This article focuses on LangChain retrievers and RAG system design. It explains how a Retriever provides a unified interface to vector databases, how Redis enables semantic retrieval, and how chain composition builds knowledge-grounded question answering. It addresses three major pain points: LLM hallucinations, outdated knowledge, and inaccessible private data. Keywords: LangChain, RAG, Retriever.
Technical Specification Snapshot
| Parameter | Description |
|---|---|
| Language | Python |
| License | CC 4.0 BY-SA (as stated in the source) |
| Stars | Not provided in the original content |
| Core Dependencies | langchain, langchain_redis, langchain_google_genai, langchain_deepseek |
| Vector Store | Redis Vector Store |
| Retrieval Modes | similarity, mmr |
 AI Visual Insight: This animation summarizes where the retrieval system fits inside an AI application. It highlights the relationships among the user query, retrieval module, document collection, and generation model, helping developers build a solid mental model of the overall RAG architecture.
AI Visual Insight: This animation summarizes where the retrieval system fits inside an AI application. It highlights the relationships among the user query, retrieval module, document collection, and generation model, helping developers build a solid mental model of the overall RAG architecture.
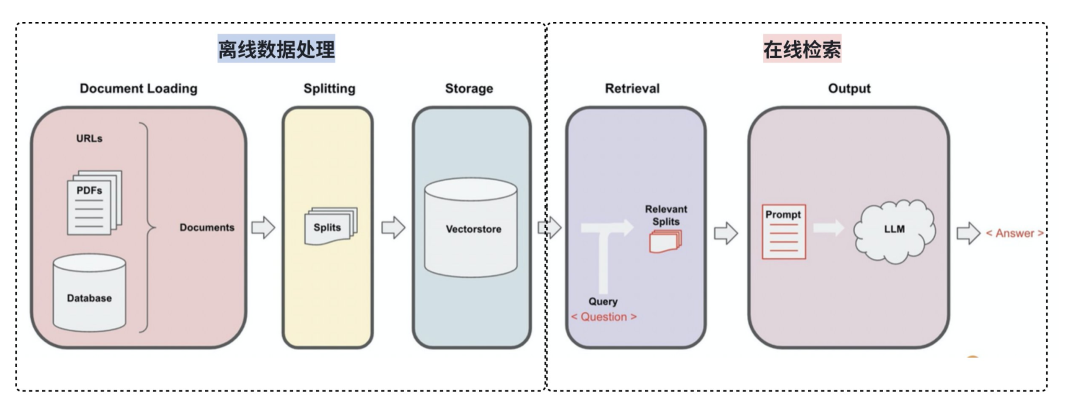
Retrieval systems are core infrastructure for RAG, not optional add-ons.
The goal of a retrieval system is to find the most relevant content from large-scale data, rank it by relevance, and return the results. It is not just a search box. It is the entry layer that connects the knowledge base to the generation model.
In engineering practice, retrieval systems usually fall into three categories: relational databases, lexical search engines, and vector databases. These are not mutually exclusive. Each one solves a different problem: exact matching, keyword recall, and semantic recall.
The boundaries between the three retrieval system types are clear.
- Relational databases: best for structured field filtering and exact queries.
- Lexical search: best for scenarios with explicit keywords and fixed terminology.
- Vector databases: best for semantic similarity, synonymous expressions, and open-domain question answering.
# Abstract selection across three retrieval approaches
search_mode = "vector" # Prioritize semantic retrieval
if search_mode == "sql":
result = "Exact field matching" # Best for structured filtering
elif search_mode == "keyword":
result = "Inverted index retrieval" # Best for keyword matches
else:
result = "Vector similarity retrieval" # Best for semantic recall in RAG
print(result)This code snippet illustrates the division of responsibilities across different retrieval paradigms.
LangChain retrievers hide backend storage differences behind a unified interface.
A Retriever takes a query string as input and returns a standardized list of Document objects. This contract is critical because it allows upper-layer chains to ignore whether the backend is Redis, Chroma, or Pinecone.
 AI Visual Insight: This diagram shows the one-way flow in which a query enters the retriever and candidate documents are returned. It emphasizes the retriever’s responsibility boundary: it only recalls relevant documents and does not generate answers directly.
AI Visual Insight: This diagram shows the one-way flow in which a query enters the retriever and candidate documents are returned. It emphasizes the retriever’s responsibility boundary: it only recalls relevant documents and does not generate answers directly.
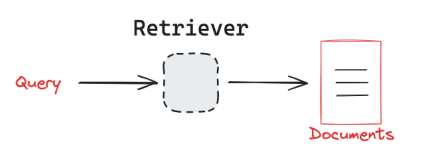 AI Visual Insight: This image compresses a complex retrieval process into a minimal model of “input Query, output Documents.” It highlights the abstraction value of LangChain’s unified interface and helps explain LCEL composition.
AI Visual Insight: This image compresses a complex retrieval process into a minimal model of “input Query, output Documents.” It highlights the abstraction value of LangChain’s unified interface and helps explain LCEL composition.
 AI Visual Insight: This image emphasizes how a vector store receives a natural language query, performs similarity matching, and returns document chunks. It shows why semantic retrieval is a better fit than traditional SQL retrieval for unstructured knowledge bases.
AI Visual Insight: This image emphasizes how a vector store receives a natural language query, performs similarity matching, and returns document chunks. It shows why semantic retrieval is a better fit than traditional SQL retrieval for unstructured knowledge bases.
A Redis vector store can quickly become a callable retriever.
from langchain_redis import RedisConfig, RedisVectorStore
from langchain_google_genai import GoogleGenerativeAIEmbeddings
# Initialize the embedding model
embeddings = GoogleGenerativeAIEmbeddings(model="gemini-embedding-001")
# Configure the Redis vector index
config = RedisConfig(
index_name="qa",
redis_url="redis://localhost:6378",
)
# Build the vector store and retriever
vector_store = RedisVectorStore(embeddings, config=config)
retriever = vector_store.as_retriever(search_kwargs={"k": 4}) # Return the top 4 resultsThis code snippet shows how to wrap a Redis vector store directly as a LangChain retriever.
Custom Runnables can also simulate retriever behavior.
If you need more flexible filtering, reranking, or debugging logic, you can define a custom Runnable with @chain. Strictly speaking, it may not be a standard Retriever class, but in chain composition it already has the same input-output shape.
from typing import List
from langchain_core.documents import Document
from langchain_core.runnables import chain
@chain
def custom_retriever(query: str) -> List[Document]:
return vector_store.similarity_search(
query=query,
k=4, # Recall the 4 most relevant chunks
)This code snippet builds a custom Runnable that behaves like a retriever.
RAG works by retrieving first and generating under contextual constraints.
The value of RAG is that it replaces “model memory” with “external knowledge plus on-demand reasoning.” That significantly reduces hallucinations and gives the system an update path for knowledge without frequent fine-tuning.
A standard workflow usually has four steps: retrieve documents, assemble context, inject the prompt, and call the model to generate an answer. The key factor is not how strong the model is, but how accurate the context is.
RunnablePassthrough preserves the original question.
RunnablePassthrough does not transform data. It simply passes the input through unchanged. In RAG, this role is important because the question must go to the retriever and also remain available for the prompt template.
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
def docs_to_str(docs):
return "\n".join([doc.page_content for doc in docs]) # Concatenate retrieved results
chain = {
"context": retriever | RunnableLambda(docs_to_str), # Convert documents into context
"question": RunnablePassthrough(), # Pass the original question through directly
}This code snippet generates the context and question prompt fields in parallel.
A complete RAG chain covers loading, splitting, indexing, retrieval, and generation.
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_deepseek import ChatDeepSeek
prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
Answer the question based on the following documents:
{context}
Question: {question}
If the answer cannot be found in the documents, say so explicitly.
""",
)
llm = ChatDeepSeek(model="deepseek-chat")
rag_chain = chain | prompt | llm | StrOutputParser() # Build the full QA chainThis code snippet connects retrieval results, the prompt, and model reasoning into a complete RAG invocation chain.
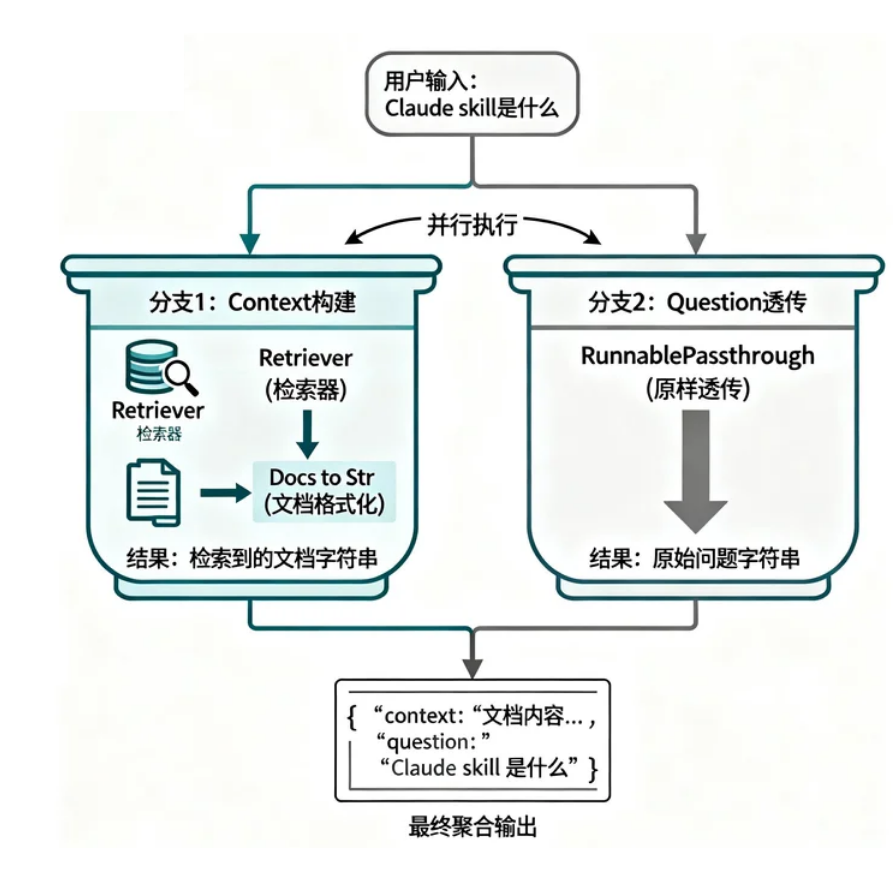 AI Visual Insight: This diagram shows the parallel branches of a dictionary-based chain: one side builds
AI Visual Insight: This diagram shows the parallel branches of a dictionary-based chain: one side builds context, while the other preserves question. They are then merged and sent into the prompt, accurately reflecting LCEL’s concurrent orchestration model.
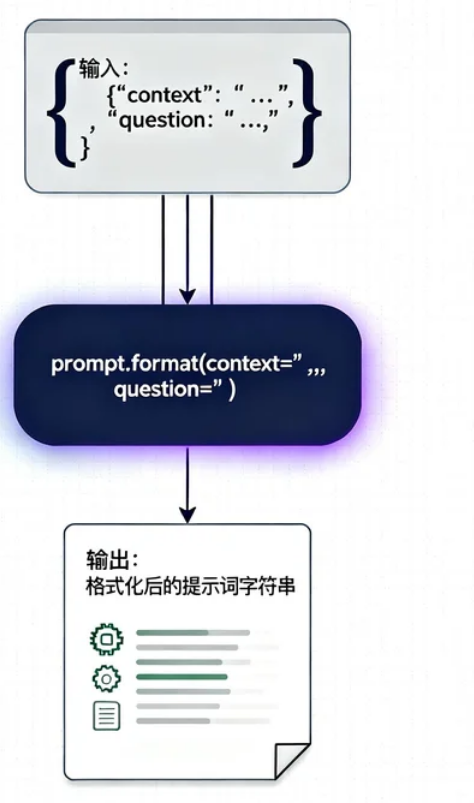 AI Visual Insight: This image highlights the central role of
AI Visual Insight: This image highlights the central role of PromptTemplate in RAG. It organizes retrieved context and the original question into a structured prompt the model can consume.
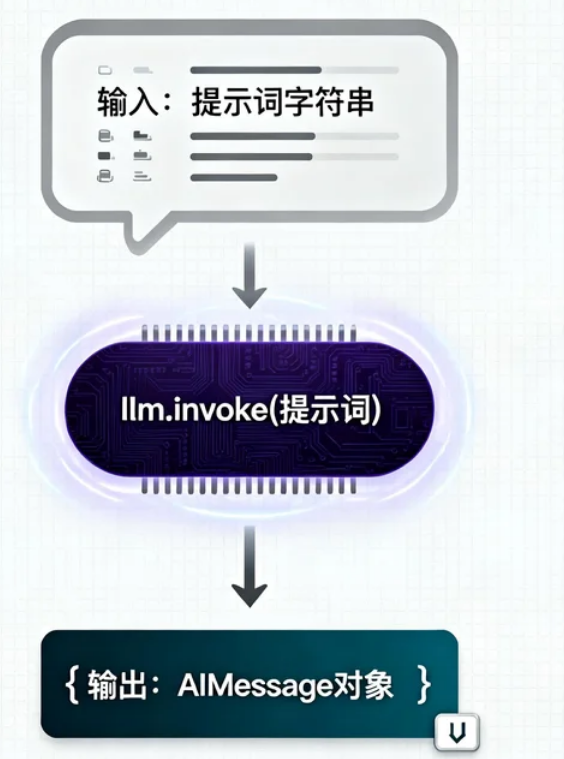 AI Visual Insight: This figure focuses on the generation phase. Once retrieval and prompt construction are complete, the LLM only performs constrained generation based on the provided context rather than answering purely from memory.
AI Visual Insight: This figure focuses on the generation phase. Once retrieval and prompt construction are complete, the LLM only performs constrained generation based on the provided context rather than answering purely from memory.
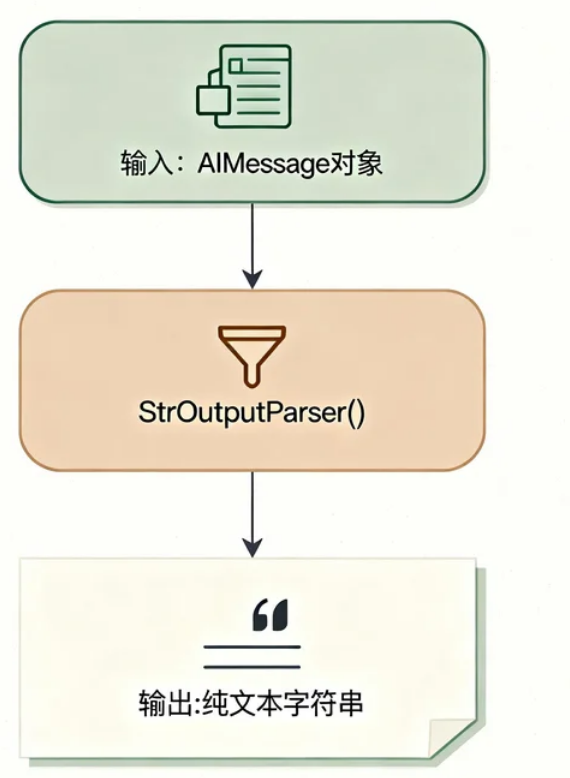 AI Visual Insight: This image shows that the output parser sits at the tail of the chain and normalizes the model response into a string or structured object, making it easier for the service layer to consume directly.
AI Visual Insight: This image shows that the output parser sits at the tail of the chain and normalizes the model response into a string or structured object, making it easier for the service layer to consume directly.
Retrieval quality sets the upper bound for RAG.
There are three main optimization points: document chunking, recall count, and prompt constraints. If chunk_size is too large, semantic focus becomes diluted. If it is too small, contextual continuity breaks. If k is too large, noise increases. If the prompt is too loose, the model has more room to hallucinate.
retriever = vector_store.as_retriever(
search_type="mmr", # Use Maximal Marginal Relevance to reduce duplicate content
search_kwargs={"fetch_k": 10, "k": 4}
)This code snippet uses MMR to improve result diversity and reduce repeated chunks.
Metadata filtering can significantly improve hit rates in enterprise knowledge bases.
from redisvl.query.filter import Tag, Num
# Combine tag and numeric filters
filter_func = (Tag("category") == "qa") & (Num("num") <= 10)
docs = vector_store.similarity_search(
query="What is Claude skill",
k=4,
filter=filter_func, # Search only within the specified document scope
)This code snippet adds business tags and numeric conditions to the semantic retrieval process.
FAQ
Q: Why is RAG more reliable than pure LLM-based question answering?
A: Because the answer is grounded in externally retrieved context rather than relying entirely on model parameter memory. This reduces hallucinations and supports both private knowledge and up-to-date knowledge access.
Q: Why is RunnablePassthrough indispensable in a RAG chain?
A: Because the question must trigger retrieval and also be passed unchanged into the prompt. Without it, you usually need to write an extra data-wrapping layer, which makes the chain more verbose.
Q: Is Redis suitable as a production-grade vector store for RAG?
A: Yes, for small to medium-scale, low-latency scenarios, especially when your stack already uses Redis. If you need a richer ecosystem or more advanced retrieval features, evaluate options such as Chroma, Pinecone, or Milvus.
Core Summary
This article reconstructs the core concepts behind LangChain retrievers and RAG systems, covering retrieval system types, the Retriever unified interface, Redis vector store integration, the role of RunnablePassthrough, chain execution flow, and optimization guidance. It helps developers quickly build interpretable and scalable knowledge-grounded question answering systems.