Kafka producers must decide the target partition before sending a message. That decision directly affects load balancing, per-key ordering, and throughput efficiency. This article focuses on the partition selection flow, key hashing, round-robin, and sticky partitioning, and explains why tuning
batch.sizeandlinger.msmatters. Keywords: Kafka, producer partitioning, sticky partitioning
Technical Specification Snapshot
| Parameter | Details |
|---|---|
| Technical Topic | Kafka Producer Partitioning |
| Primary Language | Java |
| Communication Protocol | Kafka custom binary protocol / TCP |
| Source Type | Kafka study notes |
| Reference Popularity | Blog article, tag shows Kafka(7) |
| Core Dependency | org.apache.kafka:kafka-clients |
| Key Interface | org.apache.kafka.clients.producer.Partitioner |
| Core Configuration | batch.size, linger.ms |
Kafka producer partitioning determines where a message lands first
In Kafka, a partition is the fundamental unit of message organization. It supports horizontal scaling and load balancing, and it also carries responsibility for business-level ordering. For a producer, the first step in writing a message is not to send it immediately, but to calculate the target partition first.
When you call producer.send(record), partition selection follows a clear priority order. If the developer explicitly specifies a partition, Kafka uses that value directly. If no partition is specified but a key is provided, Kafka computes the partition from the key. If neither is present, Kafka falls back to the default assignment strategy.
// Pseudocode for partition selection before the producer sends a message
if (record.partition() != null) {
// If the partition is explicitly specified, write directly to the target partition
partition = record.partition();
} else if (record.key() != null) {
// If a key exists, choose a fixed partition based on the hash result
partition = hash(record.key()) % numPartitions;
} else {
// If neither key nor partition is provided, use the default assignment strategy
partition = defaultPartitionStrategy();
}The core purpose of this logic is to map business semantics to a physical partition.
Key-based partitioning preserves per-key ordering
If a message includes a key, Kafka tries to send messages with the same key to the same partition. A common calculation is abs(murmur2(key)) % numPartitions. As a result, data for the same user, order, or device consistently lands in a fixed partition.
The value of this strategy is not uniformity, but ordering. Kafka guarantees ordering only within a single partition, so if you want events for the same business entity to be consumed in timeline order, the safest approach is to assign a consistent key.
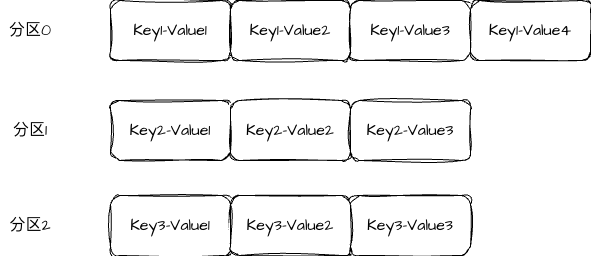
AI Visual Insight: The diagram shows how the same business key is stably routed to the same partition after hashing, emphasizing the deterministic mapping from key to partition. This means multiple messages for the same entity enter a single partition and preserve local ordering, while different keys can still be distributed across multiple partitions in parallel.
import org.apache.kafka.clients.producer.ProducerRecord;
ProducerRecord<String, String> record =
new ProducerRecord<>("orders", "user_1024", "create-order"); // Specify a key to keep routing stable for related messagesThis pattern works well for order flows, account ledgers, device events, and other scenarios that require local ordering.
The benefits and trade-offs of key hashing must be evaluated together
The advantage is stable ordering and clear consumption semantics. The trade-off is that a hot key can overload a single partition and create partition skew. If business keys are distributed unevenly, you may need to shard the key space or introduce a custom partitioner.
The default partitioning strategy evolved from round-robin to sticky partitioning
In older Kafka versions, round-robin was commonly used when no key was specified. It sends messages to different partitions in sequence, for example: the first message to partition0, the second to partition1, and the third to partition2. Its main advantage is highly even distribution.
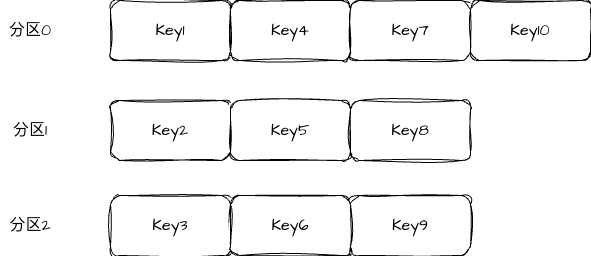
AI Visual Insight: The diagram illustrates how keyless messages are cyclically distributed across multiple partitions in order. Because each message may switch to a different target partition, load distribution is strong, but batches become fragmented, network requests become more scattered, and producer-side batching efficiency and overall throughput can drop.
// Simplified pseudocode for the round-robin strategy
partition = nextPartition;
nextPartition = (nextPartition + 1) % numPartitions; // Rotate to the next partition in sequenceThe main benefit of round-robin is even distribution; the main drawback is smaller batches.
Sticky partitioning prioritizes throughput over perfect short-term uniformity
To address the small-batch problem caused by round-robin, Kafka introduced sticky partitioning. It keeps sending messages to the same partition for a period of time, until the batch is full or the wait threshold is reached, and only then switches to a new partition.
This approach can significantly improve batching efficiency, reduce the number of requests, and increase throughput. It sacrifices perfect short-term distribution in exchange for better send efficiency, which makes it more practical in modern production environments.
// Simplified pseudocode for the sticky strategy
if (currentBatch.isFull() || lingerTimeoutReached()) {
// Switch partitions only after the current batch is full or the wait timeout is reached
partition = selectNewPartition();
} else {
// Continue using the previous partition to improve batching efficiency
partition = currentStickyPartition;
}Sticky partitioning is essentially an engineering trade-off between balance and throughput.
A custom partitioner lets you encode business rules directly into routing logic
If the default strategy does not meet your needs, you can implement the org.apache.kafka.clients.producer.Partitioner interface. Its partition() method receives the topic, key, value, and cluster metadata, which is enough to support most business routing rules.
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class RegionPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
String region = key == null ? "default" : key.toString();
int partitions = cluster.partitionCountForTopic(topic);
// Route by region to isolate different business traffic patterns
return Math.abs(region.hashCode()) % partitions;
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> configs) {}
}This example shows how to turn a regional dimension into a partition routing rule.
batch.size and linger.ms are key parameters that shape partitioning behavior at send time
batch.size controls how much data a single batch can hold. A common default is 16 KB. Larger batches usually help improve throughput, but they also increase per-send latency and memory usage.
linger.ms controls how long the producer is willing to wait to accumulate more messages. The default is often 0, which means send as soon as possible. In production, you can often set it to 5 to 100 ms based on your throughput target to improve the batching benefits of sticky partitioning.
# Increase the capacity of each batch for high-throughput scenarios
batch.size=16384
# Wait briefly for more messages to enter the batch and improve compression and send efficiency
linger.ms=20Together, these two parameters determine whether messages are sent immediately or sent more efficiently after batching.
Understanding partitioning is the starting point for Kafka producer performance tuning
Kafka producer partitioning is not just a routing detail. It directly determines ordering semantics, load distribution, and send throughput. Explicit partitions fit scenarios that require strong control, key hashing fits local ordering, round-robin emphasizes balance, and sticky partitioning is more focused on performance optimization.
In engineering practice, first determine whether the business requires ordering. Then decide whether to assign a key. After that, tune batch.size and linger.ms for throughput. This usually gives you a reliable baseline for producer configuration.
FAQ
1. Why does Kafka need to determine the partition before sending a message?
Because the partition is Kafka’s smallest unit of storage and ordering guarantees. Only after the target partition is known can the producer complete batch aggregation, routing, and ordering control.
2. When should a message have a key?
You should set a key when messages for the same business entity must be consumed in order. Typical examples include user activity streams, order state transitions, and account change ledgers.
3. Why does sticky partitioning usually deliver higher throughput than round-robin?
Because it allows more messages to accumulate in the same batch, reducing the number of small requests and improving network utilization, batching efficiency, and compression effectiveness. As a result, total throughput is usually better than pure round-robin.
Structured Summary
This article systematically breaks down Kafka producer partitioning and explains why partition selection determines load balancing, local ordering, and throughput. It also examines key-based assignment, round-robin, sticky partitioning, custom strategies, and the two critical tuning parameters: batch.size and linger.ms.