This article breaks down a practical four-step workflow for reducing AI detection risk in academic papers. The core method is to use tools on high-risk sections first, then control rework costs through manual refinement and CNKI rechecking. It addresses a common pain point: buying a top-ranked tool and still failing to meet the threshold. Keywords: AI detection reduction software, CNKI AIGC detection, paper rewriting.
This is a technical specification snapshot for the CNKI workflow
| Parameter | Details |
|---|---|
| Target users | Undergraduate, master’s, and doctoral thesis submitters |
| Target platform | CNKI AIGC Detection |
| Document format | DOCX recommended, PDF supported |
| Core workflow | Upload preparation → Engine processing → Manual refinement → Recheck confirmation |
| Processing time | About 50–60 minutes for 8,000 words |
| Cost information | Initial check/recheck: about CNY 30 per run; tool usage: about CNY 4.8 per 1,000 words |
| Core dependencies | AIGC detection report, AI reduction engine, manual review |
| Protocol/interface | Web-based upload/download workflow, no public API |
| Source characteristics | The original material claims dual-engine processing and coverage across 9 platform scenarios |
A top ranking does not mean you will pass immediately
The core conclusion of the source material is straightforward: a highly ranked tool only means it performs more consistently on certain samples or platforms. It does not mean you can upload a full paper and automatically pass the threshold. What actually determines the outcome is process control, not a single click.
In the CNKI scenario, AIGC detection and plagiarism detection usually act as two parallel constraints. If you focus only on the AI score while ignoring readability, terminology consistency, and recheck results, the paper may still raise issues during advisor review or final platform validation.
A reusable four-step execution framework looks like this
1. Run an initial check to locate high-risk paragraphs
2. Upload only the content that needs processing to avoid over-rewriting
3. Review the output manually and fix semantics and terminology issues
4. Recheck on the target platform and decide whether a second pass is necessaryThis workflow turns blind full-text rewriting into targeted intervention, which reduces both cost and semantic damage.
The first step is to complete data preprocessing before upload
Upload preparation is not administrative overhead. It directly affects the upper bound of the final result. The source material recommends using DOCX first, because PDF parsing is less stable for formulas, tables, and quotation blocks. That instability can distort structure and reduce rewriting quality.
More importantly, you should isolate special content. Formulas, complex tables, long quotations, and references are usually poor candidates for direct rewriting by an engine. A safer approach is to replace them with placeholders first, then restore them after the main body has been processed.
A practical preprocessing checklist looks like this
special_blocks = ["formulas", "tables", "long quotations", "references"]
placeholders = {
"formulas": "[FORMULA]", # Protect formulas with placeholders
"tables": "[TABLE]", # Prevent tables from being rewritten incorrectly
"long quotations": "[QUOTE]", # Keep quotation structure intact
"references": "[REFERENCES]" # Preserve bibliography entries as-is
}
for block in special_blocks:
print(f"Process {block} -> {placeholders[block]}") # Output the replacement mappingThis code demonstrates the placeholder protection strategy before upload. The goal is to reduce the probability that the engine will corrupt structured content.
 AI Visual Insight: This image shows the product homepage entry point. It emphasizes the combined handling of both plagiarism reduction and AI detection reduction, which suggests the product is not just a synonym replacer but a workflow-oriented rewriting interface for academic papers.
AI Visual Insight: This image shows the product homepage entry point. It emphasizes the combined handling of both plagiarism reduction and AI detection reduction, which suggests the product is not just a synonym replacer but a workflow-oriented rewriting interface for academic papers.
The second step, engine processing, determines most of the reduction
The source material gives a processing window of 22–30 minutes for a paper of about 8,000 words. The key in this stage is not waiting but mode selection. If a paper faces both plagiarism pressure and AIGC detection pressure, an integrated “plagiarism reduction + AI reduction” workflow is usually more efficient than handling the two separately.
The dual-engine logic mentioned in the material can be understood roughly as follows: first perform semantic reconstruction, then apply style transfer. The first stage breaks apart highly similar structures. The second stage reduces traces of generative writing style. Although the public technical details are not verifiable, this is a typical layered rewriting architecture from a product design perspective.
The processing stage is closer to the following pipeline
def rewrite_pipeline(text):
semantic_text = semantic_rebuild(text) # Step 1: Reconstruct the semantic structure
styled_text = style_transfer(semantic_text) # Step 2: Transfer the writing style
return export_docx(styled_text) # Export the processed resultThis pseudocode summarizes a typical AI reduction flow: semantics first, style second, export last.
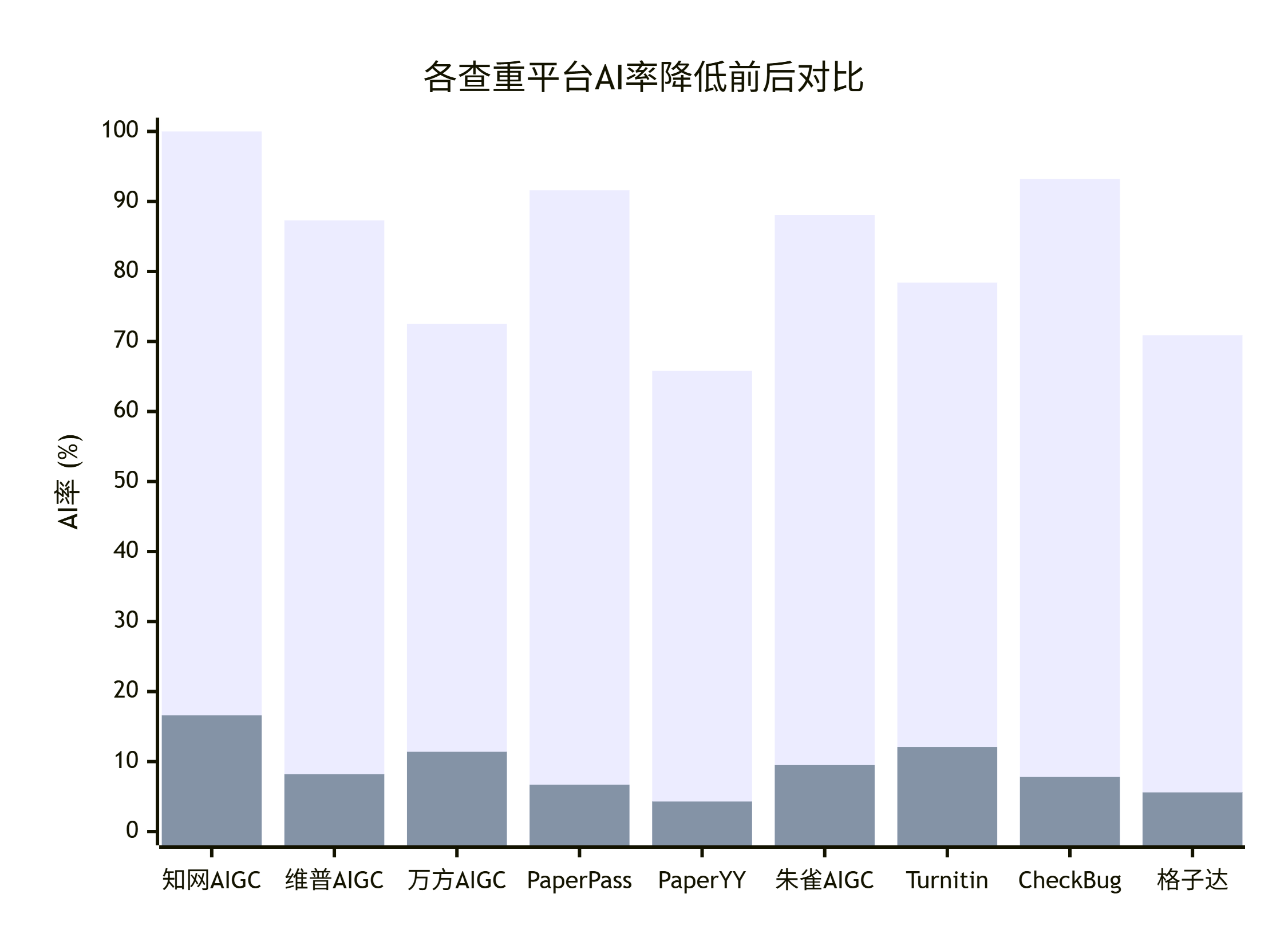 AI Visual Insight: The image highlights performance comparisons across multiple detection platforms. Its intent is to show that the tool is not optimized for only one detector, but attempts to adapt to different rule systems such as CNKI and VIP. That is useful for users who need cross-platform validation.
AI Visual Insight: The image highlights performance comparisons across multiple detection platforms. Its intent is to show that the tool is not optimized for only one detector, but attempts to adapt to different rule systems such as CNKI and VIP. That is useful for users who need cross-platform validation.
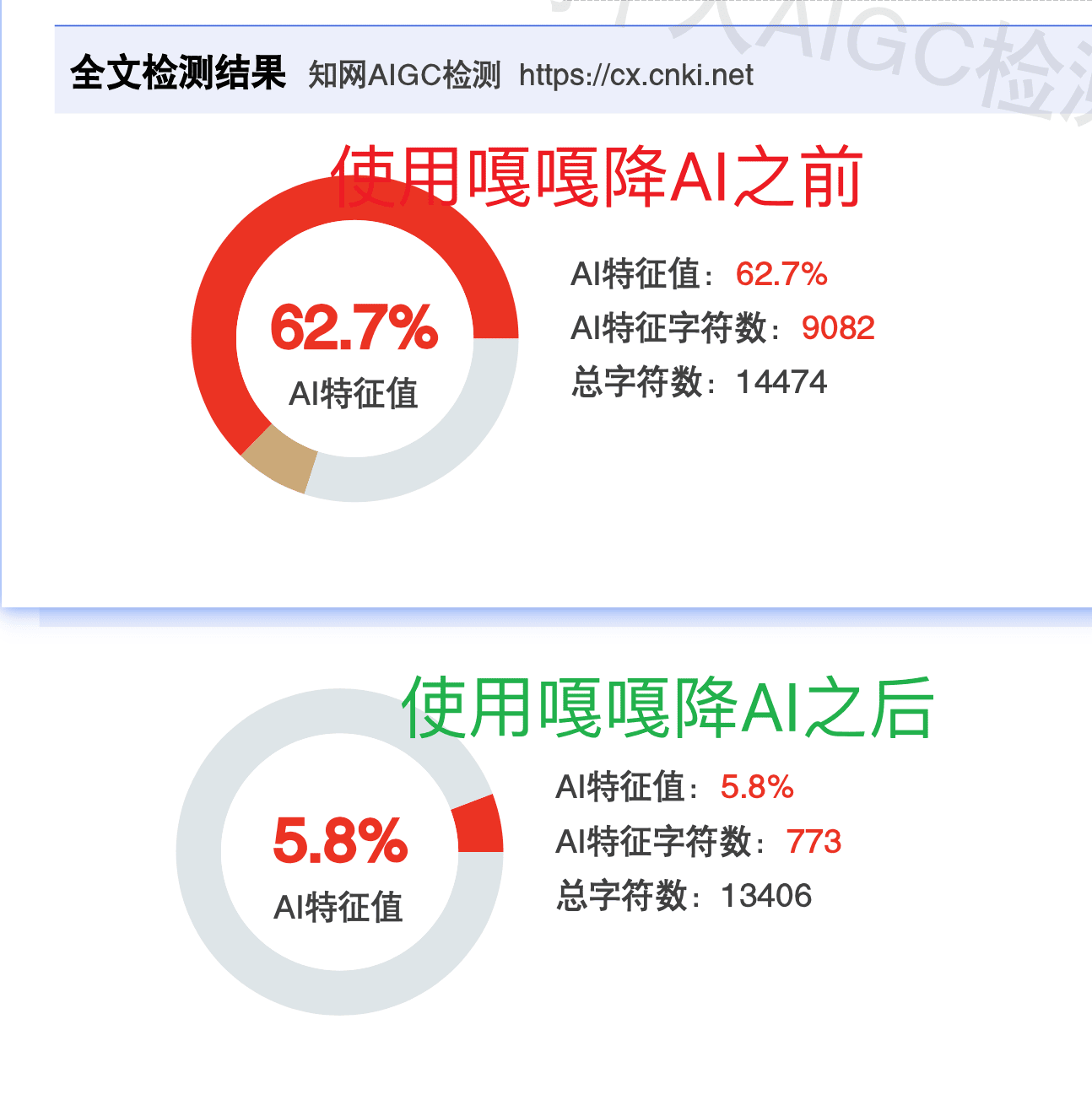 AI Visual Insight: This image directly shows before-and-after data in a CNKI scenario. The core message is that a text with a high AI score can be reduced into a lower-risk range after processing. Visually, it serves as a typical proof-of-results page designed to reinforce expectations of a significant reduction.
AI Visual Insight: This image directly shows before-and-after data in a CNKI scenario. The core message is that a text with a high AI score can be reduced into a lower-risk range after processing. Visually, it serves as a typical proof-of-results page designed to reinforce expectations of a significant reduction.
The third step, manual refinement, is critical to avoid advisor recognition
Many users fail not because the AI score remains too high, but because the paper still reads as if it was patched by an algorithm. The source material clearly states that about 5%–10% of processed sentences may still feel awkward. These issues usually cluster around long-sentence splitting, subject drift, and oversimplified replacement of technical terminology.
The goal of manual refinement is not to rewrite the entire paper. It is to repair local breaks. Prioritize logical connectors, pronoun references, and restoration of domain-specific terminology. Fixing a few obvious issues in 10 minutes usually brings more value than sending the whole paper through another full rewrite.
You should prioritize four types of sentence-level issues
Long sentences split into fragments with broken logic
Subjects or references rewritten too vaguely
Academic terminology replaced with language that is too conversational
Word order changes that make reading harder
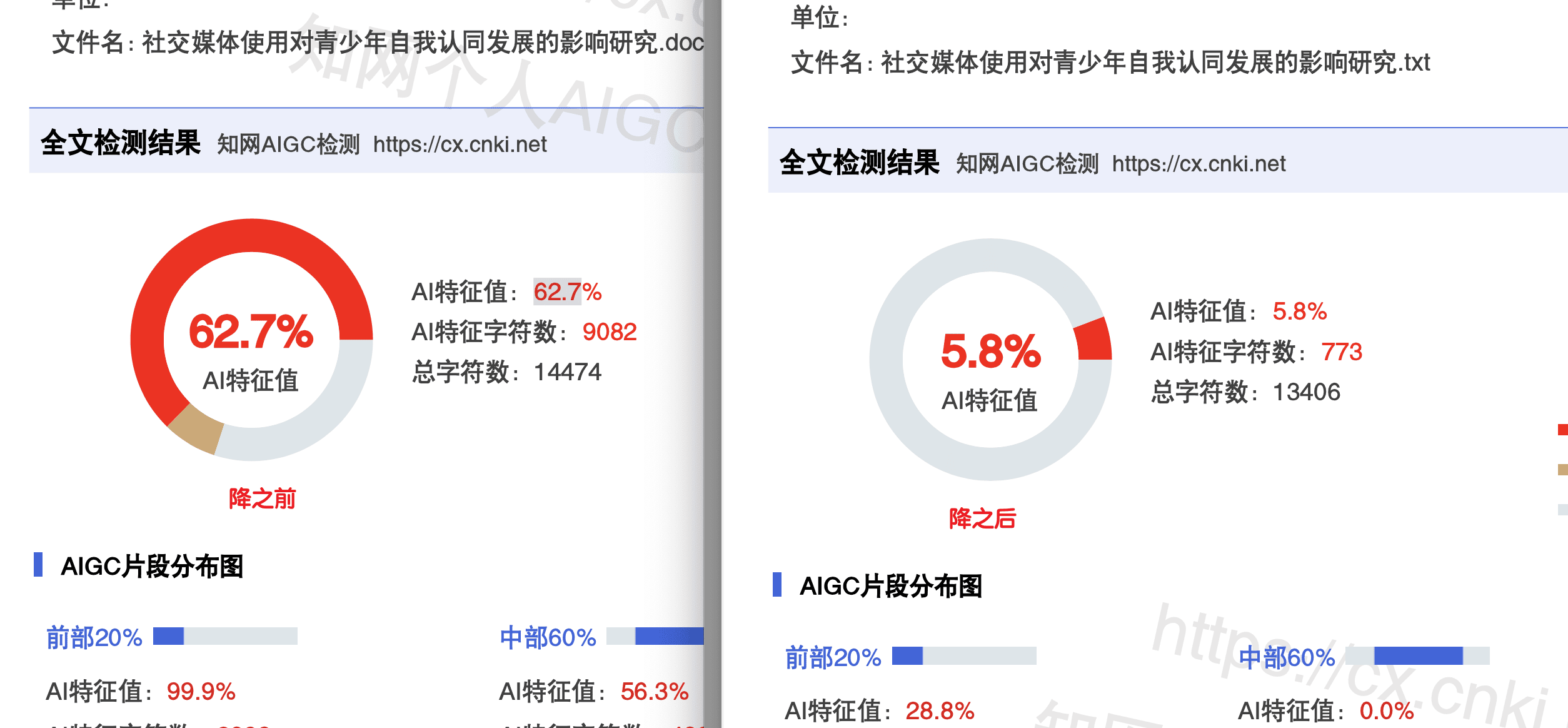 AI Visual Insight: This image looks more like a full report page, showing specific percentage changes and report structure. Its practical value is that it reminds users to trust the target platform report, not the tool’s internal self-assessment.
AI Visual Insight: This image looks more like a full report page, showing specific percentage changes and report structure. Its practical value is that it reminds users to trust the target platform report, not the tool’s internal self-assessment.
The fourth step is to close the loop with a recheck on the target platform
The value of a recheck is validation, not formality. The source material recommends continuing to purchase CNKI’s official self-check report rather than relying on low-cost third-party checks. The underlying reason is to avoid false passes caused by detector inconsistency.
When you interpret the result, divide it into three bands: more than 5 percentage points below the institutional red line is a safe zone; within about 2 percentage points above or below the red line is a marginal zone; above the red line is a risk zone. This threshold-based method works very well for process decisions.
def risk_level(score, redline):
if score < redline - 5:
return "safe zone" # Clearly below the threshold and usually ready for submission
elif redline - 2 <= score <= redline + 2:
return "marginal zone" # Close to the threshold; optimize again if possible
else:
return "risk zone" # Above or near the threshold; further processing is neededThis code turns recheck results into an actionable decision, making it easier to determine whether a second round is necessary.
 AI Visual Insight: This image emphasizes effectiveness guarantees, refunds, or protection mechanisms. It reflects that competition in this category is not only about rewriting quality, but also about risk coverage. For users close to a submission deadline, guarantee terms can matter almost as much as technical performance.
AI Visual Insight: This image emphasizes effectiveness guarantees, refunds, or protection mechanisms. It reflects that competition in this category is not only about rewriting quality, but also about risk coverage. For users close to a submission deadline, guarantee terms can matter almost as much as technical performance.
Different thesis scenarios require adjustments to the same standard workflow
For an 8,000-word undergraduate thesis, it usually makes sense to run all four steps in one pass, with a total time of about one hour. For a 30,000-word master’s thesis, a two-round approach is better: first do a broad full-text pass, then refine only the paragraphs that remain flagged after rechecking.
If the school threshold is below 10%, or if the scenario involves SCI papers or English-language submissions, a single tool is often not stable enough. In that case, a better strategy is “primary tool processing + target-platform recheck + secondary refinement for high-risk sections,” rather than repeatedly rewriting the entire manuscript.
FAQ
Q: Can I skip manual review and submit the processed document directly?
A: No. The tool mainly optimizes detection-related features, but it does not guarantee that every sentence will sound natural. Manual refinement corrects semantic jumps and terminology distortion, and significantly reduces the chance that an advisor will notice rewriting traces.
Q: Why is a CNKI recheck mandatory? Why not just trust the tool result?
A: Because the final judgment comes from the target platform. A tool’s internal report is only a reference and cannot replace the real CNKI detector. Rechecking closes the validation loop and is the only reliable basis for deciding whether a second pass is necessary.
Q: When should I run a second round?
A: If the recheck result is close to your school’s threshold, or if high-risk sections remain flagged, extract only the problematic paragraphs for a second refinement pass. Do not rerun the entire paper unless necessary, because that increases both semantic damage and cost.
Core summary: This article reconstructs the original tutorial into a more reusable AI detection reduction framework for developers and graduating students. It covers upload preparation, dual-engine processing, manual refinement, and CNKI rechecking, while adding guidance on timing, cost, risk points, and scenario-based strategy so you can more reliably push your paper’s AIGC detection score toward the acceptable range within limited time.