools and execution interfaces, turning the model from a static responder into a controller for actionable task flows.
AI Visual Insight: The image highlights that a pure Prompt-based approach stays at the language generation layer, while an Agent architecture introduces external tools and execution interfaces, turning the model from a static responder into a controller for actionable task flows.
 AI Visual Insight: The figure places the large model at the center as the “brain,” with tools, environments, and execution modules connected around it, showing that an Agent is fundamentally a system-level abstraction rather than a simple enhancement of model capability.
AI Visual Insight: The figure places the large model at the center as the “brain,” with tools, environments, and execution modules connected around it, showing that an Agent is fundamentally a system-level abstraction rather than a simple enhancement of model capability.
The difference between Agents and Workflows is autonomy, not complexity
Workflows fit fixed-step tasks and emphasize determinism. They are like predefined pipelines: node order usually cannot change. Their strength is stability, but their weakness is brittleness.
An Agent is more like a control system with a feedback loop. It plans first, then observes execution results, and if it detects that the direction is wrong, it can proactively adjust the next action. That makes Agents better suited for high-uncertainty tasks.
# A minimal Agent execution loop
user_goal = "Organize a course summary on AI Agents"
plan = llm.plan(user_goal) # Let the model break the task into steps first
for step in plan:
result = tool_executor.run(step) # Call search, code, or document tools step by step
if not llm.verify(result): # Replanning is triggered if the result does not meet requirements
plan = llm.replan(user_goal, result)
breakThis code snippet shows the smallest closed loop of an Agent: planning, execution, verification, and replanning.
An Agent’s core capabilities are built on planning, action, and memory
A usable Agent must have at least three capabilities at the same time: planning, action, and memory. If any one of them is missing, the system will struggle to support sustained execution in complex scenarios.
Planning determines whether a task can be decomposed correctly
Planning includes both perception and decision-making. Perception requires the model to understand text, images, speech, and even software interfaces. Decision-making requires it to convert vague goals into executable steps.
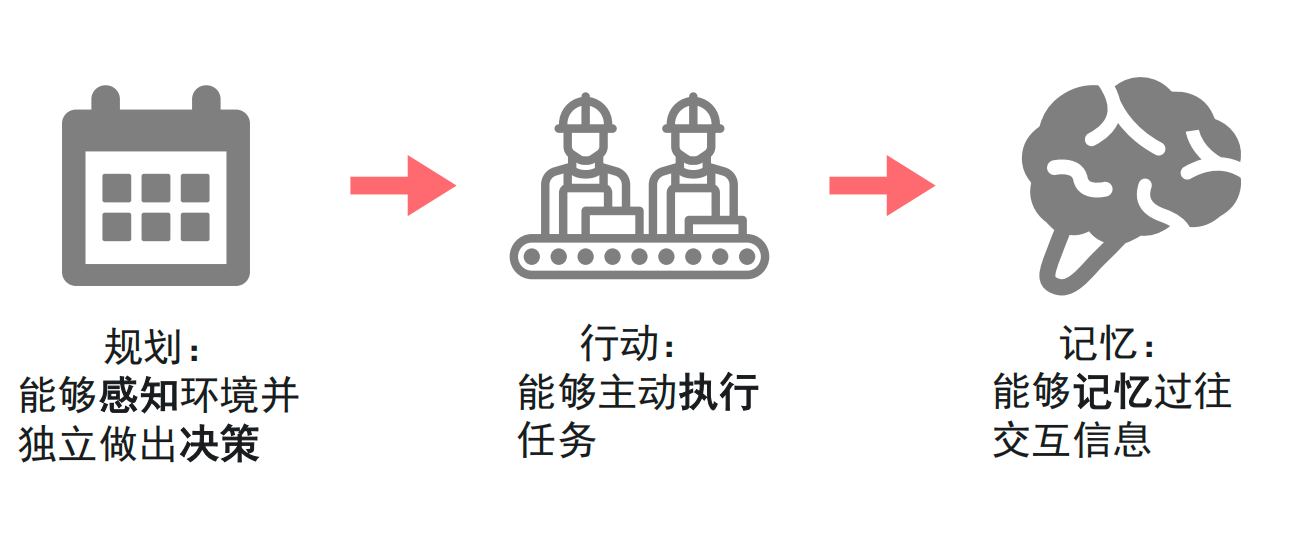 AI Visual Insight: The diagram presents Planning, Action, and Memory as three pillars, showing that an intelligent agent is not defined by a single capability but by a system structure jointly supported by decision, execution, and state layers.
AI Visual Insight: The diagram presents Planning, Action, and Memory as three pillars, showing that an intelligent agent is not defined by a single capability but by a system structure jointly supported by decision, execution, and state layers.
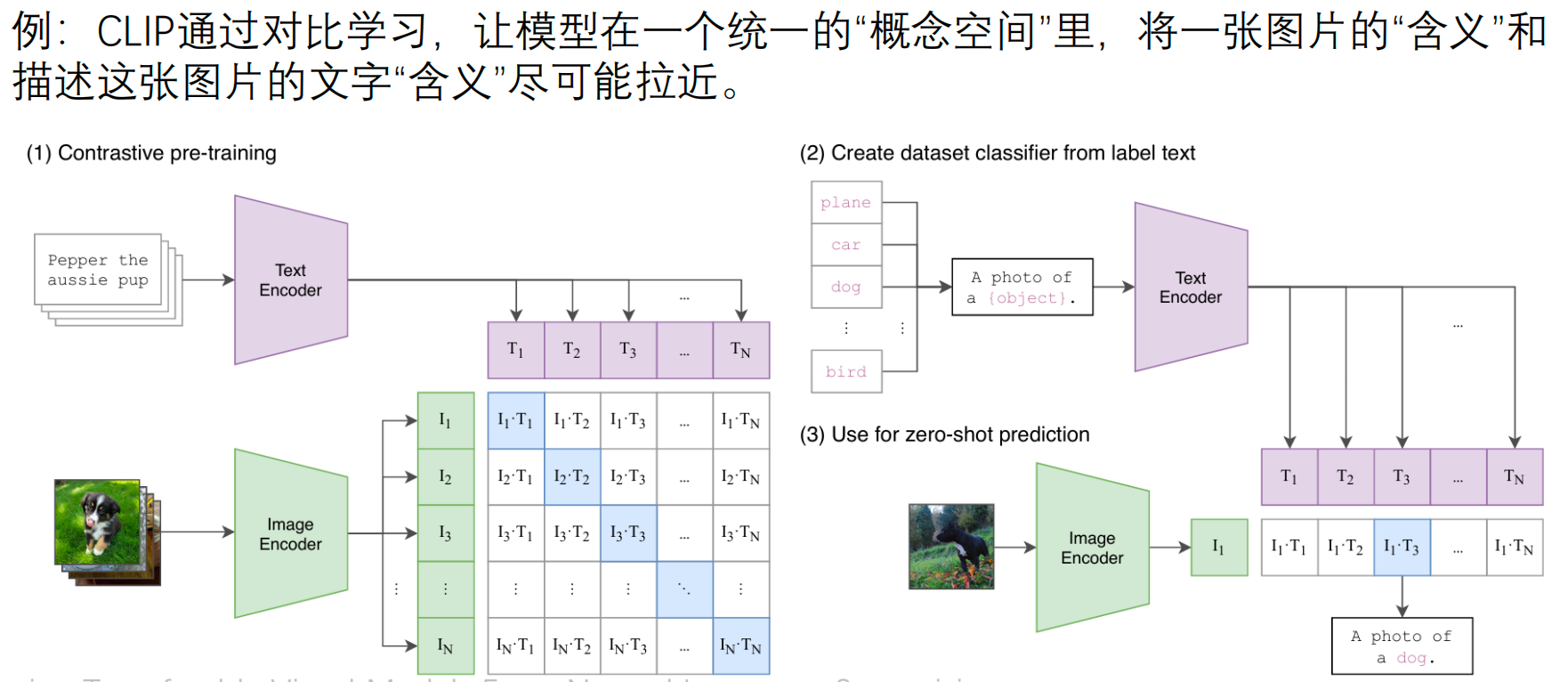 AI Visual Insight: The image reflects the idea of mapping images and text into the same semantic space. This multimodal alignment is the basis for giving Agents unified perceptual input, which is useful for retrieval, recognition, and cross-modal understanding.
AI Visual Insight: The image reflects the idea of mapping images and text into the same semantic space. This multimodal alignment is the basis for giving Agents unified perceptual input, which is useful for retrieval, recognition, and cross-modal understanding.
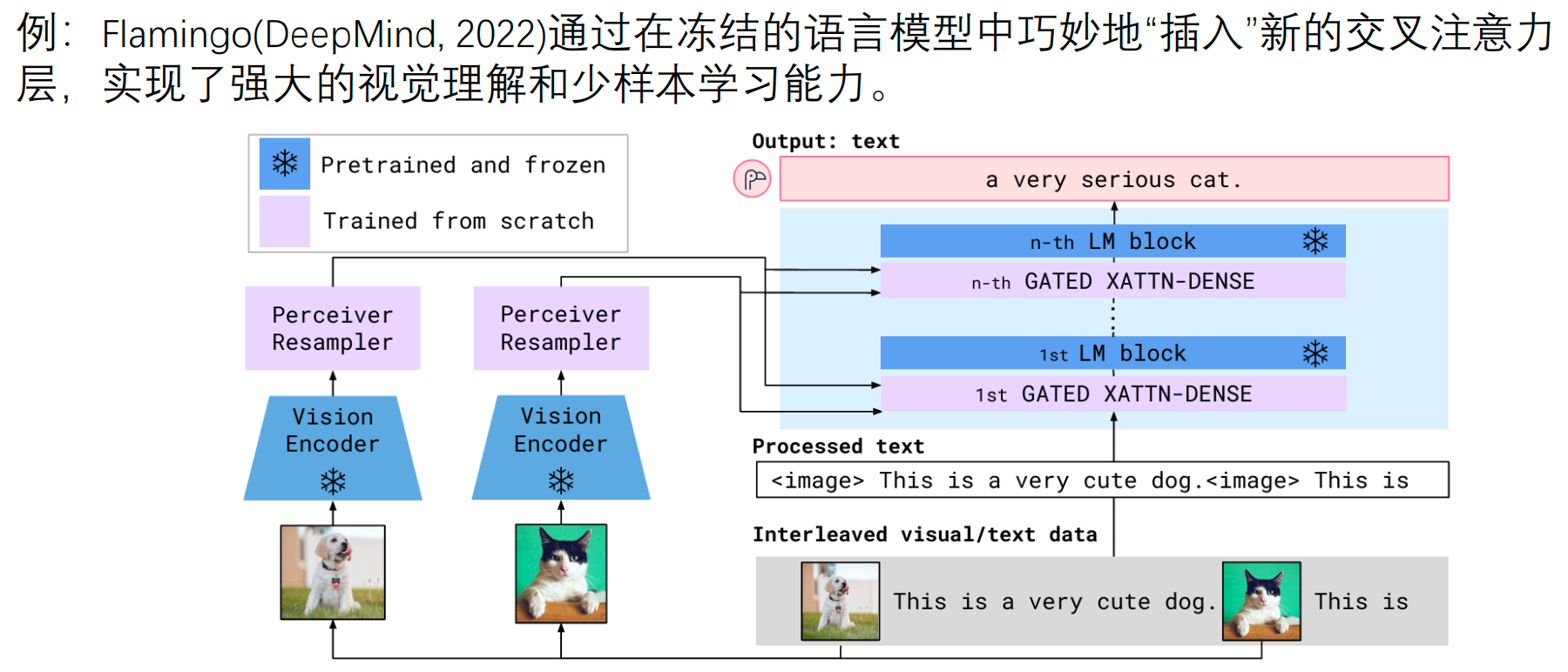 AI Visual Insight: The figure emphasizes that different modalities are connected to the language model through cross-attention or fusion mechanisms, making visual signals part of the reasoning context and strengthening decision-making in complex scenarios.
AI Visual Insight: The figure emphasizes that different modalities are connected to the language model through cross-attention or fusion mechanisms, making visual signals part of the reasoning context and strengthening decision-making in complex scenarios.
Action determines whether the model can actually complete the task
Action is not about directly outputting an answer. It is about calling tools. For example, an Agent might call Python to execute code, use the ArXiv API to fetch the latest papers, or use a search engine to supplement time-sensitive information.
Chain-of-Thought helps a model perform multi-step reasoning, but the engineering priority is not to make the model “explain its thinking.” The real goal is to convert steps into reliable actions. In an effective Agent, the core is a tool-based closed loop, not a long reasoning transcript.
def run_arxiv_query(keyword: str):
api = ArxivClient() # Initialize the academic search interface
papers = api.search(keyword, top_k=5) # Fetch metadata for the latest papers
return [p.title for p in papers]This code shows how an Agent turns “query papers” from a language task into an API action.
Memory determines whether multi-turn tasks remain stable over time
Short-term memory is usually formed by combining the System Prompt with conversation history. Its goal is to maintain role consistency and contextual continuity. As context windows grow larger, the pressure on short-term memory has already decreased significantly.
Long-term memory remains a critical challenge. When a task spans long time periods, multiple documents, or very large codebases, the system needs to compress historical interactions into events, preferences, and knowledge fragments, store them in external memory, and retrieve them on demand through RAG.
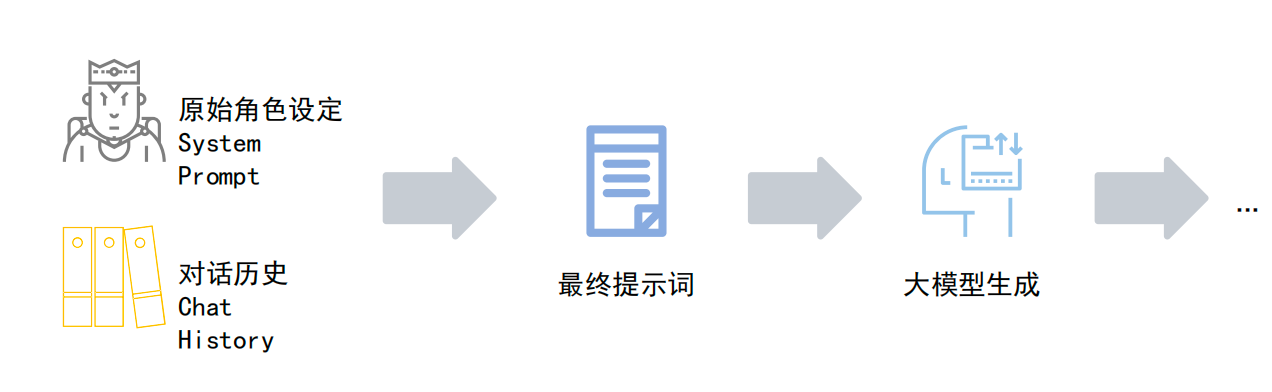 AI Visual Insight: The image shows the short-term memory management flow, where system settings and conversation history are combined and sent to the model. It emphasizes that deciding how much history to include and how to compress context are key engineering concerns.
AI Visual Insight: The image shows the short-term memory management flow, where system settings and conversation history are combined and sent to the model. It emphasizes that deciding how much history to include and how to compress context are key engineering concerns.
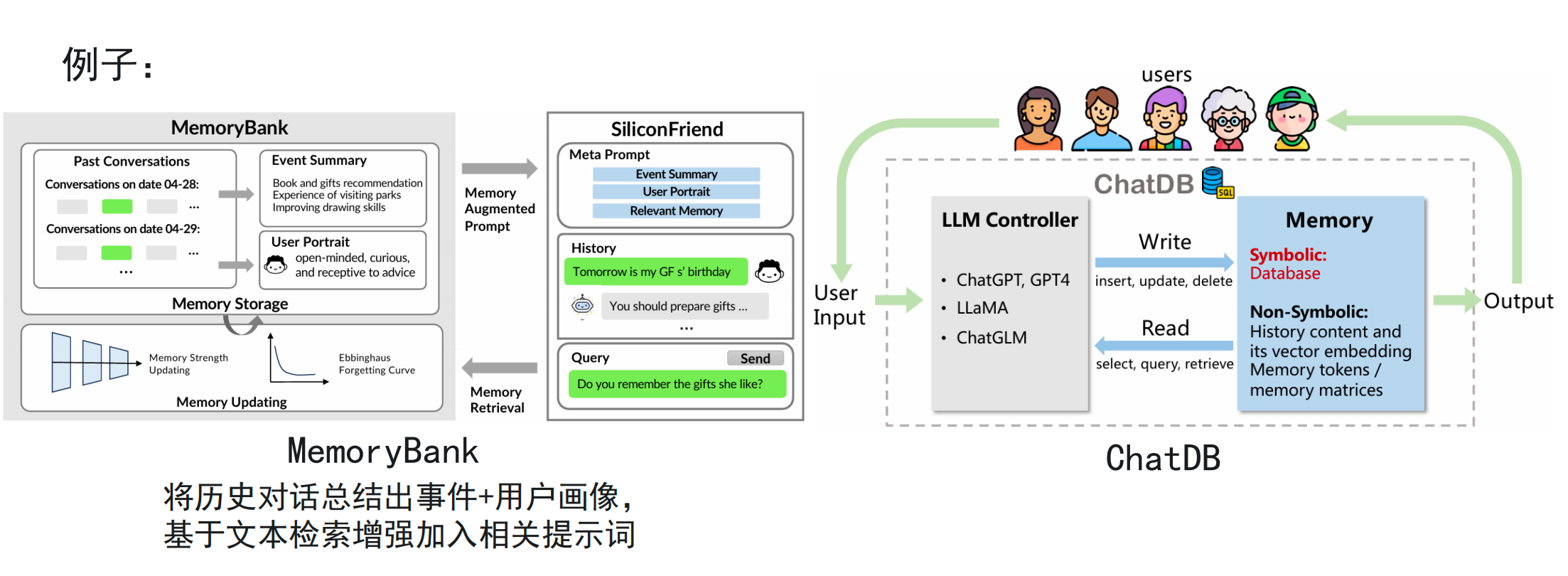 AI Visual Insight: The figure shows long-term memory being stored in an external database and then retrieved by a retrieval module based on relevance into the current reasoning path, demonstrating that RAG is the core approach that allows Agents to go beyond context window limits.
AI Visual Insight: The figure shows long-term memory being stored in an external database and then retrieved by a retrieval module based on relevance into the current reasoning path, demonstrating that RAG is the core approach that allows Agents to go beyond context window limits.
Multi-Agent systems improve success rates on complex tasks through role specialization
The core idea behind Multi-Agent systems is not to “stack more models,” but to assign clear responsibilities to different Agents and let them collaborate through communication. Typical benefits include task decomposition, stronger specialization, and improved fault tolerance.
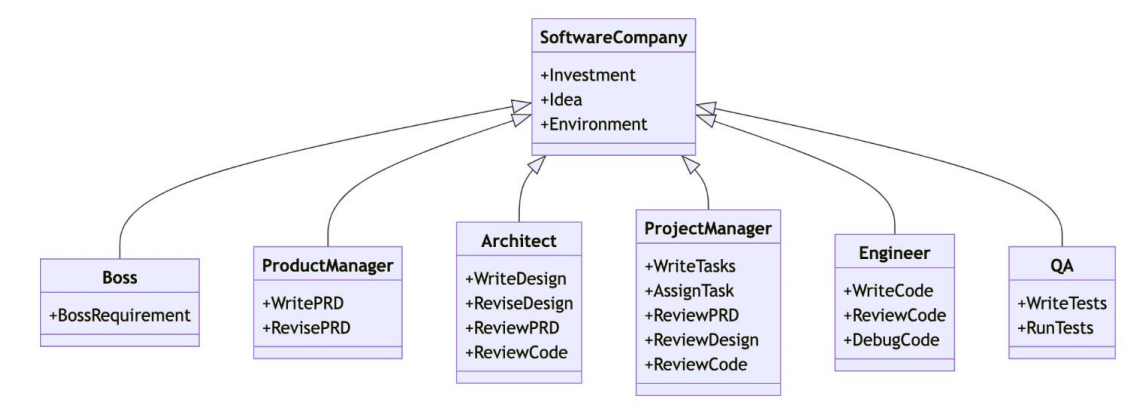 AI Visual Insight: The image emphasizes multiple role-based Agents collaborating around a shared goal. It shows that the key to Multi-Agent systems is not the number of models, but the design of responsibility boundaries, message passing, and state sharing.
AI Visual Insight: The image emphasizes multiple role-based Agents collaborating around a shared goal. It shows that the key to Multi-Agent systems is not the number of models, but the design of responsibility boundaries, message passing, and state sharing.
For example, a code generation task can define two roles: Programmer and Inspector. The former writes code, while the latter reviews it, identifies defects, and drives iteration. This is often more reliable than having a single model produce a one-shot output.
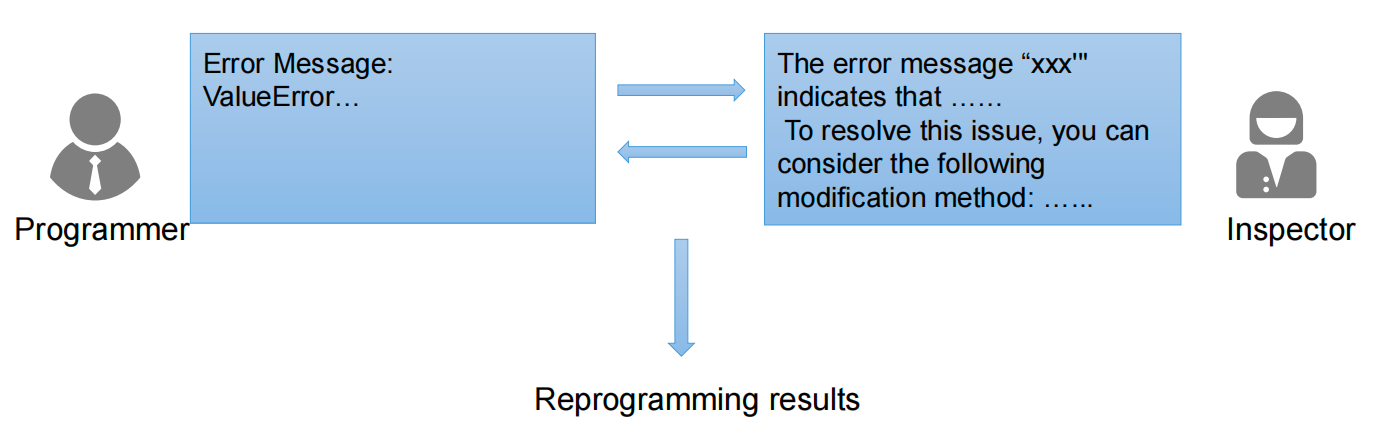 AI Visual Insight: The diagram uses a generate-review-revise loop to illustrate adversarial collaboration in Multi-Agent systems, which can significantly reduce hallucinations, bugs, and omissions in a single generation pass.
AI Visual Insight: The diagram uses a generate-review-revise loop to illustrate adversarial collaboration in Multi-Agent systems, which can significantly reduce hallucinations, bugs, and omissions in a single generation pass.
agents = [Programmer(), Inspector()]
code = agents[0].write("Build a weather query service") # The programmer produces the first draft
review = agents[1].review(code) # The inspector checks for errors and improvements
final_code = agents[0].revise(code, review) # Revise the code based on feedbackThis snippet demonstrates the most common two-Agent closed-loop collaboration pattern.
Coze and OpenManus reduce the barrier to building Agent applications
Coze is well suited for quickly building low-code Agents. It supports prompt optimization, plugin integration, workflow orchestration, and multi-platform publishing, making it a strong fit for business prototyping and lightweight application delivery.
In practice, three lessons matter most. First, use automatic optimization to generate a structured prompt. Second, tune Top P, context turns, and repetition penalty based on the task type. Third, do not blindly stack MCP plugins.
For developers who want local deployment or deep customization, open-source Agent frameworks such as OpenManus are a better fit. They can connect to third-party model APIs and reproduce the planning and execution capabilities of commercial Agents at lower cost.
Architecture choices must match task uncertainty
A single LLM fits simple Q&A. A Workflow fits fixed processes. A Multi-Agent system fits complex, open-ended tasks that require feedback and correction. These are not replacements for one another, but optimal choices under different constraints.
If task steps are strictly deterministic—for example, fixed-format grading or template-based long-form writing—a Workflow is often more reliable than an Agent. If the task changes dynamically and tool-calling branches are numerous, an Agent or Multi-Agent system is usually the better choice.
World models are pushing Agents from text systems toward environment-aware systems
A world model is not primarily about whether a system can “speak,” but whether it understands the rules of the physical world. This capability is especially visible in video generation, where systems such as Sora demonstrate spatial relationships, occlusion, and temporal continuity.
This means future Agents will not only process documents and APIs, but also embodied environments, 3D spaces, and continuous action sequences. At that point, perception, planning, and execution will become even more tightly integrated.
FAQ
FAQ 1: When should you use an Agent instead of a Workflow?
Use an Agent when the task path is not fixed, requires dynamic decisions, or depends on tool feedback. Use a Workflow when the process is stable, can be predefined, and requires strong controllability.
FAQ 2: Are Multi-Agent systems always better than single-Agent systems?
Not necessarily. For simple tasks, Multi-Agent systems increase communication overhead and system complexity. They are only more advantageous when you need role specialization, cross-review, or fault tolerance.
FAQ 3: What are the most common reasons Agent systems fail?
There are usually three categories: too many attached tools causing poor tool selection, poorly designed memory leading to context drift, and a lack of result verification mechanisms that lets errors amplify through the pipeline.
Core Summary
This article systematically reconstructs the core knowledge framework of Agent and Multi-Agent systems. It covers the three foundational capabilities of planning, action, and memory; explains the differences between Agents, Workflows, and Multi-Agent systems; and uses Coze, OpenManus, RAG, and MCP to illustrate implementation methods and parameter-tuning best practices.