This article explains how deep learning is reshaping the full 3D reconstruction pipeline—from input modality selection and capture quality control to pose estimation, MVS, NeRF/3DGS, semantic enhancement, and deployment optimization. The core challenges are weak robustness, cross-scene degradation, and operational complexity. Keywords: 3D reconstruction, deep learning, production deployment.
Technical Specification Snapshot
| Parameter | Details |
|---|---|
| Core domains | Computer Vision / 3D Reconstruction / Neural Rendering |
| Primary languages | Python, C++ |
| Key protocols/formats | RGB, RGB-D, LiDAR, PLY, OBJ, TSDF |
| GitHub stars | Not provided in the source |
| Core dependencies | PyTorch, CUDA, OpenCV, COLMAP, Open3D |
The 3D reconstruction path depends first on how the task is defined
The success or failure of a 3D reconstruction project is rarely determined by the accuracy of a single model. It is usually determined by whether the task entry point is defined correctly. Input modality, scene attributes, and business objectives directly constrain the upper bound of downstream pose estimation, depth inference, representation, and deployment strategy.
Monocular input works for low-cost capture, but it lacks absolute scale. Multi-view input provides stable parallax. Video offers temporal continuity. RGB-D is well suited for fast indoor reconstruction. LiDAR fits large-scale, high-precision environments. In practice, teams should not start by asking, “Which foundation model should we use?” They should start by asking, “What information can we actually observe?”
 AI Visual Insight: The image shows the information limits of using monocular images as reconstruction input: you only get 2D texture, without direct depth or scale. As a result, downstream stages must recover 3D constraints through learned depth priors, semantic layout, or multi-frame geometric relationships.
AI Visual Insight: The image shows the information limits of using monocular images as reconstruction input: you only get 2D texture, without direct depth or scale. As a result, downstream stages must recover 3D constraints through learned depth priors, semantic layout, or multi-frame geometric relationships.
Scene constraints define the feasible boundary of the algorithm
Indoor versus outdoor scenes, static versus dynamic environments, small objects versus large-scale spaces, and diffuse versus reflective or transparent materials all lead to different error modes. For example, in dynamic scenes, if you do not separate static and moving regions first, SfM and MVS can easily produce ghosting and trajectory drift.
A more practical engineering objective is to rank geometry accuracy, visual fidelity, real-time performance, and deployment cost—instead of blindly chasing the strongest possible model.
def select_pipeline(modality, dynamic, priority):
# Select the base reconstruction path from the input modality
if modality == "multi_view":
base = "SfM + MVS"
elif modality == "video":
base = "VO/SLAM + Dense Fusion"
else:
base = "Monocular Depth + Geometry"
# Dynamic scenes must isolate moving regions first
if dynamic:
base += " + Dynamic Mask"
# Add appearance or efficiency modules based on the objective
if priority == "render":
base += " + NeRF/3DGS"
return baseThis code illustrates a core principle: a 3D reconstruction solution should be driven jointly by input conditions and target outcomes, not by a fixed template.
Data capture quality control is the highest-ROI optimization point
In real-world projects, poor data can amplify downstream errors by orders of magnitude. The most valuable role of deep learning during acquisition is not to generate 3D output directly, but to govern the front end: image quality assessment, keyframe selection, dynamic interference detection, and active recapture guidance.
Key metrics include usable frame rate, exposure and sharpness scores, coverage, the proportion of dynamic regions, and downstream SfM inlier rate and depth completeness. Once front-end quality control is effective, reconstruction success rate, completeness, and total processing time usually improve together.
 AI Visual Insight: The figure shows a typical online capture governance architecture: the input frame stream passes through quality scoring, dynamic detection, keyframe decision, and feedback modules to form a closed loop of “capture while evaluating.” This significantly reduces the chance that blurry frames, duplicate frames, and viewpoint blind spots will enter downstream reconstruction.
AI Visual Insight: The figure shows a typical online capture governance architecture: the input frame stream passes through quality scoring, dynamic detection, keyframe decision, and feedback modules to form a closed loop of “capture while evaluating.” This significantly reduces the chance that blurry frames, duplicate frames, and viewpoint blind spots will enter downstream reconstruction.
Geometric front-end enhancement should follow a hybrid paradigm of learning and constraints
Camera calibration, pose estimation, and multi-sensor registration form the geometric foundation of the entire pipeline. Learned models are effective for feature enhancement, match ranking, uncertainty modeling, and coarse cross-modal registration. Geometric methods are responsible for interpretable optimization and global consistency.
Compared with black-box end-to-end pose prediction, a more robust engineering pattern is “learned features + learned matching + PnP/BA/graph optimization.” This approach improves noise robustness and cross-domain generalization while preserving diagnosable intermediate signals.
matches = matcher(img1, img2) # Learned model outputs candidate matches
weights = confidence_net(matches) # Predict the confidence of each match
pose = solve_pnp(matches, weights) # Estimate pose with a weighted geometric solver
refined = bundle_adjustment(pose) # Use BA for global consistency optimizationThis code captures the central idea: learned modules provide better observations, while geometric modules compute more trustworthy solutions.
Depth estimation and multi-view geometry are the middle-layer hub
The most important change that deep learning brings to 3D reconstruction is that depth estimation no longer outputs only numeric depth values. It now also outputs confidence and geometric consistency signals. As a result, downstream fusion no longer performs naive averaging, but uncertainty-aware weighted decision making.
Monocular depth is useful for initializing geometry. MVS networks handle multi-view depth inference. Geometric consistency modules filter false depth. Temporal models stabilize video reconstruction. During the NeRF/3DGS stage, depth priors can further constrain neural representations so that they converge to more realistic geometry.
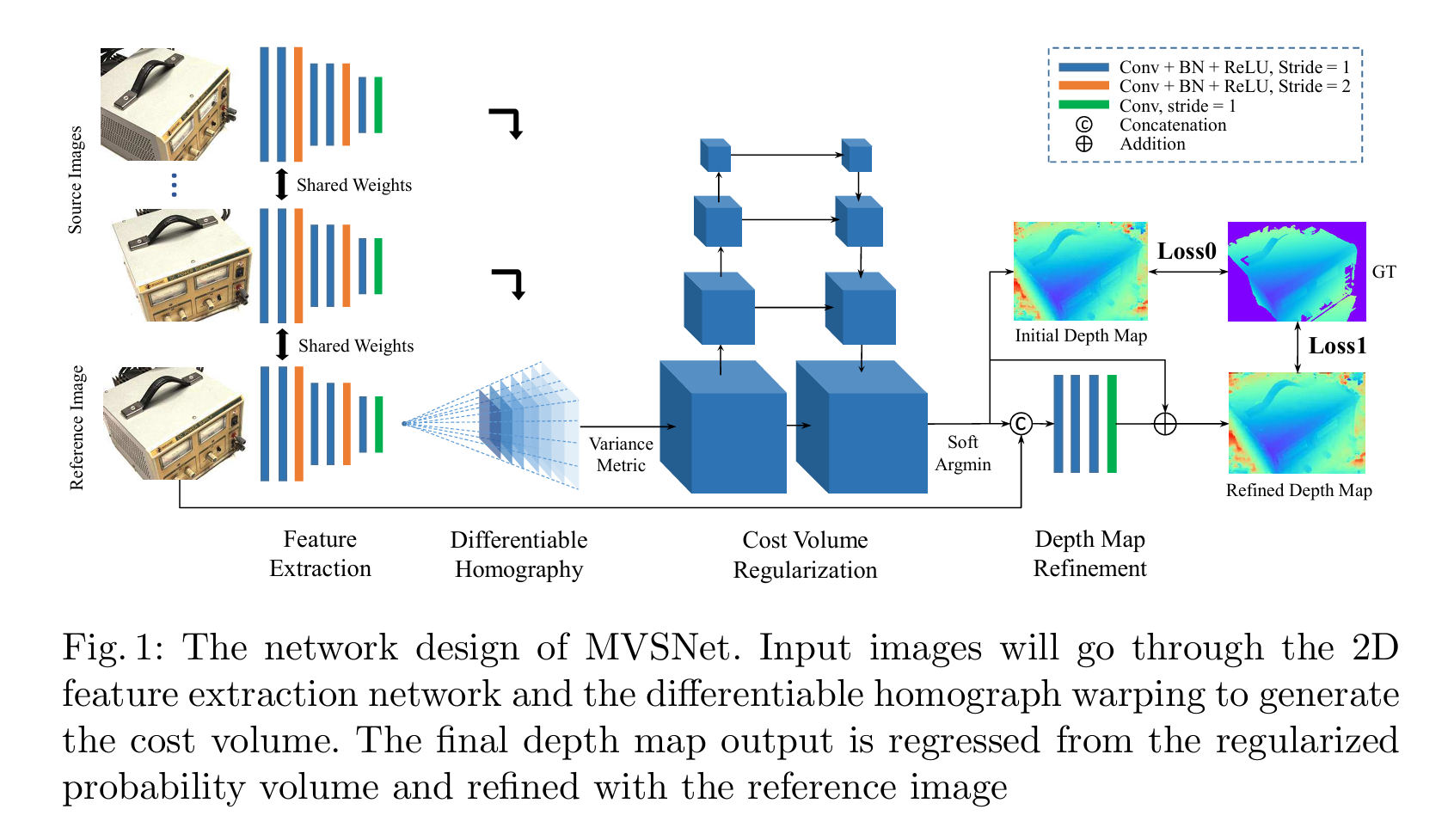 AI Visual Insight: The figure corresponds to a typical multi-view depth inference workflow, which usually includes a reference view, source views, cost volume construction, and depth probability regression. The key technical idea is to build cross-view pixel correspondences with differentiable homography warping, then regularize the depth distribution with 3D convolutions or attention modules.
AI Visual Insight: The figure corresponds to a typical multi-view depth inference workflow, which usually includes a reference view, source views, cost volume construction, and depth probability regression. The key technical idea is to build cross-view pixel correspondences with differentiable homography warping, then regularize the depth distribution with 3D convolutions or attention modules.
Dense representations and neural representations should be chosen based on the delivery target
Point clouds are suitable for fast fusion and measurement. Meshes are better for delivery, simulation, and printing. TSDF works well for real-time incremental mapping. Implicit fields are useful for continuous surface representation. NeRF and 3DGS are more appropriate for high-fidelity novel view synthesis. There is no universally optimal representation—only a task-optimal one.
If the business goal is industrial accuracy, prioritize MVS + Dense Fusion + Mesh Repair. If the goal is digital content production, consider NeRF/3DGS with depth-based geometric constraints.
 AI Visual Insight: The image shows the result of fusing multi-view depth into a unified point cloud space. The key observation is that depth maps from different viewpoints are projected into the same coordinate system and merged by confidence, making it possible to inspect local density, boundary quality, and outlier suppression.
AI Visual Insight: The image shows the result of fusing multi-view depth into a unified point cloud space. The key observation is that depth maps from different viewpoints are projected into the same coordinate system and merged by confidence, making it possible to inspect local density, boundary quality, and outlier suppression.
Appearance recovery and dynamic consistency determine final usability
Correct geometry does not guarantee a deliverable result. Texture fusion, super-resolution enhancement, lighting decomposition, reflective and transparent material handling, and PBR material recovery determine whether the model actually looks realistic. For materials such as car paint, glass, and metal, the system must also model view-dependent appearance to avoid rendering artifacts.
Dynamic scenes further require temporal consistency. You must suppress flicker, jitter, and label switching across pose, depth, and semantic layers. Otherwise, even if individual frames look correct, the full sequence is still unusable.
 AI Visual Insight: The figure highlights the key change when dynamic scenes extend static 3D reconstruction into 4D spatiotemporal representation: the system must not only recover spatial structure, but also track deformation, motion, and occlusion over time. This places much higher demands on temporal consistency and object separation.
AI Visual Insight: The figure highlights the key change when dynamic scenes extend static 3D reconstruction into 4D spatiotemporal representation: the system must not only recover spatial structure, but also track deformation, motion, and occlusion over time. This places much higher demands on temporal consistency and object separation.
Semantic enhancement and post-processing close the product loop
Semantic enhancement upgrades a 3D model from a geometric asset into a searchable, editable, decision-ready data asset. Typical capabilities include mapping 2D semantics into 3D, instance-level object separation, open-vocabulary semantic retrieval, and semantic quality alert loops.
Final post-processing turns a research prototype into a deployable asset: denoising, hole filling, LOD generation, compression, and cross-device adaptation. A mature system is not defined by one impressive reconstruction result, but by long-term stability, observability, and rollback support.
A deployable 3D reconstruction engineering framework can be organized like this
pipeline = [
"capture_governance", # Capture quality governance
"calibration_and_pose", # Calibration and pose estimation
"depth_and_mvs", # Depth and multi-view geometry
"dense_representation", # Dense representation generation
"appearance_recovery", # Texture and material recovery
"dynamic_semantic_layer", # Dynamic and semantic enhancement
"postprocess_deploy" # Post-processing and deployment optimization
]This code summarizes the complete engineering chain: deep learning is no longer a point solution for improving one module. It becomes a system-level capability spanning input governance, geometric enhancement, representation learning, and the operations feedback loop.
FAQ
Q: Which deep learning module should a 3D reconstruction project prioritize first?
A: Start with data capture governance and front-end pose enhancement. They require relatively low investment, produce stable returns, and directly reduce downstream failure rates and rework costs.
Q: Can NeRF or 3DGS completely replace traditional SfM/MVS?
A: No. Neural representations excel at appearance modeling and novel view synthesis, but geometric interpretability, editability, and industrial measurement workflows still depend on traditional geometric pipelines.
Q: How can you tell whether the current system is ready for production deployment?
A: Check three things: whether it has a quality scoring and alert loop, whether it outputs confidence rather than only final results, and whether it supports template-based multi-scene deployment with rollback and rerun capability.
Core Summary
This article reconstructs the engineering pipeline of deep learning for 3D reconstruction from end to end. It covers task definition, capture governance, pose estimation, depth and MVS, dense representations, appearance recovery, dynamic temporal modeling, semantic enhancement, and post-processing for deployment. The key takeaway is a production-ready paradigm built on learned enhancement, geometric constraints, and closed-loop quality control.