The core idea behind RAG is “retrieve first, then generate.” It addresses three major pain points of large language models: outdated knowledge, severe hallucinations, and the inability to use private knowledge. This article systematically explains 16 mainstream RAG approaches and their best-fit scenarios. Keywords: RAG, Retrieval-Augmented Generation, Agentic RAG.
Technical Specification Snapshot
| Parameter | Description |
|---|---|
| Core topic | A full-stack view of RAG (Retrieval-Augmented Generation) technologies |
| Language | Chinese |
| Source format | Originally a blog post, referencing the open-source repository liyupi/ai-guide |
| GitHub stars | The article states that the “AI Programming for Complete Beginners” repository has surpassed 10,000 stars |
| Core dependencies | Embedding models, vector databases, BM25, rerankers, LLMs, knowledge graphs, SQL databases |
| Common components | Milvus, Chroma, Qdrant, LangChain, LangGraph, LlamaIndex, Dify, RAGFlow |
RAG addresses three core weaknesses of LLMs in real-world applications
RAG does not replace LLMs. It adds “external memory” and an “evidence chain” to them. When a model relies only on parametric knowledge, it is constrained by training cutoff dates, missing domain knowledge, and generation hallucinations.
This issue becomes especially obvious in enterprise settings. Users often expect AI to answer questions about the latest policies, internal manuals, codebase conventions, or business data, but such information is usually absent from the base model’s training corpus.
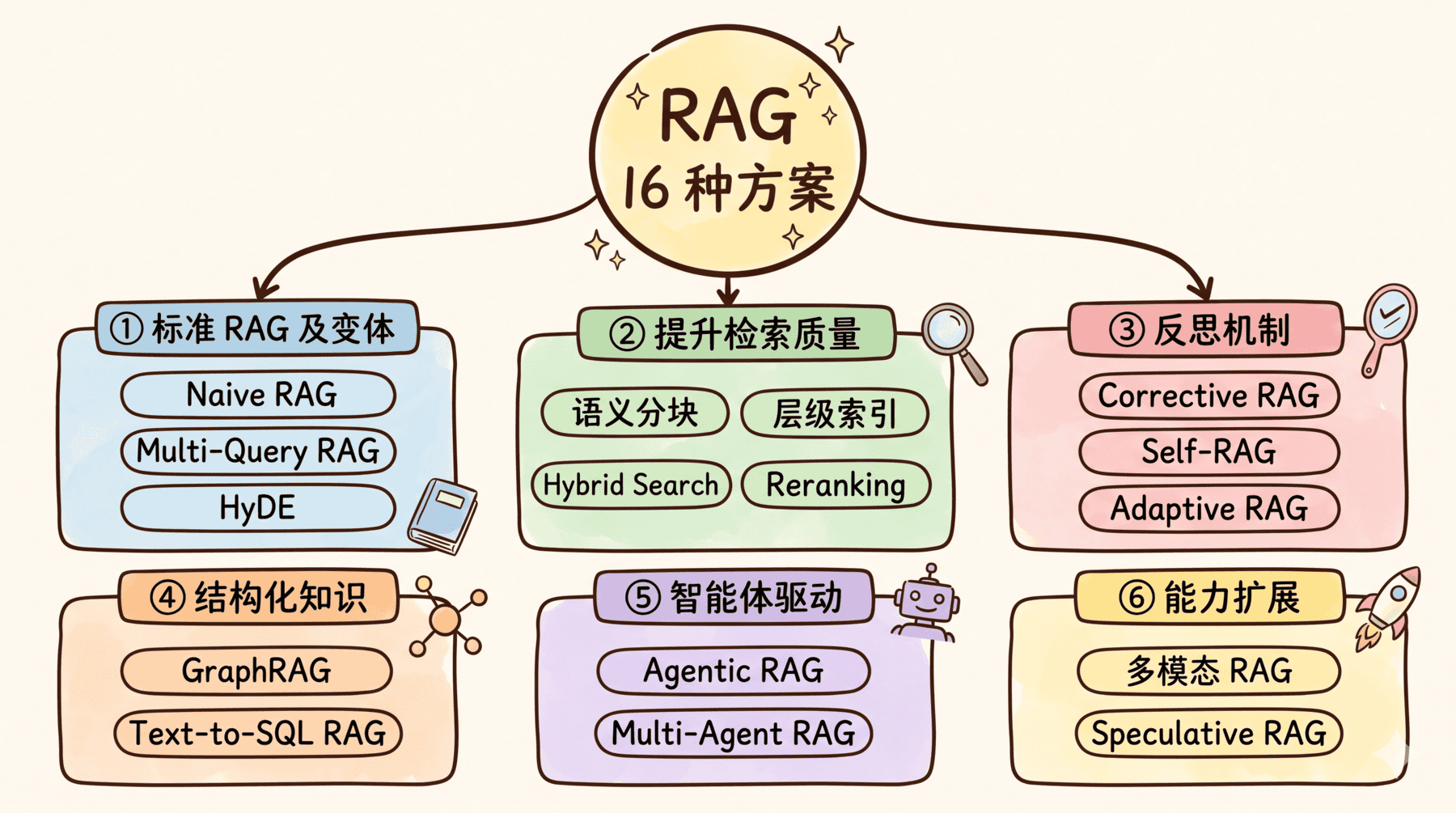 AI Visual Insight: This image introduces the article’s central theme: RAG is not a single algorithm, but a family of approaches ranging from basic retrieval to agent-driven retrieval. It works well as an overview for the 16 methods discussed below.
AI Visual Insight: This image introduces the article’s central theme: RAG is not a single algorithm, but a family of approaches ranging from basic retrieval to agent-driven retrieval. It works well as an overview for the 16 methods discussed below.
The core RAG workflow is best summarized as retrieve first, answer second
The standard workflow has two stages: offline indexing and online question answering. The offline stage chunks documents, embeds them, and stores them in an index. The online stage embeds the user query, retrieves candidate passages, and passes them to an LLM to generate the answer.
# Offline indexing: chunk documents and build a vector index
chunks = split_into_chunks(documents, chunk_size=500, chunk_overlap=50) # Control chunk size and overlap
for chunk in chunks:
vector = embedding_model.encode(chunk) # Encode text into a semantic vector
vector_store.insert(vector, chunk) # Store the vector together with the original text
# Online QA: retrieve relevant context, then generate an answer
query_vector = embedding_model.encode(user_query) # Vectorize the user query
top_k_chunks = vector_store.search(query_vector, k=5) # Retrieve the most similar content
prompt = "Answer the question based on the following materials:\n" + join(top_k_chunks) + "\nQuestion: " + user_query
answer = llm.generate(prompt) # Generate an answer grounded in evidenceThis code demonstrates the smallest complete loop of Naive RAG: indexing, retrieval, and generation.
Mainstream RAG approaches fall into three categories: retrieval optimization, quality control, and structural expansion
Naive RAG is useful for quick validation, but it depends heavily on chunk quality and vector recall quality. It often runs into three problems: it cannot find the right information, it retrieves imprecisely, or it retrieves low-value noise. As a result, production systems usually evolve gradually from basic RAG.
Retrieval recall optimization determines whether the system can find the right information at all
Multi-Query RAG asks the LLM to rewrite one question into multiple phrasings, which improves recall for conversational or loosely phrased queries. HyDE first generates a hypothetical answer, then uses the embedding of that answer for retrieval, making it especially useful when matching short questions against long documents.
Semantic chunking and hierarchical indexing improve retrieval from the data preprocessing side. The former splits text along semantic boundaries to reduce meaning fragmentation. The latter retrieves small chunks but returns larger blocks, balancing retrieval precision with contextual completeness.
# Multi-Query RAG: expand one question into multiple query variations
queries = llm.generate("Rewrite the following question into 3 different phrasings: " + user_query)
all_results = []
for query in queries:
results = vector_store.search(embed(query), k=5) # Retrieve separately for each rewritten query
all_results.append(results)
merged_chunks = deduplicate(all_results) # Merge and deduplicate results
answer = llm.generate(join(merged_chunks) + user_query)This code shows that the main benefit of Multi-Query RAG comes from multi-phrasing recall, at the cost of additional LLM calls and retrieval overhead.
Hybrid retrieval and reranking are the baseline configuration for production-grade RAG
Hybrid Search combines vector retrieval with BM25. The former handles semantic similarity, while the latter handles exact term matching. This combination is especially effective for high-precision use cases involving error codes, API names, legal clauses, or medical terminology.
Reranking adds a precision-ranking step after recall. It often uses a Cross-Encoder to recompute the relevance score between the query and each document, which significantly reduces the chance that noisy documents reach the generation stage.
# Hybrid Search + Reranking: a common production combination
semantic_results = vector_store.search(embed(query), k=20) # Semantic recall
keyword_results = bm25_index.search(query, k=20) # Keyword recall
candidates = rrf_fuse(semantic_results, keyword_results) # Fuse rankings
top_docs = cross_encoder_rerank(query, candidates, top_k=5) # Filter noise with reranking
answer = llm.generate(join(top_docs) + query)This code summarizes the main path used by most production systems: maximize recall first, then filter for precision.
Reflective RAG reduces hallucinations and incorrect citations
Retrieving something is not enough. The real question is whether the retrieved evidence is trustworthy. Corrective RAG (CRAG) performs a relevance check after retrieval. If internal knowledge is insufficient, it can automatically fall back to supplementary channels such as web search.
Self-RAG goes one step further by decomposing the process into multiple self-check stages: whether retrieval is needed, whether documents are relevant, whether the answer is evidence-grounded, and whether the final answer is useful. These approaches increase inference cost, but they pay off in high-accuracy tasks.
 AI Visual Insight: This image shows a typical failure mode when no external retrieval is used: the model answers based on outdated or incorrect knowledge. It clearly illustrates why parametric knowledge alone cannot cover real-time information or private knowledge.
AI Visual Insight: This image shows a typical failure mode when no external retrieval is used: the model answers based on outdated or incorrect knowledge. It clearly illustrates why parametric knowledge alone cannot cover real-time information or private knowledge.
 AI Visual Insight: This comparison shows that once the model receives additional reference material, factual consistency and contextual fit improve noticeably, demonstrating RAG’s direct value in reducing hallucinations.
AI Visual Insight: This comparison shows that once the model receives additional reference material, factual consistency and contextual fit improve noticeably, demonstrating RAG’s direct value in reducing hallucinations.
Adaptive RAG controls cost and complexity through routing
Not every question deserves the full RAG pipeline. Adaptive RAG first classifies the query: simple questions are answered directly, moderately difficult ones go through standard retrieval, and complex ones move into CRAG or other advanced flows.
# Adaptive RAG: choose a path based on complexity
complexity = classifier.predict(query) # Predict query complexity
if complexity == "simple":
answer = llm.generate(query) # Answer simple questions directly
elif complexity == "moderate":
docs = retriever.search(query)
answer = llm.generate(join(docs) + query)
else:
answer = run_full_crag_pipeline(query) # Use enhanced quality-control flow for complex questionsThis code reflects a key design principle in RAG systems: spend compute where the questions are truly difficult.
Structured knowledge and multi-hop reasoning require more specialized RAG variants
If the answer is distributed across multiple documents, traditional vector search struggles with cross-document reasoning. GraphRAG extracts entities and relationships to build a knowledge graph, then traverses the graph around relevant entities. It is well suited for organizational relationships, dependency chains, and global semantic analysis.
When the data itself lives in tables or databases, Text-to-SQL RAG is often more appropriate than vector retrieval. It translates natural language directly into SQL, then lets the LLM convert the query result into a natural-language response.
# Text-to-SQL: let the model translate the question into an executable query
schema = "Table sales: product(name), amount(value), month(period), region(area)"
sql = llm.generate("Convert the question into SQL based on the following schema:\n" + schema + "\nQuestion: " + query)
result = database.execute(sql) # Production systems must enforce read-only access, auditing, and isolation
answer = llm.generate("Query result: " + str(result) + "\nPlease answer in natural language: " + query)This code shows that the core of Text-to-SQL is not text retrieval, but precise computation through a database.
Agentic RAG is becoming the dominant pattern for multi-source systems
When a system includes a document corpus, a search engine, a database, and a knowledge graph at the same time, hardcoding multiple pipelines quickly becomes unmanageable. Agentic RAG lets an agent choose tools, adjust strategy, and iterate on retrieval until it has enough evidence.
Multi-Agent RAG further splits routing, retrieval, verification, and answer polishing across multiple agents. This pattern fits large enterprise knowledge systems, complex permission models, and architectures involving multiple teams.
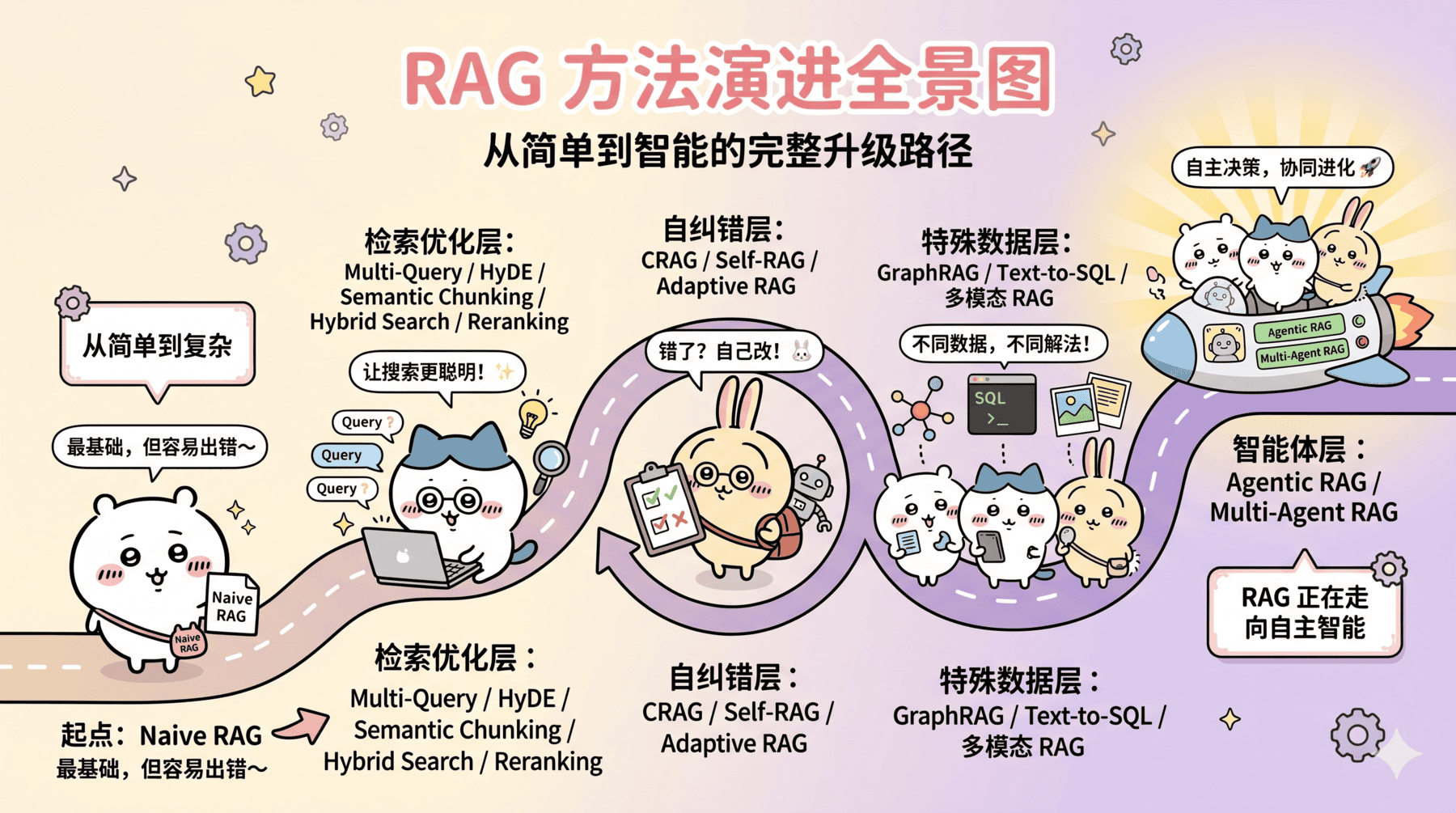 AI Visual Insight: This image highlights that different RAG approaches are not linear replacements for one another. Instead, teams should combine them based on query type, data shape, accuracy requirements, and system complexity. It serves as a useful engineering decision map.
AI Visual Insight: This image highlights that different RAG approaches are not linear replacements for one another. Instead, teams should combine them based on query type, data shape, accuracy requirements, and system complexity. It serves as a useful engineering decision map.
A practical RAG selection principle is to start simple and upgrade incrementally
If you are just getting started, first build a working loop with Naive RAG. Then optimize based on the actual bottleneck: if retrieval is inaccurate, add Hybrid Search; if noise is high, add Reranking; if hallucinations are severe, add CRAG or Self-RAG; if you need cross-document reasoning, evaluate GraphRAG.
If your document set contains many charts, diagrams, or images, you can extend the system into Multimodal RAG. If latency is extremely sensitive, you can also explore Speculative RAG to reduce response time through parallel draft generation.
In production, optimize with evaluation metrics rather than intuition
You cannot evaluate RAG only by asking whether an answer looks correct. You also need to measure whether it stays faithful to the evidence. Frameworks such as RAGAS commonly use four metrics: faithfulness, answer relevancy, context precision, and context recall.
From an engineering perspective, a strong starting configuration is: semantic or structure-aware chunking + Hybrid Search + Reranking + a minimal prompt template. Introduce knowledge graphs, routing, agents, or multimodal capabilities only after this baseline configuration has clearly hit its ceiling.
 AI Visual Insight: This image presents a visual entry point to the author’s related open-source tutorials or course materials, showing that the topic has evolved beyond conceptual explanation into practical learning paths and project-based implementation resources.
AI Visual Insight: This image presents a visual entry point to the author’s related open-source tutorials or course materials, showing that the topic has evolved beyond conceptual explanation into practical learning paths and project-based implementation resources.
FAQ structured Q&A
FAQ 1: Will RAG replace long context, or vice versa?
No. They do not replace each other. Long-context models are good at reasoning over larger evidence sets, while RAG filters for the truly relevant information first. In practice, the best pattern is often RAG first, then long-context analysis.
FAQ 2: Which three components should production teams prioritize first?
The usual priority order is Hybrid Search, Reranking, and an evaluation framework. Together, they improve recall quality, reduce noise, and make optimization measurable at a relatively controllable cost.
FAQ 3: When do you actually need GraphRAG or Agentic RAG?
Use these more complex approaches when questions require cross-document multi-hop reasoning, involve relationship networks, or depend on multiple heterogeneous data sources that cannot be handled with hardcoded strategies. Most teams do not need the full stack on day one.
Core summary: This article reconstructs the full RAG landscape, covering Naive RAG, Hybrid Search, Reranking, CRAG, Self-RAG, GraphRAG, Text-to-SQL, and Agentic RAG. It explains the problems they solve, their ideal scenarios, implementation patterns, and selection guidance. It is suitable for AI application development, interview preparation, and production system design.