DeepSeek-V4 is an open-source MoE large language model built for million-token context windows. Through CSA/HCA hybrid attention, mHC hyper-connections, and the Muon optimizer, it addresses the high cost of long-context inference, KV cache bloat, and insufficient training stability. Keywords: DeepSeek-V4, hybrid attention, long-context inference.
Technical specifications provide a quick snapshot
| Parameter | Details |
|---|---|
| Model family | DeepSeek-V4-Pro / DeepSeek-V4-Flash |
| Architecture | MoE + Hybrid Attention (CSA/HCA) |
| Context length | Native support for 1M tokens |
| Language | LLM engineering stack centered on the Python/CUDA ecosystem |
| Protocol / License | MIT License |
| Training data scale | More than 32T bytes of high-quality corpus data |
| Core dependency ideas | Transformer, MQA, Muon, AdamW, GRPO, ZeRO-like Sharding |
| Public release format | 4 open-weight models |
| Star count | Not provided in the source input |
DeepSeek-V4 turns million-token context from a demo feature into a deployable capability
The core tension in long-context models is not simply whether they can read longer text. It is whether they can still compute efficiently after doing so. In standard attention, both FLOPs and KV cache grow rapidly with sequence length, which makes million-token context suitable for demos but not for production serving.
DeepSeek-V4 takes a clear path: while preserving access to long-range information, it rewrites the attention mechanism, residual connectivity, and training optimization stack to push inference cost into an engineering-feasible range.
 AI Visual Insight: The image shows the DeepSeek-V4 product matrix, including Pro, Flash, and their Base variants. The key takeaway is a tiered design built around native 1M-token context plus different activated parameter scales, indicating that the series simultaneously targets frontier performance, speed optimization, and research use cases.
AI Visual Insight: The image shows the DeepSeek-V4 product matrix, including Pro, Flash, and their Base variants. The key takeaway is a tiered design built around native 1M-token context plus different activated parameter scales, indicating that the series simultaneously targets frontier performance, speed optimization, and research use cases.
Two model variants cover both performance and speed
DeepSeek-V4-Pro has about 1.6T total parameters with 49B activated parameters. DeepSeek-V4-Flash has about 284B total parameters with 13B activated parameters. Both support 1M-token context, but they optimize for different goals: Pro pushes the performance ceiling, while Flash prioritizes throughput and cost efficiency.
The model family also provides three inference intensities: Non-Think, Think High, and Think Max. In essence, these modes dynamically allocate test-time compute budgets based on task difficulty instead of relying on a single decoding strategy for every scenario.
 AI Visual Insight: The image compares compute investment and task performance across different reasoning modes. It emphasizes that DeepSeek-V4 uses adjustable thinking depth to trade off response latency against answer quality at runtime, making it well suited for tiered invocation in coding, math, and agent workflows.
AI Visual Insight: The image compares compute investment and task performance across different reasoning modes. It emphasizes that DeepSeek-V4 uses adjustable thinking depth to trade off response latency against answer quality at runtime, making it well suited for tiered invocation in coding, math, and agent workflows.
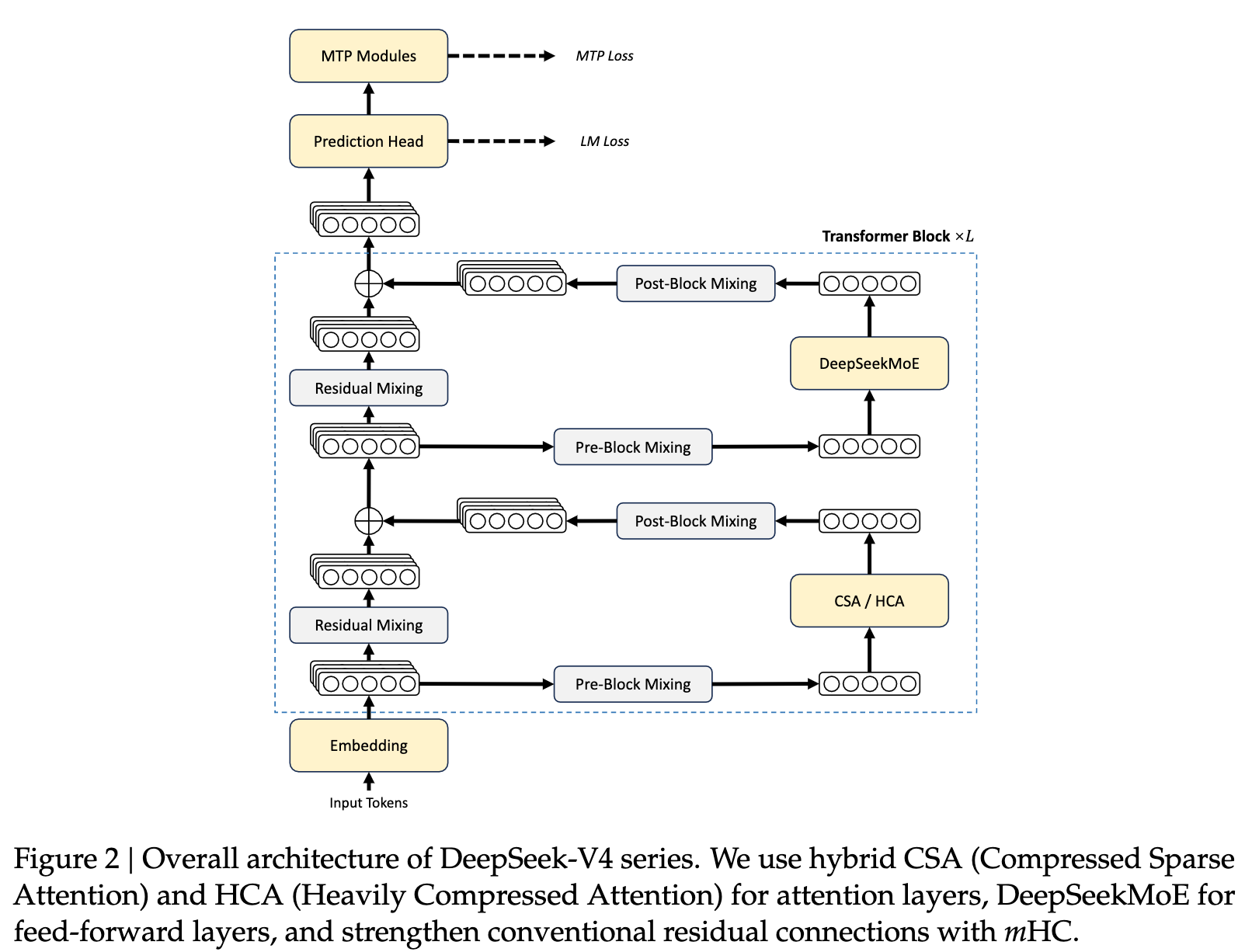
The hybrid attention mechanism is the core lever behind DeepSeek-V4’s efficiency gains
DeepSeek-V4’s most important innovation is that it splits long-context attention into modules with different responsibilities, instead of sending all tokens through the same expensive attention pipeline.
In this design, CSA handles compress-then-sparse-retrieve attention, while HCA handles more aggressive compression of distant history. By alternating the two, the model preserves local precision while controlling global memory usage.
 AI Visual Insight: The image shows how CSA, HCA, and local window attention work together. It reflects how DeepSeek-V4 separates fine-grained nearby modeling from compressed long-range memory, reducing the computational pressure of attention at million-token scale.
AI Visual Insight: The image shows how CSA, HCA, and local window attention work together. It reflects how DeepSeek-V4 separates fine-grained nearby modeling from compressed long-range memory, reducing the computational pressure of attention at million-token scale.
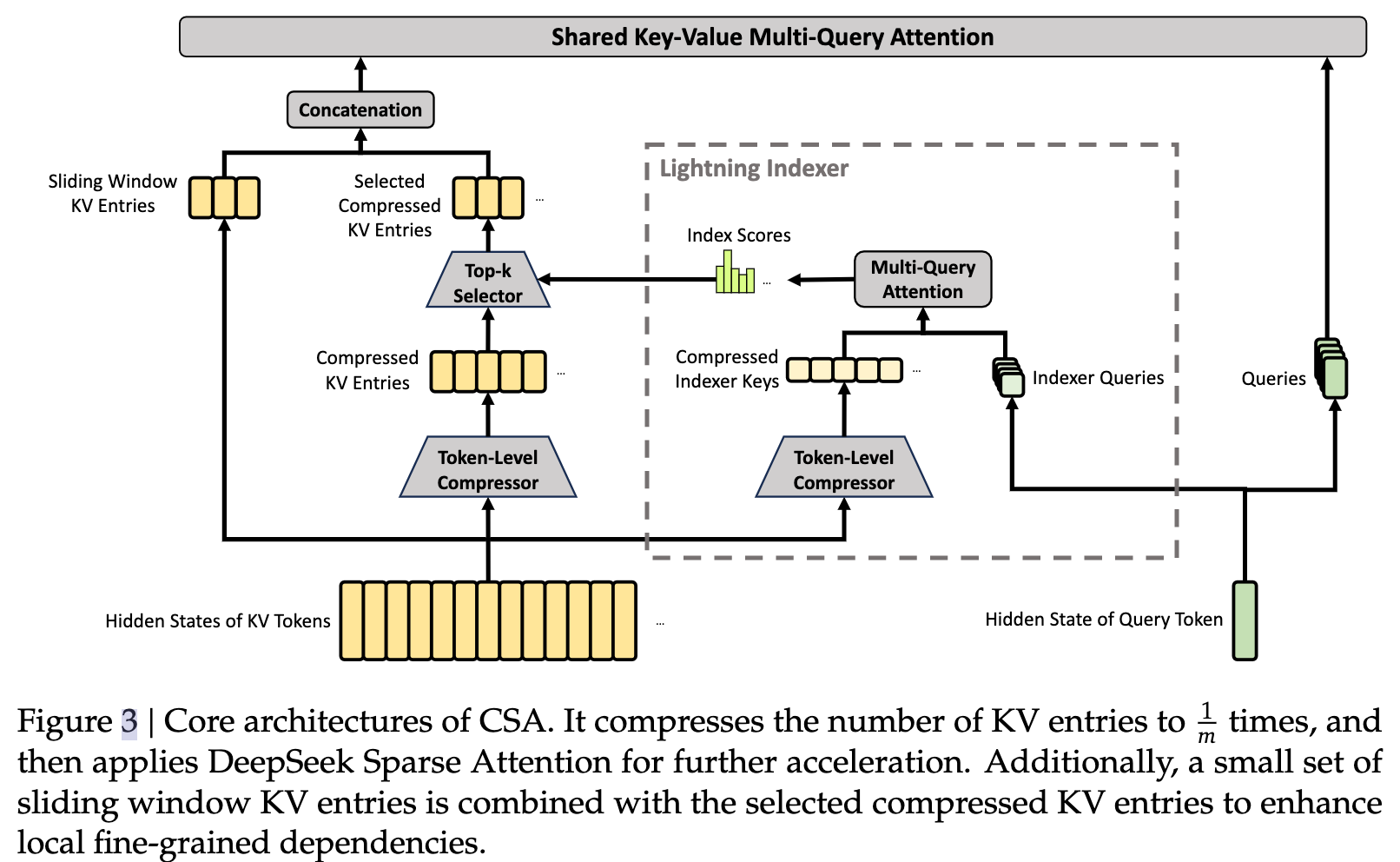
CSA compresses KV first and then performs sparse selection
The core idea of CSA is to first project a group of tokens’ K/V states into a compressed representation, and then select the most relevant top-k compressed blocks for the main attention step. This avoids full computation over every historical token.
# Pseudocode: the two-stage CSA process
kv_comp = compress_kv(hidden_states) # Compress KV first to reduce cache size
topk_idx = sparse_select(query, kv_comp) # Then select the most relevant compressed blocks
output = attention(query, kv_comp[topk_idx]) # Run core attention only on the selected blocksThis snippet captures the key CSA logic: replace full scanning with compression plus retrieval.
 AI Visual Insight: The image details the process of compressed KV entry construction, query index generation, and top-k selection. It shows that the model performs relevance filtering in a low-dimensional compressed space before entering attention computation, reducing wasted memory access and FLOPs.
AI Visual Insight: The image details the process of compressed KV entry construction, query index generation, and top-k selection. It shows that the model performs relevance filtering in a low-dimensional compressed space before entering attention computation, reducing wasted memory access and FLOPs.
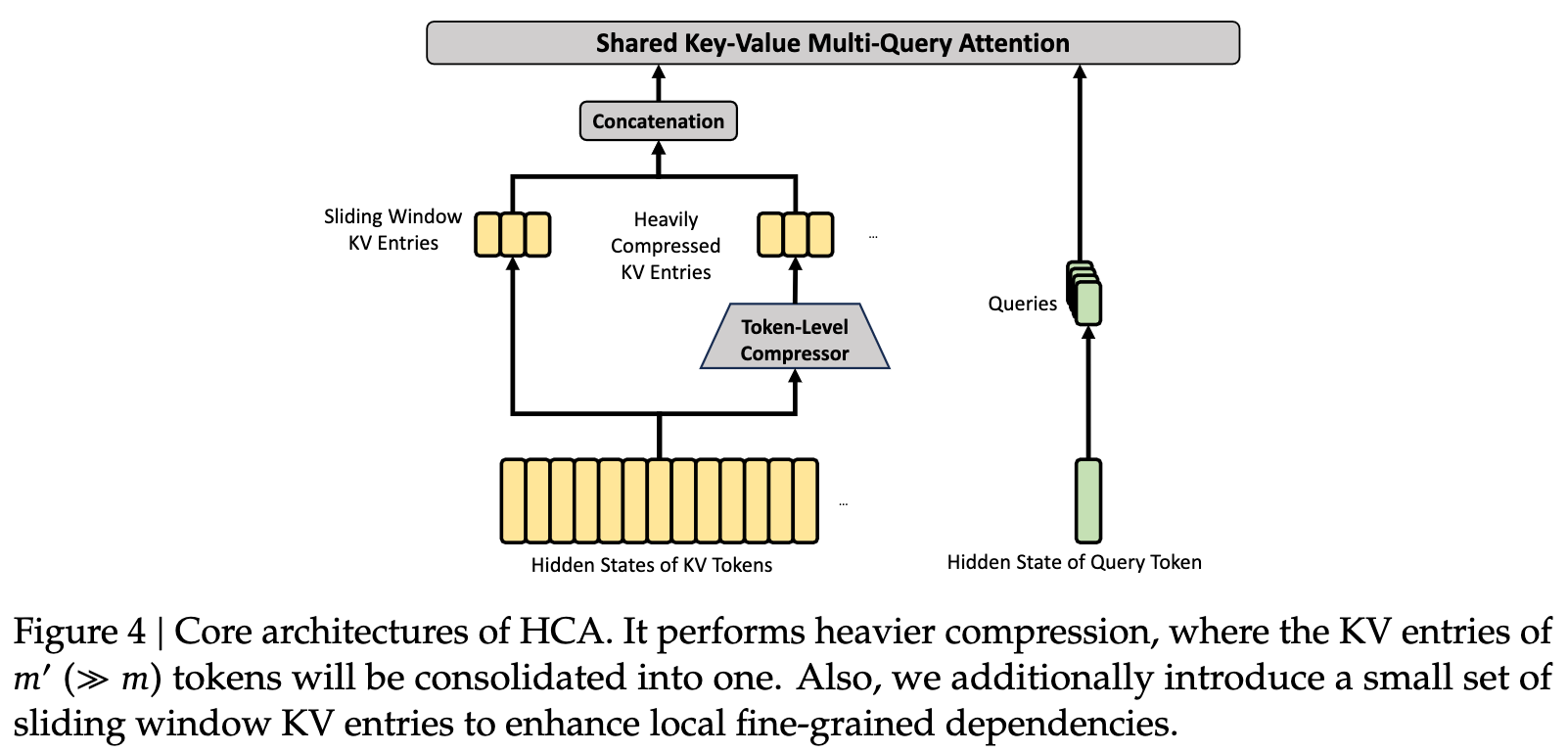
HCA trades stronger compression for more efficient ultra-long-range memory
HCA is more aggressive than CSA. It merges KV entries from much longer segments into fewer compressed entries, which further reduces KV cache usage. The trade-off is greater loss of fine-grained information, so it is better suited for coarse-grained retrieval over distant context.
A streaming indexer and shared-KV MQA further reduce inference overhead
Inside CSA, a streaming indexer generates an index query for the current query and quickly finds the most relevant compressed blocks. Shared-KV multi-query attention (MQA) reduces cache and memory bandwidth costs in multi-head attention by reusing K/V states across heads.
# Pseudocode: streaming index plus MQA
index_query = down_proj(h_t) # Generate the index query
selected = stream_indexer(index_query, mem) # Streamingly select top-k historical blocks
out = core_attn(q_t, selected.k, selected.v) # Use shared KV for core attentionThis code illustrates that DeepSeek-V4 applies system-level optimization in both stages: deciding what to attend to and deciding how to attend to it.
 AI Visual Insight: The image shows how a query vector passes through a down-projection layer into the streaming index module, where candidate blocks are selected from compressed memory in real time. This reflects a low-latency retrieval-style attention design.
AI Visual Insight: The image shows how a query vector passes through a down-projection layer into the streaming index module, where candidate blocks are selected from compressed memory in real time. This reflects a low-latency retrieval-style attention design.
 AI Visual Insight: The image shows multiple query heads sharing a single set of K/V states. That significantly reduces memory bandwidth pressure and cache redundancy, which is especially valuable for online serving under ultra-long-context inference workloads.
AI Visual Insight: The image shows multiple query heads sharing a single set of K/V states. That significantly reduces memory bandwidth pressure and cache redundancy, which is especially valuable for online serving under ultra-long-context inference workloads.
Rebuilding the training stack keeps the model stable under a highly compressed architecture
Efficient attention alone is not enough. Training must also adapt. DeepSeek-V4 introduces mHC (manifold-constrained hyper-connections) to strengthen stable cross-layer signal propagation and prevent training degradation in deep networks with complex attention structures.
On the optimizer side, the model primarily uses Muon while retaining AdamW for modules such as embeddings, the prediction head, and RMSNorm. This combination balances convergence speed for large-scale backbone parameters with optimization stability for specialized modules.
# Pseudocode: optimizer grouping during training
main_params = get_main_transformer_params(model) # Use Muon for backbone parameters
special_params = get_norm_embed_head_params(model) # Use AdamW for specialized modules
muon.step(main_params) # Improve convergence efficiency in large-scale training
adamw.step(special_params) # Keep edge modules updating stablyThis snippet shows that DeepSeek-V4 does not force a single optimizer across the entire model. Instead, it applies a divide-and-conquer strategy based on module characteristics.
In addition, the original notes mention that its OPD uses full-vocabulary supervision, meaning it tries to preserve full-vocabulary logits when computing KL divergence instead of looking only at sampled tokens or top-k candidates. This produces more stable gradients, but it also increases memory and compute cost. To offset that, the system uses teacher scheduling, on-demand weight loading, ZeRO-like sharding, and hidden-state caching.
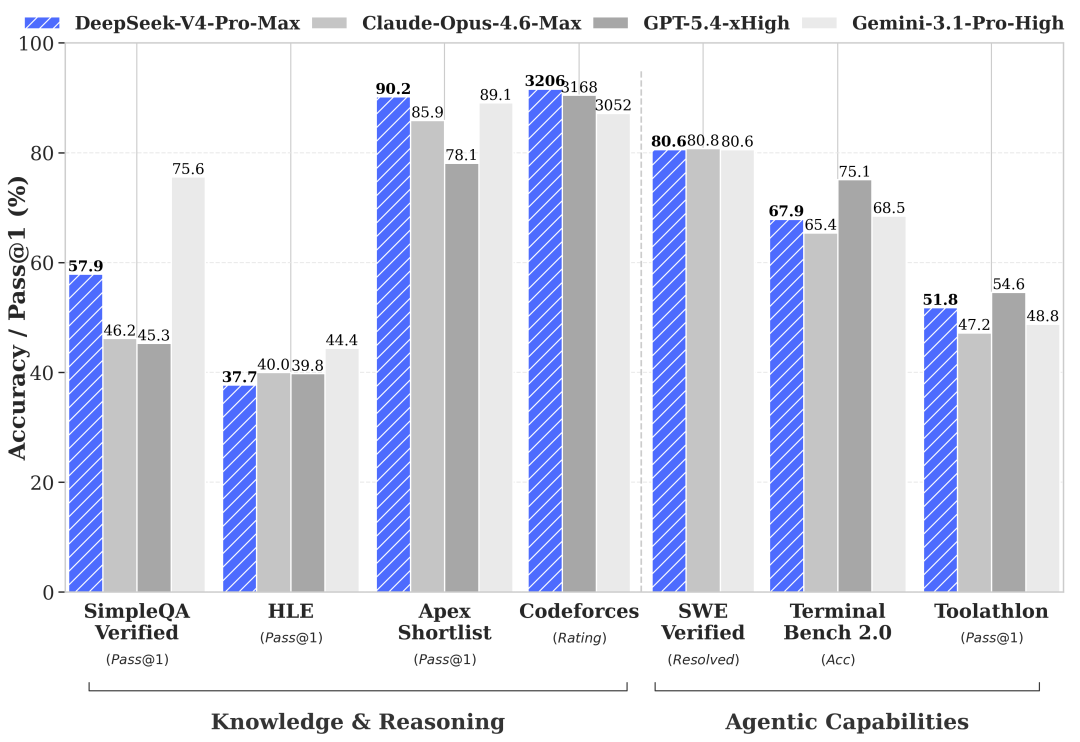
Experimental results show that it materially improves the cost structure of million-token context
In 1M-token scenarios, DeepSeek-V4-Pro requires about 27% of the per-token inference FLOPs of DeepSeek-V3.2, while using about 10% of its KV cache. The Flash variant is even more aggressive, reducing per-token FLOPs to about 10% and KV cache to about 7%.
The value of these numbers is not just stronger leaderboard performance. They suggest that long context is approaching service-ready deployment conditions for the first time: controllable memory footprint, higher throughput, and continued access to distant information.
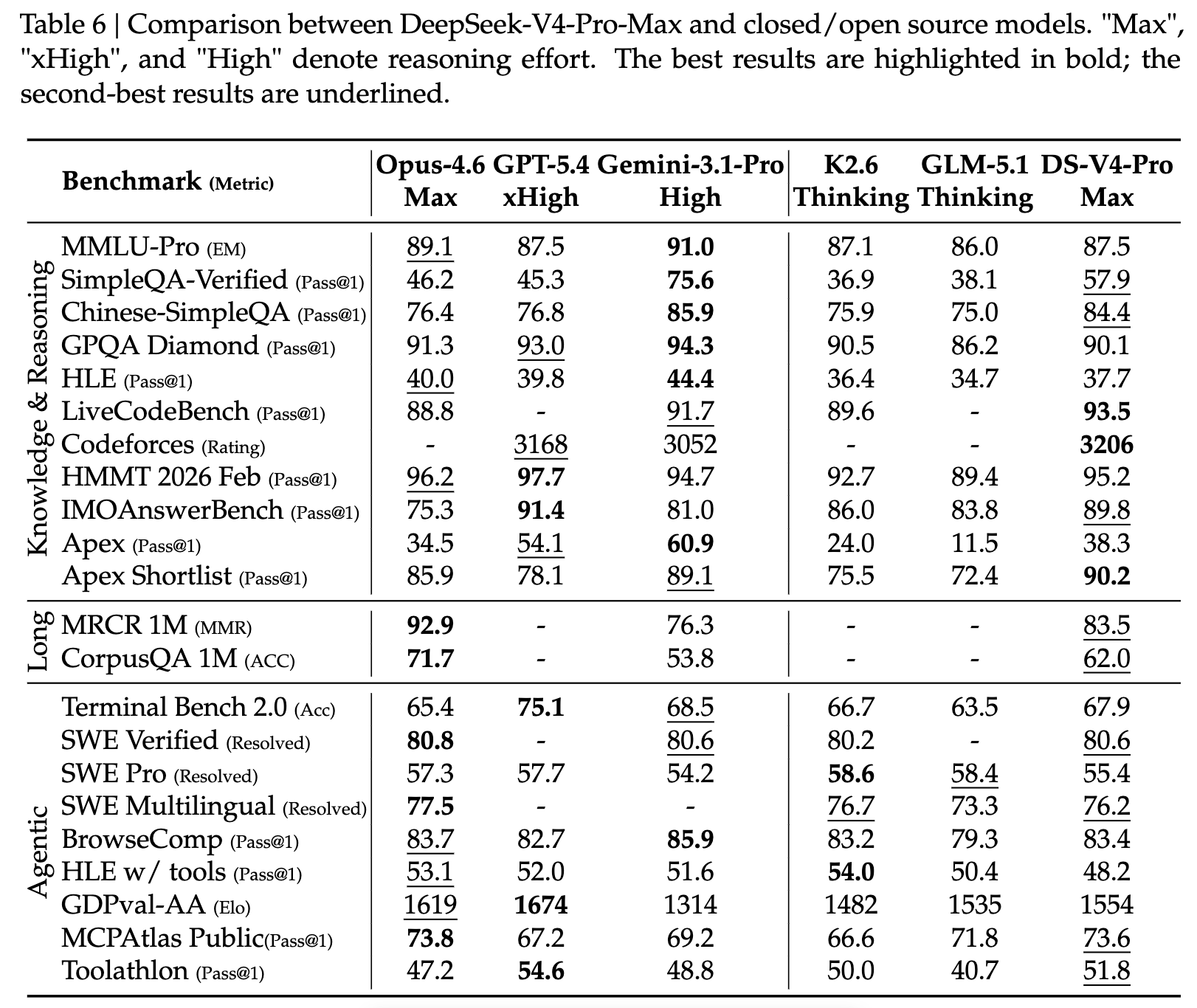 AI Visual Insight: The image summarizes performance across long-context, knowledge, reasoning, and coding benchmarks, together with efficiency metrics. It shows that the V4 family moves forward on the cost-performance curve by approaching the capabilities of leading closed-source models at lower inference cost.
AI Visual Insight: The image summarizes performance across long-context, knowledge, reasoning, and coding benchmarks, together with efficiency metrics. It shows that the V4 family moves forward on the cost-performance curve by approaching the capabilities of leading closed-source models at lower inference cost.
Why these results matter more to engineering teams
For engineering teams, the critical question around million-token context is not the window size reported in a paper. It is whether each request is still economically supportable. DeepSeek-V4’s answer is that hybrid compression, sparse selection, and shared KV can turn ultra-long context from an extremely expensive feature into a product capability that can be enabled on demand.
Developers should focus on three questions when evaluating DeepSeek-V4
First, ask whether the task truly needs 1M-token context. If the workload centers on codebase Q&A, long-report analysis, or complex agent memory, V4’s architectural advantages become more pronounced.
Second, identify whether the system bottleneck is memory, bandwidth, or latency. V4 primarily targets KV cache growth and attention FLOPs, so it tends to provide the greatest gains for online inference.
Third, decide whether tunable reasoning intensity is required. The three Think modes allow one model to serve different SLAs, which is highly valuable for enterprise platform deployments.
FAQ provides structured answers to the key questions
What is the biggest difference between DeepSeek-V4 and a traditional Transformer?
The biggest difference is that DeepSeek-V4 does not send the entire context through full attention. Instead, it divides responsibilities across CSA, HCA, local window attention, and MQA to reduce long-context cost at the system level.
How should you understand the difference between CSA and HCA?
CSA focuses on compress first, then retrieve precisely. It is better when you want higher retrieval accuracy from compressed memory. HCA focuses on stronger compression for lower cost, which makes it better for coarse-grained modeling of extremely distant history.
Which real-world scenarios is DeepSeek-V4 well suited for?
It is well suited for long-document question answering, code repository analysis, multi-turn agent memory, enterprise knowledge retrieval augmentation, and complex reasoning tasks that benefit from expanded test-time compute.
References
- DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
- Related interpretive materials on the DeepSeek-V4 technical report
Core Summary: This article reconstructs and explains the core design of DeepSeek-V4: its MoE architecture, CSA/HCA hybrid attention, mHC hyper-connections, Muon optimizer, and full-vocabulary OPD. The focus is on why it can significantly reduce FLOPs and KV cache usage under a 1M-token context window while remaining competitive on reasoning, coding, and agent tasks.