This article focuses on integrating OpenClaw, kookeey dynamic residential proxies, and Lark to build an Amazon product data scraping and AI-powered automation pipeline that addresses three major pain points: geo-restrictions, IP blocking, and inefficient human collaboration. Keywords: OpenClaw, dynamic proxies, Lark workflow.
Technical Specifications Snapshot
| Parameter | Description |
|---|---|
| Core Languages | Python, JavaScript (CLI installation) |
| Task Orchestration | OpenClaw Agent / Skill |
| Proxy Protocol | HTTP/HTTPS dynamic residential proxies |
| Collaboration Channel | Lark Chatbot / Webhook |
| Target Platform | Amazon multi-market search and product pages |
| Core Dependencies | requests, BeautifulSoup, pandas, OpenClaw CLI |
| GitHub Stars | Not provided in the source material; use live repository data instead |
This architecture solves broken cross-border e-commerce data pipelines
Amazon product research depends on price, rating, review volume, ranking, and keyword popularity. In practice, data collection is often blocked by three factors: inconsistent regional perspectives, fixed IPs that easily trigger anti-bot systems, and raw data that cannot be quickly converted into operational insights.
This solution uses OpenClaw as the orchestration hub, kookeey as the proxy egress layer, Python as the scraping execution layer, and Lark as the collaboration entry point. Together, they form an automation loop where sending a message can trigger the entire workflow.
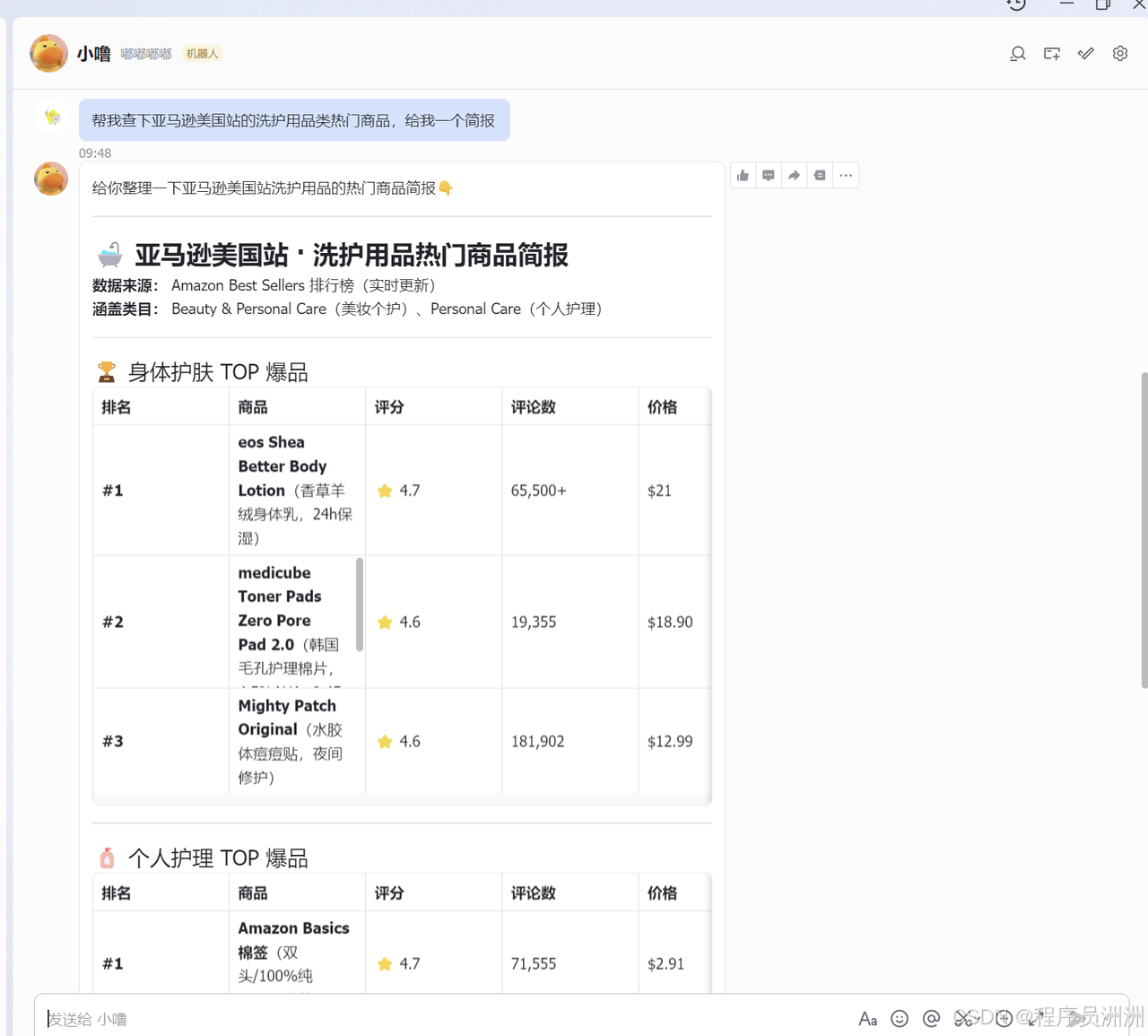 AI Visual Insight: This image shows the full pipeline from natural language instructions and proxy scheduling to crawler execution and result delivery. It highlights OpenClaw as the orchestration hub that connects Amazon scraping, data analysis, and Lark notifications into a unified workflow.
AI Visual Insight: This image shows the full pipeline from natural language instructions and proxy scheduling to crawler execution and result delivery. It highlights OpenClaw as the orchestration hub that connects Amazon scraping, data analysis, and Lark notifications into a unified workflow.
OpenClaw turns natural language into executable tasks
OpenClaw is not just a chat assistant. It is an Agent runtime with tool invocation, script execution, file read/write support, and plugin extensibility. It is well suited for packaging reusable Skills that encapsulate scraping, analysis, and notification logic.
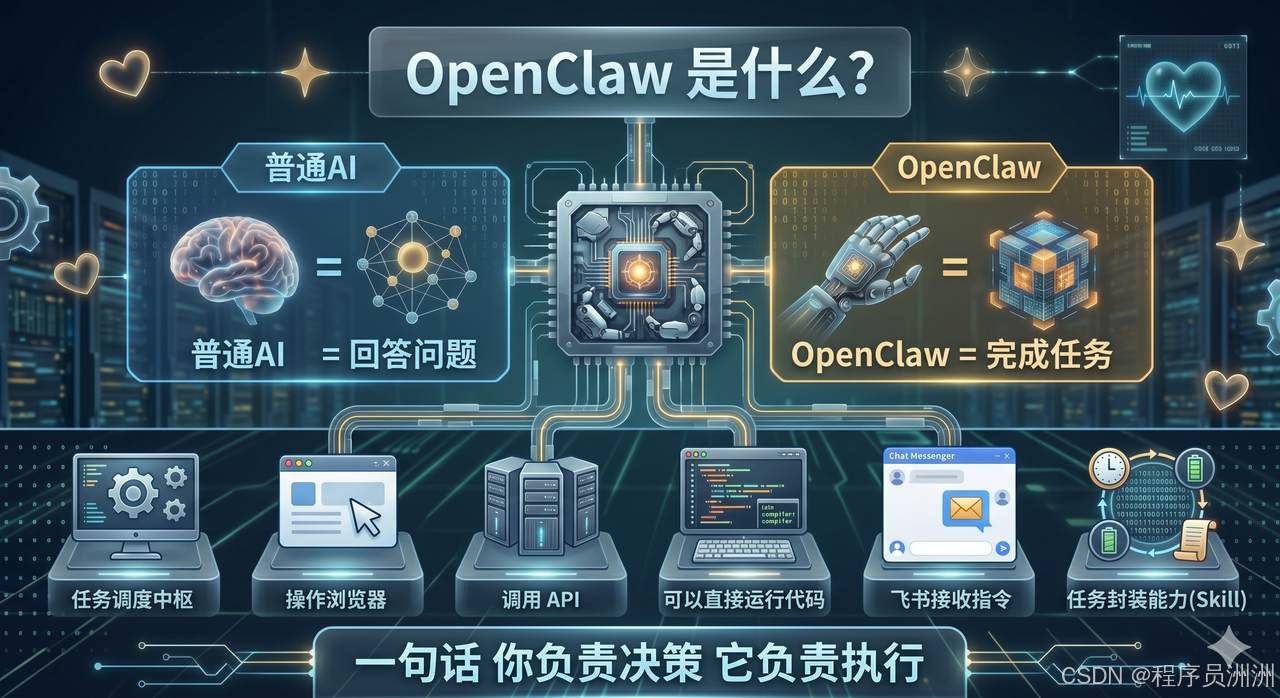 AI Visual Insight: This image shows the OpenClaw platform interface and tool entry points, emphasizing its role as an Agent runtime for execution rather than a simple text-based assistant.
AI Visual Insight: This image shows the OpenClaw platform interface and tool entry points, emphasizing its role as an Agent runtime for execution rather than a simple text-based assistant.
 AI Visual Insight: This image presents the SkillHub or skill composition interface, showing how developers can quickly extend web scraping, messaging integration, and task scheduling through modular skill installation and composition.
AI Visual Insight: This image presents the SkillHub or skill composition interface, showing how developers can quickly extend web scraping, messaging integration, and task scheduling through modular skill installation and composition.
npm install -g openclaw
# Install the OpenClaw CLI globally for local skill development and task executionThis command installs the OpenClaw CLI and provides the foundation for subsequent Skill packaging and local debugging.
Dynamic residential proxies are the key prerequisite for stable Amazon scraping
Amazon evaluates visitors based on request frequency, user-agent fingerprints, cookie continuity, and IP geolocation. Datacenter IPs are generally easier to detect, while residential proxies more closely resemble real-user network environments.
kookeey provides rotating dynamic residential proxies across multiple countries and regions, allowing scraping scripts to access localized Amazon pages such as Amazon US, Germany, and Japan from realistic geographic viewpoints.
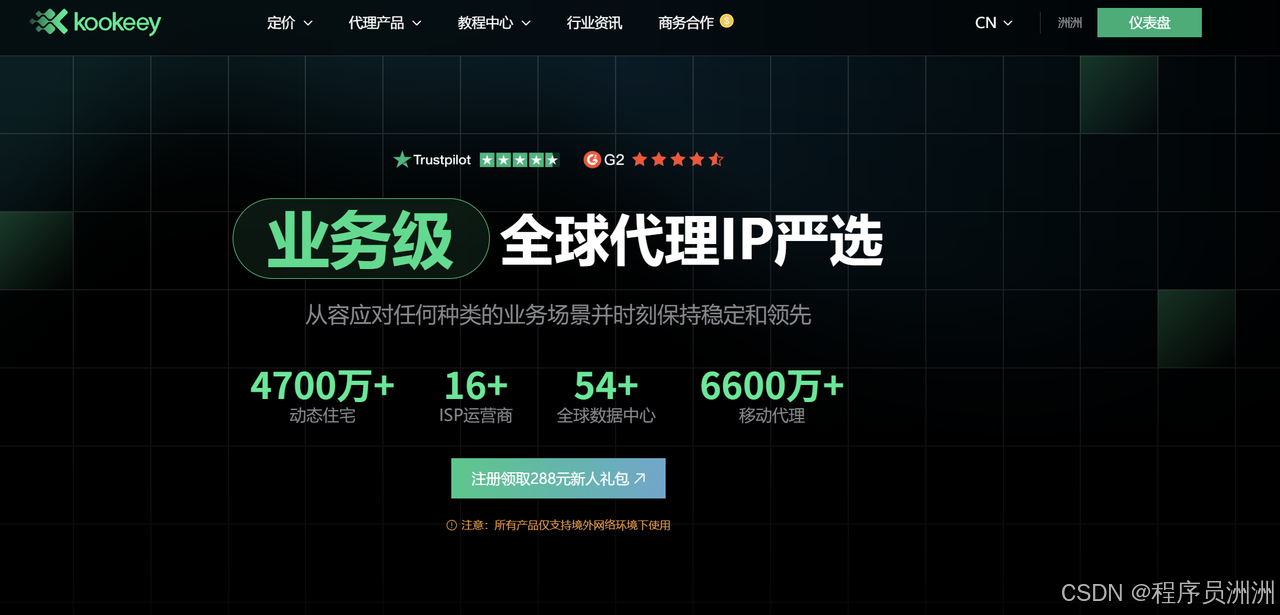 AI Visual Insight: This image shows the kookeey product portal and proxy offerings, highlighting dynamic residential proxies, static residential proxies, and other network resources suitable for automated scraping infrastructure.
AI Visual Insight: This image shows the kookeey product portal and proxy offerings, highlighting dynamic residential proxies, static residential proxies, and other network resources suitable for automated scraping infrastructure.
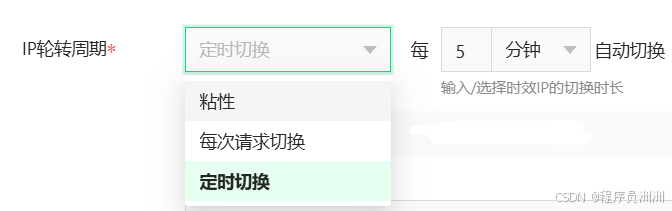 AI Visual Insight: This image highlights geographic selection and exit rotation for dynamic residential proxies, showing how the proxy pool can switch at the country or city level to simulate local-user behavior in the target market.
AI Visual Insight: This image highlights geographic selection and exit rotation for dynamic residential proxies, showing how the proxy pool can switch at the country or city level to simulate local-user behavior in the target market.
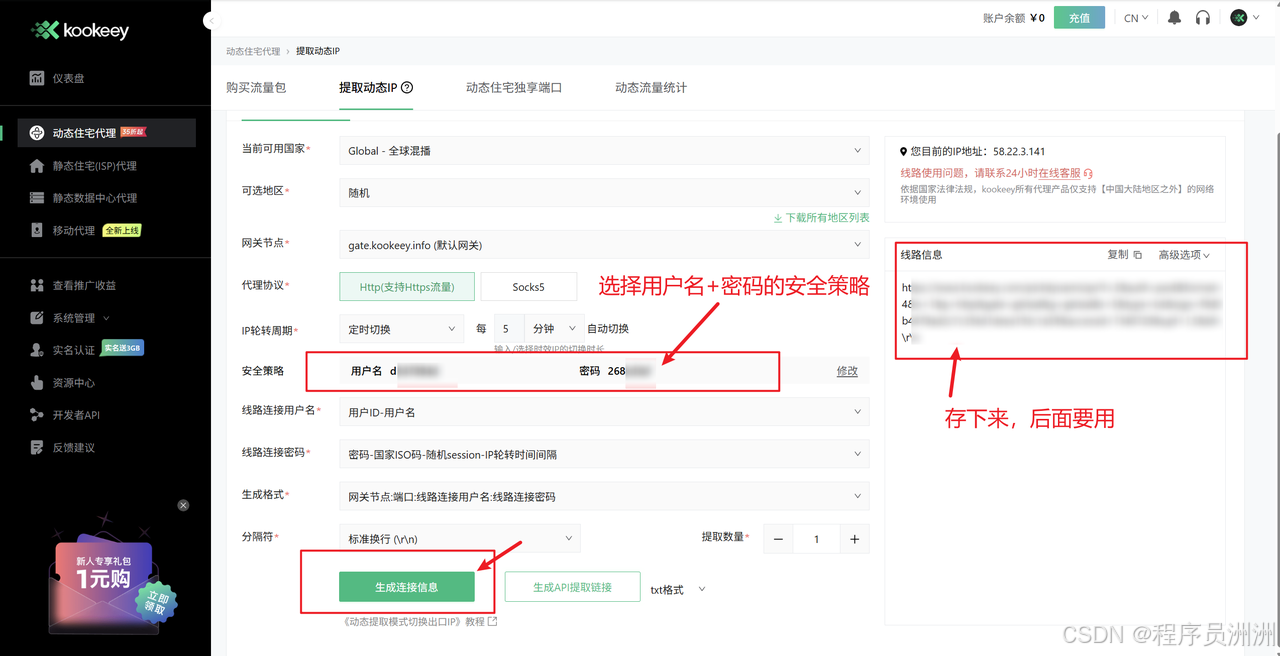 AI Visual Insight: This image shows the proxy extraction parameter configuration interface, which typically includes region, protocol, authentication method, and output format. These fields directly determine how the script reads and uses the proxy list.
AI Visual Insight: This image shows the proxy extraction parameter configuration interface, which typically includes region, protocol, authentication method, and output format. These fields directly determine how the script reads and uses the proxy list.
The core of a scraping script is not page retrieval, but realistic session simulation
For reliable Amazon scraping, success does not depend on whether a single request works. It depends on whether the session remains consistent, whether headers look trustworthy, whether latency appears natural, and whether proxies can rotate. In particular, Cookie, Referer, and User-Agent are critical fields.
import random
import time
import requests
session = requests.Session()
session.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0 Safari/537.36", # Simulate a real browser
"Accept-Language": "en-US,en;q=0.9", # Request English content from the target site
"Referer": "https://www.amazon.com/" # Declare an on-site referral source to reduce anomaly risk
})
for page in range(1, 4):
params = {"k": "yoga mat", "page": page}
resp = session.get("https://www.amazon.com/s", params=params, timeout=20)
time.sleep(random.uniform(1, 3)) # Add a random delay to simulate human pausesThis code demonstrates a minimum viable session simulation strategy built around stable headers and randomized access intervals.
API analysis determines extraction efficiency and robustness
The original workflow starts by observing search requests in the browser Network panel. Pay close attention to parameters such as k, page, sprefix, and crid, and distinguish between XHR, Fetch, and direct HTML page responses.
If you can access structured JSON, parsing costs stay low. If only HTML is available, you need CSS selectors to extract the title, price, rating, review count, and ASIN. In practice, both approaches should coexist to maximize robustness.
 AI Visual Insight: This image shows Amazon pages used together with developer tools, illustrating that interface analysis starts from real page interactions rather than directly writing scraping scripts.
AI Visual Insight: This image shows Amazon pages used together with developer tools, illustrating that interface analysis starts from real page interactions rather than directly writing scraping scripts.
 AI Visual Insight: This image highlights the Preserve log and Disable cache settings in the Network panel, which help retain redirect requests and avoid cache interference when tracing the actual request sequence.
AI Visual Insight: This image highlights the Preserve log and Disable cache settings in the Network panel, which help retain redirect requests and avoid cache interference when tracing the actual request sequence.
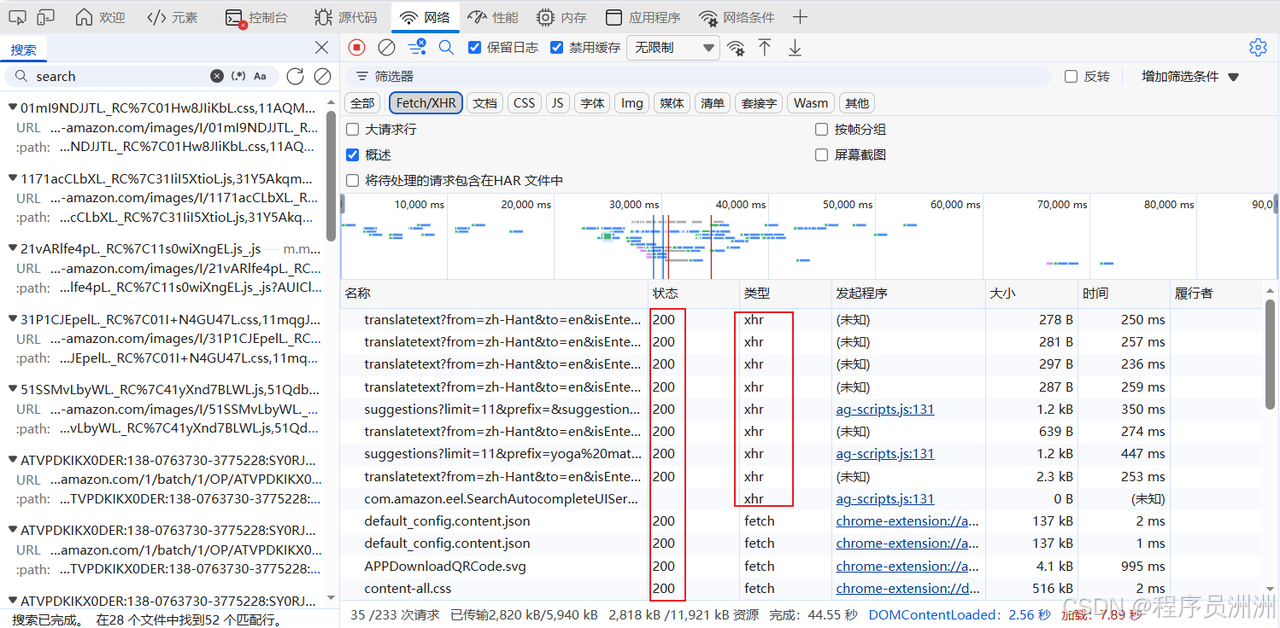 AI Visual Insight: This image focuses on the request parameter analysis area, where developers can identify how keyword, pagination, and session parameters are constructed from the URL, query string, and headers.
AI Visual Insight: This image focuses on the request parameter analysis area, where developers can identify how keyword, pagination, and session parameters are constructed from the URL, query string, and headers.
from bs4 import BeautifulSoup
def parse_products(html: str):
soup = BeautifulSoup(html, "html.parser")
items = []
for card in soup.select("div[data-asin]"):
asin = card.get("data-asin", "").strip() # Extract the unique product identifier
title = card.select_one("h2 span")
rating = card.select_one("span.a-icon-alt")
items.append({
"asin": asin,
"title": title.get_text(strip=True) if title else "",
"rating": rating.get_text(strip=True) if rating else ""
})
return itemsThis code extracts a basic product structure from search-result HTML and serves as a fallback parser when a JSON endpoint is unavailable.
Packaging the crawler as a Skill is what unlocks true automation
In OpenClaw, a Skill typically consists of a descriptor file, an execution script, and a configuration file. The descriptor defines the natural-language interface, the execution script receives parameters and performs data collection, and the configuration file stores environment variables such as proxy keys and model credentials.
In the original implementation, the user provided OpenClaw with the full requirement set, including proxy API retrieval, Amazon search pagination, randomized delays, CSV export, and exception handling, then let the Agent generate the executable Skill scaffold automatically.
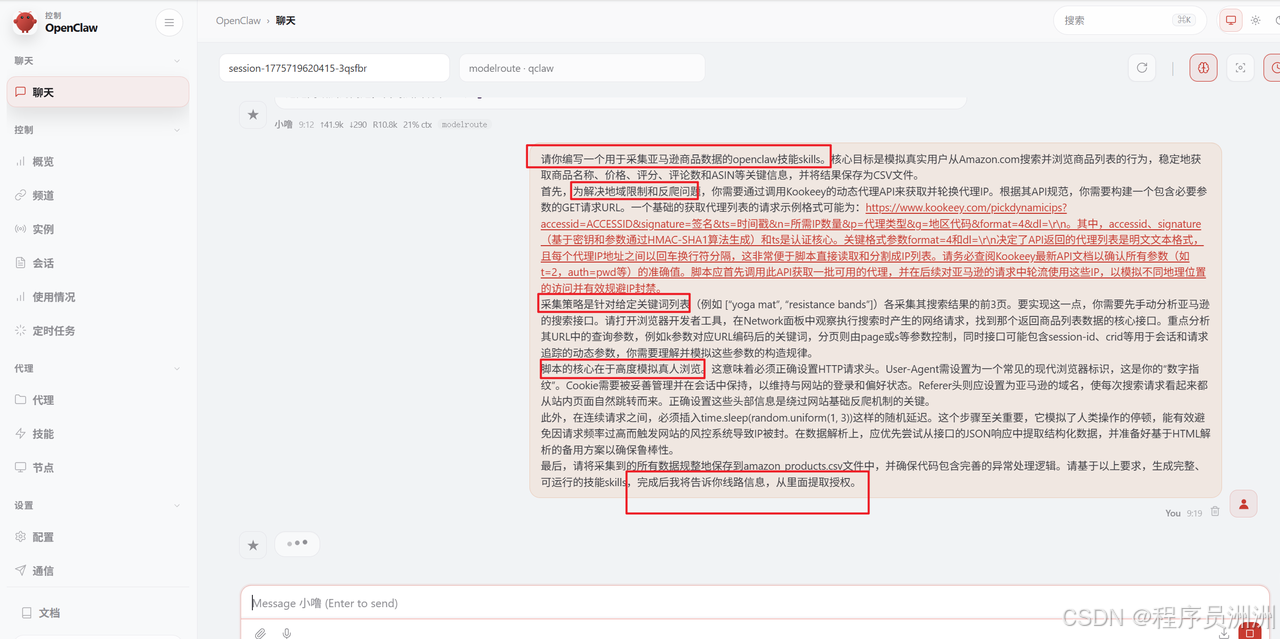 AI Visual Insight: This image shows OpenClaw automatically generating skill files or execution steps from natural-language requirements, demonstrating the Agent’s orchestration capabilities in code generation and task packaging.
AI Visual Insight: This image shows OpenClaw automatically generating skill files or execution steps from natural-language requirements, demonstrating the Agent’s orchestration capabilities in code generation and task packaging.
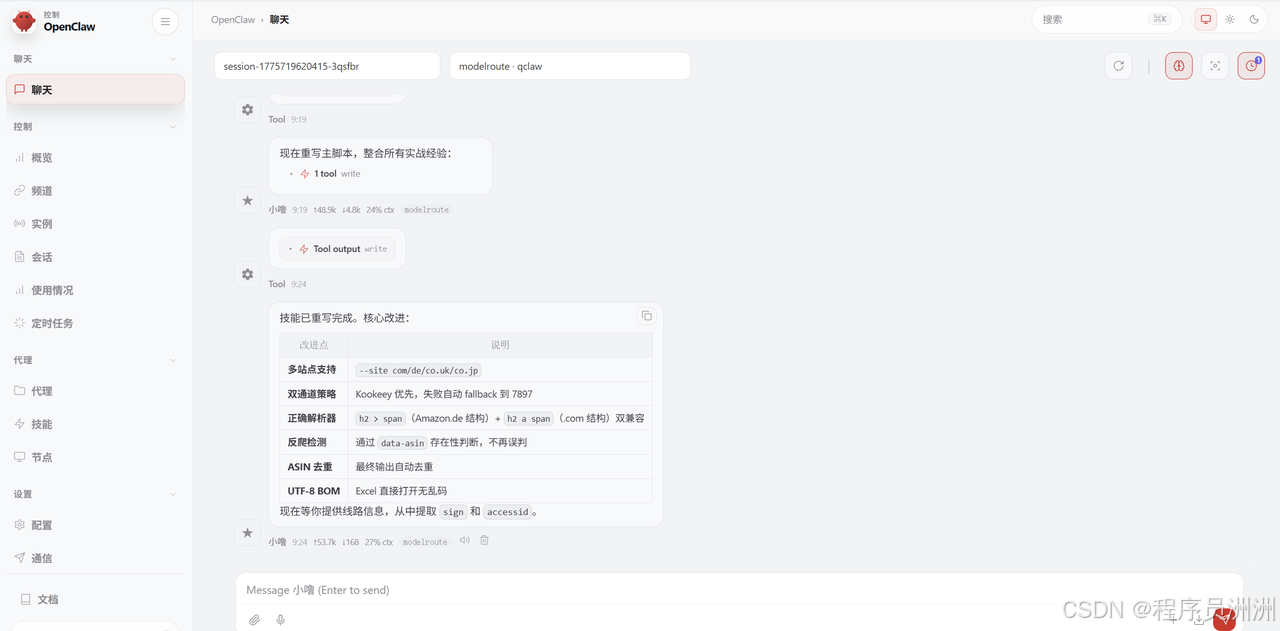 AI Visual Insight: This image presents the structured Skill definition interface, which usually includes parameter mapping, input descriptions, and output formats to reliably map natural-language requests to script parameters.
AI Visual Insight: This image presents the structured Skill definition interface, which usually includes parameter mapping, input descriptions, and output formats to reliably map natural-language requests to script parameters.
Lark turns a technical workflow into a business-friendly interface
Lark works well as the front-end collaboration entry point because it combines message delivery, card-based display, bot APIs, and enterprise collaboration features. After integration, operations or analysis teams do not need to log in to a server. They can trigger tasks simply by sending a message.
A typical setup path is: create a custom app in the Lark Open Platform, enable bot capabilities, request message read/write permissions, and then fill in the App ID, App Secret, and target conversation settings in the OpenClaw plugin.
 AI Visual Insight: This image shows the custom app creation entry point in the Lark Open Platform, which is the starting point for bot integration and API authentication.
AI Visual Insight: This image shows the custom app creation entry point in the Lark Open Platform, which is the starting point for bot integration and API authentication.
 AI Visual Insight: This image focuses on the bot capability and permission configuration area, which determines whether the application can receive @mentions and proactively push results.
AI Visual Insight: This image focuses on the bot capability and permission configuration area, which determines whether the application can receive @mentions and proactively push results.
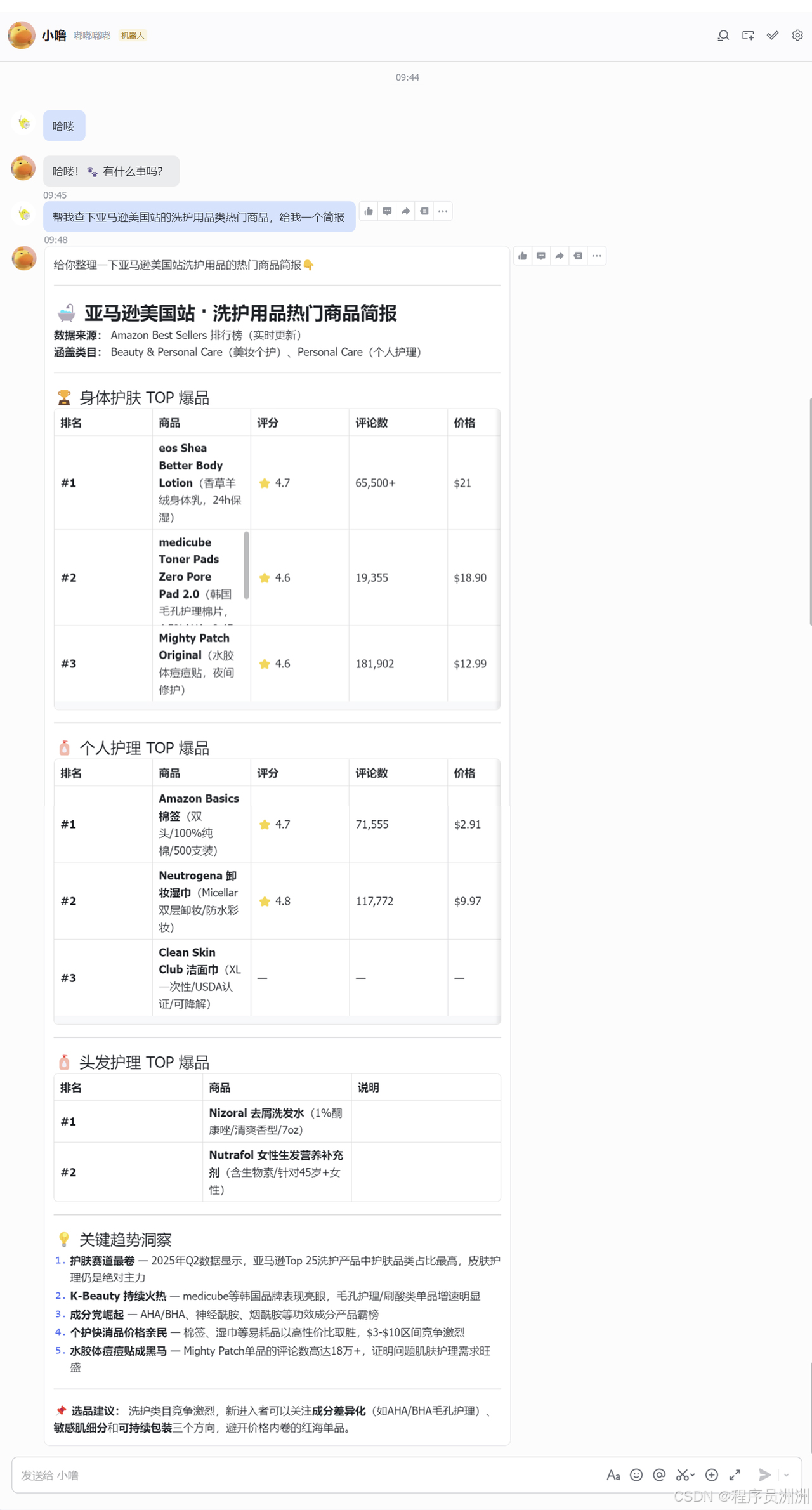 AI Visual Insight: This image shows a complete human-machine interaction flow in Lark, including task submission, in-progress feedback, and final result delivery. It represents the end state of conversation-as-a-service.
AI Visual Insight: This image shows a complete human-machine interaction flow in Lark, including task submission, in-progress feedback, and final result delivery. It represents the end state of conversation-as-a-service.
{
"keyword": "kitchen utensils",
"site": "de",
"pages": 5,
"output": "amazon_products.csv"
}This parameter set can serve as the standard Skill input so OpenClaw can parse a Lark message into a structured task.
The analysis layer is where the real business value appears
In the original case, the scraped output did not stop at a product list. It also generated analytical views such as brand distribution, category structure, rating distribution, price bands, and review-volume ranking. That is what makes the workflow useful for product research and competitor monitoring.
For example, in the German kitchenware market, you can identify the share of silicone sets versus stainless steel sets, mainstream price ranges, review density, and brand fragmentation, then combine those signals with local-language characteristics to produce more market-aligned operational decisions.
 AI Visual Insight: This image shows metadata statistics such as scraping scale and deduplication results, which help evaluate data completeness, coverage, and the credibility of downstream analysis.
AI Visual Insight: This image shows metadata statistics such as scraping scale and deduplication results, which help evaluate data completeness, coverage, and the credibility of downstream analysis.
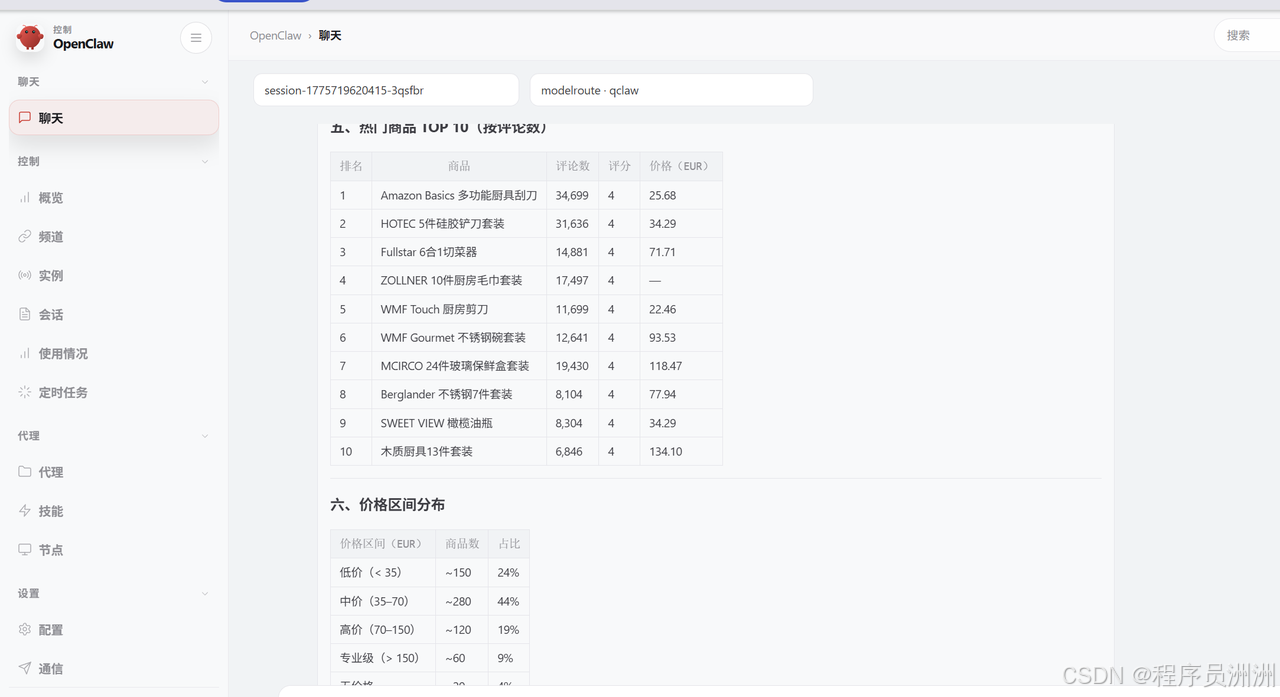 AI Visual Insight: This image shows visualized outputs such as price-range distributions, indicating that the system has already abstracted raw records into market-structure information for pricing and product-selection decisions.
AI Visual Insight: This image shows visualized outputs such as price-range distributions, indicating that the system has already abstracted raw records into market-structure information for pricing and product-selection decisions.
This is an automation architecture built for reuse and extension
This solution is highly reusable. Replace the keyword and it becomes a product research tool. Add scheduled tasks and it becomes a competitor-monitoring system. Add review analysis and it becomes a customer feedback insight engine. Connect spreadsheets or BI tools and it becomes a persistent operations dashboard.
However, real-world data collection must comply with the target platform’s terms of service, robots policies, and local laws and regulations. If your business requires more stable and auditable data sources, you should first evaluate official APIs or compliant third-party data services.
FAQ
1. Why is OpenClaw a good fit for this kind of e-commerce automation task?
Because it can orchestrate natural-language requests, tool invocation, script execution, and message delivery in one workflow, lowering the technical barrier and allowing scraping logic to be packaged and reused as Skills.
2. Why are dynamic residential proxies recommended for Amazon scraping?
Because residential proxies more closely match real-user network profiles, reducing the chance that datacenter IPs will be detected, while also supporting localized access by country or region.
3. What is the main benefit of integrating Lark?
The core benefit is that it converts a complex technical workflow into a conversation-driven interface that business teams can use directly, enabling task triggering, status tracking, and result delivery in one collaborative channel.
[AI Readability Summary]
This article reconstructs an end-to-end solution for cross-border e-commerce workflows: OpenClaw orchestrates tasks, kookeey dynamic residential proxies improve Amazon scraping stability, Python handles product data collection and cleanup, and Lark enables conversational triggering, status feedback, and analysis result delivery. It fits product research, competitor monitoring, and automation-driven collaboration scenarios.