Modern AI applications do not rely on large models alone. They are built on five coordinated layers of capability: LLMs, Tokens, Context, Prompts, and Tools. This article focuses on their definitions, boundaries, and engineering relationships to solve a common problem: knowing each term individually, but not understanding how they connect. Keywords: LLM, Prompt, Tool.
The technical specification snapshot
| Parameter | Description |
|---|---|
| Content Language | Chinese technical analysis |
| Core Domain | Foundational understanding of large language models |
| Related Protocols/Paradigms | Transformer, RAG, Function Calling |
| Reference Popularity | The original article shows 119 views, 3 likes, and 3 bookmarks |
| Core Dependencies | Tokenizer, context window, prompt design, external tool interfaces |
The modern AI workflow is not a single-point capability
When many developers first learn AI, they tend to focus all their attention on model size. But a usable AI system actually depends on a complete workflow: model generation, text segmentation, context organization, instruction constraints, and external execution.
This workflow can be summarized as follows: the LLM handles generation, Tokens handle encoding, Context carries information, Prompts constrain tasks, and Tools connect the system to the real world. You only truly understand modern AI products when you understand these five layers together.
A minimal framework for moving from concepts to systems
LLM → Token → Context → Prompt → Tool
# Start with the generation core, then the input unit, context assembly, task guidance, and finally external capabilitiesThis chain shows how large-model applications evolve from simply “speaking” to actually “doing.”
An LLM fundamentally predicts the next Token continuously
An LLM is not a database, nor is it a rules engine. At its core, it is a probabilistic model that continuously predicts the most likely next Token based on the input it has already seen. During answer generation, this process repeats many times until it produces a complete output.
Most mainstream LLMs today are based on the Transformer architecture. Their key value is not that they “memorize answers,” but that they learn language patterns, semantic relationships, and expressive structures from massive training data. That is why they are good at summarization, question answering, rewriting, code generation, and reasoning-oriented expression.
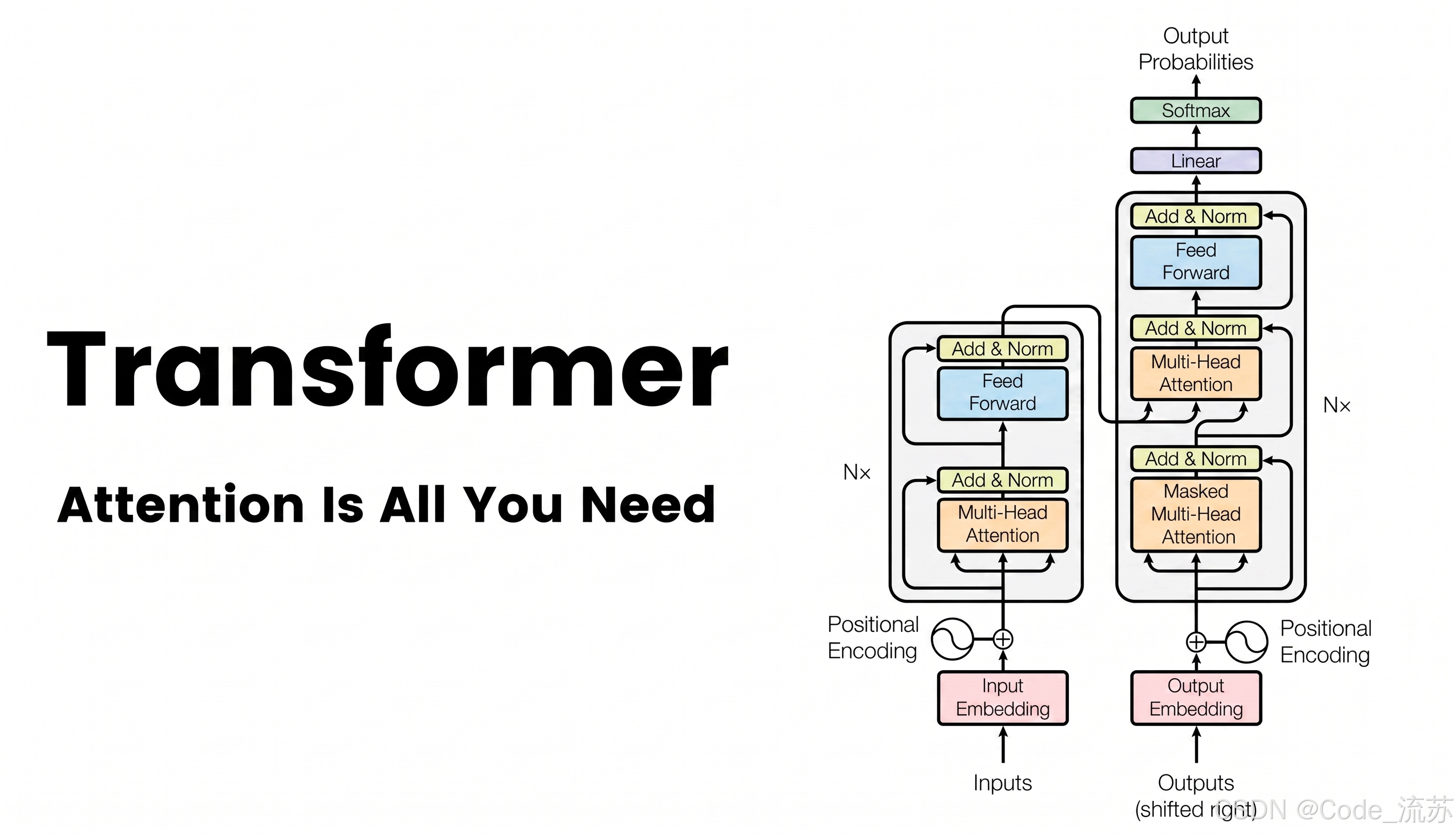 AI Visual Insight: This diagram shows the generation mechanism of a large language model from an input sequence to an output sequence. It should include Transformer encoding/decoding or attention paths, emphasizing that the model does not retrieve fixed answers but predicts subsequent Tokens step by step under contextual conditions.
AI Visual Insight: This diagram shows the generation mechanism of a large language model from an input sequence to an output sequence. It should include Transformer encoding/decoding or attention paths, emphasizing that the model does not retrieve fixed answers but predicts subsequent Tokens step by step under contextual conditions.
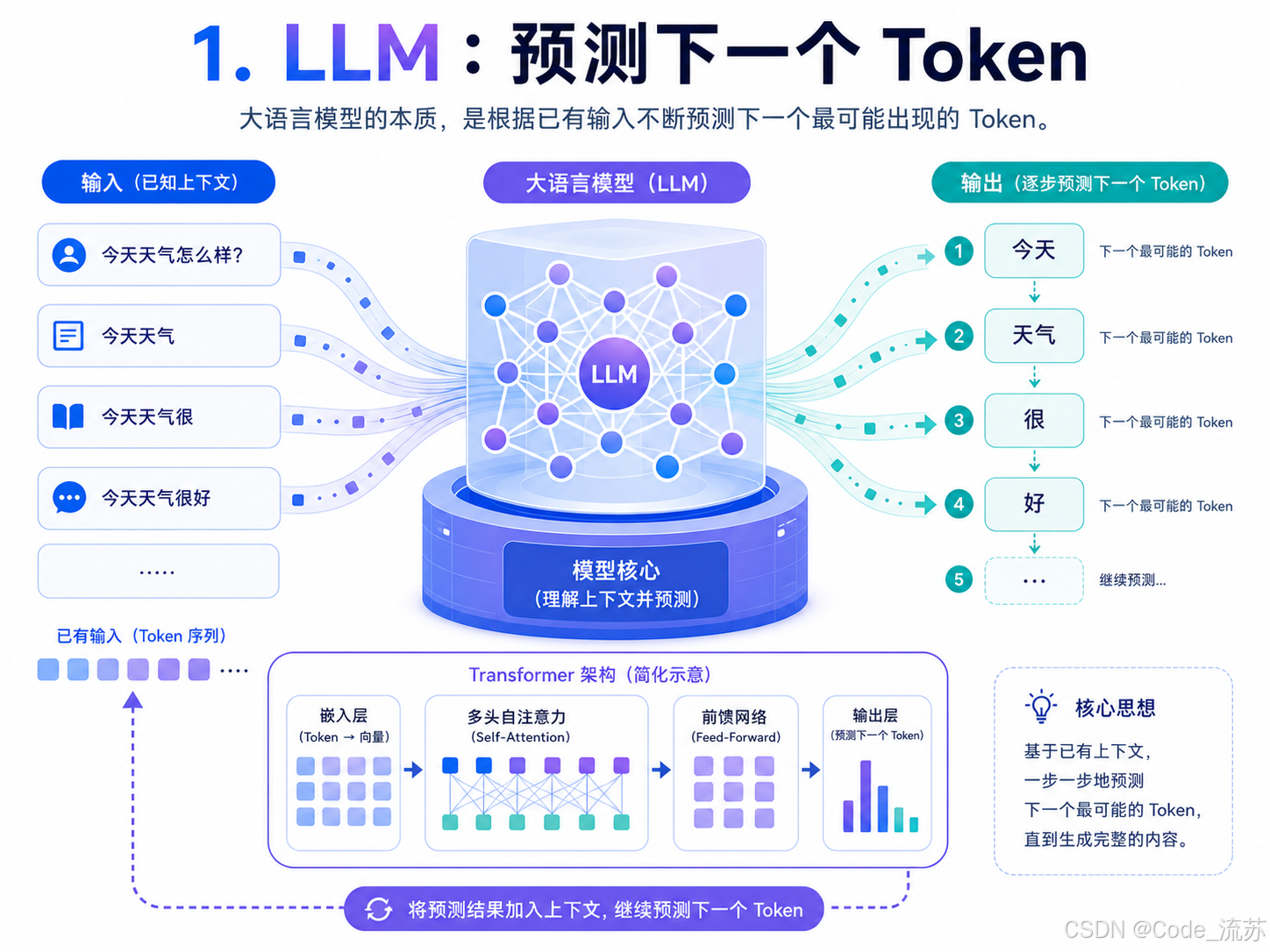 AI Visual Insight: This diagram visually illustrates the pipeline-style process of “predicting the next Token.” It typically shows the input text, candidate probability distribution, and final sampling result, helping explain that LLM output is based on probabilistic selection rather than deterministic memory retrieval.
AI Visual Insight: This diagram visually illustrates the pipeline-style process of “predicting the next Token.” It typically shows the input text, candidate probability distribution, and final sampling result, helping explain that LLM output is based on probabilistic selection rather than deterministic memory retrieval.
LLMs are strong at expression, but not inherently strong at fact verification
def next_token_prediction(context_tokens):
probs = model(context_tokens) # The model computes the probability distribution of the next Token from the context
token = sample(probs) # Select the next Token according to the sampling strategy
return tokenThis code abstracts the minimal working pattern of an LLM: input context, output the next Token.
A Token is the smallest unit the model actually processes
A model does not directly process “characters” or “words.” It processes Tokens. A tokenizer splits input text into smaller pieces and then maps them to numeric IDs for model computation. A single Chinese word may correspond to one or more Tokens, and an English word does not necessarily map to exactly one Token either.
The importance of Tokens shows up in three areas: cost, capacity, and quality. APIs are often billed by Token count; context windows are measured in Tokens; and when irrelevant content fills the available Token budget, output quality drops significantly.
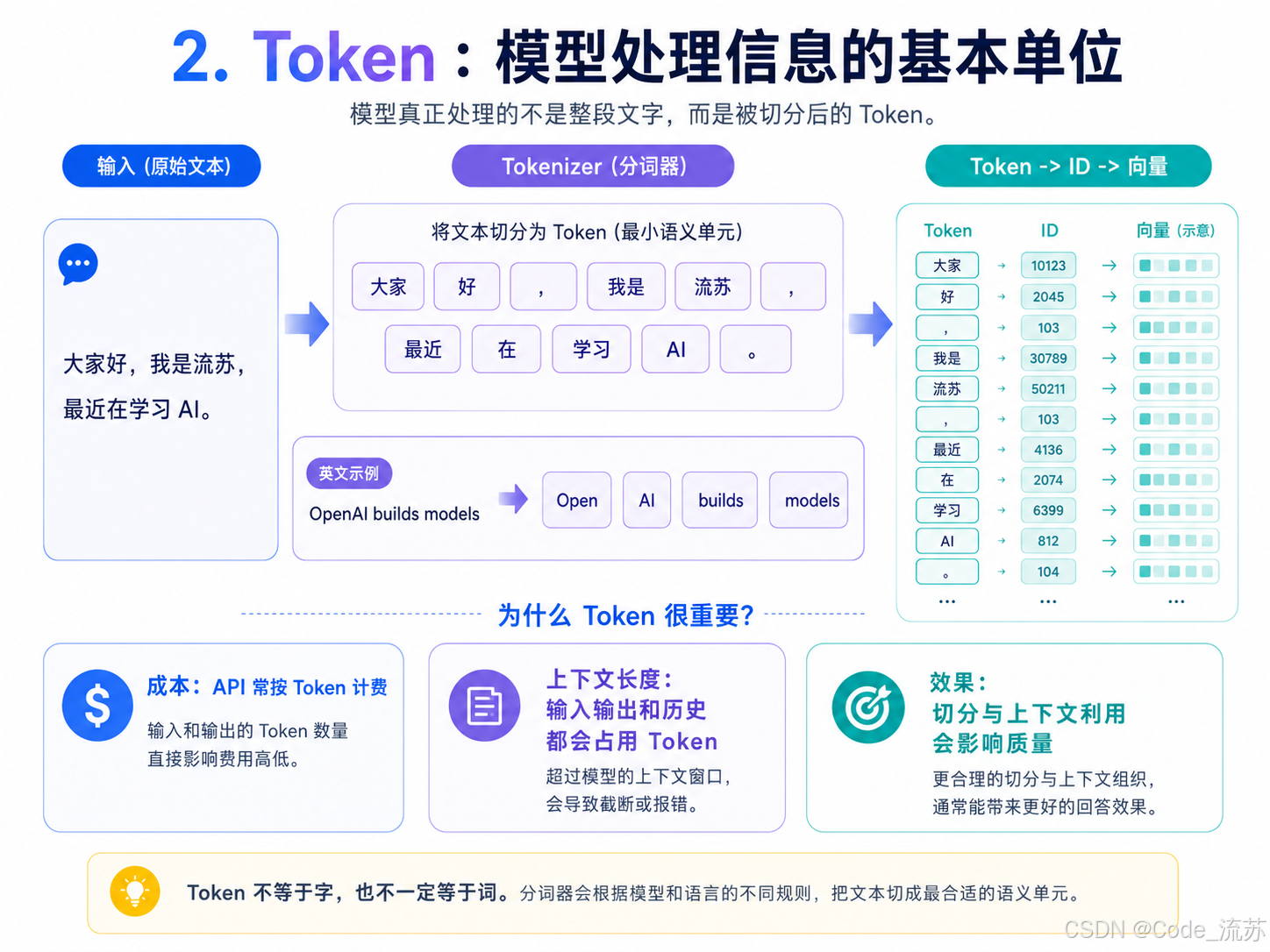 AI Visual Insight: This diagram should show how text is split into multiple Tokens and converted into numeric indices. It reflects the tokenizer’s bridging role between language input and model computation, and also shows that Tokens do not map one-to-one to natural-language characters or words.
AI Visual Insight: This diagram should show how text is split into multiple Tokens and converted into numeric indices. It reflects the tokenizer’s bridging role between language input and model computation, and also shows that Tokens do not map one-to-one to natural-language characters or words.
Tokens directly affect cost and context window utilization
text = "Please explain what a context window is"
tokens = tokenizer.encode(text) # Encode natural language into a Token sequence
print(len(tokens)) # Count the number of Tokens to estimate cost and capacityThis code is used to estimate how many Tokens a single request will consume.
Context determines what the model can currently see
Context can be understood as all information visible to the model during the current round of reasoning, including the system prompt, conversation history, the current question, retrieved results, tool descriptions, and tool return values. It is not long-term memory. It is a temporary workspace for a single interaction.
The Context Window is the capacity limit of that workspace. If the content exceeds the window, the model cannot see all information at the same time. In practice, engineers usually use summarization, truncation, chunked retrieval, or RAG to fit the most relevant information into a limited window.
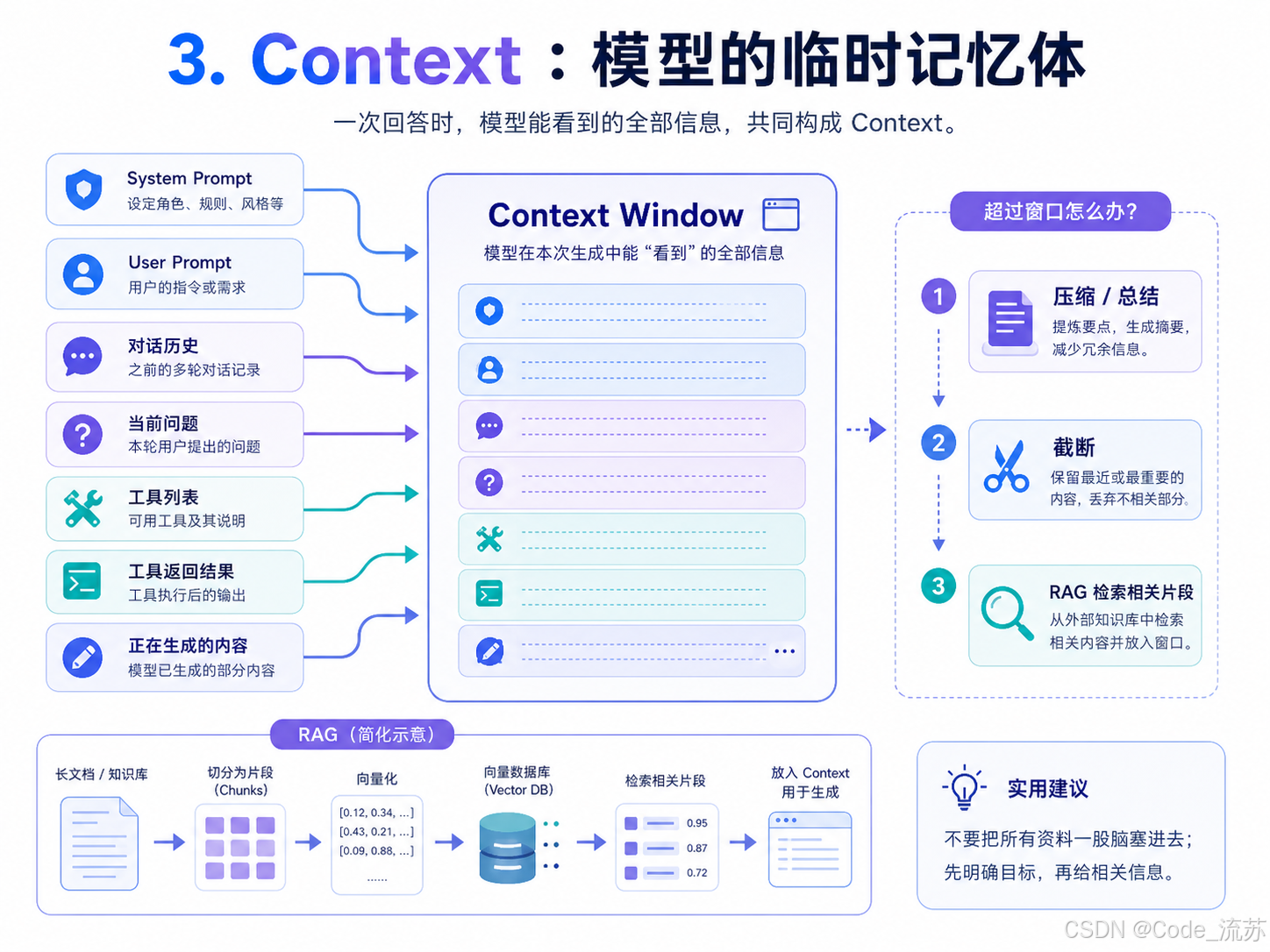 AI Visual Insight: This diagram should express the boundary concept of the context window. It may include system instructions, historical messages, user input, and external retrieval snippets arranged within a limited container, highlighting the core constraint that the total visible information is bounded.
AI Visual Insight: This diagram should express the boundary concept of the context window. It may include system instructions, historical messages, user input, and external retrieval snippets arranged within a limited container, highlighting the core constraint that the total visible information is bounded.
High-quality context matters more than piling up documents
context = {
"system": "You are a technical documentation assistant", # Define the role and rules
"history": recent_messages, # Keep the necessary recent conversation history
"user": user_query, # The current task input
"docs": retrieved_chunks[:3] # Inject only the most relevant retrieved snippets
}This code demonstrates the core principle of context construction: be concise and precise, not broad and noisy.
A Prompt explicitly orchestrates task boundaries
A Prompt is not a magic spell. It is a task specification. Its purpose is to reduce model uncertainty by making it clear who the model is, what it needs to do, what source material it should reference, what output format it should follow, and what constraints it must obey.
In engineering practice, Prompts commonly exist in two layers: the System Prompt defines role, rules, and boundaries, while the User Prompt defines the current task. Both jointly shape model behavior, and neither is optional.
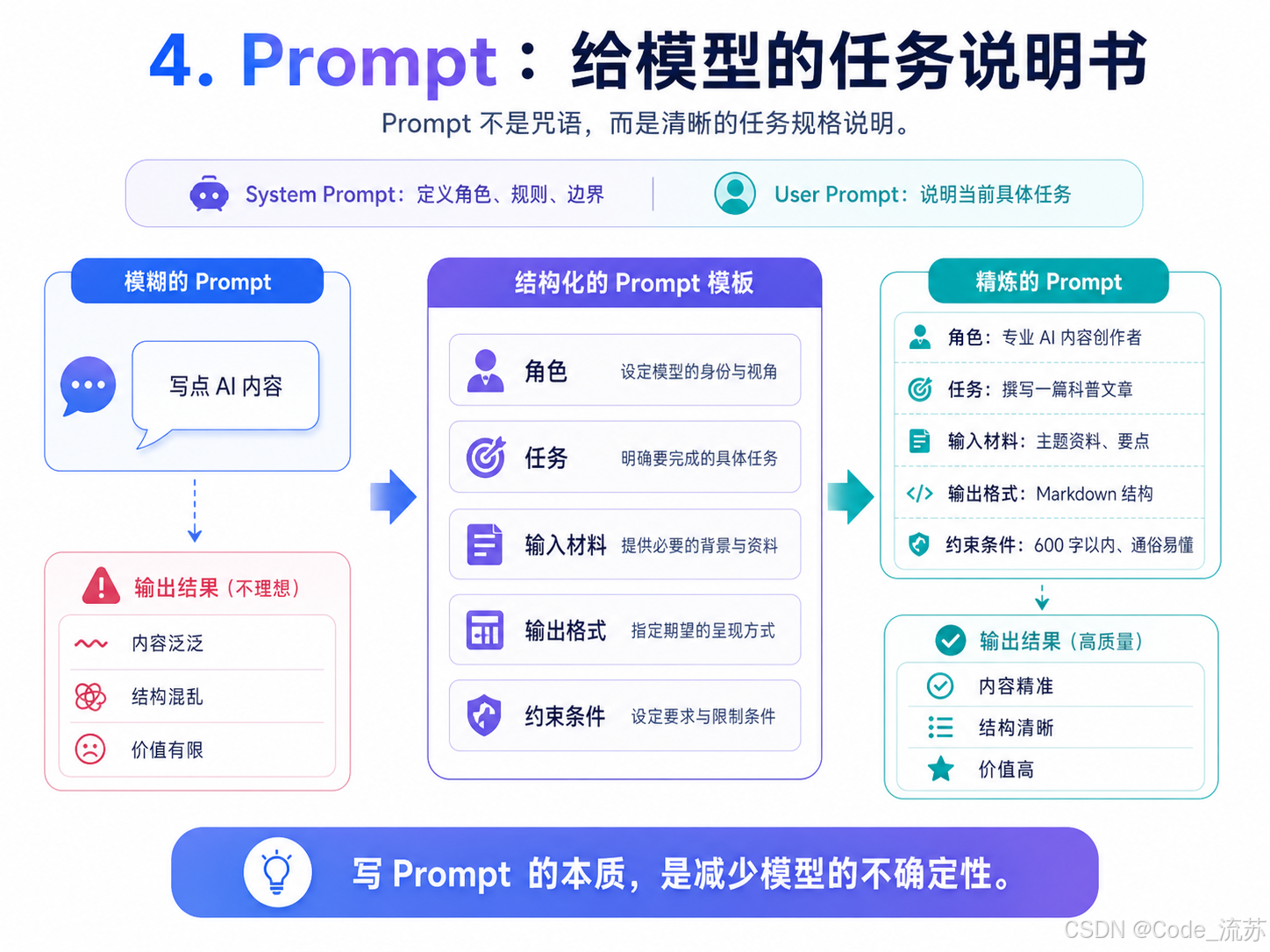 AI Visual Insight: This diagram should show a structured prompt template composed of role, task, input material, output format, and constraints. It reflects that the essence of prompt engineering is task decomposition and constraint injection, not single-sentence prompting tricks.
AI Visual Insight: This diagram should show a structured prompt template composed of role, task, input material, output format, and constraints. It reflects that the essence of prompt engineering is task decomposition and constraint injection, not single-sentence prompting tricks.
A strong Prompt structure usually contains five elements
Who you are: You are a senior AI architecture consultant
What the task is: Explain the relationship between LLMs and Tokens
Input material: Below is the concept list provided by the user
Output format: Please explain using a table and bullet points
Constraints: Avoid empty language and keep it within 300 words
# Role, task, material, format, and constraints work together to reduce response deviationThis template can serve directly as the basic skeleton for most knowledge Q&A and content-generation scenarios.
Tools turn a generation system into an execution system
An LLM cannot, by itself, check the weather, query a database, run code, or send email. The role of a Tool is to connect model output to external systems. The model decides when to call a tool, which tool to call, and what parameters to pass; the host platform performs the actual execution.
As a result, a Tool is fundamentally closer to a function-calling interface than to an intrinsic model capability. It upgrades AI from a system that can “describe actions” to one that can “trigger actions.” This is one of the most critical extension points at the application layer.
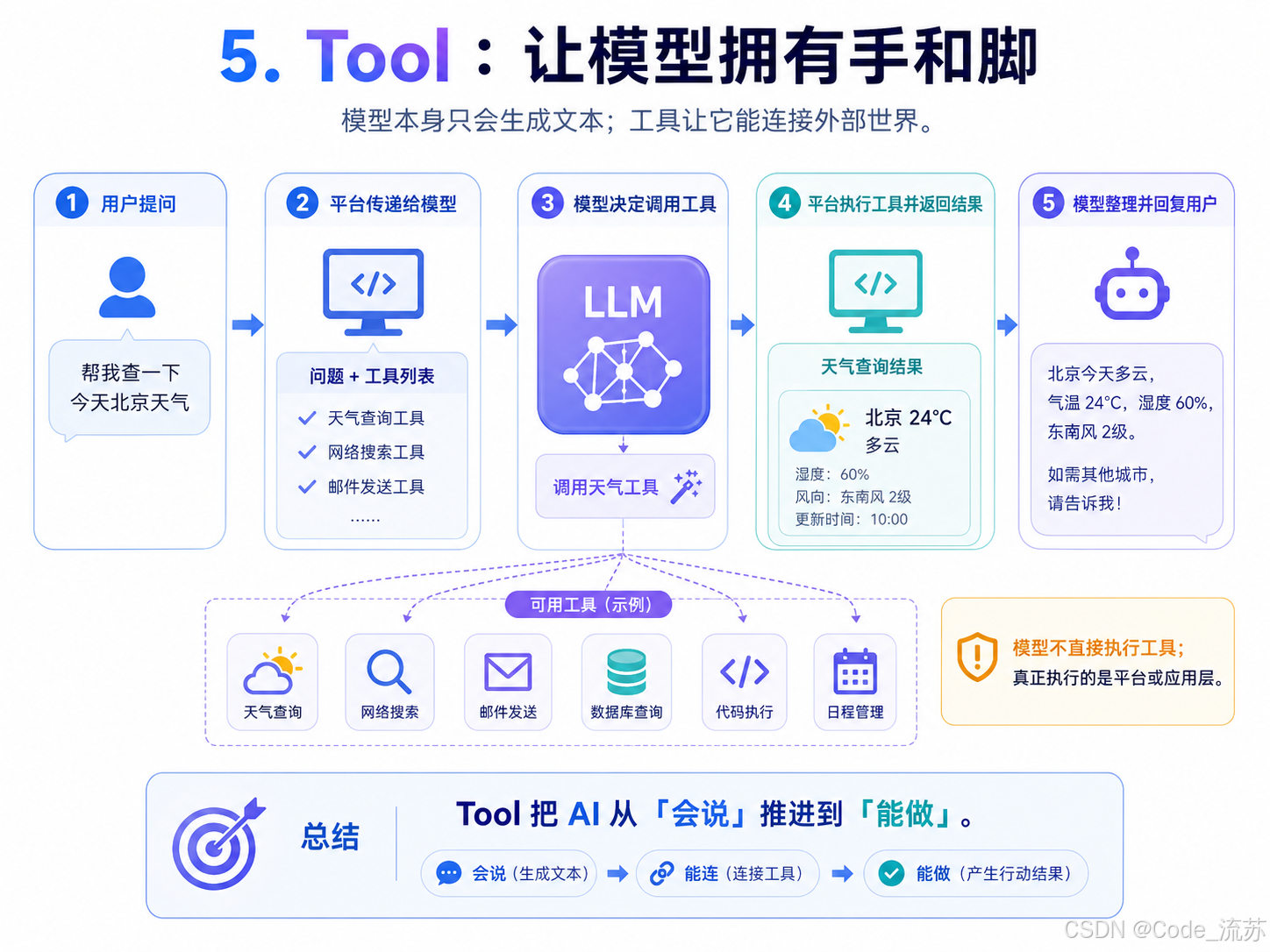 AI Visual Insight: This diagram should depict the closed loop of user request, model decision, tool execution, result return, and final response. It highlights the separation of responsibilities in tool calling: the model makes decisions, the platform performs execution, and the result is fed back into the model for natural-language output composition.
AI Visual Insight: This diagram should depict the closed loop of user request, model decision, tool execution, result return, and final response. It highlights the separation of responsibilities in tool calling: the model makes decisions, the platform performs execution, and the result is fed back into the model for natural-language output composition.
Tool calls are the foundational interface of modern Agents
{
"tool_name": "search_docs",
"arguments": {
"query": "what is a context window"
}
}This structure shows a typical tool call request: the model outputs intent, and the platform executes the tool based on structured parameters.
The five concepts together form the backbone of modern AI products
Viewed individually, none of these concepts is especially difficult. The challenge lies in how they collaborate. The LLM determines the upper bound of generation, Tokens define computational granularity, Context defines visible scope, Prompts define task direction, and Tools define action capability.
When an AI product performs well, the reason is often not that the model name is bigger, but that context management is more precise, prompting is more stable, and tool integration is more complete. In the end, engineering quality becomes visible to users.
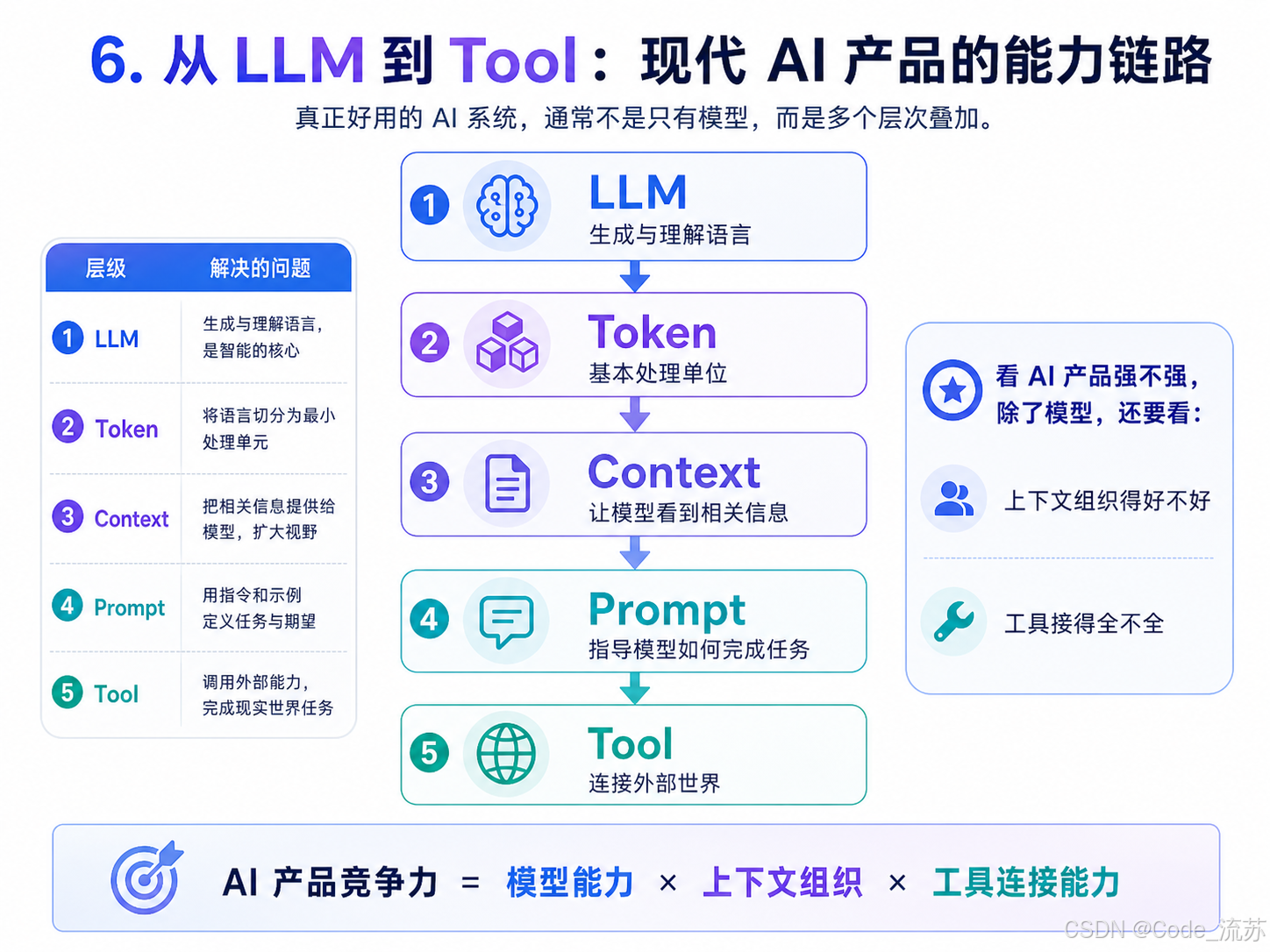 AI Visual Insight: This diagram should connect LLM, Token, Context, Prompt, and Tool in sequence through a flowchart, emphasizing that these concepts are not parallel buzzwords but a layer-by-layer capability chain. It is a foundational map for understanding Agents, MCP, and RAG.
AI Visual Insight: This diagram should connect LLM, Token, Context, Prompt, and Tool in sequence through a flowchart, emphasizing that these concepts are not parallel buzzwords but a layer-by-layer capability chain. It is a foundational map for understanding Agents, MCP, and RAG.
The FAQ is structured for practical understanding
Q1: Why can a strong model still produce wrong answers?
A: Because an LLM is fundamentally a probabilistic generation system and does not include built-in fact verification. If the Context is incomplete, the Prompt is unclear, or Tool/RAG-based verification is missing, the model may generate content that sounds plausible but is not true.
Q2: What is the essential difference between Prompt and Context?
A: A Prompt is the task instruction intentionally written for the model, emphasizing rules and goals. Context is all information the model can currently see. It includes the Prompt, but also conversation history, retrieval results, and tool outputs.
Q3: Is a Tool the same thing as an Agent?
A: No. A Tool is an external capability interface responsible for execution. An Agent is a higher-level intelligent system pattern that usually also includes planning, memory, state management, and multi-step decision-making. A Tool is only one foundational component of an Agent.
The core takeaway is an engineering view of modern AI fundamentals
This article reconstructs the five foundational concepts of modern AI from an engineering perspective: LLM, Token, Context, Prompt, and Tool. It explains what each one does, how they depend on one another, and the key design considerations in real AI applications, helping developers quickly build a system-level understanding.