Embeddings convert text into computable semantic vectors. They are a foundational component of semantic search and RAG, solving the limitations of keyword retrieval and enabling knowledge bases to retrieve content by meaning. Core keywords: Embedding, Vector Database, RAG.
Technical Specifications Snapshot
| Parameter | Description |
|---|---|
| Core topic | Embedding models, semantic retrieval, RAG |
| Primary language | Python |
| Integration protocol | HTTP / REST API |
| Ecosystem frameworks | LangChain, Transformers |
| Vector databases | Chroma, Milvus, Pinecone, FAISS |
| Models covered | text-embedding-3-large, Qwen3-Embedding-8B, gemini-embedding-001 |
| GitHub stars | Not provided in the source |
| Core dependencies | openai, transformers, vector database SDK |
Embeddings serve as the semantic representation layer rather than the generation layer
Large language models generate answers, while embedding models represent meaning. An embedding model does not write a reply directly. Instead, it encodes text, sentences, or even images into high-dimensional vectors such as [0.3, 0.2, 0.7, ...].
These vectors are not random numbers. They are mathematical representations that preserve semantic relationships. Texts with similar meanings tend to appear closer in vector space, which allows computers to measure whether two pieces of content are similar by comparing distance or angle.
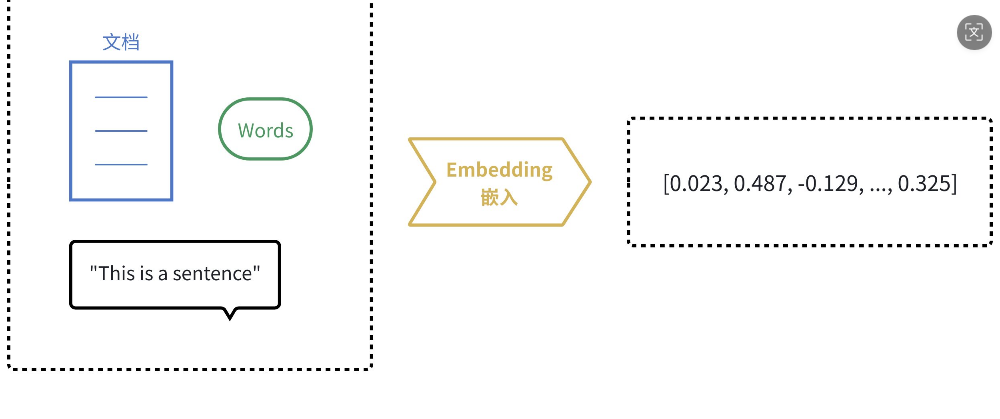 AI Visual Insight: This image illustrates how text passes through an embedding model and is mapped into vector space. The key takeaway is that natural language is encoded into computable numerical representations. Diagrams like this typically emphasize a three-layer structure: input text, encoder, and output vector, making it easier to understand that embeddings represent semantics rather than generate text.
AI Visual Insight: This image illustrates how text passes through an embedding model and is mapped into vector space. The key takeaway is that natural language is encoded into computable numerical representations. Diagrams like this typically emphasize a three-layer structure: input text, encoder, and output vector, making it easier to understand that embeddings represent semantics rather than generate text.
Semantic similarity is typically computed through vector operations
Common methods include Euclidean distance and cosine similarity. The former measures the straight-line distance between two points, while the latter focuses on directional alignment. In text applications, cosine similarity is more common because it reduces the effect of vector length and focuses more on semantic direction.
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
v1 = np.array([[0.6, -0.4, 0.1]]) # Semantic vector 1
v2 = np.array([[0.6, -0.2, 0.1]]) # Semantic vector 2
score = cosine_similarity(v1, v2)[0][0] # Compute cosine similarity
print(round(score, 4))This code demonstrates how cosine similarity can quantify the semantic closeness between two pieces of text.
The value of embeddings lies in semantic retrieval
Traditional database retrieval relies on exact keyword matching. It works well for structured condition-based queries but does not handle synonymous phrasing effectively. Embeddings map both queries and documents into the same vector space, enabling retrieval by meaning.
Semantic search can bypass literal wording mismatches
For example, a user might search for “laptop not charging,” while the documentation may instead say “a faulty power adapter prevents the laptop from receiving power.” Even without an exact phrase match, semantic retrieval can still find the relevant result.
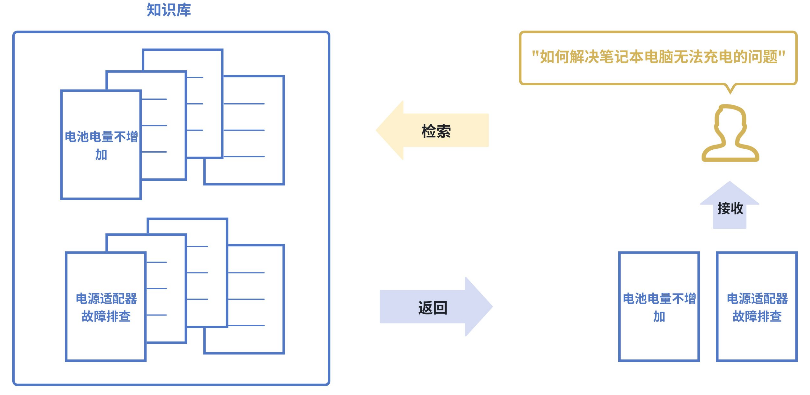 AI Visual Insight: This image shows the flow in which both the query and knowledge base documents are vectorized and then matched by similarity. The main point is that retrieval happens through semantic proximity rather than keyword hits. This is why embeddings outperform traditional full-text search when wording differs.
AI Visual Insight: This image shows the flow in which both the query and knowledge base documents are vectorized and then matched by similarity. The main point is that retrieval happens through semantic proximity rather than keyword hits. This is why embeddings outperform traditional full-text search when wording differs.
RAG turns embeddings into the entry point for knowledge augmentation
The essence of RAG is retrieve first, then generate. After a user submits a question, the system first vectorizes it with an embedding model, retrieves relevant chunks from the knowledge base, and then passes both the question and the retrieved context to the LLM to generate the answer.
This approach significantly reduces hallucinations, stale knowledge, and the inability to access private data. Embeddings determine retrieval quality, while the LLM determines expression quality. Their responsibilities are clearly separated.
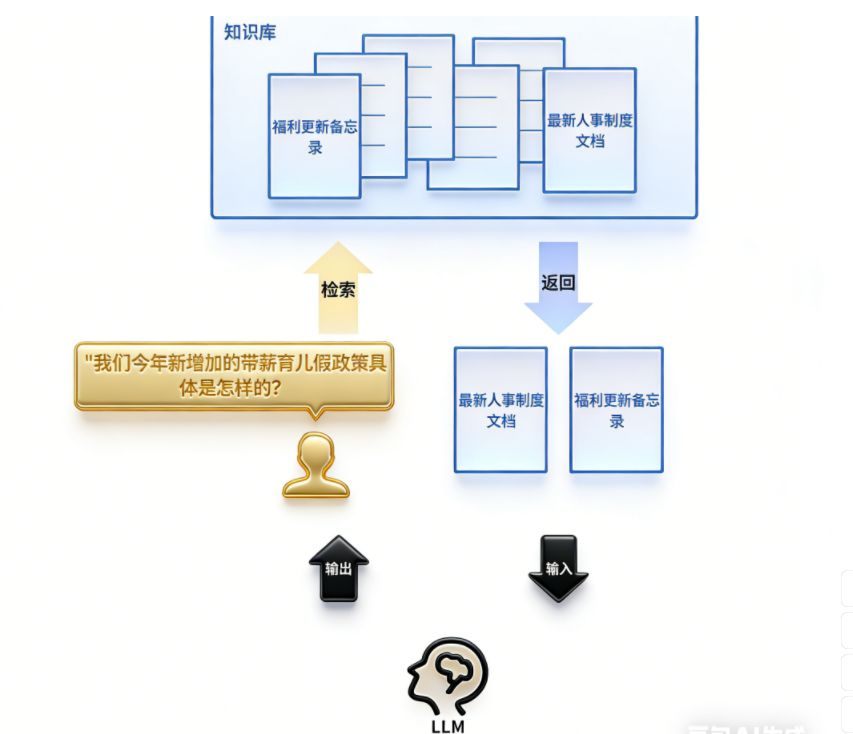 AI Visual Insight: This image shows the standard RAG pipeline: a user question enters the retrieval layer, documents are matched through embedding and similarity search, and the selected context is then injected into the large model for answer generation. The technical focus is the separation between the retrieval chain and the generation chain. Embeddings serve as the key bridge between enterprise knowledge and LLM output.
AI Visual Insight: This image shows the standard RAG pipeline: a user question enters the retrieval layer, documents are matched through embedding and similarity search, and the selected context is then injected into the large model for answer generation. The technical focus is the separation between the retrieval chain and the generation chain. Embeddings serve as the key bridge between enterprise knowledge and LLM output.
query = "What is our new paid parental leave policy this year?" # User question
query_vec = embed(query) # Encode the question as a vector
chunks = vectordb.similarity_search(query_vec, k=3) # Retrieve the most relevant documents
answer = llm.generate(query=query, context=chunks) # Generate an answer from the retrieved contextThis pseudocode summarizes the three main stages of RAG: embed, retrieve, and generate.
Embeddings have become a foundational capability across multiple AI scenarios
Beyond RAG, embeddings are widely used in recommendation systems, anomaly detection, and multimodal retrieval. The shared pattern is simple: first encode objects into a unified vector space, then compare them by similarity.
Recommendation systems rely on proximity of interests in vector space
User behavior history, product tags, and content features can all be encoded as vectors. The system generates recommendations by measuring the closeness between user vectors and item vectors rather than relying on a single label.
Anomaly detection depends on deviation in vector distributions
Normal samples typically cluster together, while anomalous samples lie far from dense regions. Financial risk control, spam detection, and log anomaly discovery can all use these differences in vector distribution.
 AI Visual Insight: This image shows the relationship between clusters and outliers in vector space. The core technical idea is that normal data forms dense clusters, while abnormal samples appear on the edges or far from the main distribution. This kind of visualization is especially intuitive for understanding vector-based anomaly detection.
AI Visual Insight: This image shows the relationship between clusters and outliers in vector space. The core technical idea is that normal data forms dense clusters, while abnormal samples appear on the edges or far from the main distribution. This kind of visualization is especially intuitive for understanding vector-based anomaly detection.
Mainstream model selection should focus on language coverage, dimensionality, and deployment cost
Among closed-source models, OpenAI’s text-embedding-3-large and Google’s gemini-embedding-001 are well suited for fast integration. Their advantages are out-of-the-box usability and low maintenance overhead. Among open-source models, Qwen3-Embedding-8B is a better fit for teams that need local deployment and stronger data control.
If your primary workload is in Chinese, prioritize models with stable Chinese semantic performance, such as the Qwen, BGE, and GTE families. Higher dimensions often improve semantic representation, but they also increase storage cost and retrieval overhead.
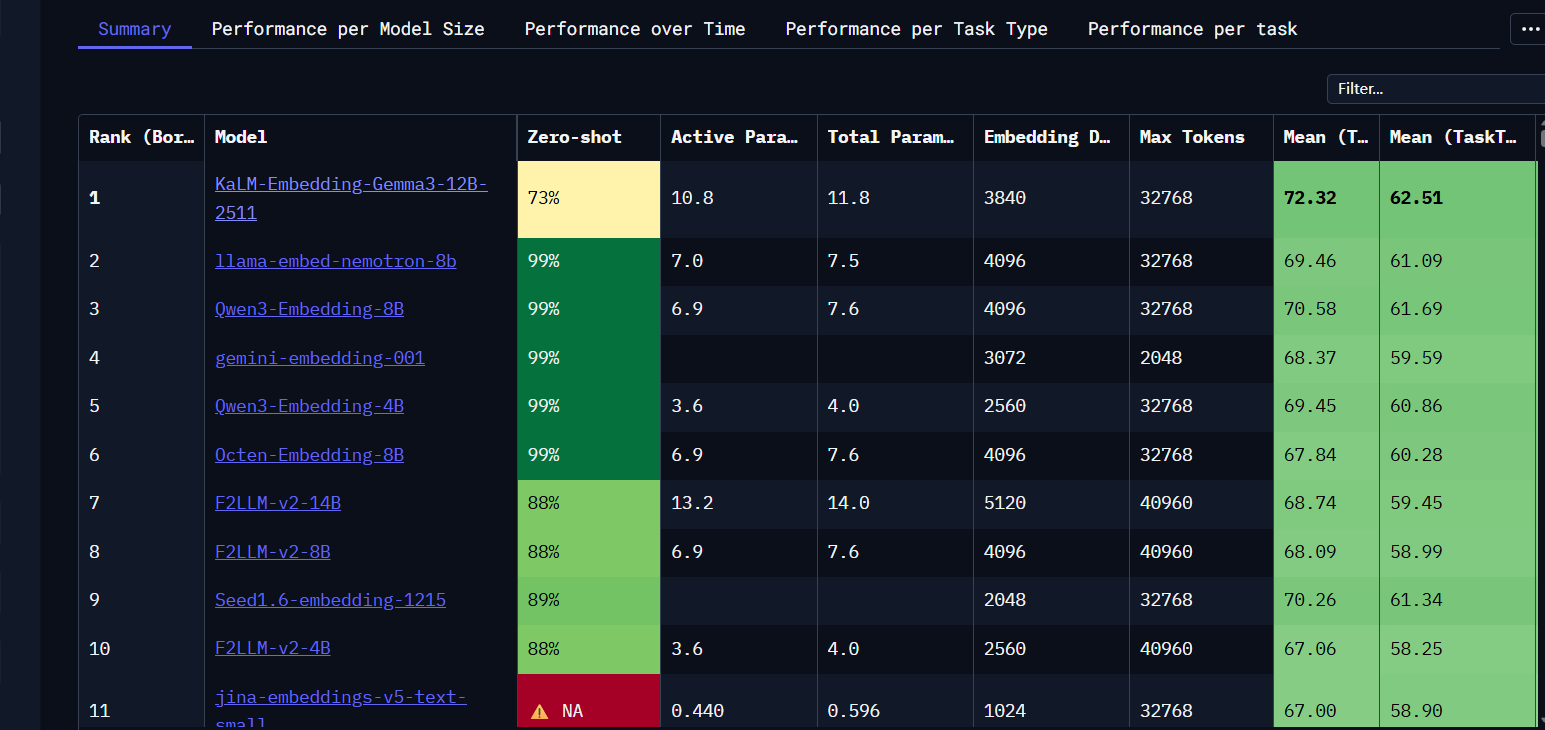 AI Visual Insight: This image is likely an embedding benchmark leaderboard or a model comparison interface. Its main value is to show ranking differences across models on multitask benchmarks. For model selection, these leaderboards are useful for comparing multilingual capability, retrieval quality, and overall performance rather than judging by parameter count alone.
AI Visual Insight: This image is likely an embedding benchmark leaderboard or a model comparison interface. Its main value is to show ranking differences across models on multitask benchmarks. For model selection, these leaderboards are useful for comparing multilingual capability, retrieval quality, and overall performance rather than judging by parameter count alone.
Integration strategy should match the stage of the business
During the prototyping phase, prefer APIs for speed and predictable cost. For large-scale or compliance-sensitive workloads, move to local deployment to gain stronger data control and potentially better long-term economics.
from openai import OpenAI
client = OpenAI(api_key="your-api-key") # Initialize the client
text = "This is the text to convert into a vector."
response = client.embeddings.create(
model="text-embedding-3-large", # Specify the embedding model
input=text,
dimensions=1024 # Reduce dimensions as needed to lower storage and retrieval cost
)
embedding = response.data[0].embedding # Extract the vector result
print(len(embedding))This code shows the shortest integration path for obtaining text embeddings with an SDK.
Local deployment is better suited for teams that need more privacy and control
Open-source embedding models are typically loaded with Transformers and run on GPUs for inference. Using Qwen3-Embedding-8B as an example, practical deployment requires attention to VRAM usage, throughput, batch size, and vector dimension settings.
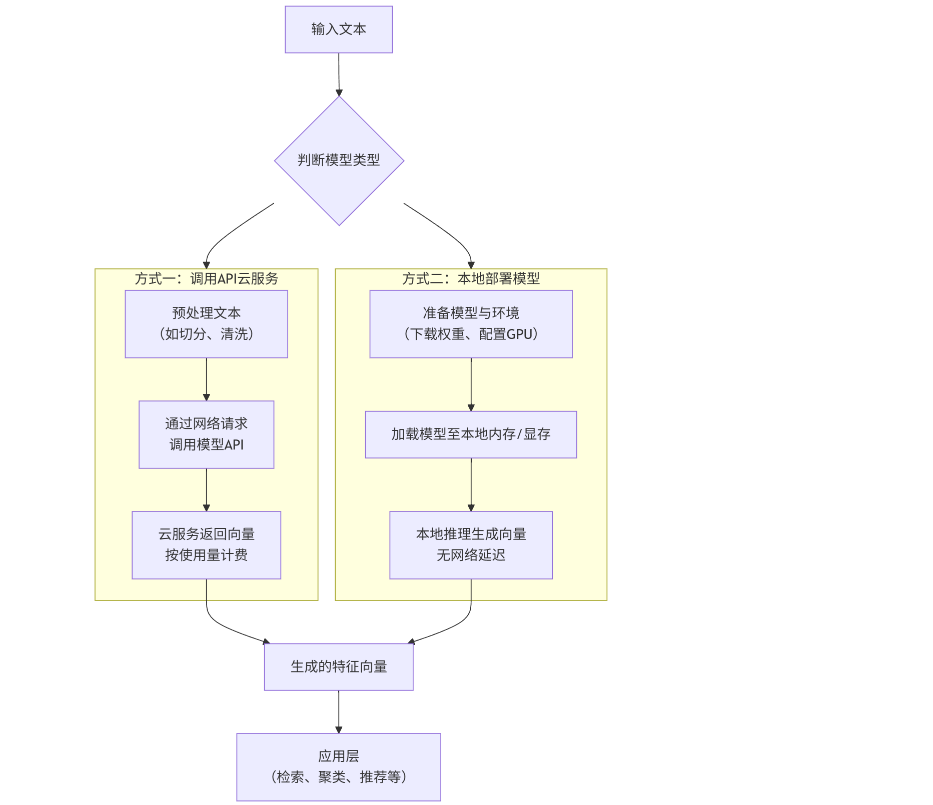 AI Visual Insight: This image shows the architectural split between two integration paths: closed-source APIs and open-source local deployment. The technical difference lies in the infrastructure responsibility boundary. In the first path, the cloud provider manages the stack. In the second, the team manages model weights, inference services, and hardware resources.
AI Visual Insight: This image shows the architectural split between two integration paths: closed-source APIs and open-source local deployment. The technical difference lies in the infrastructure responsibility boundary. In the first path, the cloud provider manages the stack. In the second, the team manages model weights, inference services, and hardware resources.
from transformers import AutoTokenizer, AutoModel
model_name = "Qwen/Qwen3-Embedding-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name) # Load the tokenizer
model = AutoModel.from_pretrained(model_name) # Load the embedding model
texts = ["Semantic retrieval", "Vector database"]
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs) # Run the forward pass
embeddings = outputs.last_hidden_state[:, 0, :] # Extract the sentence vector representationThis code demonstrates the basic workflow for loading an open-source model locally and generating sentence embeddings.
Vector databases are the persistence and retrieval core of embedding systems
Once vectors are generated, you cannot simply discard them. You must store them in a vector database that supports approximate nearest neighbor search. Chroma is suitable for learning and prototyping, Milvus for enterprise-grade retrieval, Pinecone for managed cloud services, and FAISS for lightweight local solutions.
In engineering practice, LangChain does not replace models. Its value lies in providing a unified abstraction over embeddings, vector stores, and retrieval pipelines, which reduces the cost of switching models.
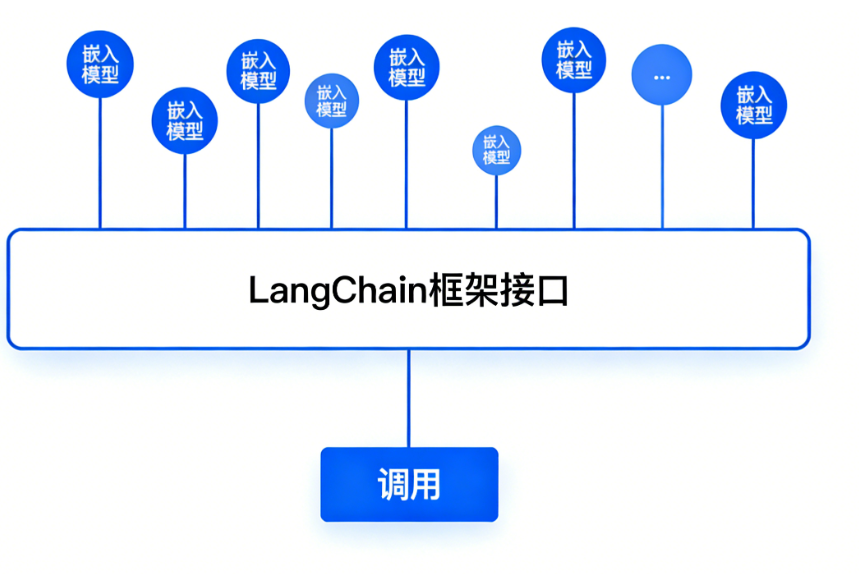 AI Visual Insight: This image shows LangChain as a unified abstraction layer that connects embedding models and vector databases. The technical implication is that upper-layer applications do not need to handle differences in underlying models or storage engines directly. They can rely on standard interfaces for vectorization, indexing, and similarity retrieval.
AI Visual Insight: This image shows LangChain as a unified abstraction layer that connects embedding models and vector databases. The technical implication is that upper-layer applications do not need to handle differences in underlying models or storage engines directly. They can rely on standard interfaces for vectorization, indexing, and similarity retrieval.
The practical conclusions can be summarized in six points
- Embeddings are the infrastructure of the retrieval layer in RAG.
- Semantic search is better suited than keyword matching for knowledge base QA.
- APIs are ideal for rapid validation, while local deployment is better for compliance and cost optimization.
- In Chinese-language scenarios, evaluate Qwen, BGE, and GTE first.
- Vector dimensionality affects quality, cost, and retrieval performance.
- The vector database determines recall efficiency and scalability.
FAQ structured Q&A
Q1: What is the core difference between embeddings and large language models?
A: LLMs generate text, while embeddings generate semantic vectors. The former outputs answers, while the latter outputs numerical representations used for retrieval, clustering, recommendation, and matching.
Q2: Why can’t you build RAG with only an LLM and no embeddings?
A: Because an LLM alone is not good at accurately retrieving relevant passages from massive external private document collections. Embeddings provide semantic retrieval, which is the prerequisite for delivering the right context to the LLM.
Q3: How should I choose between API integration and local deployment?
A: Use APIs during the prototyping phase to optimize development speed and maintenance cost. In production, if you handle sensitive data, expect high call volume, or need strong operational control, consider locally deploying an open-source model.
Core summary
This article systematically explains how embeddings work, how semantic similarity is measured, where embeddings are commonly used, and how to select mainstream models. It also compares API integration with local deployment and clarifies the critical role of vector databases in RAG, helping developers implement semantic retrieval and knowledge base QA efficiently.