VisDrone2019-DET is an object detection benchmark for drone aerial imagery. Its core value lies in providing real-world data with high object density, small-scale targets, and complex occlusion, making it well suited for training and evaluating detection models such as YOLO. It addresses the mismatch between traditional ground-view datasets and aerial top-down imagery. Keywords: drone vision, small object detection, YOLO.
The technical specification snapshot captures the dataset at a glance
| Parameter | Details |
|---|---|
| Dataset Name | VisDrone2019-DET |
| Task Type | Drone-view object detection |
| Annotation Format | Standard YOLO format |
| Number of Classes | 10 |
| Image Scale | train 6,471 / val 548 / test-dev 1,610 |
| Annotation Count | More than 2.6 million bounding boxes |
| Data Source | 288 video clips + 10,209 static images |
| Release Context | ICCV 2019 Vision Meets Drone Challenge |
| Primary Language Ecosystem | Python ecosystem |
| Common Training Frameworks | YOLOv5 / YOLOv8 / Ultralytics |
| Protocol / Evaluation System | Academic benchmark evaluation following the official challenge rules |
| Star Count | Not provided in the original input |
| Core Dependencies | PyTorch, Ultralytics, PyYAML |
This dataset is a strong benchmark for drone small object detection
Released by the AISKYEYE team at Tianjin University, VisDrone is one of the most frequently cited datasets in drone vision research. Its key value does not come from having many categories, but from the dense distribution of small objects in real top-down scenes.
Compared with general-purpose detection datasets such as COCO and VOC, VisDrone is much closer to traffic inspection, urban surveillance, crowd counting, and low-altitude security use cases. For researchers, it is an effective benchmark for validating both small object detection capability and generalization performance.
The dataset scale and collection distribution reflect real-world complexity
The training set contains 6,471 images, the validation set 548, and the test set 1,610. With more than 2.6 million bounding boxes in total, the dataset indicates that each image often contains many instances rather than sparse objects.
The data was collected across 14 cities in China and covers urban roads, rural areas, and other geographic environments. It also includes multiple drone platforms, weather conditions, and lighting scenarios. This cross-scene variation makes it naturally suitable for robustness evaluation.
# Example data.yaml
path: /data/dataset_visdrone # Dataset root directory
train: VisDrone2019-DET-train/images # Training image directory
val: VisDrone2019-DET-val/images # Validation image directory
test: VisDrone2019-DET-test-dev/images # Test image directory
nc: 10 # Total number of classes
names:
0: pedestrian
1: people
2: bicycle
3: car
4: van
5: truck
6: tricycle
7: awning-tricycle
8: bus
9: motorThis configuration defines the core data entry points and class mapping required for YOLO training.
The class design focuses on traffic and pedestrian scenarios
VisDrone2019-DET includes 10 predefined classes: pedestrian, people, bicycle, car, van, truck, tricycle, awning-tricycle, bus, and motor. Its design clearly targets low-altitude traffic observation tasks.
The distinction between pedestrian and people is especially important. The former refers to an individual pedestrian instance, while the latter is closer to a dense crowd region. This fine-grained definition directly affects label cleaning and evaluation consistency.
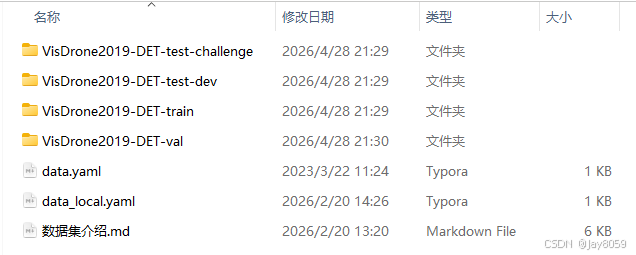
The directory layout is straightforward for engineering integration
The YOLO-converted directory structure is clean and easy to integrate directly into Ultralytics or custom training pipelines. Training, validation, and test splits all use parallel images and labels directories.
dataset_visdrone/
├── data.yaml
├── VisDrone2019-DET-train/
│ ├── images/
│ └── labels/
├── VisDrone2019-DET-val/
│ ├── images/
│ └── labels/
└── VisDrone2019-DET-test-dev/
├── images/
└── labels/This directory structure directly satisfies the data loading conventions of mainstream YOLO frameworks.
The annotation format is already aligned with mainstream YOLO training workflows
Each image corresponds to a .txt file with the same filename. Each line represents one object and uses normalized center coordinates plus width-height encoding. This format is concise and efficient for batch training.
<class_id> <x_center> <y_center> <width> <height>
3 0.026429 0.956190 0.052857 0.074286 # car: passenger car
8 0.982143 0.737619 0.035714 0.075238 # bus: bus
0 0.208929 0.655714 0.007857 0.025714 # pedestrian: small pedestrian targetThis example shows the standard YOLO annotation style for multiple object classes within the same image.
Small-object characteristics make it especially suitable for studying hard-to-detect regions
The most prominent challenge in this dataset is object scale. Because the capture altitude is high, pedestrians and vehicles often occupy only a few dozen pixels, and normalized width and height values are often below 0.02.
The second challenge is dense occlusion. Intersections, sidewalks, and parking areas frequently contain overlapping targets, making NMS, feature resolution, and label quality key performance bottlenecks.
The third challenge is multi-scale mixing. Large vehicles in the foreground and distant pedestrians may appear in the same frame, requiring the detector to provide a more stable feature pyramid representation.
This dataset has strong alignment with active research topics
If your work focuses on drone aerial small object detection, traffic object recognition, air-ground collaborative perception, or lightweight detection networks, VisDrone is almost impossible to avoid as a validation benchmark.
It is especially suitable for testing whether the following methods are effective: high-resolution inputs, enhanced feature pyramids, attention modules, small-object reweighting, label resampling, and post-processing optimization for dense scenes.
The original special annotations must be considered in experiment design
The original VisDrone annotation system includes Ignore Regions and Others. The former represents crowded or blurry areas that are difficult to annotate precisely, while the latter represents rare categories excluded from the main evaluation.
If you use a converted YOLO version, you should verify whether these regions were filtered, ignored, or remapped. Otherwise, unexplained discrepancies may appear between your training set and published paper results.
Example images make the dense targets and top-down challenges immediately visible
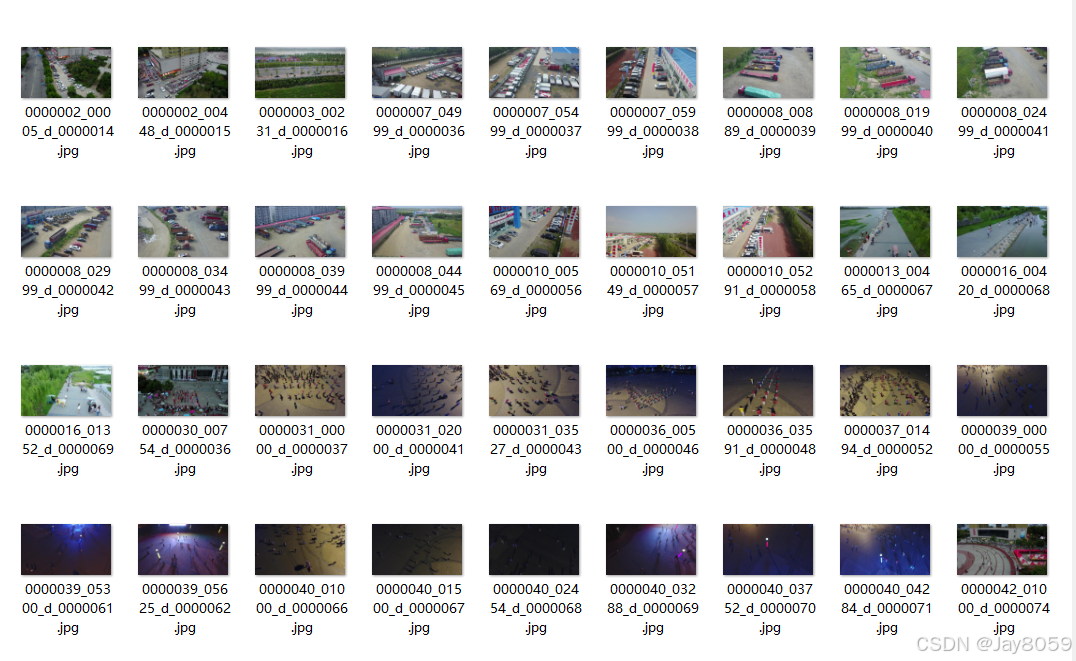 AI Visual Insight: This image shows a typical drone top-down traffic scene with densely packed object instances and clear size differences between vehicles and pedestrians. It demonstrates that the dataset includes both distant small targets and local mid-scale targets, placing high demands on multi-scale feature extraction and dense detection heads.
AI Visual Insight: This image shows a typical drone top-down traffic scene with densely packed object instances and clear size differences between vehicles and pedestrians. It demonstrates that the dataset includes both distant small targets and local mid-scale targets, placing high demands on multi-scale feature extraction and dense detection heads.
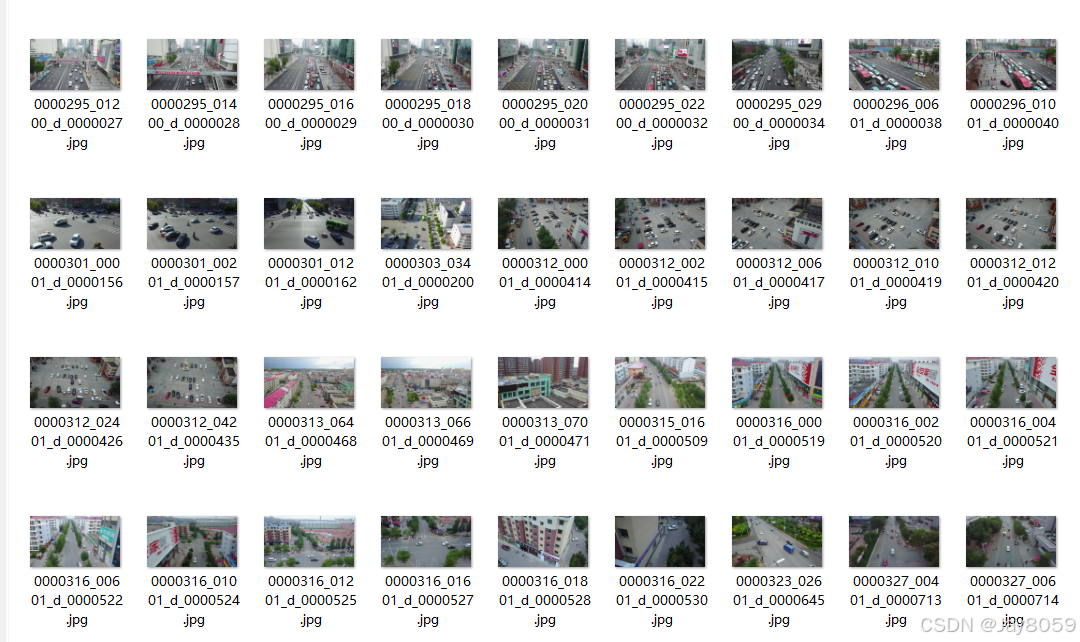 AI Visual Insight: This image highlights complex road textures and occlusion issues. Targets may be disrupted by lane markings, shadows, and building edges. For detectors, this kind of background increases the risk of false positives and especially tests the contextual discrimination ability of the classification head.
AI Visual Insight: This image highlights complex road textures and occlusion issues. Targets may be disrupted by lane markings, shadows, and building edges. For detectors, this kind of background increases the risk of false positives and especially tests the contextual discrimination ability of the classification head.
 AI Visual Insight: This image emphasizes the dense distribution of far-range targets, where many instances occupy only a tiny number of pixels. These samples typically require higher input resolution, finer-grained feature layers, and anchor or dynamic matching strategies tailored for small objects.
AI Visual Insight: This image emphasizes the dense distribution of far-range targets, where many instances occupy only a tiny number of pixels. These samples typically require higher input resolution, finer-grained feature layers, and anchor or dynamic matching strategies tailored for small objects.
A minimal runnable training command can quickly validate dataset usability
from ultralytics import YOLO
# Load a pretrained model as a strong starting point for small object detection
model = YOLO("yolov8n.pt")
# Start training by specifying data.yaml and the input size
model.train(
data="/data/dataset_visdrone/data.yaml", # Dataset configuration file
imgsz=1280, # Higher input resolution helps small object detection
epochs=100,
batch=8,
device=0
)This code launches a quick YOLOv8 training experiment on VisDrone.
Reference citations and usage notes should be included in papers or project documentation
If you use this dataset in a paper, it is recommended to cite the official paper, Detection and Tracking Meet Drones Challenge. This not only satisfies academic conventions but also helps reviewers identify the benchmark quickly.
It is also best practice to document the data source, conversion method, ignore-region handling rules, and class mapping table in your project documentation. For anyone reproducing the experiment, this information is more valuable than a download link alone.
FAQ provides structured answers to practical questions
Why is VisDrone more suitable than COCO for drone-scene research?
Because it comes from real drone top-down and oblique views, and includes large numbers of small objects, dense occlusions, and complex traffic backgrounds. Its data distribution is far more consistent with low-altitude vision tasks.
Which parameters should I tune first when training YOLO on VisDrone?
Prioritize input resolution, data augmentation strategy, and small-object-related hyperparameters. In practice, imgsz, multi-scale training, Mosaic strength, and the NMS threshold often have the earliest impact on results.
Can converted YOLO labels be used directly for paper reproduction?
Yes, as a starting point. However, you must verify whether Ignore Regions, the Others category, and class mappings are consistent with the original paper settings. Otherwise, the model may train correctly but still fail to align with official evaluation results.
Core Summary: VisDrone2019-DET is a classic benchmark for drone-view object detection. It covers 10 traffic-oriented classes and includes training, validation, and test splits. Its defining characteristics are small objects, dense occlusion, and mixed multi-scale targets. This article reconstructs its dataset scale, annotation format, YOLO configuration, research value, and practical usage considerations.