This article focuses on Elasticsearch relevance scoring, explains how
_scoredetermines search result ranking, compares the core differences between TF-IDF and BM25, breaks down their formula structures and tuning ideas, and addresses the common question: why do matched documents rank differently than expected? Keywords: Elasticsearch, BM25, relevance scoring.
Technical specification snapshot
| Parameter | Description |
|---|---|
| Domain | Elasticsearch search relevance scoring |
| Core languages | Java, DSL Query |
| Core protocol | HTTP/REST |
| Default algorithm | BM25 in ES 7.x+ |
| Historical algorithm | TF-IDF (classic) |
| Key metadata | _score |
| Debugging tool | Explain API |
| Core dependency | Lucene Similarity |
| Stars | Original data not provided |
Elasticsearch relevance scoring essentially estimates the value of a match between a query and a document
In Elasticsearch, _score is the default basis for search ranking. If you do not explicitly specify sort, documents with higher scores appear first.
Here, “relevance” is not just whether a document matches. It measures how closely that match aligns with what the user is actually trying to find. As a result, search ranking is probabilistic rather than binary, and retrieval results are often ordered by confidence instead of returning a single definitive answer.
Search and retrieval do not share the same boundaries
Search often has clear boundaries, such as exact conditions like eq, gte, and lte. Retrieval places more emphasis on semantic similarity, aliases, synonyms, term frequency distribution, and field weights.
That is why two documents can both match and still rank very differently.
GET my_index/_search
{
"query": {
"match": {
"title": "elasticsearch relevance"
}
}
}This query returns matching documents and lets Elasticsearch automatically compute _score for ranking.
TF-IDF calculates weight through term frequency, inverse document frequency, and field length
TF-IDF was the default similarity model in early Lucene versions. It focuses on three core signals: term frequency (TF), inverse document frequency (IDF), and field-length normalization (Norm).
Higher term frequency usually means higher relevance, but the gain is not infinitely linear
Term frequency represents how many times a term appears in a single document. The classic formula can be simplified as: tf(t in d) = √frequency.
This means a term that appears 4 times does not get 4 times the gain. Instead, the gain decays according to the square root, which prevents repeated keyword stuffing from producing unreasonable scores.
PUT /product_tf/_doc/1
{
"name": "小米 大米 紫米 青米 红米 黑米 豌豆 大米"
}
PUT /product_tf/_doc/2
{
"name": "小米 大米 紫米 青米 红米 黑米 豌豆 小米"
}
GET /product_tf/_search
{
"query": {
"match": {
"name": "大米"
}
}
}This dataset helps illustrate how the number of occurrences of the same term in different documents affects scoring.
Inverse document frequency lowers the weight of terms that appear everywhere
IDF measures whether a term is sufficiently rare. The more common a term is, the less discriminative it becomes, and the lower its weight should be.
A typical form is: idf(t) = 1 + log(numDocs / (docFreq + 1)). If a term appears in almost every document, it becomes much less useful for determining which document is actually more relevant.
PUT /product_idf/_doc/1
{
"name": "小米 大米 紫米 青米 红米 黑米 豌豆"
}
PUT /product_idf/_doc/2
{
"name": "小米 大米 紫米 青米 红米 黑米 花生"
}
GET /product_idf/_search
{
"query": {
"match": {
"name": "小米 豌豆"
}
}
}This example shows that the rarer term “豌豆” usually creates more score separation than the frequent term “小米”.
Shorter fields usually assign more weight to the same matched term
The goal of length normalization is to prevent long text from having a built-in advantage. The same term appearing in a short title often matters more than the same term appearing in a long body field.
The formula can be written as: norm(d) = 1 / √numTerms. The shorter the field, the larger the Norm value and the stronger the relevance boost.
The vector space model maps multi-term queries into a unified scoring framework
TF-IDF does not only score individual terms. It also relies on the vector space model to handle multi-term queries. Both the document and the query are represented as term-weight vectors, and the system computes their overall match strength.
 AI Visual Insight: This diagram shows the geometric relationship between the query vector and document vectors in the vector space model. The key idea is that term weights are mapped into a multi-dimensional space, and text similarity is measured by vector angle or distance. The more consistently multiple terms align, the higher the relevance.
AI Visual Insight: This diagram shows the geometric relationship between the query vector and document vectors in the vector space model. The key idea is that term weights are mapped into a multi-dimensional space, and text similarity is measured by vector angle or distance. The more consistently multiple terms align, the higher the relevance.
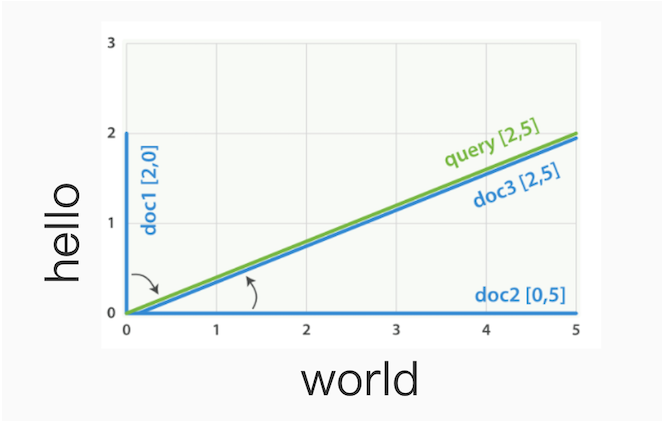 AI Visual Insight: This diagram further illustrates how different documents are distributed in vector space, emphasizing that scoring is not based only on whether a keyword exists. It also considers term-weight structure, match coverage, and directional alignment.
AI Visual Insight: This diagram further illustrates how different documents are distributed in vector space, emphasizing that scoring is not based only on whether a keyword exists. It also considers term-weight structure, match coverage, and directional alignment.
The classic scoring function combines several factors
The classic formula can be summarized as:
score(q,d) = queryNorm(q) · coord(q,d) · ∑(
tf(t in d) · idf(t)^2 · boost · norm(t,d)
)Here, coord rewards documents that match more query terms, while boost lets you manually increase the importance of specific terms or fields.
BM25 is the default and more practical scoring algorithm in modern Elasticsearch
Starting with Elasticsearch 5.x, BM25 became the default similarity algorithm. It still uses TF, IDF, and document length, but it handles TF in a more reasonable way.
The core improvement in BM25 is that term-frequency gain gradually saturates. Increasing a term from 1 occurrence to 3 can matter a lot, but increasing it from 100 to 500 usually should not produce a massive score boost.
BM25 introduces saturation control for term frequency
BM25 no longer uses a simple square root. Instead, it uses k1 to control the upper bound of term-frequency gain. The default is k1=1.2. The larger the value, the more strongly term frequency can widen score differences.
This helps solve keyword stuffing and makes ranking behave more like real-world search relevance.
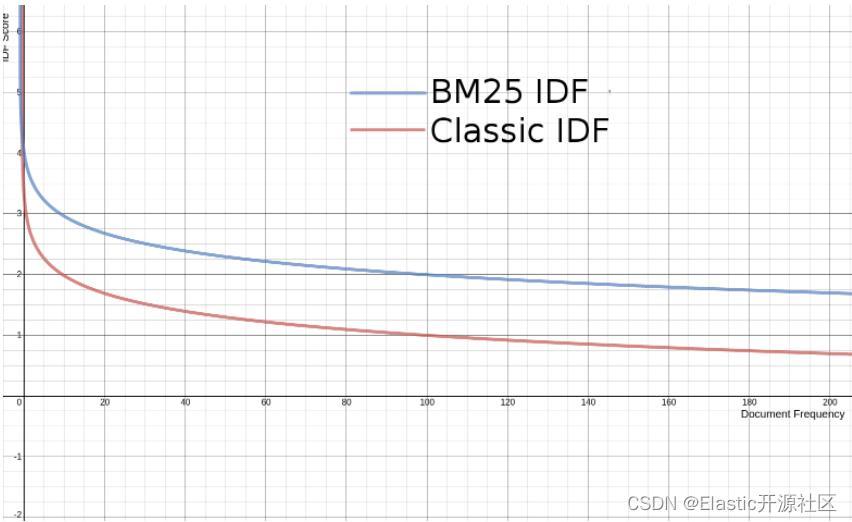 AI Visual Insight: This chart shows how the IDF curve in BM25 changes with document frequency, demonstrating that the more common a term is, the weaker its discriminative power. The smoothed curve also avoids negative values, which makes it more suitable for production-grade search systems.
AI Visual Insight: This chart shows how the IDF curve in BM25 changes with document frequency, demonstrating that the more common a term is, the weaker its discriminative power. The smoothed curve also avoids negative values, which makes it more suitable for production-grade search systems.
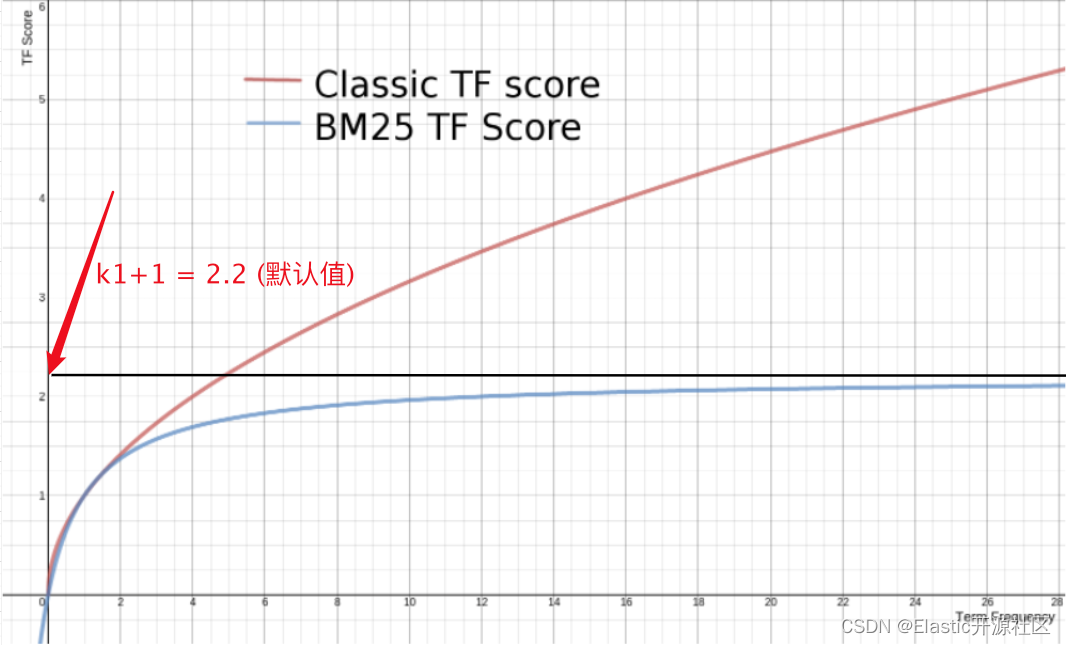 AI Visual Insight: This chart shows the saturation curve of the BM25 term-frequency function. As the number of term occurrences increases, the score gain slows down and approaches an upper limit, reflecting the algorithm’s ability to suppress repeated keyword stacking.
AI Visual Insight: This chart shows the saturation curve of the BM25 term-frequency function. As the number of term occurrences increases, the score gain slows down and approaches an upper limit, reflecting the algorithm’s ability to suppress repeated keyword stacking.
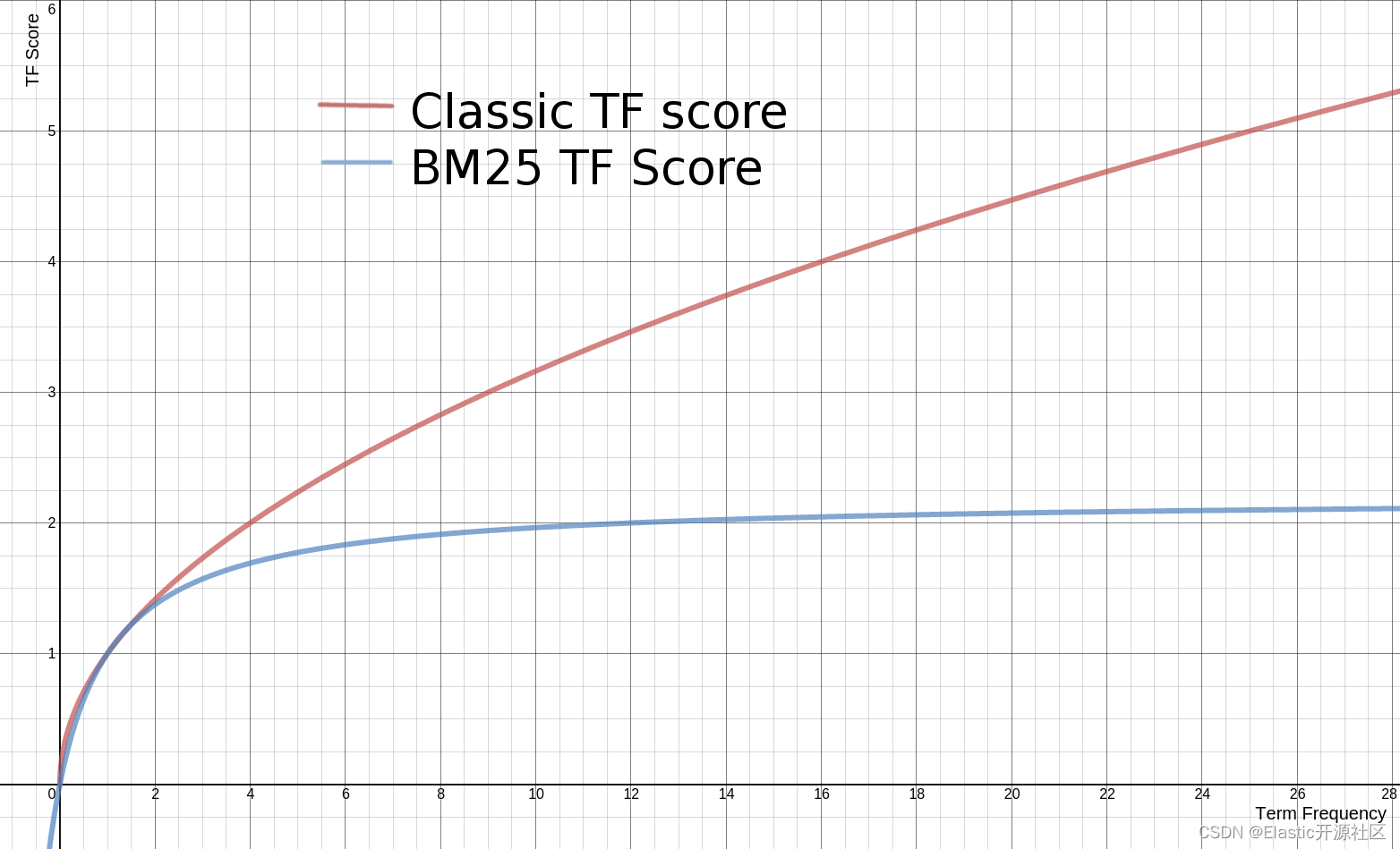 AI Visual Insight: This chart visually compares BM25 with traditional TF gain behavior, highlighting BM25’s slower growth in the high-frequency range and showing why it is better suited to content-quality ranking than simple term-count accumulation.
AI Visual Insight: This chart visually compares BM25 with traditional TF gain behavior, highlighting BM25’s slower growth in the high-frequency range and showing why it is better suited to content-quality ranking than simple term-count accumulation.
BM25 also models document length explicitly
The parameter b controls the degree of length normalization, with a default of b=0.75. When a document is longer than the average length, the contribution of term frequency is compressed further.
As a result, BM25 is usually more stable than TF-IDF in scenarios involving long documents, short titles, product names, and Q&A content.
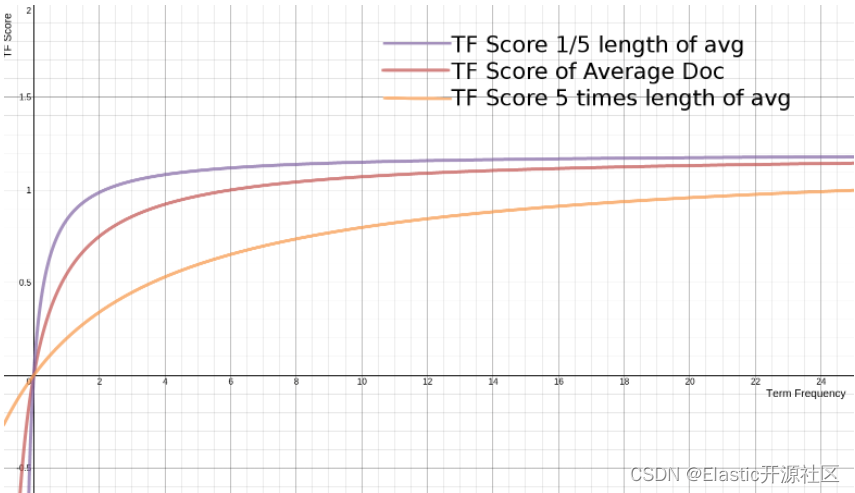 AI Visual Insight: This chart shows how the BM25 term-frequency function changes under different document-length ratios. It demonstrates that shorter documents reach higher scores more quickly at the same term frequency, while longer documents need more term occurrences to achieve the same relevance gain.
AI Visual Insight: This chart shows how the BM25 term-frequency function changes under different document-length ratios. It demonstrates that shorter documents reach higher scores more quickly at the same term frequency, while longer documents need more term occurrences to achieve the same relevance gain.
PUT my-index-000001
{
"mappings": {
"properties": {
"default_field": {
"type": "text"
},
"boolean_sim_field": {
"type": "text",
"similarity": "boolean"
}
}
}
}This mapping example shows that Elasticsearch supports switching similarity models at the field level instead of forcing the entire index to use only one scoring method.
The Explain API is the most direct tool for understanding scoring details
If search results “look wrong,” the most effective approach is not to guess. Use the Explain API to inspect how each score is constructed.
It can tell you why a document matched, which terms participated in scoring, how much TF and IDF contributed, and whether field length influenced ranking.
GET /product/_search
{
"explain": true,
"query": {
"match": {
"name": "小米"
}
}
}This request returns a detailed score explanation in the response and is the preferred way to troubleshoot ranking anomalies.
The key to scoring optimization is not changing the formula but understanding business signals
For e-commerce, content retrieval, and knowledge base search, relevance is never just a pure text problem. In addition to the algorithm itself, you also need to consider field weighting, recall strategy, filter context, synonyms, and business-level boosts.
If you need manual intervention in ranking, prioritize boost, function_score, field splitting, and short-field modeling instead of directly rejecting BM25.
FAQ
Why do two documents that match the same keyword have different scores?
Because _score is influenced by term frequency, inverse document frequency, field length, match coverage, and field weights at the same time. A match is only the starting point; the final score depends on the combined effect of these signals.
Why did Elasticsearch switch from TF-IDF to BM25?
Because BM25 applies saturation to high term-frequency gains and handles document length more reasonably, which reduces ranking bias caused by keyword stuffing and produces more stable results in practice.
How can I quickly diagnose abnormal relevance ranking in production?
Start by using the Explain API to inspect the score details for a single document. Then verify that the query runs in query context rather than filter context, and finally review field tokenization, boosts, synonyms, and length differences.
AI Readability Summary
This article systematically reconstructs the Elasticsearch relevance scoring model. It explains the meaning of _score, the core formulas behind TF-IDF and BM25, the roles of term frequency and inverse document frequency, field-length normalization, and the practical value of the Explain API. The goal is to help developers understand search ranking logic precisely and tune relevance scoring with confidence.