llm-ime is an experimental Chinese IME project that uses a local large language model to rank input method candidates. Its core capability is reranking Pinyin candidates based on context, addressing the key limitation of traditional frequency-based IMEs: they do not truly understand the current writing context. Keywords: local LLM, Chinese IME, GGUF.
The technical specification snapshot outlines the project clearly
| Parameter | Details |
|---|---|
| Project Name | llm-ime |
| Core Languages | TypeScript, JavaScript |
| Runtime | Node.js |
| Frontend and Backend Frameworks | Hono, React |
| Model Format | GGUF |
| Inference Dependency | node-llama-cpp |
| Repository Structure | pnpm monorepo |
| Example Model | Qwen3-0.6B-IQ4_XS |
| Model Size | About 350 MB |
| Protocol | HTTP API + Hono RPC |
| Privacy Strategy | Local inference, no online upload |
| GitHub | https://github.com/Deali-Axy/llm-ime |
This project redefines candidate ranking logic
Traditional Pinyin IMEs are good at hitting high-frequency words, but they mainly depend on global word frequency and static language models. The problem is that whether the user is writing code, drafting documentation, or chatting, the candidate ranking may still fail to understand the current context.
llm-ime takes a straightforward approach: Pinyin constrains the candidate set, while the large language model understands context and ranks the results. That means the IME no longer answers only “what word do people usually type,” but instead tries to answer “what word are you most likely trying to type right now.”
This approach works for a clear reason
One of the core capabilities of a large language model is predicting the probability of the next token based on previous context. Applied to an IME, that capability effectively transforms “free-form generation” into “candidate reranking constrained by Pinyin.”
User context + current Pinyin -> enumerate matching candidates -> LLM scores candidates -> return ranked resultsThe key value of this flow is that it injects language understanding directly into the IME’s most critical interaction loop.
The project uses a lightweight local model to balance speed and quality
The author chose the quantized Qwen3-0.6B-IQ4_XS model, which is about 350 MB in size. The goal is not to use the strongest possible model, but to reach an engineering balance that makes sense for an IME: small enough, fast enough, and still capable of basic Chinese contextual understanding.
For an input method, latency matters more than absolute accuracy. If users need to wait several seconds for candidate updates, even a smarter model becomes unusable in daily typing. That makes a 0.6B-class quantized model a much more realistic starting point for experimentation.
Local execution provides a privacy advantage
The model runs entirely on the local machine. It does not depend on a cloud API, and it does not upload user input. That matters especially for IMEs, because input methods naturally touch the most sensitive text users type.
git clone https://github.com/Deali-Axy/llm-ime.git
cd llm-ime
pnpm installThese commands clone the project source and install dependencies.
The system architecture is designed around low-latency input
The project uses a pnpm monorepo structure and is split into three layers: apps/server handles LLM inference and the HTTP API, apps/web provides a browser-based validation interface, and packages/ui contains shared components.
The server is built on Hono, while model loading and inference rely on node-llama-cpp. The frontend uses React, combined with TanStack Router, Tailwind CSS, and shadcn/ui to build the interactive interface.
The architecture can be summarized as a three-stage pipeline
Web input interface
-> Hono API / RPC
-> node-llama-cpp loads the GGUF model
-> return context-reranked candidatesThis pipeline emphasizes end-to-end control and debuggability rather than complex middleware.
The project uses multiple mechanisms to control inference stalls
The worst-case scenario for an IME is keystroke blocking. If every keypress waits synchronously for inference to finish, the experience breaks immediately. One of llm-ime’s main implementation priorities is separating “input display” from “candidate refresh” into different priority levels.
The author highlights several key strategies: synchronous input box updates, debounced request triggering, useTransition to lower the rendering priority of candidate updates, backend versioning to discard outdated tasks, and AbortController on the frontend to cancel stale requests.
Here is an example strategy for canceling stale requests on the frontend
let controller: AbortController | null = null
export async function fetchCandidates(query: string) {
controller?.abort() // Cancel the previous stale request
controller = new AbortController()
const res = await fetch(`/api/candidates?q=${query}`, {
signal: controller.signal, // Bind the cancellation signal for this request
})
return res.json()
}This code prevents old request results from overwriting the candidate list for newer input.
Fuzzy Pinyin and type safety improve real-world usability
The project does not just validate LLM-based ranking. It also considers error tolerance in real typing. Built-in fuzzy Pinyin rules handle common mixed-input cases such as z/zh, c/ch, s/sh, an/ang, and en/eng.
Another highlight is the end-to-end type safety provided by Hono RPC. After routes are defined on the server, the frontend can infer request and response types directly through `hc
()`, reducing repeated declarations and API drift. ### Type sharing works like this “`typescript import { hc } from ‘hono/client’ import type { AppType } from ‘./server’ const client = hc (‘http://127.0.0.1:3000’) // Automatically infer API types “` This code shows how the frontend and backend can share API types and reduce integration overhead. ## The browser interface serves both validation and observability The project is still in the Web validation stage. The browser is not the final IME form factor, but rather an experimental workbench. The advantage is that it allows fast observation of candidate ranking quality, response speed, and engine state, while making it easier to iterate on scoring strategies. [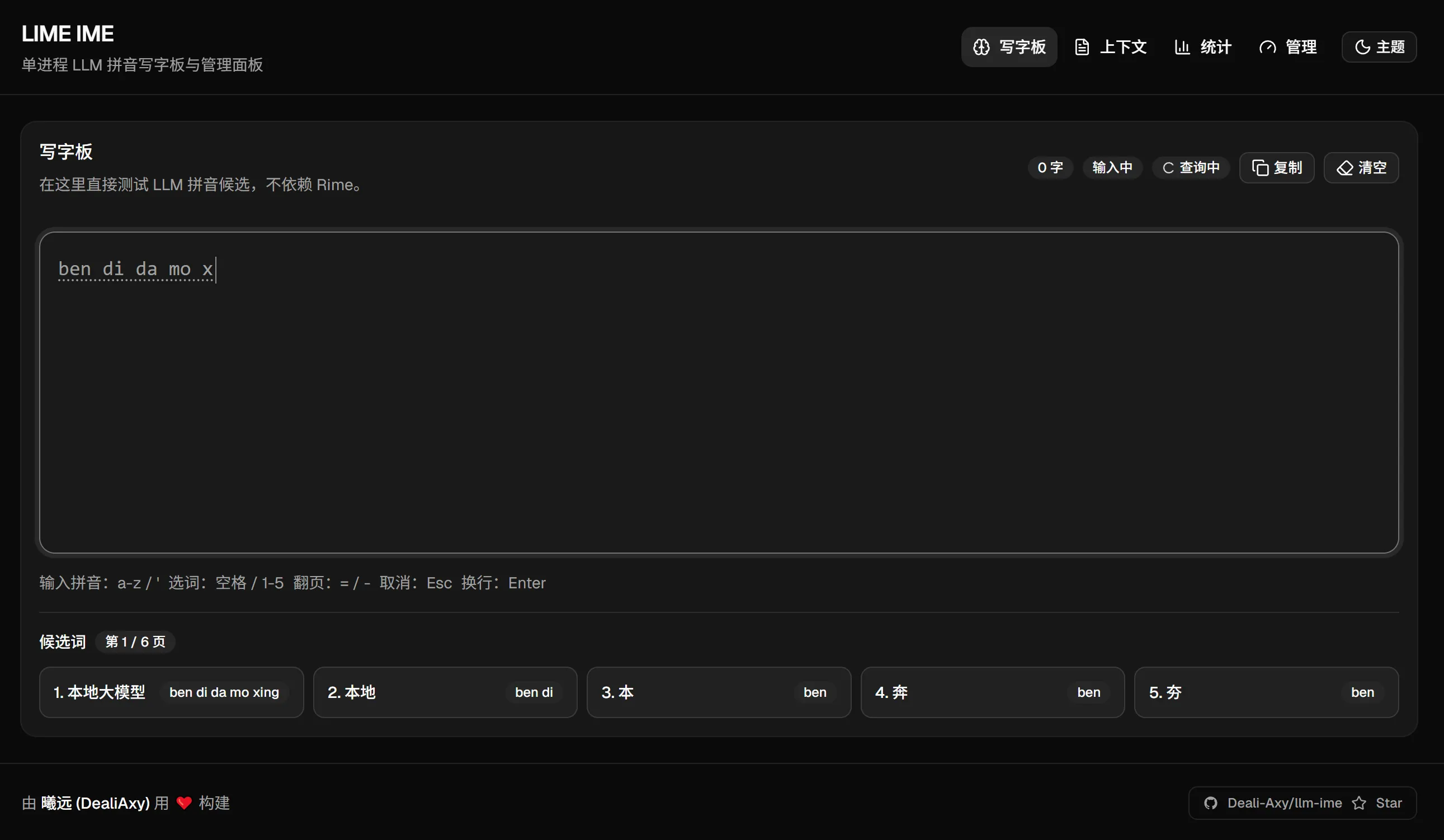](https://blog.deali.cn/media/blog/71c8760f71f34966/e8d9c988a9539d4b.webp) **AI Visual Insight:** This screenshot shows a Web console designed for IME experimentation. The left or center area contains text input and candidate regions, with an interface that emphasizes immediate feedback. Surrounding panels display statistics, engine status, or debugging data, indicating that the project is not only validating candidate ranking accuracy, but also observing inference latency, request update cadence, and interaction smoothness. ## The current results validate the direction, but productization still requires substantial work Experimental feedback suggests that candidate reranking already shows value for short phrases and local context. However, issues remain with long-sentence prediction, unexpected candidate surfacing, and the impact of quantization accuracy. These issues show that there is still a significant engineering gap between “it works” and “it is genuinely usable.” The next priorities are clear: continue optimizing candidate scoring strategies, explore quantized models that fit IME scenarios better, and consider integrating with real IME frameworks such as RIME, or building a native frontend directly. “`bash pnpm run model:download pnpm run server:dev pnpm run web:dev “` These commands download the target model, start the backend service, and launch the frontend validation interface. ## This experiment offers useful insight into AI-native tool design The value of llm-ime is not just that it built an IME demo. More importantly, it points to a product direction worth watching: applying LLMs to high-frequency, constrained, and instantly testable foundational tools. Input methods are a strong representative of that category. Compared with chatbots, IMEs have a much clearer objective function: whether the candidate is more accurate, whether it appears faster, and whether it better matches the context. That is exactly why IMEs are an ideal proving ground for the practical usefulness of small local models. ## FAQ ### 1. What is the biggest difference between llm-ime and a traditional IME? Traditional IMEs rely more heavily on word-frequency statistics and static language models. llm-ime introduces an LLM to understand the current context and dynamically rerank Pinyin candidates, so it focuses more on “the context right now” than on “globally common words.” ### 2. Why does the project choose a 0.6B model instead of a larger one? An IME is a strongly real-time scenario, so latency is extremely sensitive. A 0.6B quantized model is much more likely to achieve acceptable response speed on CPU, while keeping the model size to about 350 MB. That makes it a practical balance point for local experimentation and everyday deployment. ### 3. Can this project replace a daily-use IME right now? Not yet. It is currently closer to a Web-based validation platform for the concept. It has already shown that the direction is feasible, but there is still a clear gap before it becomes a mature product, especially in long-sentence stability, candidate accuracy, native system integration, and interaction details. ## AI Readability Summary llm-ime is an experimental Chinese input method project that uses a local large language model to rank candidates. Built with Node.js, Hono, React, and node-llama-cpp, it loads a local GGUF quantized model and reranks Pinyin candidates based on context without requiring an internet connection, validating the feasibility of LLMs in IME scenarios.