ModelVerse Nebula provides an embodied expression layer for AI agents through a combination of parameter streaming and on-device rendering. This approach solves the high latency, audio-video desynchronization, and heavy cost issues common in traditional digital human stacks. Its core value is enabling human-like natural interaction in customer service, guidance, and training scenarios. Keywords: embodied AI, parameter streaming, 3D digital humans.
| Technical Specification | Details |
|---|---|
| Core Focus | Embodied AI agent interaction, intelligent customer service, 3D digital humans |
| Primary Languages | Java, Android Gradle |
| Integration Protocols / Mechanisms | Socket.IO, Protobuf, streaming text-driven interaction |
| Typical Platforms | Android, Web, iOS, Windows |
| Architectural Characteristics | Parameter stream transmission, on-device real-time rendering, multimodal expression |
| Core Dependencies | Gson, OkHttp, MsgPack, Socket.IO, Protobuf, Media3 ExoPlayer |
| Latency Performance | End-to-end driving latency can be controlled within 500 ms |
| Bandwidth Profile | KB-level parameter transfer, significantly lower than video streaming |
The core interaction bottleneck of AI agents is the missing expression layer
Large language models are already smart enough, but most AI agents still stop at text boxes or mechanical voice output. The issue is not cognition. The issue is that the output format lacks a “body.”
In customer service, exhibition halls, government services, and education, users expect more than answers. They expect coordinated eye contact, lip sync, pauses, emotion, and posture. A traditional chat interface cannot support this level of natural interaction.
Traditional stitched pipelines amplify both experience and cost problems
A common industry pipeline works like this: the LLM generates text, TTS synthesizes speech, and then a separate digital human engine renders the avatar. The modules look cleanly separated, but the pipeline is inherently serial.
This architecture has three structural weaknesses: slow response, audio-video misalignment, and complex system operations. Any jitter in any step directly degrades the final user experience.
Traditional pipeline: LLM → TTS → Rendering Engine → Frontend Player
Nebula pipeline: Cloud Brain / Expression Engine → Parameter Stream → On-Device Real-Time RenderingThis comparison shows that Nebula turns “expression” from a post-processing add-on into a native part of the interaction pipeline.
ModelVerse Nebula reconstructs the embodied expression pipeline with a parameter streaming architecture
 AI Visual Insight: This image shows a front-facing hyper-realistic 3D digital human with detailed material rendering. It highlights skin specularity, hair rendering, and the micro-expression capacity enabled by facial skeletal driving, demonstrating that the platform is not based on static textures but on an on-device character model capable of real-time lip sync, gaze control, and posture control.
AI Visual Insight: This image shows a front-facing hyper-realistic 3D digital human with detailed material rendering. It highlights skin specularity, hair rendering, and the micro-expression capacity enabled by facial skeletal driving, demonstrating that the platform is not based on static textures but on an on-device character model capable of real-time lip sync, gaze control, and posture control.
Nebula’s key advantage is not simply making digital humans look more realistic. It turns the expression layer into infrastructure. It is not just a player. It gives the agent a responsive body.
In a parameter stream architecture, the network transmits structured parameters instead of video frames. These parameters drive lip movement, eyebrows, head motion, gestures, and state transitions. Once the terminal receives them, it generates the visuals locally in real time.
The parameter stream approach improves latency, bandwidth, and concurrency at the same time
In a video streaming model, the server must continuously render, encode, transmit, and then the client must decode and play. The pipeline is long and bandwidth-intensive. A parameter stream only transmits motion instructions, and the client reconstructs the result using local rendering capabilities.
Video stream: Server renders frames → Encodes → Transmits → Decodes → Plays
Parameter stream: Server generates parameters → Compresses and transmits → Client receives → Renders locallyThe significance of this pipeline change is that it reduces high-frequency data from “images” to “control instructions.”
The Android SDK integration path is already production-oriented
The original implementation shows that once developers obtain an AppID and Secret, they can quickly start from the Android demo. The official team also provides sample projects on both GitHub and Gitee, lowering the barrier to first-time integration.
First, replace the authentication information in demo_configs.json, then copy the SDK .aar package into the project’s libs directory, and declare the dependency in Gradle.
{
"config": {
"init_events": [
{
"type": "SetCharacterCanvasAnchor",
"x_location": 0,
"y_location": 0,
"width": 1,
"height": 1,
"appid": "your AppID",
"appSecret": "your AppSecret"
}
]
}
}This configuration initializes the digital human canvas and application authentication. It is the minimum prerequisite for getting the demo running.
The dependency layer reveals the platform’s real-time communication and serialization capabilities
The dependency list shows that the Nebula Android SDK already covers key components for network communication, message encoding and decoding, media playback, and lightweight serialization, making it well suited for real-time interactive scenarios.
implementation files('libs/xmovdigitalhuman-xxx.aar')
implementation "javax.vecmath:vecmath:1.5.2"
implementation "com.google.code.gson:gson:2.13.1"
implementation "com.squareup.okhttp3:okhttp:5.1.0"
implementation "org.msgpack:msgpack-core:0.9.3"
implementation "io.socket:socket.io-client:2.1.0"
implementation "com.google.protobuf:protobuf-javalite:3.21.12"
implementation "androidx.media3:media3-exoplayer:1.9.0"This dependency set provides the communication, serialization, and streaming media foundations required for SDK integration.
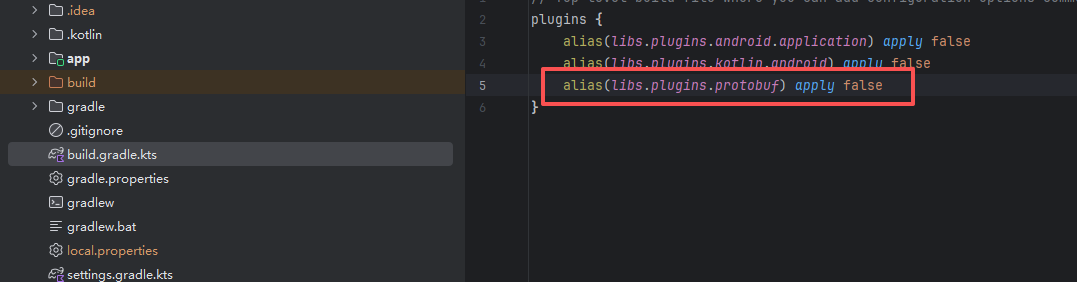 AI Visual Insight: This screenshot shows the Protobuf-related build configuration area in an Android/Gradle project. It indicates that the project needs additional compiler plugins or task declarations in the root build script to support parameter message generation and transmission.
AI Visual Insight: This screenshot shows the Protobuf-related build configuration area in an Android/Gradle project. It indicates that the project needs additional compiler plugins or task declarations in the root build script to support parameter message generation and transmission.
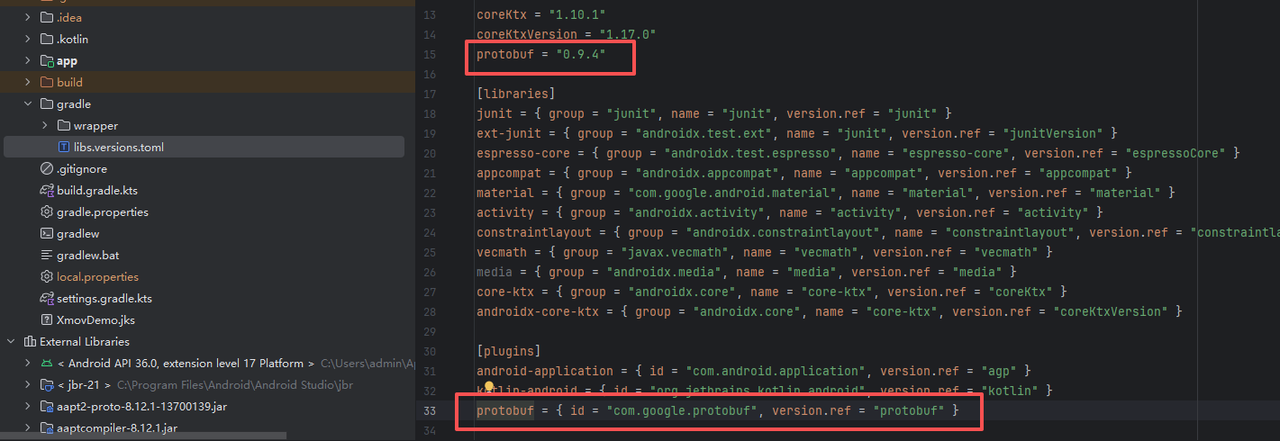 AI Visual Insight: This image further shows dependency or plugin blocks in the build file, emphasizing that SDK integration is not limited to importing an
AI Visual Insight: This image further shows dependency or plugin blocks in the build file, emphasizing that SDK integration is not limited to importing an .aar file. It also requires consistent configuration of the message protocol stack and packaging workflow to avoid runtime protocol parsing failures.
 AI Visual Insight: This screenshot presents the project structure or runtime preparation state after configuration is complete, showing that Protobuf and SDK resources have been successfully incorporated into the build pipeline and that the project is ready to load 3D digital human assets.
AI Visual Insight: This screenshot presents the project structure or runtime preparation state after configuration is complete, showing that Protobuf and SDK resources have been successfully incorporated into the build pipeline and that the project is ready to load 3D digital human assets.
Streaming text driving is the key to making a digital human sound like a person
What truly shapes the user experience is not only whether the model produces the right answer, but whether it can express that answer while generating it. If the system must wait for the LLM to output a full long response before speaking, the interaction degrades into a narrated report.
Nebula supports streaming-driven interaction, but streaming text is naturally fragmented. The client therefore needs sentence buffering to merge scattered tokens into more natural expression units.
import java.util.concurrent.Flow.*;
import java.util.regex.Pattern;
public class ReactiveLLMHandler {
private static final Pattern SENTENCE_PATTERN = Pattern.compile(".*?[,。!?,.!?]");
private final Avatar avatar;
public ReactiveLLMHandler(Avatar avatar) {
this.avatar = avatar;
}
public Subscriber
<String> createSubscriber() {
return new Subscriber<>() {
private Subscription subscription;
private StringBuilder buffer = new StringBuilder();
private boolean isFirstSentence = true;
@Override
public void onSubscribe(Subscription sub) {
this.subscription = sub;
avatar.think(); // Switch to thinking state when the stream starts
sub.request(1); // Pull data on demand to avoid uncontrolled streaming
}
@Override
public void onNext(String chunk) {
buffer.append(chunk); // Continuously buffer fragmented text returned by the LLM
var matcher = SENTENCE_PATTERN.matcher(buffer);
if (matcher.find()) {
String sentence = buffer.substring(0, matcher.end());
buffer.delete(0, matcher.end());
avatar.speak(sentence, isFirstSentence, false); // Trigger speech only after a complete sentence is detected
isFirstSentence = false;
}
subscription.request(1); // Request the next text fragment
}
@Override
public void onError(Throwable throwable) {}
@Override
public void onComplete() {
if (buffer.length() > 0) {
avatar.speak(buffer.toString(), false, true); // Process remaining text after the stream ends
}
}
};
}
}This code reorganizes fragmented LLM output into natural sentences, then drives the digital human to express them sentence by sentence in a streaming manner.
The end-to-end state machine determines whether the interaction feels human
In the original experience, the digital human switches naturally among Listen, Think, and Speak: it listens first, then thinks, and finally responds with emotion and motion. This state flow is much closer to real conversation than simple audio playback.
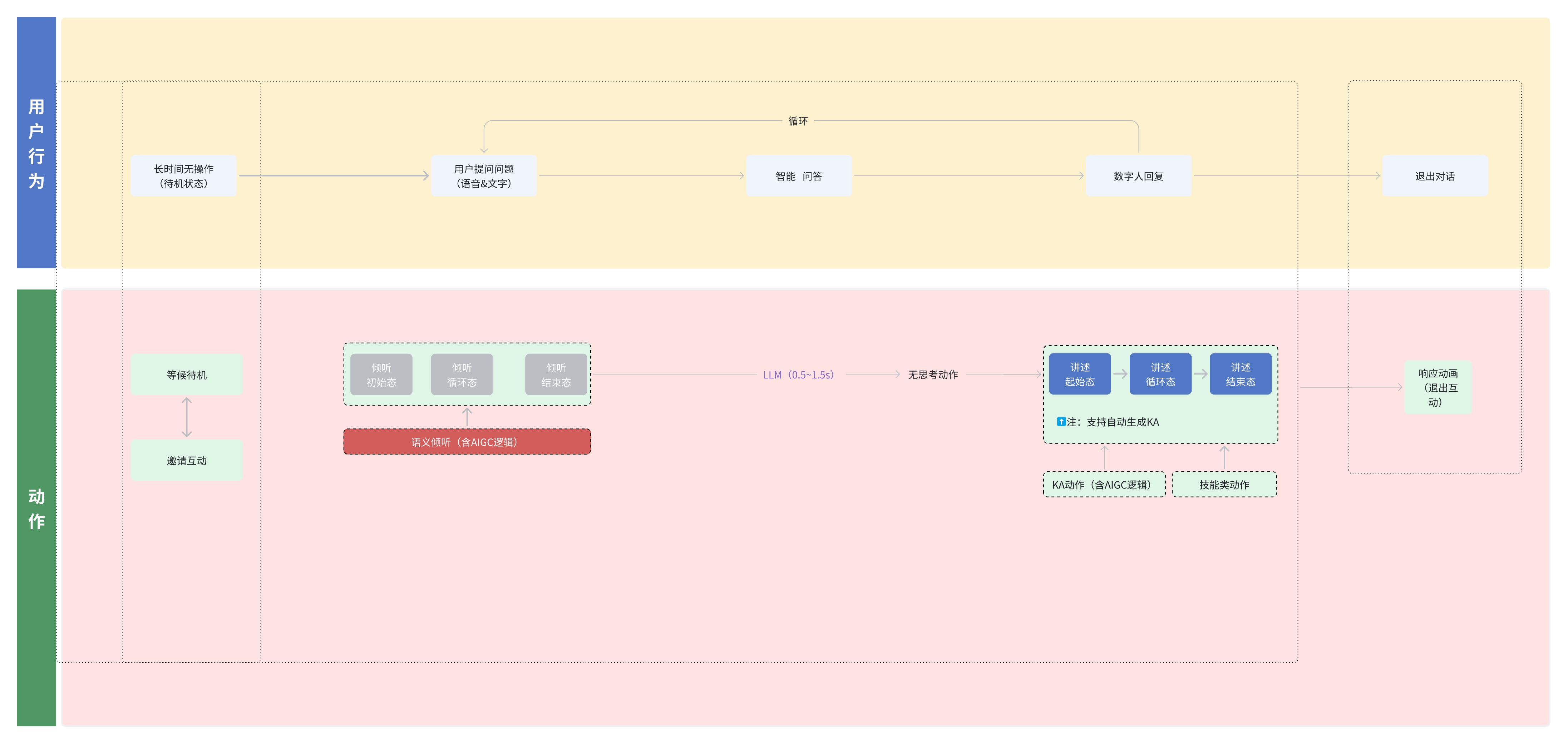 AI Visual Insight: This image likely shows the digital human’s state transition graph, usually including nodes such as listening, thinking, speaking, and idle, along with their transition paths. Technically, this corresponds to an event-driven state machine used to coordinate voice input, expression switching, motion generation, and lip sync.
AI Visual Insight: This image likely shows the digital human’s state transition graph, usually including nodes such as listening, thinking, speaking, and idle, along with their transition paths. Technically, this corresponds to an event-driven state machine used to coordinate voice input, expression switching, motion generation, and lip sync.
What developers actually get is an embodied interaction operating system
From an engineering perspective, Nebula’s value is not limited to model accuracy. It standardizes high-naturalness expression as a platform capability: character assets, voice, gestures, state machines, protocols, and debugging tools are all brought into one unified system.
That means teams no longer need to assemble TTS, rendering engines, and players on their own, nor do they need to repeatedly compromise between audio-video synchronization and bandwidth cost.
 AI Visual Insight: This image shows the platform console or debugging interface. It may include panels for state monitoring, parameter tuning, conversation logs, and performance metrics, indicating that developers can directly observe latency, character state, and rendering effects throughout the interaction pipeline and thereby improve debugging efficiency.
AI Visual Insight: This image shows the platform console or debugging interface. It may include panels for state monitoring, parameter tuning, conversation logs, and performance metrics, indicating that developers can directly observe latency, character state, and rendering effects throughout the interaction pipeline and thereby improve debugging efficiency.
This architecture is better suited for large-scale deployment across customer service and general service terminals
Banks, hospitals, shopping malls, and government service halls already have large numbers of existing screens. If these endpoints can be upgraded into AI service terminals through only an SDK and parameter streaming, without replacing hardware, the business value becomes very direct.
Compared with cloud-rendered video digital human solutions, parameter streaming is better positioned to support high concurrency and low-cost deployment. It is also a stronger fit for human-machine service scenarios that must remain online continuously, allow interruption, and support follow-up questions.
FAQ
Q1: Why is parameter streaming better than video streaming for real-time digital humans?
A: Because it transmits motion parameters rather than video frames, the data volume is much smaller and latency is lower. At the same time, the client can use local rendering to maintain high visual quality.
Q2: What are the most critical engineering tasks when integrating ModelVerse Nebula?
A: The most important tasks are completing authentication configuration, integrating the .aar, adding the required Protobuf and Socket dependencies, and handling sentence segmentation for streaming text. If you miss these pieces, the naturalness of expression will degrade significantly.
Q3: What are the most suitable business scenarios for this platform?
A: It is especially well suited for intelligent customer service, guided reception, training and instruction, medical inquiry, government services, and other scenarios that require visual conversation and emotional expression.
Core Summary: This article explains how ModelVerse Nebula uses a parameter streaming architecture to replace the traditional stitched pipeline of “LLM + TTS + rendering.” It shows how the platform balances low latency, high visual quality, and low cost, and uses Android SDK integration plus streaming sentence segmentation practices to demonstrate how it provides a practical embodied expression layer for AI agents.