[AI Readability Summary]
Agno v2.5.17 is a focused minor release centered on stability and control. It adds a toggle to disable Claude file references, allows GitHubConfig repositories to be specified per request, and fixes several production-impacting issues across streaming cancellation, component loading, JSON fidelity, and MCP initialization. Keywords: Agno, GitHubConfig, streaming stability.
Technical specifications provide a quick snapshot
| Parameter | Details |
|---|---|
| Project Name | Agno |
| Version | v2.5.17 |
| Primary Language | Python |
| Typical Protocols | HTTP/HTTPS, MCP, Streaming Responses |
| Project Positioning | Multi-agent and workflow development framework |
| Star Count | Not provided in the source |
| Core Dependencies | LLM Provider, knowledge base components, Router, GitHubConfig |
 AI Visual Insight: This image shows a release page or release notes interface. The core focus is the publication point for Agno v2.5.17, helping developers quickly verify the version number, change entry point, and release context.
AI Visual Insight: This image shows a release page or release notes interface. The core focus is the publication point for Agno v2.5.17, helping developers quickly verify the version number, change entry point, and release context.
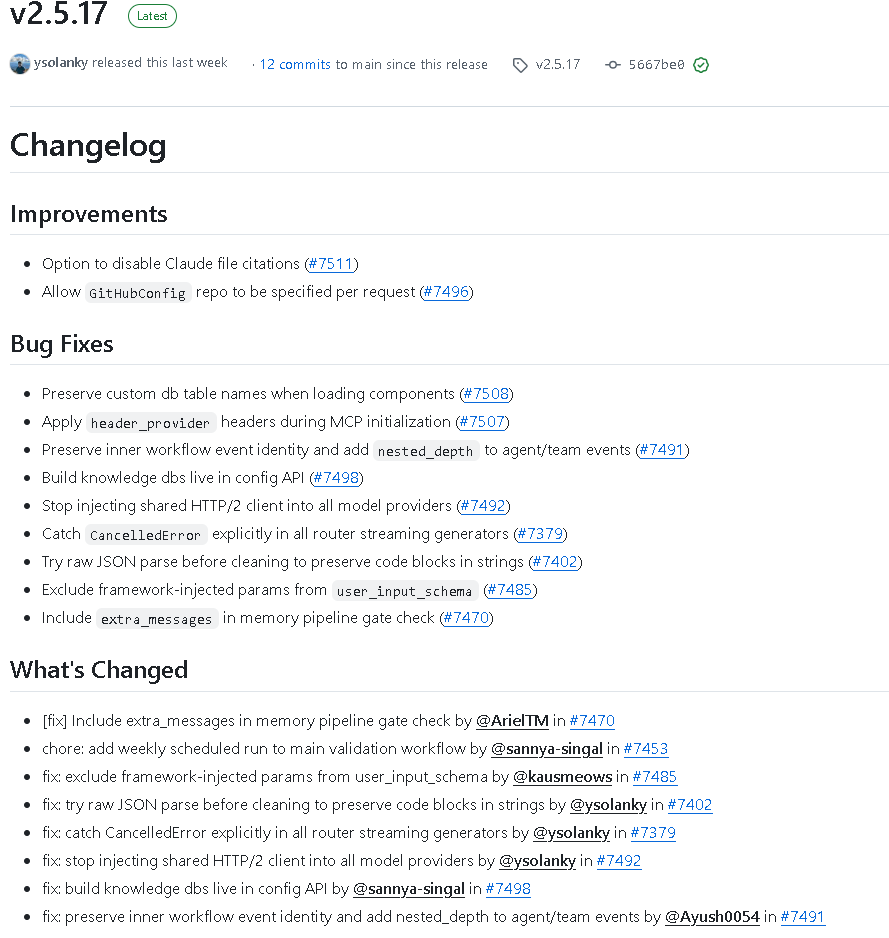 AI Visual Insight: This image presents a summary of updates or a change list view, typically used to centralize new capabilities and bug fixes so engineering teams can quickly locate affected modules from the release page.
AI Visual Insight: This image presents a summary of updates or a change list view, typically used to centralize new capabilities and bug fixes so engineering teams can quickly locate affected modules from the release page.
 AI Visual Insight: This image looks more like a full changelog or commit history screenshot, showing that the release covers a broad repair surface across configuration, events, streaming, parsing, and component loading.
AI Visual Insight: This image looks more like a full changelog or commit history screenshot, showing that the release covers a broad repair surface across configuration, events, streaming, parsing, and component loading.
This update is fundamentally a production-focused stability iteration
Agno v2.5.17 is not a major release, but its value is concentrated. On one side, it improves configuration flexibility. On the other, it fixes several low-level details that directly affect production behavior. This matters especially for multi-agent systems, knowledge base workflows, MCP integrations, and streaming output scenarios.
The changes fall into two categories. There are only two new features, but both are highly practical. The bug fixes are more numerous, and most target real engineering problems such as distorted edge-case behavior, lost context, or insufficient runtime stability.
Two new capabilities directly improve configuration control
The first new capability lets you disable Claude file references. In user-facing products, reference metadata is not always something you want to expose. Developers can now decide whether file references should appear in responses, making it easier to control response format and reduce information noise.
The second change allows the repo field in GitHubConfig to be specified per request. This means repository selection no longer has to remain statically bound to global configuration. You can now switch repositories dynamically by user, task, or project. This is critical for multi-repository retrieval, code Q&A, and automated analysis workflows.
from agno.config import GitHubConfig
# Keep a default repository in global configuration
base_config = GitHubConfig(owner="agno-agi", repo="agno")
def build_request_config(repo_name: str):
# Override repo per request for dynamic multi-project access
return GitHubConfig(owner="agno-agi", repo=repo_name)This snippet shows how to extend GitHub repository selection from static global configuration to dynamic request-level configuration.
Multiple fixes are removing uncertainty from real-world engineering
Preserving custom database table names during component loading is a classic example of a fix that looks small but has large impact. Many projects customize table names by tenant, environment, or business domain. If the loading process rewrites those names, it can cause migration failures, mapping errors, or read/write mismatches.
Correctly applying headers returned by header_provider during MCP initialization is another critical fix. Authentication, tenant identification, and context routing often depend on request headers. If headers are dropped during initialization, every later interaction may run on the wrong session context.
Workflow events and knowledge base building are now more trustworthy
This release preserves internal workflow event identity and adds nested_depth to agent and team events. That means complex workflows now carry more complete hierarchical information for tracing, auditing, and visualization. It becomes much easier to investigate nested calls and collaborative team execution paths.
At the same time, the knowledge base database in the config API is now built in real time. Previously, delayed construction or state desynchronization could cause the configuration layer to show something different from the data actually available. Now the pipeline is much closer to a model where configuration changes take effect immediately.
async def stream_with_cancel_guard(generator):
try:
async for chunk in generator:
yield chunk # Stream chunks normally
except asyncio.CancelledError:
# Explicitly catch cancellation to avoid noisy errors on interruption
returnThis pattern reflects the direction of the v2.5.17 fix for router streaming generators, with an emphasis on handling cancellation gracefully.
Fixes across streaming, parsing, and schema generation deserve the most upgrade attention
Agno no longer injects a shared HTTP/2 client into every model provider. This is a low-level isolation improvement. While a shared client can reuse connections, it can also introduce compatibility issues, state contamination, or harder debugging. Removing the universal injection makes each provider’s network behavior more clearly bounded.
Explicitly catching CancelledError in all router streaming generators directly improves the stability of interactive applications. Frontend aborts, browser disconnects, and repeated user submissions all trigger cancellation paths. Without proper handling, both logs and runtime state can become messy.
JSON fidelity and input schema accuracy have been strengthened
Agno now attempts raw JSON parsing first and only enters a cleanup path if parsing fails. That order matters. Many structured outputs embed code blocks or formatted text internally, and premature cleanup can damage the original content. This is especially useful for code generation, document extraction, and structured response handling.
In addition, framework-injected parameters are now excluded from user_input_schema. As a result, generated input definitions are closer to the fields users actually need to provide. This improves frontend auto-generated forms, API documentation, and parameter validation consistency.
import json
def parse_response(raw_text: str):
try:
# Parse raw JSON first to preserve code blocks and original strings
return json.loads(raw_text)
except json.JSONDecodeError:
cleaned = raw_text.strip()
# Fall back to cleanup only after direct parsing fails
return json.loads(cleaned)This snippet captures the core idea: parse raw content first, then use cleanup only as a fallback, with the goal of preserving as much original content as possible.
The memory pipeline improvement closes the loop on context evaluation
This update includes extra_messages in the memory pipeline gate check. For applications that rely on supplemental messages to complete context, this is an essential fix. If those messages are ignored, memory gating may make decisions based on incomplete context, which can affect retrieval and reasoning quality.
Overall, v2.5.17 does not fix superficial feature gaps. It addresses common engineering issues such as coarse configuration control, incomplete context, ungraceful cancellation, and parsing that damages original content. For that reason, the benefits of upgrading usually become more visible in production environments.
This version should be prioritized for the following scenarios
If your system depends on multi-repository GitHub access, MCP authentication header forwarding, complex workflow event tracing, or long-lived streaming output, v2.5.17 is worth prioritizing. The issues it improves are high-frequency foundational problems that are often difficult to debug.
If your application also involves hot knowledge base configuration updates, structured JSON output, auto-generated input forms, or parallel calls across multiple providers, the value of this release becomes even greater. This is not a flashy feature release. It is an infrastructure hardening release.
FAQ provides structured answers
FAQ 1: What are the most important upgrades in Agno v2.5.17?
The most notable changes are two new capabilities plus a set of stability fixes: the ability to disable Claude file references, request-level repo support in GitHubConfig, and focused fixes for streaming cancellation, JSON fidelity, MCP headers, and preservation of table names during component loading.
FAQ 2: Why does per-request GitHub repository selection matter?
Because many AI agent applications do not serve just one code repository. They need to switch context by user, project, or task. Request-level repository selection makes it much easier to build unified services for multi-repository retrieval, code review, and repository Q&A.
FAQ 3: Why is this version more production-friendly?
Because it fixes the edge cases that appear most often in production, such as exception handling after canceled streaming requests, coupling introduced by a shared HTTP/2 client, JSON cleanup that accidentally damages code blocks, and state mismatches between the configuration layer and the knowledge base.
Core summary: Agno v2.5.17 focuses on configuration flexibility and runtime stability. It adds a Claude file reference toggle, enables per-request repository selection in GitHubConfig, and fixes key issues across streaming cancellation, component loading, JSON fidelity, MCP headers, and knowledge base building. It is a strong upgrade for multi-agent, knowledge base, and multi-provider environments.