This article focuses on building a local private RAG question-answering system with Spring Boot, LangChain4j, and Ollama. It addresses stale model knowledge and hallucinations by implementing document vectorization, semantic retrieval, and fact-grounded answer generation. Keywords: RAG, LangChain4j, Ollama.
The technical specification snapshot clarifies the system baseline
| Parameter | Details |
|---|---|
| Programming Language | Java 17 |
| Core Framework | Spring Boot 3.2.5 |
| AI Orchestration | LangChain4j 1.0.0-beta4 |
| Model Protocol | Ollama Local HTTP API |
| Chat Model | qwen2:7b |
| Embedding Model | nomic-embed-text |
| Vector Store | EmbeddingStore (supports in-memory or persistent implementations) |
| Document Parsing | Apache PDFBox Parser |
| GitHub Stars | Not provided in the source |
| Typical Use Cases | Enterprise knowledge bases, internal Q&A, private document retrieval |
RAG is the key mechanism for making LLM answers more trustworthy
LLMs are excellent at general-purpose generation, but two limitations often surface in enterprise applications: their knowledge is frozen at training time, and they tend to hallucinate when they lack supporting evidence. For private policies, internal workflows, and project documentation, these issues directly reduce usability.
The core value of RAG is not to replace the model, but to retrieve facts first and then let the model generate an answer based on those facts. This shifts the paradigm from “model memory” to “model + verifiable context,” which is far better suited for enterprise intranets and domain-specific question answering.
The RAG workflow can be split into two stages
The first stage is indexing: load documents, extract text, split them into chunks, generate embeddings, and write them into a vector store. The second stage is querying: vectorize the user question, run similarity retrieval, inject the results into the prompt, and let the model generate the final answer.
Raw documents -> Parsing -> Chunking -> Vectorization -> Storage
User question -> Question vectorization -> Similarity retrieval -> Context augmentation -> Answer generationAt its core, this workflow supplements “non-updatable parametric knowledge” with “externally maintained knowledge that can be updated in real time.”
LangChain4j already provides the full set of RAG building blocks
In the Java ecosystem, one of LangChain4j’s biggest strengths is its clean abstraction model. Document represents the source document, DocumentParser handles format parsing, DocumentSplitter handles chunking, EmbeddingModel generates vectors, and EmbeddingStore manages storage.
On the retrieval side, you will also use ContentRetriever and RetrievalAugmentor. The former recalls relevant segments, while the latter injects retrieval results into the prompt context. AiServices then assembles these capabilities into declarative AI services, which reduces integration effort for business applications.
Prepare the local embedding model before deployment
If you use Ollama to host embeddings, pull the model first. This approach also avoids DLL extraction or permission issues that sometimes appear on Windows with certain local inference libraries.
ollama pull nomic-embed-textThis command downloads the local embedding model that will be used to vectorize both documents and user questions.
Dependency configuration defines the system’s foundational capability boundaries
At a minimum, your Maven dependencies should cover Spring Web, the LangChain4j Spring Boot Starter, the Ollama Starter, and document parsing modules. The original setup uses a BOM to unify versions and avoid incompatibilities between components.
<properties>
<java.version>17</java.version>
<langchain4j.version>1.0.0-beta4</langchain4j.version>
</properties>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama-spring-boot-starter</artifactId>
</dependency>This section defines the minimum runtime skeleton for Java, Spring Boot, and Ollama integration.
Application configuration must declare both the chat model and the embedding model
The chat model is responsible for generating the final answer, while the embedding model computes semantic vectors. Their responsibilities differ, so they do not need to be the same model. In production, teams often choose a lighter embedding model to reduce indexing and retrieval costs.
langchain4j:
ollama:
chat-model:
base-url: http://localhost:11434
model-name: qwen2:7b
temperature: 0.7
timeout: PT600S
embedding-model:
base-url: http://localhost:11434
model-name: nomic-embed-textThis configuration defines the dual-model responsibility split in local Ollama.
The document ingestion service is the indexing entry point of RAG
The indexing service is responsible for reading knowledge files at startup and passing them to EmbeddingStoreIngestor for chunking, vectorization, and persistence into the vector store. This allows the knowledge base to become available for question answering as soon as the application starts.
@Service
public class DocumentIndexingService {
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private EmbeddingStore
<TextSegment> embeddingStore; // Inject the vector store
@PostConstruct
public void init() throws IOException {
ClassPathResource resource = new ClassPathResource("knowledge/knowledge.txt");
Path docPath = resource.getFile().toPath();
Document document = FileSystemDocumentLoader.loadDocument(docPath); // Load the document
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel) // Use the embedding model for vectorization
.embeddingStore(embeddingStore) // Write into the vector database
.build();
ingestor.ingest(List.of(document)); // Execute ingestion
}
}This code automatically indexes the knowledge document, which is a prerequisite for making the Q&A system usable.
Retrieval augmentation configuration determines whether answers are truly grounded in source material
The key to RAG is not simply “connecting a model,” but whether retrieval results can be injected reliably into the answer generation path. Here, EmbeddingStoreContentRetriever is used to fetch relevant segments, and DefaultRetrievalAugmentor enhances the prompt context with those results.
@Bean
public RAGAssistant ragAssistant(ChatModel chatModel,
EmbeddingStore
<TextSegment> embeddingStore,
EmbeddingModel embeddingModel) {
var contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3) // Return at most 3 context segments
.minScore(0.7) // Filter out low-relevance results
.build();
var retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.contentRetriever(contentRetriever)
.build();
return AiServices.builder(RAGAssistant.class)
.chatModel(chatModel)
.retrievalAugmentor(retrievalAugmentor) // Bind the RAG augmentor
.build();
}This configuration connects vector retrieval to the actual answer-generation pipeline.
The assistant interface should explicitly constrain the answer boundary
If the system prompt does not emphasize “answer only based on the provided context,” the model may still improvise even when relevant materials have been retrieved. For that reason, the interface definition must include a restrictive SystemMessage.
public interface RAGAssistant {
@SystemMessage("You are a knowledge base assistant. Answer questions based only on the provided context. If the answer cannot be found in the context, say so honestly.")
String chat(@UserMessage String userMessage);
}This interface definition turns “answer truthfully and do not fabricate” into a system-level behavior.
Exposing an HTTP endpoint enables end-to-end verification
The controller can remain minimal and simply pass the user question to RAGAssistant. This works well for browser-based debugging and also makes it easy to integrate with a frontend page or enterprise IM system later.
@RestController
@RequestMapping("/rag")
public class RAGController {
private final RAGAssistant ragAssistant;
public RAGController(RAGAssistant ragAssistant) {
this.ragAssistant = ragAssistant;
}
@GetMapping("/ask")
public String ask(@RequestParam String question) {
return ragAssistant.chat(question); // Generate the answer based on retrieved results
}
}This code provides a question-answering entry point that you can test immediately.
A sample document helps you validate whether retrieval is working
You can create a sample knowledge file with employee policies such as office hours and annual leave rules. Then visit /rag/ask?question=What time do employees leave work?. If the response is 18:00, both the retrieval path and the answer-generation path are working correctly.
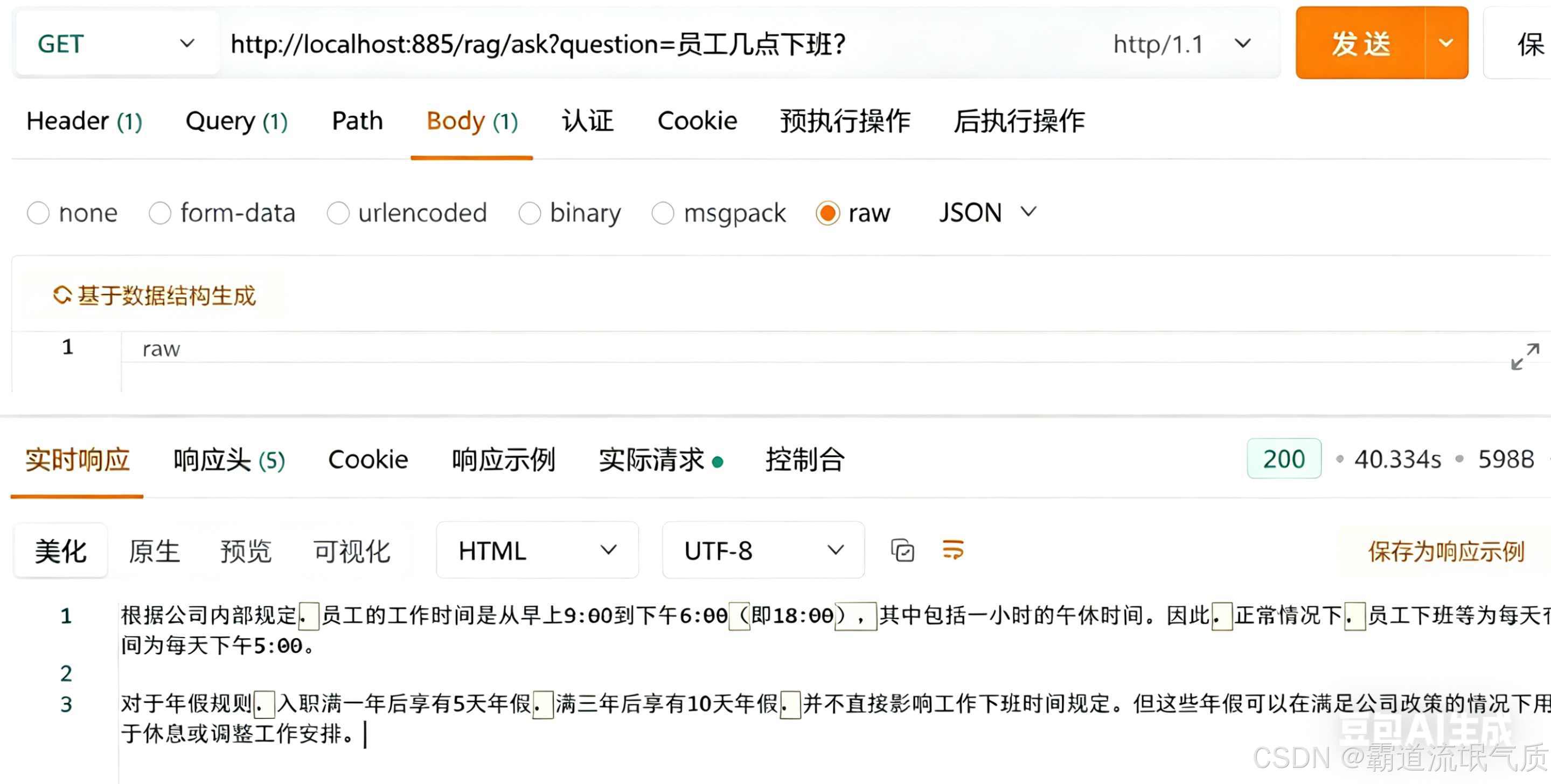 AI Visual Insight: The image shows the Q&A result returned in a browser after accessing the local RAG endpoint. The interface directly returns an answer generated from the knowledge document, which helps validate endpoint connectivity, retrieval quality, and whether the model is answering from context.
AI Visual Insight: The image shows the Q&A result returned in a browser after accessing the local RAG endpoint. The interface directly returns an answer generated from the knowledge document, which helps validate endpoint connectivity, retrieval quality, and whether the model is answering from context.
Common issues usually surface in the embedding, chunking, and storage layers
Failures when loading local embedding models are often caused by permission or DLL issues in local inference libraries. The original solution switches to Ollama embeddings, which is a more stable engineering choice.
When retrieval is inaccurate, the root cause is often not the model itself. More commonly, chunks are too large or too fragmented, or the embedding model does not align well with the domain semantics. Start by tuning chunk size, overlap length, and minScore, and only then consider replacing the embedding model.
Production hardening requires attention to persistence and performance
If you use an in-memory EmbeddingStore, the index will be lost after a restart. In production, you should move to a persistent vector database such as Redis, Chroma, Milvus, or Qdrant.
Slow responses usually fall into two categories: slow retrieval and slow generation. You can improve the former with better indexing structures or caching for hot questions. You can optimize the latter by using a smaller model, GPU inference, or shorter context windows.
FAQ provides structured answers to common implementation questions
1. Why do I still need RAG if I am already using a local model?
Because a local LLM is still constrained by training data freshness and hallucination risk. RAG provides external fact injection and does not depend on whether the model has internet access.
2. Retrieval hits the right content, but the answer is still inaccurate. What should I check first?
First, verify whether the SystemMessage enforces “answer only from context.” Then check whether maxResults, minScore, and the chunking strategy are configured appropriately.
3. Can this solution be used directly for an enterprise knowledge base?
Yes, it can serve as a minimum viable implementation. However, a production deployment should also add a persistent vector database, permission isolation, incremental document updates, audit logs, and monitoring metrics.
[AI Readability Summary] This article reconstructs a private RAG implementation based on Spring Boot, LangChain4j, and Ollama. It covers document ingestion, vector-based retrieval, retrieval-augmented generation, API exposure, and common troubleshooting practices, making it a practical starting point for Java developers who want to build a local knowledge base Q&A system.