pi0.7 is a controllable general-purpose robot foundation model. Its core idea is to turn subtask instructions, subgoal images, episode metadata, and control mode into a four-layer prompt, allowing a Vision-Language-Action (VLA) model to do more than imitate: it can compose skills, transfer across robots, and follow complex instructions. It addresses three persistent pain points: unified training over heterogeneous multi-source data, effective use of suboptimal trajectories, and generalization on long-horizon tasks. Keywords: VLA, world model, compositional generalization.
Technical Specifications Show the System at a Glance
| Parameter | Specification |
|---|---|
| Model Positioning | General-purpose robot foundation model / VLA |
| Primary Language | Python training stack + multimodal model engineering |
| Core Architecture | Gemma 4B + SigLIP 400M + MEM + 860M Action Expert |
| Total Parameters | Approximately 5B |
| Action Modeling | Flow Matching |
| Visual Input | Up to 4 camera streams, with 6 historical frames per stream |
| Subgoal Input | Up to 3 subgoal images |
| Control Mode | joint / ee |
| Core Dependencies | Gemma, SigLIP, MEM, BAGEL |
| Paper Status | Paper and project page are public |
| GitHub Stars | Not provided in the source |
The Core Innovation in pi0.7 Extends the Prompt from Text into a Multimodal Control Interface
Traditional VLA systems usually rely on a short task string as context. That design causes behavior to average out when the model faces heterogeneous robot data, failed trajectories, and complex semantics. The key change in pi0.7 is that it upgrades context into an orchestratable control surface.
This four-layer prompt includes task-level instructions, the current subtask instruction, world-model-generated subgoal images, episode metadata, and control mode. As a result, the model knows not only what to do, but also how to do it, what state to reach, and what quality target to satisfy.
The Four-Layer Prompt Can Be Summarized as Semantic + Visual + Quality + Control
prompt = {
"task": "clean up the kitchen", # Overall task instruction
"subtask": "pick up the knife", # Current subtask
"subgoal_images": images, # Future-state images generated by the world model
"metadata": {
"speed": 8000, # Speed label
"quality": 5, # Quality label
"mistake": False # Whether mistakes are allowed
},
"control_mode": "joint" # Joint-level or end-effector control
}This code snippet shows how pi0.7 unifies discrete semantic intent and continuous control constraints within a single context.
The pi0.7 Architecture Adds a High-Level Policy and a World Model on Top of pi0.6
pi0.7 builds on pi0.6 and MEM, but introduces two decisive modules: a high-level semantic policy that generates subtask instructions, and a lightweight world model that generates subgoal images. Together, they decouple long-horizon task planning from short-horizon action execution.
The backbone consists of a 4B Gemma model, a 400M SigLIP vision encoder, a MEM-style video history encoder, and an 860M action expert. The action expert uses flow matching to predict a 50-step action chunk, then executes only the first 15 or 25 steps for real-time closed-loop control.
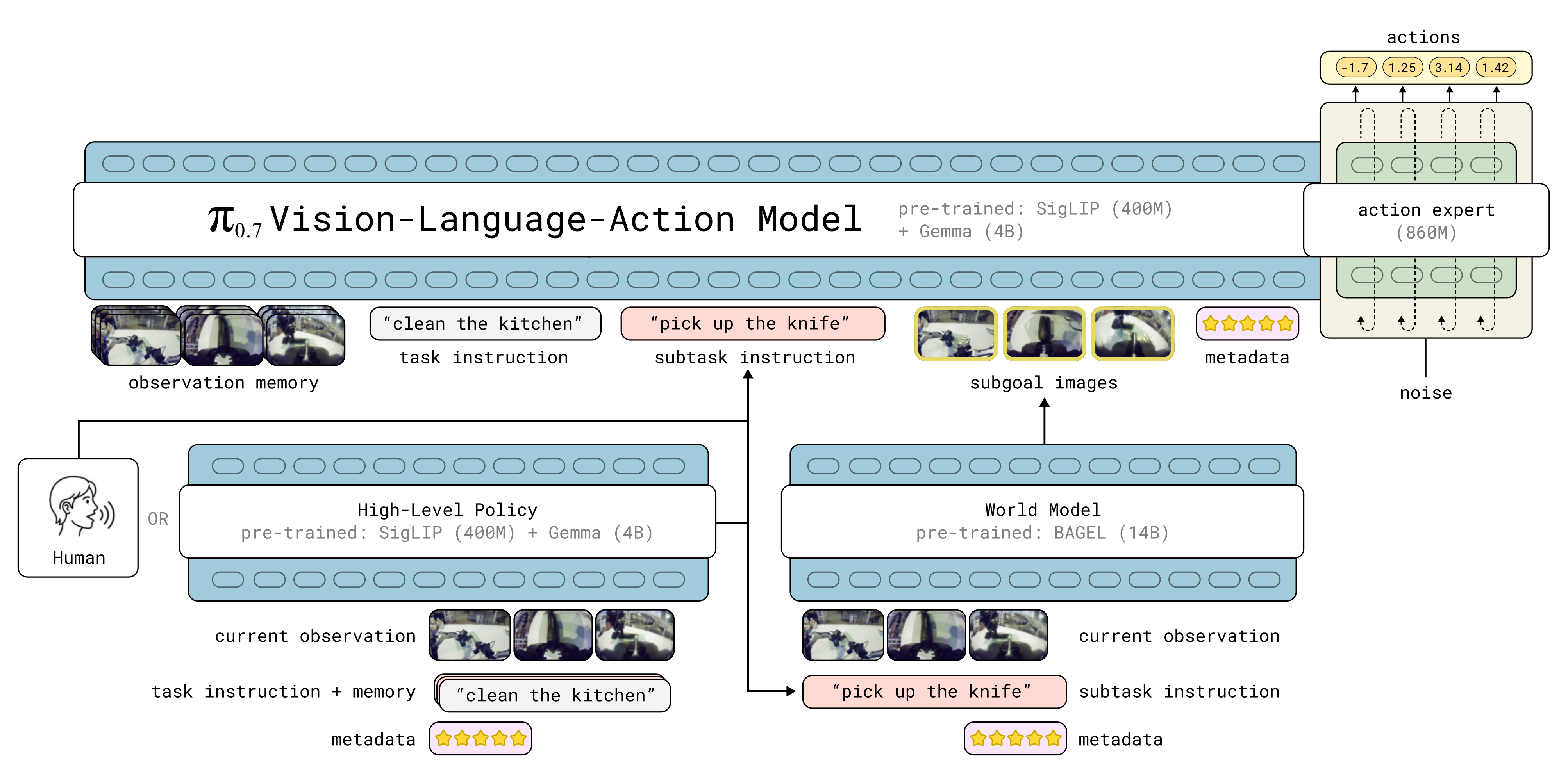 AI Visual Insight: This diagram shows the two-level control structure of pi0.7. On the left, the high-level policy takes the task description, current observation, and historical subtask memory, then outputs a natural-language subtask. On the right, the low-level VLA takes multi-view observations, historical memory, subgoal images, and metadata, then generates a continuous action chunk. In the middle, the world model uses the current scene and subtask to generate a future visual subgoal, closing the loop across semantic planning, visual imagination, and action execution.
AI Visual Insight: This diagram shows the two-level control structure of pi0.7. On the left, the high-level policy takes the task description, current observation, and historical subtask memory, then outputs a natural-language subtask. On the right, the low-level VLA takes multi-view observations, historical memory, subgoal images, and metadata, then generates a continuous action chunk. In the middle, the world model uses the current scene and subtask to generate a future visual subgoal, closing the loop across semantic planning, visual imagination, and action execution.
MEM Compresses Multi-Frame History into a Fixed Number of Tokens
Instead of feeding a long video directly into the backbone, pi0.7 uses MEM to perform spatiotemporal compression over historical frames. No matter how many past frames are provided, the number of output tokens remains fixed, which keeps inference cost under control.
This means the model balances two goals at once: short-term detail comes from video memory, while long-term progress is maintained by the high-level policy reviewing historical subtask text. The former answers what the robot sees, and the latter answers how far the task has progressed.
def encode_history(frames, encoder, mem_module):
feat = encoder(frames) # Extract per-frame visual features
memory = mem_module(feat) # Perform spatiotemporal compression
return memory # Return fixed-length tokensThis code summarizes the core path of MEM-style video history encoding.
Subgoal Images Are the Key Booster Behind pi0.7 Generalization
Text-only subtasks cannot fully specify fine-grained manipulation posture. For example, “open the refrigerator door” does not tell the robot arm what angle to use when grasping the handle. pi0.7 introduces a world model so that the system can represent what the world should look like next through images.
The world model is initialized from BAGEL. It takes current observations, the subtask, and metadata as input, and outputs future multi-view subgoal images. This lets the low-level policy reformulate action prediction as an inverse-dynamics problem between the current observation and the target observation, which improves convergence speed and execution stability.
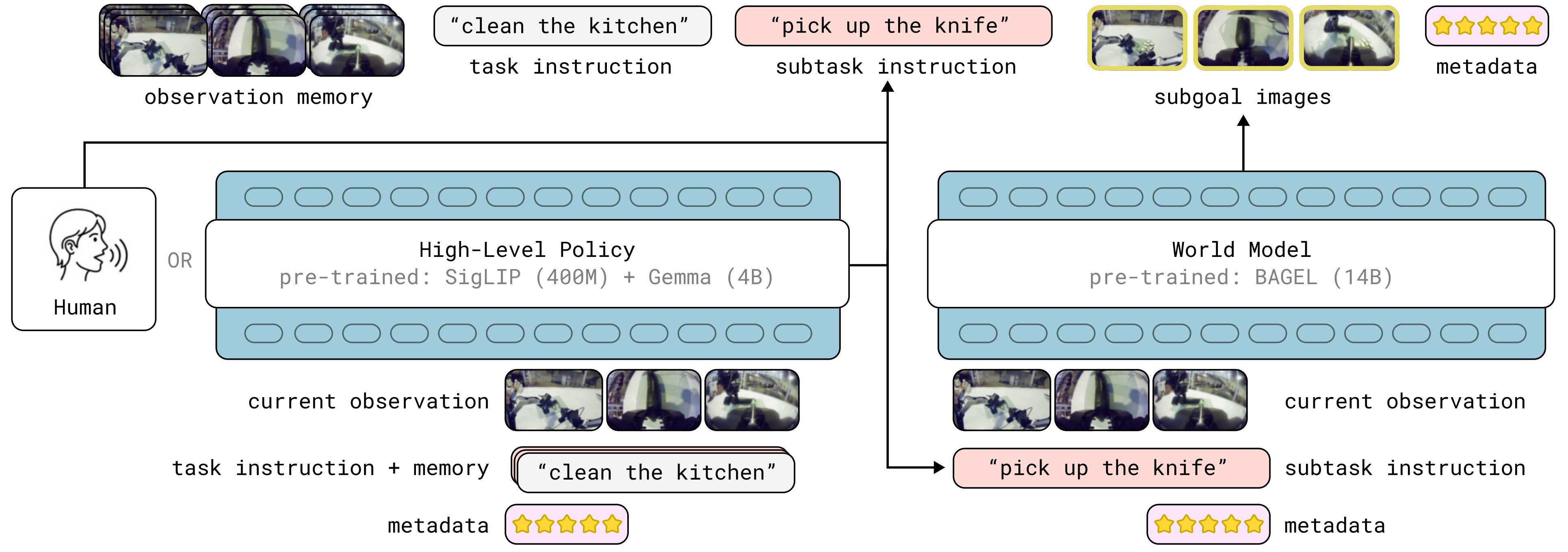 AI Visual Insight: This figure highlights a clean division of labor between two generators. On the left, the high-level language policy generates the next subtask in text. On the right, the world model generates target images from current multi-view observations and the subtask. The two outputs then jointly condition the low-level control model. This design separates abstract intent from geometric goals into two learnable signals.
AI Visual Insight: This figure highlights a clean division of labor between two generators. On the left, the high-level language policy generates the next subtask in text. On the right, the world model generates target images from current multi-view observations and the subtask. The two outputs then jointly condition the low-level control model. This design separates abstract intent from geometric goals into two learnable signals.
Runtime Uses Asynchronous Scheduling to Hide Large-Model Inference Latency
The engineering value of pi0.7 is not only in the model itself, but also in system scheduling. Subtasks and subgoal images are updated at low frequency, action chunks are generated at medium frequency, and low-level actions are executed at high frequency. This asynchronous pipeline prevents the robot from pausing during image generation or VLA inference.
while True:
if subtask_changed or timer_elapsed:
async_generate_subgoal() # Refresh subgoal images asynchronously
if need_new_action_chunk:
async_plan_actions() # Generate future action chunks asynchronously
execute_current_action() # Execute the current action at high frequencyThis code shows how pi0.7 achieves low-frequency thinking with high-frequency execution through asynchronous planning.
The Real Breakthrough in the Training Recipe Is That the Model Can Learn from Suboptimal and Failed Data
Most robot policies depend heavily on high-quality demonstrations, and low-quality trajectories are usually filtered out. pi0.7 takes the opposite approach: it keeps failed trajectories, autonomous rollouts, first-person human video, and web-scale multimodal data, then uses metadata to label speed, quality, and error segments.
The payoff is direct. The model no longer treats all trajectories as equally expert demonstrations. Instead, it learns to conditionally choose behavioral modes that are faster, more stable, and less error-prone. Ablation studies in the paper show that throughput drops significantly when metadata is removed or when self-evaluation data is absent.
Metadata Turns the Problem of More Data Means Worse Quality into More Data Means More Capability
When data scale grows while average quality drops, ordinary models often degrade. Because pi0.7 can read quality labels, it continues to benefit from a larger and noisier data pool.
This is the key distinction from traditional imitation learning: instead of blindly fitting behavior, it learns which kind of behavior should be imitated based on both the behavior itself and its context.
Experimental Results Show Clear Gains for pi0.7 Across Four Dimensions
First, it delivers strong out-of-the-box performance. On dexterous tasks such as folding clothes, assembling boxes, making coffee, and peeling, it approaches or even exceeds single-task RL/SFT specialists.
Second, it follows language better. Under complex referring expressions, reverse-direction tasks that violate dataset bias, and multi-step instructions in unseen environments, pi0.7 clearly outperforms pi0.5 and pi0.6.
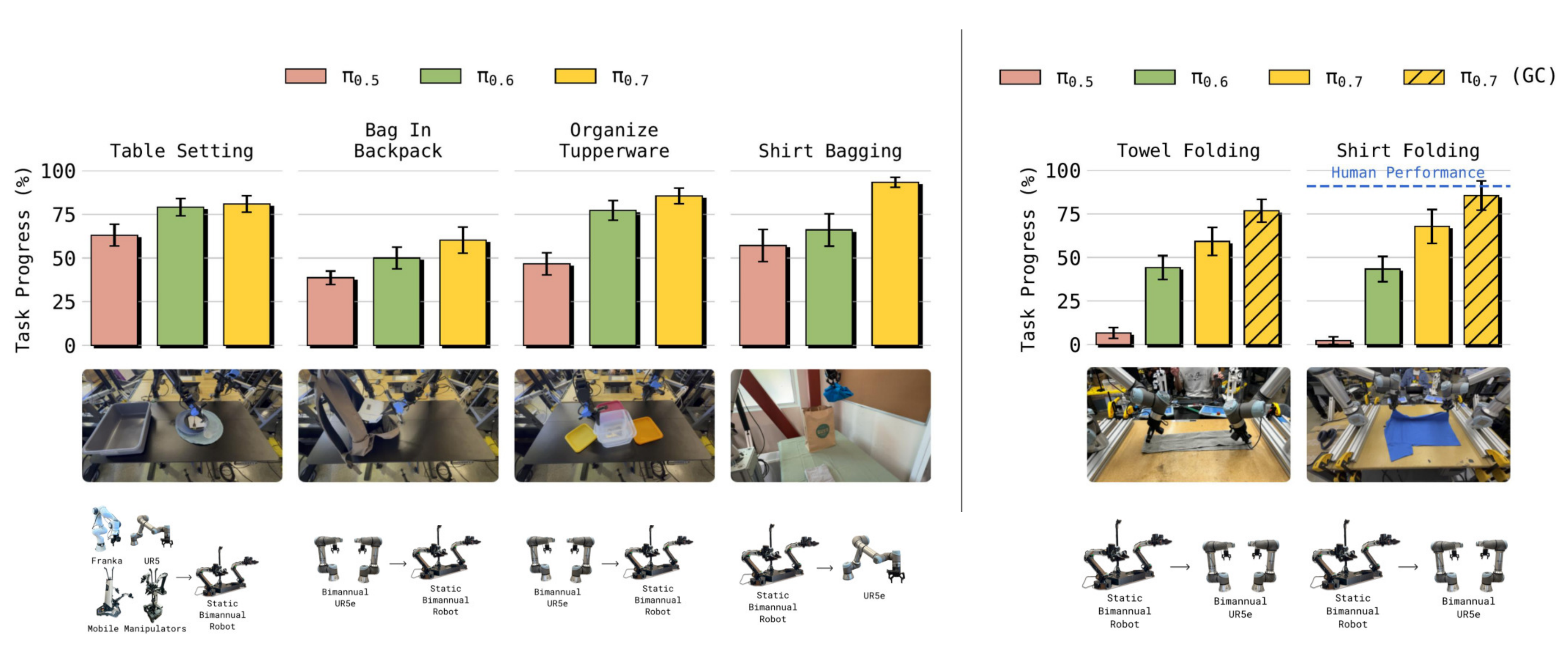 AI Visual Insight: This result figure compares success rates across multiple cross-embodiment tasks. It emphasizes pi0.7’s advantage in zero-shot transfer from source robots to target robots, especially on shirt bagging, towel folding, and shirt folding, where the system must effectively rediscover grasping strategies. pi0.7 and the variant with subgoal images perform best.
AI Visual Insight: This result figure compares success rates across multiple cross-embodiment tasks. It emphasizes pi0.7’s advantage in zero-shot transfer from source robots to target robots, especially on shirt bagging, towel folding, and shirt folding, where the system must effectively rediscover grasping strategies. pi0.7 and the variant with subgoal images perform best.
Cross-Embodiment Transfer and Compositional Generalization Are the Most Important Capabilities to Watch
Third, cross-embodiment transfer is stronger. pi0.7 can transfer skills learned on a lightweight dual-arm platform to a heavier UR5e system with longer reach, and comes close to expert teleoperators on cloth-folding tasks.
Fourth, compositional generalization is stronger. It can directly solve unseen short-horizon tasks such as scooping rice into a rice cooker, pressing a French press, and manipulating a fan knob. For long-horizon tasks involving appliances such as air fryers and toasters, human language guidance can first steer behavior, after which the guided trajectories can be distilled into an autonomous high-level policy.
The Industry Impact Is a Shift from Data-Collection-Driven Robotics to Prompt-Driven Robotics
The value of pi0.7 is not just better benchmark numbers. It changes the learning paradigm in robotics. In the past, every new task required collecting additional action data and fine-tuning a policy. Now the model begins to handle new tasks through prompting, guidance, and visual subgoals.
This suggests a future in which robot deployment looks more like using a general-purpose foundation model: prompt first, correct as needed, and distill a high-level policy from a small amount of guided data when necessary, instead of building a new task dataset from scratch.
FAQ
What is the most fundamental upgrade from pi0.6 to pi0.7?
The most fundamental upgrade is not a larger parameter count, but a better context design. pi0.7 expands text instructions into a four-layer multimodal prompt and adds both a high-level policy and a world model, which allows it to make better use of heterogeneous, suboptimal, and cross-embodiment data.
Why are subgoal images more important than pure text?
Because many robotic manipulation details are difficult to describe precisely in language, such as grasp angle, gripper pose, and relative object position. Subgoal images make these geometric constraints explicit, which significantly reduces the difficulty of action prediction.
Why can pi0.7 learn from failed data instead of being corrupted by it?
The key is metadata. The model knows which trajectories are faster, higher quality, and whether they contain mistakes. As a result, failed data is no longer noise, but a labeled source of counterexamples and broader state coverage.
Core Summary: pi0.7 is a 5B-scale general-purpose robot foundation model for embodied intelligence. By introducing a four-layer multimodal prompt, a high-level semantic policy, a world model that generates subgoal images, and MEM video memory into a VLA architecture, it significantly improves out-of-the-box performance, language following, zero-shot cross-embodiment transfer, and compositional task generalization.