GPT-image-2 is a state-of-the-art image generation model built for high-quality visual creation. Its core strengths include stable Chinese text rendering, strong understanding of complex scenes, and fast generation speed. It addresses common pain points such as garbled poster text, distorted UI details, and poor style consistency. Keywords: GPT-image-2, AI image generation, Chinese typography.
The technical specification snapshot highlights its practical positioning
| Parameter | Details |
|---|---|
| Model Name | GPT-image-2 |
| Primary Capabilities | Text-to-image, poster generation, UI recreation, scientific illustration, stylized imagery |
| Access Method | DeepSider browser extension |
| Entry Barrier | Available for registration in China, no GPT Plus required, includes free quota |
| Supported Environments | Chrome, Edge |
| Delivery Format | Web extension service |
| Reference Popularity | The original article reported 46k reads, 310 likes, and 86 saves |
| Core Dependencies | Browser extension, cloud-based image generation service |
GPT-image-2 has established a clear advantage in Chinese image generation
The biggest pain point in traditional AI image generation is not that it cannot draw. It is that the visuals may look convincing while the text completely fails. This is especially true for posters, promotional pages, and livestream screenshots that require Chinese copy, where garbled characters, typos, and broken layout structure are almost the norm.
The value of GPT-image-2 lies in moving usability from the demo stage to the production stage. The original examples show that it can generate not only clear visuals, but also relatively stable Chinese text, layout hierarchy, and interface element consistency.
 AI Visual Insight: This image shows a model capability comparison or ranking. The key signal is that GPT-image-2 is positioned in the top tier of current image generation models, emphasizing its lead in overall image quality, text rendering, and scene understanding.
AI Visual Insight: This image shows a model capability comparison or ranking. The key signal is that GPT-image-2 is positioned in the top tier of current image generation models, emphasizing its lead in overall image quality, text rendering, and scene understanding.
 AI Visual Insight: This image presents a complete product introduction graphic. It highlights the model’s control over layout composition, title hierarchy, mixed text-and-image arrangement, and branded visual elements, suggesting output quality close to commercial promotional artwork.
AI Visual Insight: This image presents a complete product introduction graphic. It highlights the model’s control over layout composition, title hierarchy, mixed text-and-image arrangement, and branded visual elements, suggesting output quality close to commercial promotional artwork.
Developers should focus on two critical capability inflection points
The first is Chinese readability. The second is complex visual semantic alignment. The former determines whether the model can be used for posters and marketing materials. The latter determines whether it can support UI mockups, e-commerce detail pages, and knowledge diagrams.
prompt = "生成一张中文科技海报,标题清晰可读,主视觉为未来感城市,配色蓝紫,包含副标题与按钮区域" # Use a Chinese prompt to explicitly constrain the layout
settings = {
"style": "poster", # Specify the poster style
"language": "zh-CN", # Strengthen the Chinese-language context
"quality": "high" # Improve rendering quality
}
print(prompt, settings) # Output request parameters for debuggingThis example shows that high-quality Chinese image generation depends on explicit constraints for layout, language, and quality.
DeepSider provides a low-friction access path for users in China
The core conclusion from the original content is straightforward: DeepSider already integrates GPT-image-2, and users in China can register and use it directly without a Plus subscription, without additional network barriers, and with a free daily quota.
This means developers, designers, and operations teams do not need to solve account or access issues before validating whether the model fits their workflow. During the evaluation stage, this is a major efficiency gain.
 AI Visual Insight: This image shows the DeepSider product entry point or model selection interface. It indicates that GPT-image-2 has been packaged as a directly callable capability module, reducing access complexity for both regular users and developers.
AI Visual Insight: This image shows the DeepSider product entry point or model selection interface. It indicates that GPT-image-2 has been packaged as a directly callable capability module, reducing access complexity for both regular users and developers.
 AI Visual Insight: This image presents the interaction interface after the browser extension is installed, showing that the model has been integrated into a browser-side workflow so users can trigger image generation without switching to a more complex platform.
AI Visual Insight: This image presents the interaction interface after the browser extension is installed, showing that the model has been integrated into a browser-side workflow so users can trigger image generation without switching to a more complex platform.
 AI Visual Insight: This image highlights the extension launch or invocation flow, reflecting a near-context generation design that fits direct image creation during web browsing, content creation, and asset collection.
AI Visual Insight: This image highlights the extension launch or invocation flow, reflecting a near-context generation design that fits direct image creation during web browsing, content creation, and asset collection.
The shortest getting-started flow looks like this
# 1. Install the DeepSider browser extension
# 2. Register an account and sign in
# 3. Select GPT-image-2 from the model list
# 4. Enter a Chinese prompt and generate
# 5. Download the image or continue iterating on the promptThis flow summarizes the shortest zero-code path for regular users to try GPT-image-2.
GPT-image-2 already covers high-value use cases from marketing to research
The original article provides a dense set of examples with broad coverage. The most representative include livestream screenshots, e-commerce posters, interior design renderings, Apple-style landing page visuals, knowledge diagrams, scientific illustrations, vintage photos, and animated-style images.
These examples show that GPT-image-2 does not just create attractive images. It also demonstrates cross-task generalization: it can produce realistic interfaces, handle illustration styles, and output structured infographics.
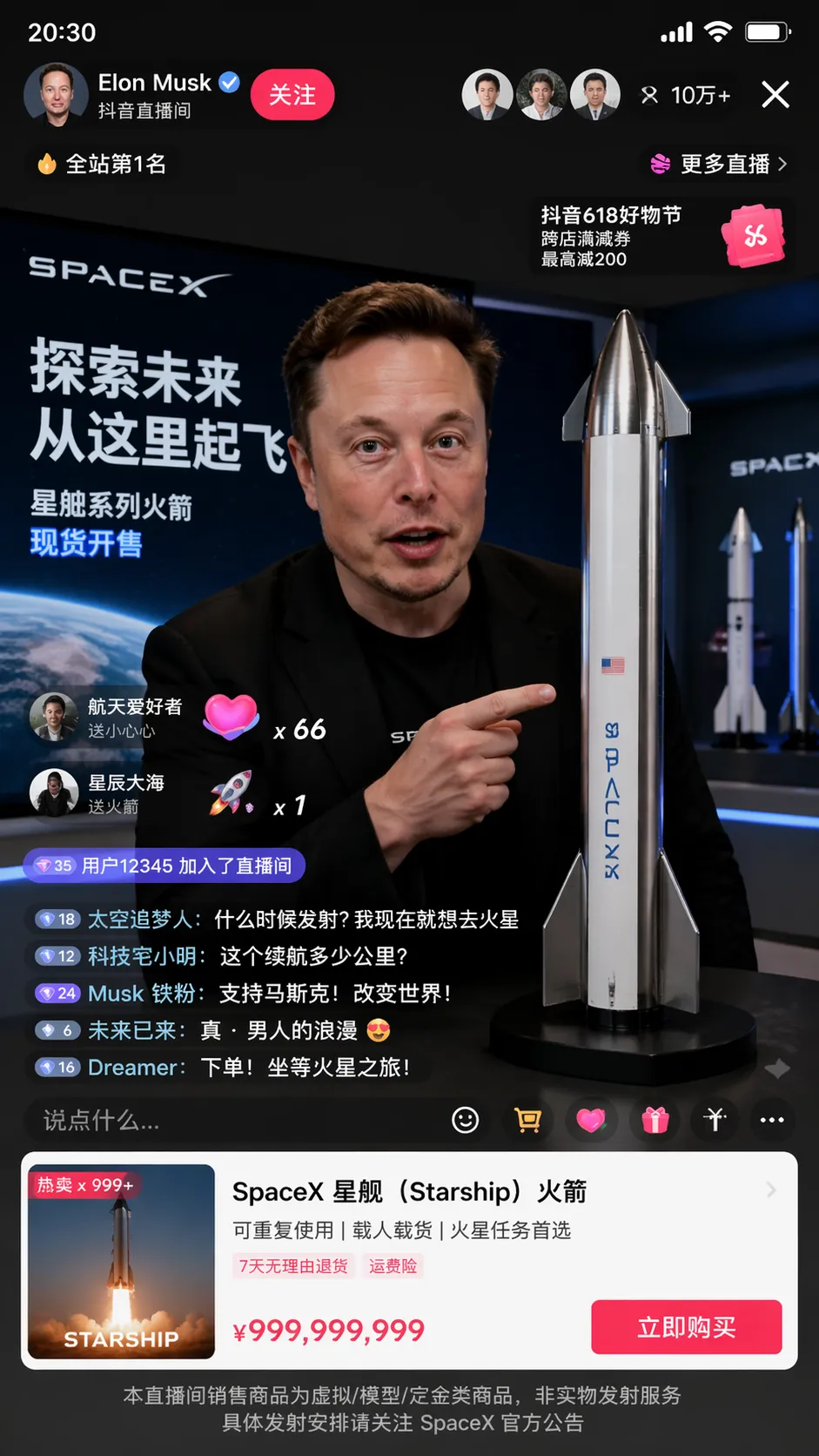 AI Visual Insight: This image shows a realistic livestream screenshot generation result. The focus is on the consistency of avatars, bullet comments, like counts, product sections, and the host screen, demonstrating the model’s strong understanding of social media UI structure.
AI Visual Insight: This image shows a realistic livestream screenshot generation result. The focus is on the consistency of avatars, bullet comments, like counts, product sections, and the host screen, demonstrating the model’s strong understanding of social media UI structure.
 AI Visual Insight: This image shows a high-detail illustration or poster generation result, indicating that the model can already approach commercial-grade visual quality in lighting, depth, subject emphasis, and style consistency.
AI Visual Insight: This image shows a high-detail illustration or poster generation result, indicating that the model can already approach commercial-grade visual quality in lighting, depth, subject emphasis, and style consistency.
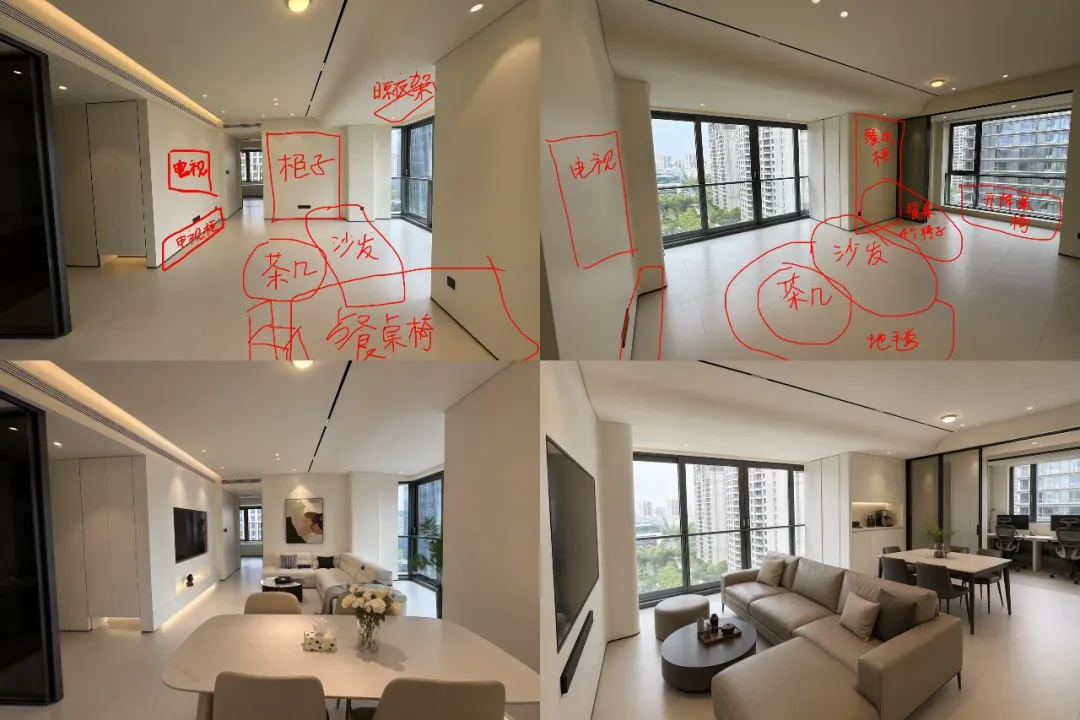 AI Visual Insight: This image appears to be an interior design or renovation rendering. The model not only generates spatial perspective, but also handles materials, lighting, and furniture layout, making it suitable for concept previews and fast proposals.
AI Visual Insight: This image appears to be an interior design or renovation rendering. The model not only generates spatial perspective, but also handles materials, lighting, and furniture layout, making it suitable for concept previews and fast proposals.
 AI Visual Insight: This image demonstrates e-commerce poster generation capabilities. The key strengths are product emphasis, focused selling points, and a conversion-oriented layout suitable for pre-generating promotional graphics and ad creatives.
AI Visual Insight: This image demonstrates e-commerce poster generation capabilities. The key strengths are product emphasis, focused selling points, and a conversion-oriented layout suitable for pre-generating promotional graphics and ad creatives.
 AI Visual Insight: This image is a complex knowledge-diagram style graphic, showing that the model can simultaneously handle structural sections, explanatory text, and visual guidance elements, which is highly valuable for educational content and technical communication.
AI Visual Insight: This image is a complex knowledge-diagram style graphic, showing that the model can simultaneously handle structural sections, explanatory text, and visual guidance elements, which is highly valuable for educational content and technical communication.
 AI Visual Insight: This image leans toward scientific illustration, indicating that the model already has professional diagramming capabilities and can assist with first drafts for paper figures, experimental flowcharts, or science communication visuals.
AI Visual Insight: This image leans toward scientific illustration, indicating that the model already has professional diagramming capabilities and can assist with first drafts for paper figures, experimental flowcharts, or science communication visuals.
What matters most for production is not how stunning a result looks, but how stable it is
If a model produces an exceptional image only once in a while, it behaves more like a toy. If it can consistently generate editable, reusable, and batch-iterable results, it becomes a productivity tool. GPT-image-2 is clearly moving toward the latter.
scenes = ["电商海报", "科研绘图", "直播截图", "产品官网首屏"]
for scene in scenes:
print(f"正在生成: {scene}") # Validate multiple business scenarios in batchThis example expresses a practical truth: model evaluation should center on batch testing across scenarios, not on a single sample image.
The real significance of GPT-image-2 is turning AI image generation from luck-based output into a workflow capability
The final judgment in the original article is accurate: in the past, AI image generation felt like drawing a random card. Now it feels more like having a visual copilot. This shift means image generation is entering a stage where it is predictable, collaborative, and ready to be integrated into workflows.
For teams, it is best suited to three categories of work: concept sketches, first-pass assets, and bulk variants. This preserves human aesthetic judgment while allowing the model to absorb a large share of repetitive production work.
 AI Visual Insight: This image shows an old-photo or vintage visual effect. The model not only simulates period color tones, but also reconstructs film grain, facial expression, and historical texture, indicating strong style transfer capabilities.
AI Visual Insight: This image shows an old-photo or vintage visual effect. The model not only simulates period color tones, but also reconstructs film grain, facial expression, and historical texture, indicating strong style transfer capabilities.
 AI Visual Insight: This image presents a Pixar-style character portrait. The focus is on consistent character design, friendly facial expression, cartoon-like material rendering, and cinematic lighting control.
AI Visual Insight: This image presents a Pixar-style character portrait. The focus is on consistent character design, friendly facial expression, cartoon-like material rendering, and cinematic lighting control.
FAQ
What problems is GPT-image-2 best suited to solve?
It is best suited for solving Chinese poster text corruption, complex UI generation, inconsistent visual style, and slow production of high-quality visual drafts.
How can users in China try GPT-image-2 with minimal friction?
They can register and use it directly through the DeepSider browser extension. It supports Chrome and Edge, does not require GPT Plus, and usually includes a free usage quota.
Which evaluation metrics should developers focus on for models like this?
Developers should prioritize Chinese text readability, scene reconstruction fidelity, composition stability, generation speed, and consistent performance across posters, UI mockups, scientific graphics, and other scenarios.
Core Summary: GPT-image-2 is emerging as a benchmark for the next generation of image generation models, with major breakthroughs in distorted Chinese text, complex scene reconstruction, and high-aesthetic output. Based on hands-on access through DeepSider, this article maps its capability boundaries, typical applications, free access path, and the evaluation points that matter most to developers.