DeepSeek-V4 is an MoE large-model architecture upgrade built for million-token contexts. It addresses three core pain points: the high cost of long-context inference, KV cache bloat, and unstable deep-network training. Keywords: million-token context, hybrid attention, mHC.
The technical specification snapshot captures the core design
| Parameter | Description |
|---|---|
| Architecture language | Research-grade model design; engineering implementation primarily uses CUDA, DSLs, and training frameworks |
| Core architecture | Transformer + DeepSeekMoE + MTP |
| Long-context capability | Native support for 1M tokens |
| Representative models | DeepSeek-V4-Pro, DeepSeek-V4-Flash |
| Parameter scale | Pro: 1.6T / 49B activated; Flash: 284B / 13B activated |
| Attention mechanism | CSA + HCA hybrid attention |
| Residual replacement | mHC (Manifold-Constrained Hyper-Connections) |
| Optimizer | Muon |
| Training data volume | Flash: 32T tokens; Pro: 33T tokens |
| Core dependencies | DeepSeekMoE, MTP, TileLang, FP4/FP8 mixed precision |
| Protocol / release format | Preview models and technical report |
| Star count | Not provided in the source input |
DeepSeek-V4 pushes million-token context from feasible to efficient
DeepSeek-V4 inherits two key assets from V3: the MoE architecture and the multi-token prediction strategy. The real change is not whether the model is larger, but whether it can process ultra-long contexts at an acceptable cost.
Its answer is a coordinated combination of three ideas: use CSA/HCA to reduce attention and cache costs, replace traditional residual connections with mHC to improve deep-network stability, and adopt the Muon optimizer to accelerate convergence and improve training robustness.
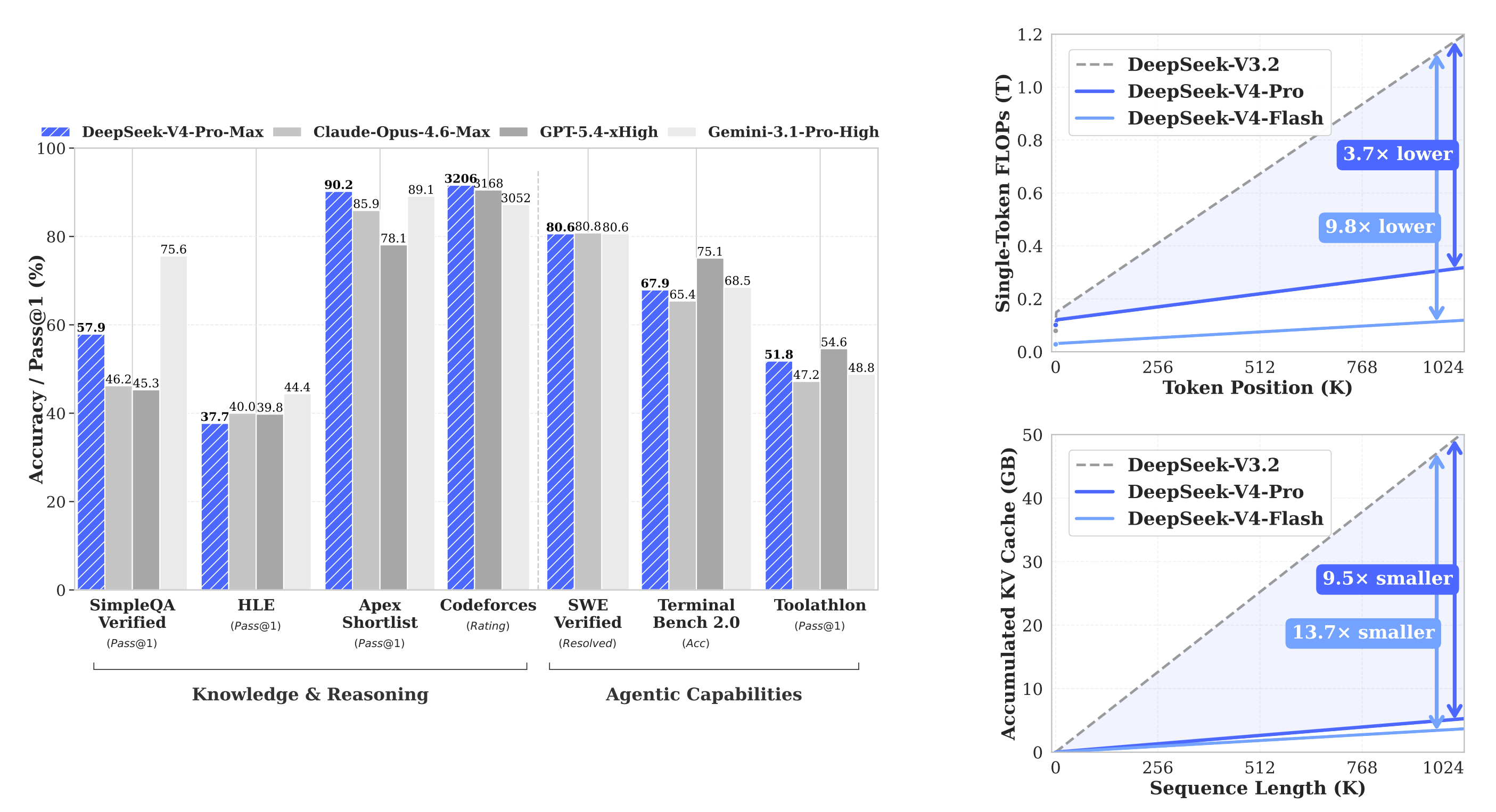 AI Visual Insight: This figure uses long-context length as the horizontal axis and compares V3.2 with the V4 family in terms of per-token inference FLOPs and cumulative KV cache growth. The key technical takeaway is that as context length increases, the V4 curves grow much more slowly. That indicates its compressed attention and cache design delivers real engineering gains at million-token scale, rather than relying only on theoretical complexity improvements.
AI Visual Insight: This figure uses long-context length as the horizontal axis and compares V3.2 with the V4 family in terms of per-token inference FLOPs and cumulative KV cache growth. The key technical takeaway is that as context length increases, the V4 curves grow much more slowly. That indicates its compressed attention and cache design delivers real engineering gains at million-token scale, rather than relying only on theoretical complexity improvements.
Efficiency gains are V4’s strongest production signal
In 1M-context scenarios, V4-Pro requires roughly 27% of V3.2’s per-token FLOPs and about 10% of its KV cache. The lighter V4-Flash reduces these figures even further, to 10% and 7% respectively. That makes long-document QA, repository-scale code reasoning, and agent memory chains much more practical to deploy.
metrics = {
"V4-Pro": {"flops_ratio": 0.27, "kv_ratio": 0.10}, # Cost ratio relative to V3.2
"V4-Flash": {"flops_ratio": 0.10, "kv_ratio": 0.07}, # A more efficiency-oriented variant
}
for name, m in metrics.items():
print(f"{name}: FLOPs={m['flops_ratio']*100:.0f}%, KV={m['kv_ratio']*100:.0f}%") # Print the cost reduction ratiosThis code snippet provides an intuitive way to express how much the two V4 variants compress inference and cache costs relative to the previous generation.
DeepSeek-V4’s architectural upgrade centers on attention, connectivity, and the optimizer
V4 keeps the Transformer backbone, but replaces the attention layer with hybrid CSA/HCA attention, retains DeepSeekMoE in the feed-forward layer, and strengthens cross-layer information flow with mHC. During training, it also introduces Muon in place of a conventional AdamW-style optimizer.
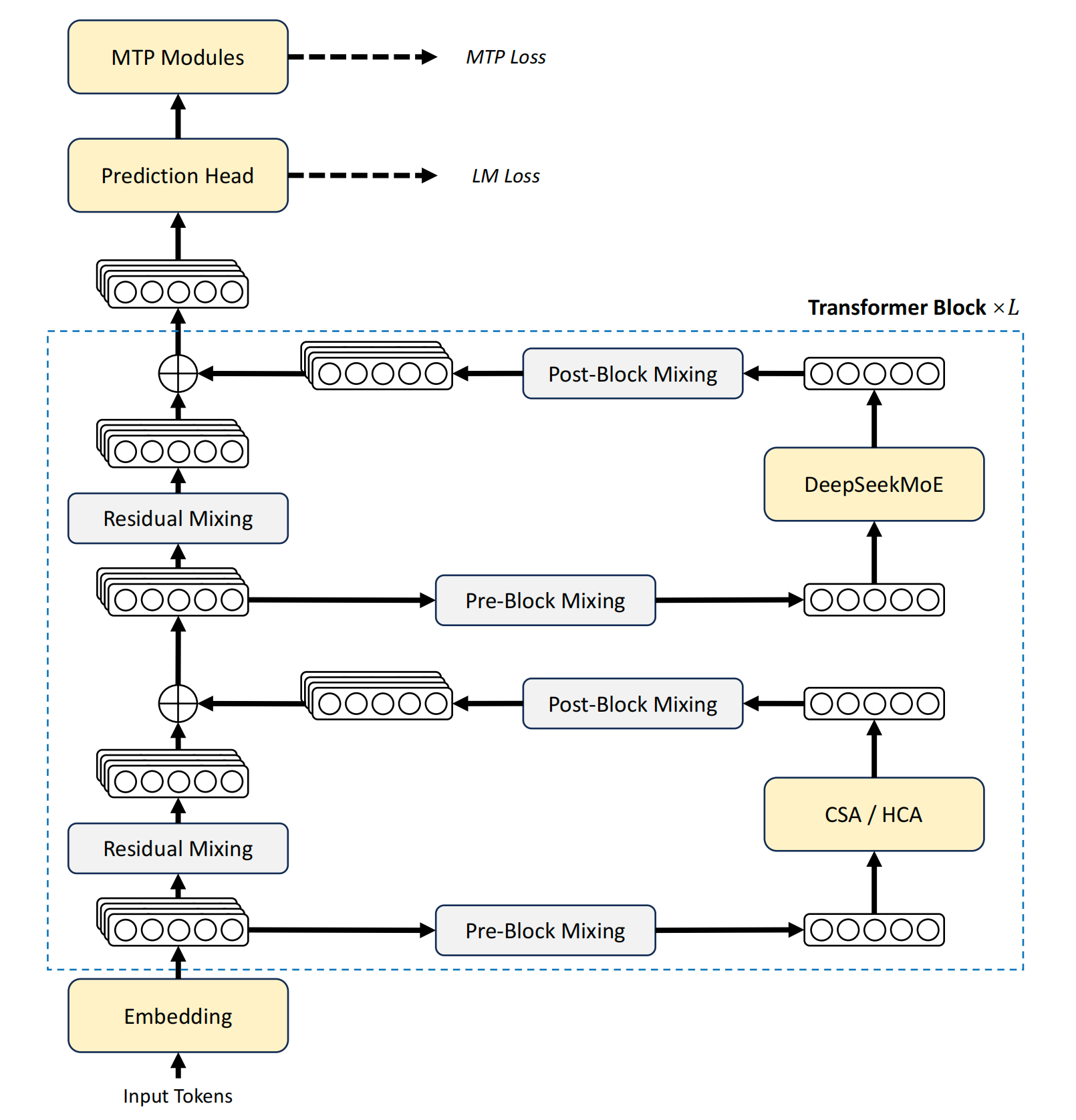 AI Visual Insight: This diagram shows the arrangement of V4’s backbone modules: compressed attention is interleaved in the attention layers, the feed-forward blocks remain MoE-based, and the residual path is expanded by mHC into multi-branch residual flows. The most important message is not the module names themselves, but that long-context efficiency optimization has evolved from isolated tricks into a system-level architectural rewrite.
AI Visual Insight: This diagram shows the arrangement of V4’s backbone modules: compressed attention is interleaved in the attention layers, the feed-forward blocks remain MoE-based, and the residual path is expanded by mHC into multi-branch residual flows. The most important message is not the module names themselves, but that long-context efficiency optimization has evolved from isolated tricks into a system-level architectural rewrite.
mHC addresses unstable residual signal propagation in very deep networks
Standard residual connections use single-channel accumulation, while Hyper-Connections expand the residual stream into multiple channels. They then use three mapping groups—A, B, and C—to implement a pattern of multi-path input, single-path computation, multi-path output, and inter-layer flow mixing. The problem is that after stacking many layers, the B matrix can cause numerical explosion or attenuation.
mHC solves this by constraining B to the doubly stochastic matrix manifold, ensuring its spectral norm does not exceed 1. That keeps the residual transform non-expansive and stabilizes both forward and backward propagation. It is a classic example of structural stability by design.
import numpy as np
def sinkhorn(mat, steps=20):
x = np.exp(mat) # Exponentiate first to ensure non-negative matrix entries
for _ in range(steps):
x = x / x.sum(axis=1, keepdims=True) # Row normalization
x = x / x.sum(axis=0, keepdims=True) # Column normalization
return x # Approximate a doubly stochastic matrixThis code snippet simulates the core idea behind applying a Sinkhorn constraint to the residual mapping matrix in mHC.
CSA and HCA share the work of long-context attention compression
CSA follows a compress-then-select strategy. It compresses every group of m token KV entries into a single entry, then allows the current query to attend only to the top-k compressed entries, while preserving a local sliding-window branch to avoid losing local dependencies.
HCA is more aggressive. It uses a higher compression ratio while preserving a dense attention computation pattern. In simple terms, CSA emphasizes compression plus retrieval, while HCA emphasizes extreme compression plus dense reading. DeepSeek-V4 alternates between them to balance accuracy and efficiency.
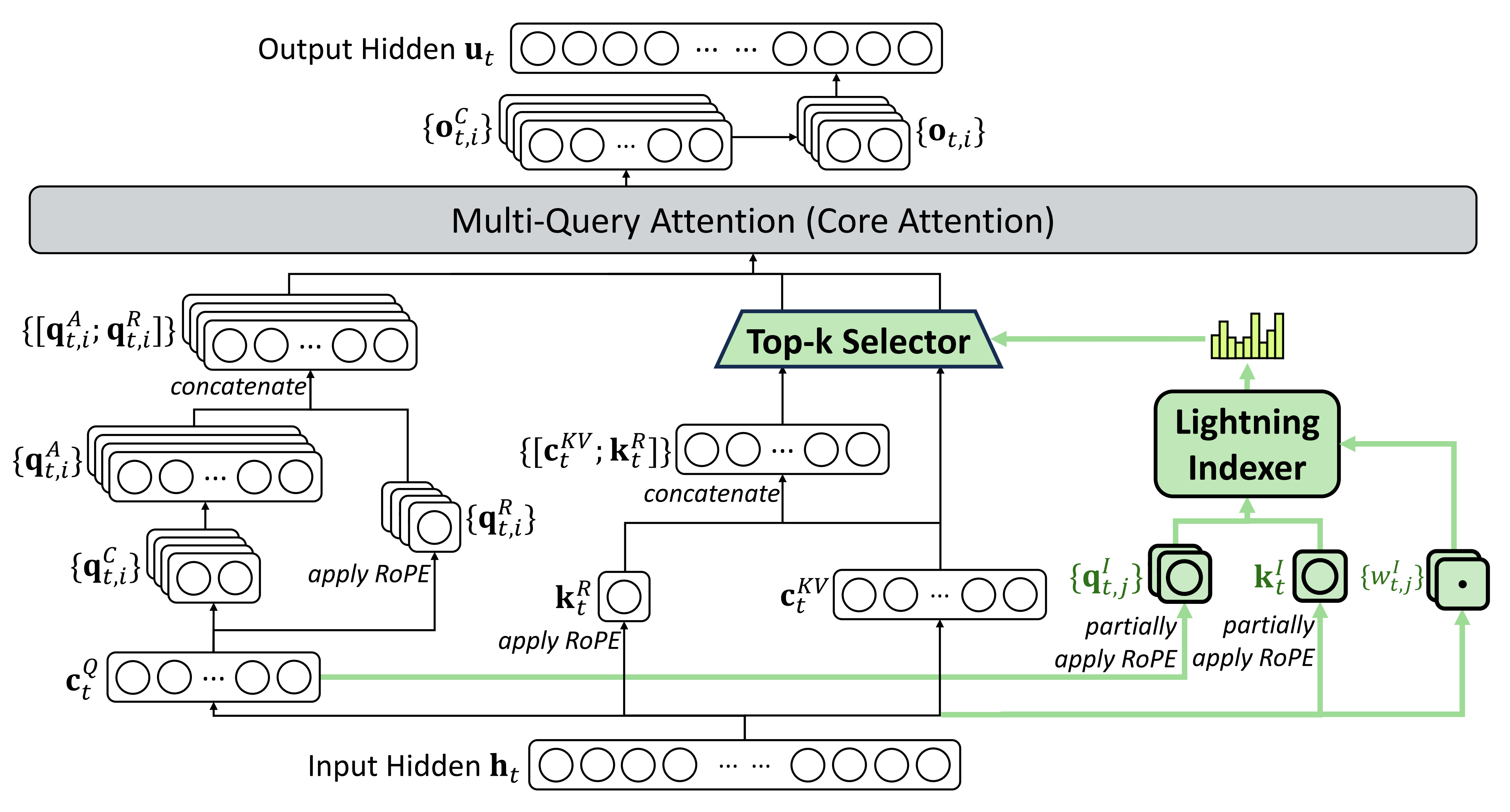 AI Visual Insight: This figure highlights a two-layer cost-reduction logic in compressed attention paths. The first layer reduces KV entries along the sequence dimension, and the second layer reduces the effective compute subset through sparse selection. It shows that V4’s long-context capability does not come from brute-forcing larger memory capacity, but from jointly optimizing cache organization and query access paths.
AI Visual Insight: This figure highlights a two-layer cost-reduction logic in compressed attention paths. The first layer reduces KV entries along the sequence dimension, and the second layer reduces the effective compute subset through sparse selection. It shows that V4’s long-context capability does not come from brute-forcing larger memory capacity, but from jointly optimizing cache organization and query access paths.
CSA’s engineering value lies in balancing local precision and global retrieval
CSA does not simply average-pool all historical information. Instead, it learns weights for compressed entries and uses the Lightning Indexer to select the most relevant compressed KV blocks. Tokens in the recent window remain uncompressed to preserve fine-grained local dependencies.
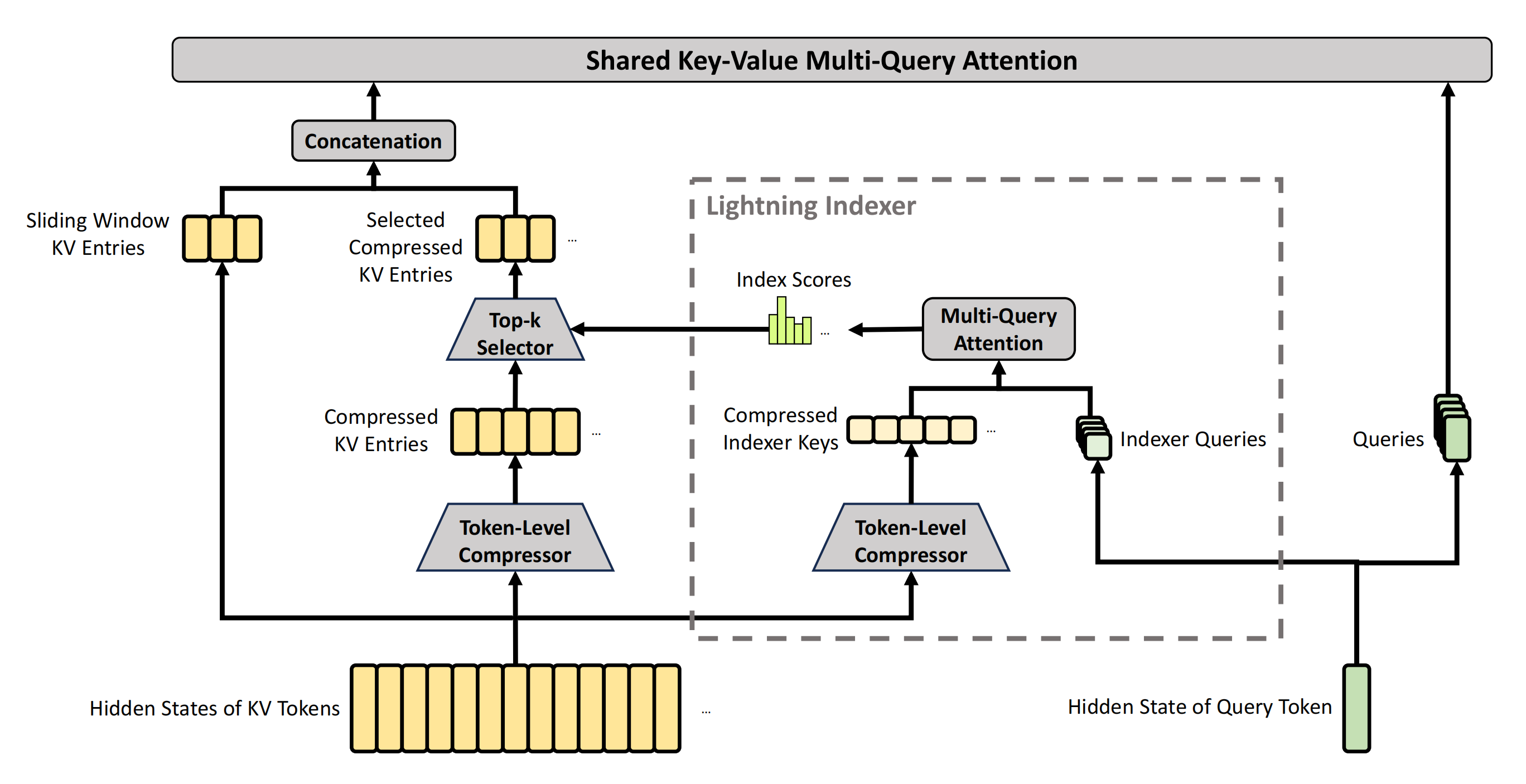 AI Visual Insight: The diagram clearly separates the local window branch from the global compressed branch. The window branch preserves high-fidelity KV entries for recent tokens, while the global branch compresses and selects historical segments. The technical meaning is that V4 explicitly separates short-range precise memory from long-range sparse recall inside the attention layer.
AI Visual Insight: The diagram clearly separates the local window branch from the global compressed branch. The window branch preserves high-fidelity KV entries for recent tokens, while the global branch compresses and selects historical segments. The technical meaning is that V4 explicitly separates short-range precise memory from long-range sparse recall inside the attention layer.
def select_topk_blocks(scores, k=1024):
order = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)
return order[:k] # Keep only the most relevant compressed KV blocksThis code snippet abstracts the top-k compressed block selection process driven by the Lightning Indexer in CSA.
The training and inference infrastructure is also redesigned in parallel
DeepSeek-V4’s gains do not come only from model equations. They also come from infrastructure. Its MoE stack uses fused kernels to overlap computation, communication, and memory access. It uses TileLang to balance DSL development efficiency with runtime performance, and relies on deterministic kernels to guarantee bitwise reproducibility in both training and inference.
At the same time, V4 introduces FP4 quantization-aware training for MoE expert weights and for the QK path of the indexer, extends tensor-level checkpointing, adopts Muon-oriented hybrid ZeRO, and adds a two-stage context parallelism mechanism. On the inference side, it introduces heterogeneous KV cache and a disk-based shared-prefix reuse strategy.
The post-training pipeline follows a two-stage paradigm: specialists first, unified distillation later
V4’s post-training pipeline does not directly force every capability into a single unified model. Instead, it first trains domain specialists for math, code, agents, instruction following, and other areas, then integrates those capabilities into one model through on-policy distillation.
In practice, this usually means starting with SFT to build the foundation, then using GRPO for domain reinforcement, and finally having a unified student model learn from a cluster of specialist teachers. The core benefit is straightforward: maximize specialization first, then merge capabilities later to reduce cross-task interference.
DeepSeek-V4 represents a systematic design pattern for the long-context era
From the results, V4 is not the victory of a single trick. It is the combined evolution of architecture, optimizer design, quantization, parallelism, cache strategy, and post-training methodology. Its importance is that million-token context is no longer just a demo window. It is starting to enter a genuinely deployable range.
If you care about codebase question answering, ultra-long RAG, multi-turn agent memory, or large-scale document understanding, V4 offers three especially useful lessons: compressed attention must work together with an indexer, residual stability deserves structural modeling, and inference-system design must be considered at the model-design stage rather than postponed until deployment.
FAQ structured Q&A
1. What is the biggest technical change in DeepSeek-V4 compared with V3?
The biggest change is not parameter count, but a system-level redesign for 1M-token context: attention moves from a traditional path to CSA/HCA, residual connections are upgraded to mHC, the training optimizer switches to Muon, and the model is paired with new quantization and parallel infrastructure.
2. Why is mHC more important than standard residuals or standard Hyper-Connections?
Because in ultra-deep training, stable cross-layer signal propagation is a prerequisite for the model’s performance ceiling. mHC improves trainability structurally by constraining residual mappings to the doubly stochastic matrix manifold, preventing uncontrolled signal amplification or decay.
3. Why is CSA well suited for million-token scenarios?
Because it combines KV compression, top-k sparse selection, and local-window fidelity preservation. That simultaneously controls the cache volume of global history while preserving as much nearby detail and long-range relevant recall as possible.
Core summary: This article reconstructs the key upgrades behind DeepSeek-V4. While retaining the MoE foundation and multi-token prediction, it adds CSA/HCA hybrid attention, mHC manifold-constrained hyper-connections, and the Muon optimizer to achieve lower FLOPs, smaller KV cache, and more stable training under million-token contexts.