The Snowflake algorithm generates globally unique, roughly increasing Long IDs locally in distributed systems. It solves the duplication, disorder, and performance limits of database auto-increment IDs in multi-node environments. This article also clarifies the boundary between distributed IDs and distributed locks. Keywords: Snowflake algorithm, distributed ID, distributed lock.
Technical Specifications at a Glance
| Parameter | Details |
|---|---|
| Core language | Java |
| Applicable protocols/scenarios | Distributed services, RPC/HTTP request tracing, database primary key generation |
| GitHub stars | Not provided in the source |
| Core dependencies | JDK System.currentTimeMillis(), bitwise operations, synchronization control |
| ID type | 64-bit Long |
| Key goals | Global uniqueness, roughly increasing order, high throughput, local generation |
The Snowflake Algorithm Belongs in the Correct Problem Domain First
Many developers confuse the Snowflake algorithm, distributed IDs, and distributed locks, not because the concepts are inherently difficult, but because all three appear in distributed systems. In practice, they solve entirely different problems.
A distributed ID answers the question, “How do we assign a globally unique identifier to an object?” A distributed lock answers the question, “How do we ensure that multiple nodes access a shared resource mutually exclusively?” The former is about identity; the latter is about concurrency control. Snowflake is simply one classic implementation of distributed ID generation.
 AI Visual Insight: This diagram establishes the conceptual hierarchy. It typically places the Snowflake algorithm under the category of distributed ID generation schemes and shows it alongside distributed locks, helping readers distinguish unique identifier generation from mutual exclusion control by responsibility rather than by name.
AI Visual Insight: This diagram establishes the conceptual hierarchy. It typically places the Snowflake algorithm under the category of distributed ID generation schemes and shows it alongside distributed locks, helping readers distinguish unique identifier generation from mutual exclusion control by responsibility rather than by name.
This Boundary Is the One Conclusion You Must Remember
A distributed ID is like a national ID number: it uniquely identifies an object. A distributed lock is like a door lock: it controls who may enter a critical section. Even if a lock value is generated with a Snowflake ID, the Snowflake algorithm is not the lock itself.
// Distributed ID: used to identify an order
long orderId = snowflake.nextId();
// Distributed lock: used to control concurrent access to order resources
String lockKey = "lock:order:" + orderId; // The ID here is only part of the lock nameThis code shows that an ID can participate in lock design, but “generating an ID” and “acquiring a lock” are two different mechanisms.
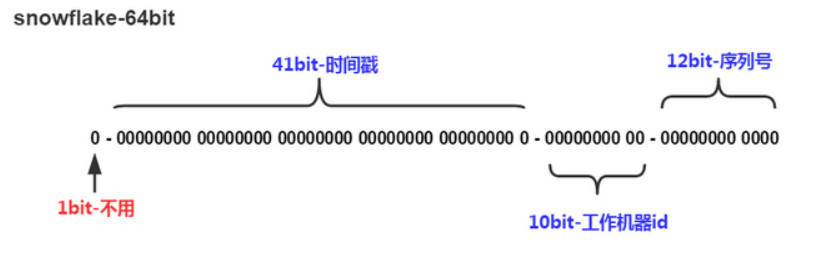
The Core Design of Snowflake Slices the 64-Bit Space
At its core, the Snowflake algorithm splits a 64-bit integer into several fields and then combines them with bitwise operations. The Tencent-style 3.23 variant discussed in the source emphasizes multi-data-center and high-concurrency scenarios, with a particular focus on optimizing the allocation of machine bits and sequence bits.
| Segment | Bits | Meaning | Purpose |
|---|---|---|---|
| Sign bit | 1 | Always 0 | Ensures a positive result |
| Timestamp bits | 31 | Millisecond offset from a custom epoch | Ensures roughly increasing order |
| Data center ID | 5 | Data center identifier | Distinguishes data centers |
| Worker ID | 5 | Node identifier | Distinguishes machines |
| Sequence | 22 | Incrementing counter within the same millisecond | Resolves collisions within the same millisecond |
What This Bit Allocation Means
A 31-bit timestamp covers roughly 68 years. Ten bits of node information support up to 1,024 deployment nodes. A 22-bit sequence allows a single machine to generate up to 4,194,304 IDs per millisecond, which fits peak-write systems well.
// 64-bit ID composition formula
long id = ((currentTimestamp - START_TIMESTAMP) << 32) // Shift the time component left
| (dataCenterId << 27) // Shift the data center component left
| (workerId << 22) // Shift the worker component left
| sequence; // The sequence occupies the low bits directlyThis snippet captures the essence of Snowflake: use left shifts and bitwise OR operations to compress multiple business fields into a single Long.
The Snowflake Generation Flow Is a Strict State Machine
A single ID generation typically includes four steps: get the current millisecond timestamp, read the data center and worker configuration, maintain the sequence within the current millisecond, and assemble the final Long value. Because it does not depend on a database or remote service, it offers low latency and high availability.
The real engineering difficulty is not the composition step, but edge-case handling, especially concurrent requests within the same millisecond and clock rollback. The former consumes sequence space, while the latter directly breaks time monotonicity.
A Java Implementation Should Handle Concurrency and Clock Rollback Explicitly
public synchronized long nextId() {
long current = System.currentTimeMillis(); // Get the current millisecond timestamp
if (current < lastTimestamp) { // Clock rollback creates a risk of duplicate IDs
throw new IllegalStateException("Clock moved backwards, refusing to generate ID");
}
if (current == lastTimestamp) {
sequence = (sequence + 1) & MAX_SEQUENCE; // Increment the sequence within the same millisecond
if (sequence == 0) {
current = waitNextMillis(lastTimestamp); // Block until the next millisecond if the sequence is exhausted
}
} else {
sequence = 0L; // Reset the sequence when a new millisecond begins
}
lastTimestamp = current;
return ((current - START_TIMESTAMP) << TIMESTAMP_SHIFT)
| (dataCenterId << DATA_CENTER_ID_SHIFT)
| (workerId << WORKER_ID_SHIFT)
| sequence;
}This code implements thread-safe Snowflake ID generation. Its core value lies in preserving uniqueness and roughly increasing order.
The Tencent-Style Optimization Is Fundamentally a Balance Between Throughput and Deployment Topology
The original Snowflake design often prioritizes general-purpose use. The Tencent-style 3.23 variant highlighted in the source emphasizes two changes. First, it splits the 10 machine bits into data center bits plus worker bits, which better supports multi-region deployment. Second, it expands the sequence field to 22 bits to increase per-node concurrency capacity.
This optimization is not universally better. It is a trade-off aimed at peak business traffic. The more bits you allocate to the sequence, the higher the throughput you can support within the same millisecond, but the tighter the timestamp budget becomes. To extend the usable lifetime, you need a custom epoch.
Typical Business Scenarios Where Snowflake Fits Well
- Order IDs, payment transaction IDs, message IDs
- User primary keys, product primary keys, log trace IDs
- Business primary keys that benefit from approximate time ordering
// Generate the primary key directly when creating an e-commerce order, without relying on database auto-increment
Long orderId = snowflake.nextId();
order.setId(orderId);
orderRepository.save(order);This snippet shows the most common usage pattern for Snowflake: generate the primary key in the application layer before persistence.
Distributed IDs and Distributed Locks Must Be Separated Completely by Their Goals
If you summarize the difference in one sentence, distributed IDs answer “who is who,” while distributed locks answer “who goes first.” One solves object identification; the other solves competitive access.
| Comparison Dimension | Distributed ID | Distributed Lock |
|---|---|---|
| Core goal | Global unique identification | Mutual exclusion for shared resources |
| Primary concern | Uniqueness, ordering, performance | Correctness, reentrancy, expiration, fault tolerance |
| Common implementations | Snowflake, UUID, Redis increment | Redis, ZooKeeper, database locks |
| Typical scenarios | Order IDs, message IDs, log IDs | Inventory deduction, coupon grabbing, balance updates |
One Commonly Misunderstood Related Scenario
In Redis-based locks, developers often set the lock value to a unique ID so they can verify during unlock that “this lock was acquired by me.” That unique ID may be generated by Snowflake, but it is only the lock owner identifier. It is not the locking mechanism itself.
String lockKey = "lock:stock:1001";
String lockValue = String.valueOf(snowflake.nextId()); // Used only as the lock owner identifier
// setNx(lockKey, lockValue) ... specific implementation omittedThis code shows that Snowflake IDs often assist distributed locks, but they cannot replace essential capabilities such as lock acquisition, renewal, and release.
The Most Common Engineering Pitfalls Do Not Come From the Algorithm Itself
The first class of problems is node ID allocation conflicts. If two nodes share the same data center ID and worker ID, duplicate IDs can still occur even if the timestamp and sequence logic is correct. The best practice is to assign node IDs centrally through a configuration center or service registry.
The second class of problems is clock rollback. NTP adjustments, VM clock drift, and manual time changes can all move system time backward. Simple implementations usually fail fast by rejecting requests. More advanced implementations may introduce buffered waiting or spare-bit strategies.
The third class of problems is database indexing behavior. Snowflake IDs are roughly increasing, but they are not globally strict and gap-free. If the business incorrectly assumes perfectly continuous IDs, you may run into issues in reconciliation or pagination design.
FAQ
FAQ 1: Why Is the Snowflake Algorithm Better Than UUID for Database Primary Keys?
Snowflake IDs are shorter because they are 64-bit integers, so indexes consume less space. They also have a roughly increasing property, which improves B+Tree insertion locality. UUIDs are unordered and much longer as strings, which is usually less friendly to indexing and storage.
FAQ 2: Can the Snowflake Algorithm Replace a Distributed Lock?
No. The Snowflake algorithm can only generate unique identifiers. It cannot provide mutual exclusion, lease renewal, timeout-based release, or atomic unlock semantics, so it cannot solve concurrent modification of shared resources.
FAQ 3: What Is the Most Important Operational Prerequisite for Snowflake?
Two prerequisites matter most: node identifiers must be globally unique, and the system clock must remain as stable as possible. If node IDs conflict or the clock rolls back significantly, ID uniqueness can be compromised.
AI Readability Summary: This article breaks down the Snowflake algorithm’s bit structure, generation flow, and Java implementation, with a focus on how it generates globally unique, roughly increasing IDs in distributed environments. It also clearly distinguishes distributed IDs from distributed locks in terms of goals, mechanisms, and usage scenarios.