Model editing enables precise correction of factual errors, bias, and toxic outputs in large language models without retraining the entire model. Its core value lies in low-cost updates, strong locality control, and better maintainability. Keywords: Model Editing, ROME, T-Patcher.
Technical Specifications Snapshot
| Parameter | Details |
|---|---|
| Domain | Large Language Model Knowledge Editing |
| Core Problems | Error correction, localized updates, low-cost maintenance |
| Representative Architecture | Transformer |
| Typical Methods | SERAC, MEND, T-Patcher, ROME, MEMIT |
| Evaluation Protocols | Accuracy, Generality, Portability, Locality, Efficiency |
| Common Datasets | zsRE, COUNTERFACT, MQuAKE, FEVER |
| Core Dependencies | Feed-Forward Networks (FFN), attention mechanisms, causal tracing, low-rank updates |
| GitHub Stars | Not provided in the source input |
Large language models need model editing instead of repeated retraining
Large language models produce three categories of high-risk errors: factual mistakes, biased outputs, and harmful content. If every issue requires returning to pretraining or full fine-tuning, costs escalate quickly and catastrophic forgetting becomes more likely.
The value of model editing is that it changes only one fact or a small behavioral region while minimizing impact on the model’s other capabilities. It is closer to performing surgery on the model than sending the entire machine back to the factory.
 AI Visual Insight: This image introduces the topic of model editing and typically serves as a cover image or concept overview. It emphasizes the central problem of correcting knowledge in large language models rather than illustrating a specific algorithmic structure.
AI Visual Insight: This image introduces the topic of model editing and typically serves as a cover image or concept overview. It emphasizes the central problem of correcting knowledge in large language models rather than illustrating a specific algorithmic structure.
The goal of model editing can be defined formally
Given an original model M and an edited model M*, the goal is to make the model return a new answer for a target fact k=(xk, yk) while preserving behavior on unrelated inputs. This definition naturally emphasizes precise modification and minimal side effects.
# Use pseudocode to express the goal of model editing
def edited_model(x, target_question, target_answer, original_model):
if is_related(x, target_question): # Trigger when the input falls within the scope of the new knowledge
return target_answer # Return the edited target answer
return original_model(x) # Preserve original behavior for unrelated questionsThis code shows that the essence of model editing is local override, not global relearning.
Model editing evaluation must track five metrics at the same time
Getting the target question right is not enough. In production settings, teams care more about post-edit stability, so model editing is typically evaluated with five metrics: accuracy, generality, portability, locality, and efficiency.
Accuracy measures whether the edit is correct. Generality measures whether paraphrased prompts are corrected as well. Portability tests whether related reasoning chains update accordingly. Locality requires unrelated tasks to remain undisturbed. Efficiency determines whether the method can support frequent online fixes.
Common datasets determine whether comparisons are reproducible
zsRE is commonly used for factual question answering edits. COUNTERFACT places more emphasis on generality and locality. MQuAKE is designed for multi-hop knowledge transfer. FEVER is well suited for fact verification. Together, they form the main benchmark suite for current model editing experiments.
| Dataset | Task Type | Primary Use |
|---|---|---|
| zsRE | Question answering / knowledge association | Measure accuracy |
| COUNTERFACT | Factual revision | Measure generality and locality |
| MQuAKE | Multi-hop questions | Measure portability |
| FEVER | Fact checking | Measure robust factual judgment |
Model editing methods follow two main paths: external extension and internal modification
External extension methods do not heavily alter the original model parameters. Instead, they add caches or auxiliary modules outside the model. Their advantages are safety, controllability, and strong locality. Representative methods include SERAC and T-Patcher.
Internal modification methods directly update parameters inside the model so that new knowledge becomes part of the model itself. These methods are more deeply internalized. Representative approaches include MEND, ROME, and MEMIT.
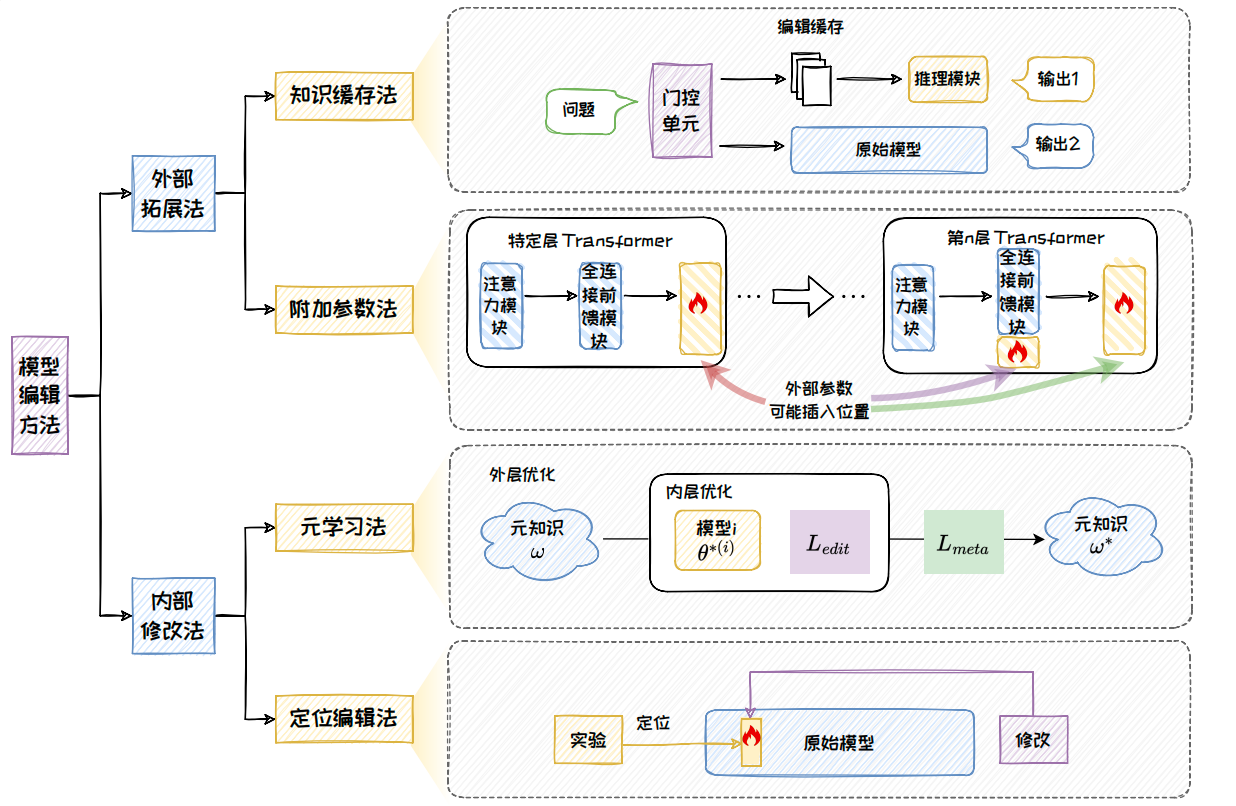 AI Visual Insight: This figure presents a taxonomy of model editing methods, from external extension to internal modification. It clearly separates four routes—knowledge caching, added parameters, meta-learning, and locate-and-edit—making the technical lineage of each method easier to understand.
AI Visual Insight: This figure presents a taxonomy of model editing methods, from external extension to internal modification. It clearly separates four routes—knowledge caching, added parameters, meta-learning, and locate-and-edit—making the technical lineage of each method easier to understand.
External extension methods emphasize low intrusion
Knowledge caching methods store new knowledge in external memory and use gating to decide when to retrieve it. Added-parameter methods insert trainable patches into locations such as FFN layers and train only the new parameters, minimizing disruption to the original model.
Internal modification methods emphasize knowledge internalization
Meta-learning methods teach the model how to edit itself. Locate-and-edit methods first identify the layer and parameters where the knowledge is stored, then apply a precise update. In recent large model editing research, the latter has offered stronger interpretability and controllability.
# Simplified method selection logic
def choose_edit_method(need_batch, need_locality, need_internalization):
if need_batch and not need_internalization:
return "SERAC" # Prioritize batch editing with low intrusion
if need_internalization and need_locality:
return "ROME" # Write the knowledge back into the model itself
return "MEND" # Balance efficiency and generalizationThis code shows that method selection is fundamentally a tradeoff among efficiency, locality, and degree of knowledge internalization.
T-Patcher corrects local knowledge through neural patches
The core idea of T-Patcher is to add key-value-style patch parameters to the feed-forward network in the final Transformer layer. It freezes the original model and trains only the patch, attaching new knowledge to the existing network with minimal intrusion.
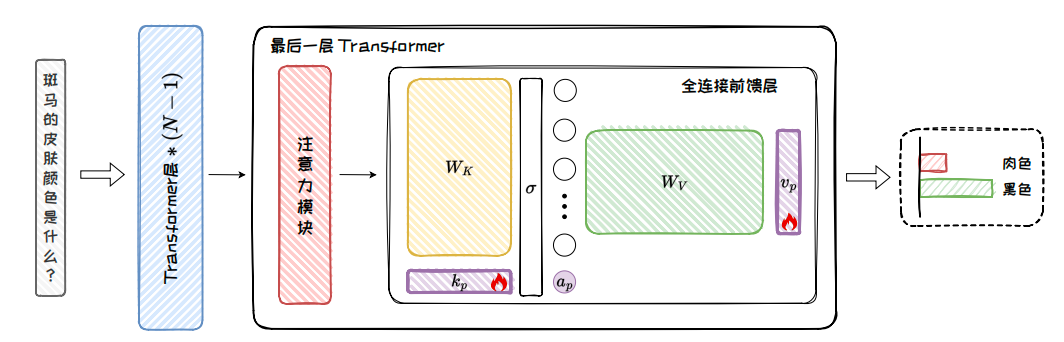 AI Visual Insight: This figure shows a trainable patch inserted into the FFN of the final Transformer layer. The patch intervenes in the output through additional neurons or key-value units, illustrating a local editing strategy based on adding rather than altering.
AI Visual Insight: This figure shows a trainable patch inserted into the FFN of the final Transformer layer. The patch intervenes in the output through additional neurons or key-value units, illustrating a local editing strategy based on adding rather than altering.
T-Patcher treats the FFN as a key-value store. When a query vector q matches a patch key kp, it activates the corresponding value vp and injects a new bias term into the output. Its strengths are solid accuracy and generalization, while its main weakness is higher memory pressure during batch editing.
# Core output form of T-Patcher
def patched_ffn(ffn_output, q, k_p, v_p, b_p):
a_p = activate(q @ k_p + b_p) # Compute whether the patch is triggered by the target input
return ffn_output + a_p * v_p # Add the patch value to the original outputThis code shows that T-Patcher essentially adds a controlled offset term to the FFN output.
ROME writes facts back into the model’s key-value memory
ROME is a representative locate-and-edit method. It first uses causal tracing to identify exactly which FFN and which layer store the target knowledge, then applies a rank-one update to write the new fact into the corresponding matrix. This design balances accuracy, generalization, and locality.
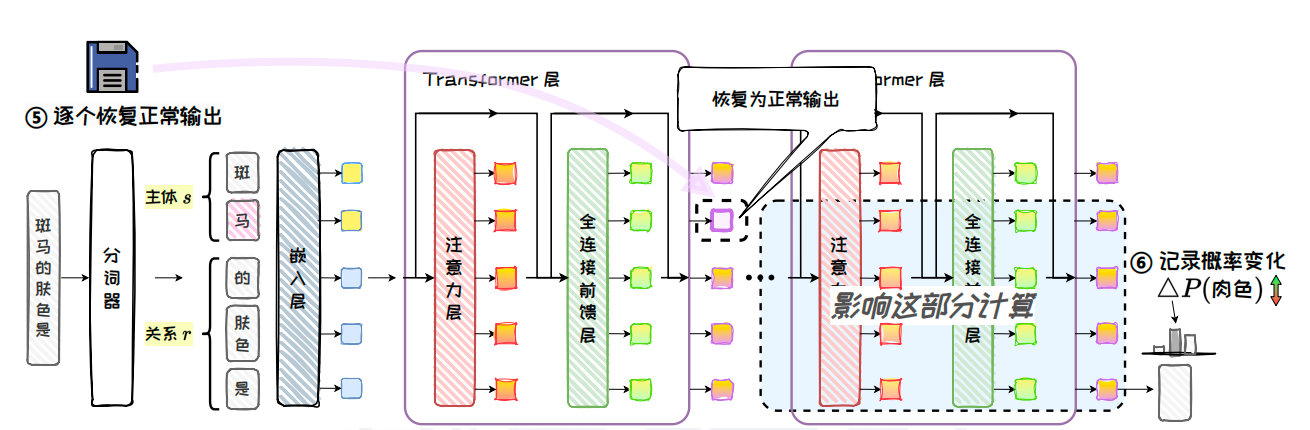 AI Visual Insight: This figure illustrates a causal tracing experiment. It first perturbs the subject token representation with noise, then restores outputs from specific modules layer by layer and measures changes in the target answer probability, allowing the system to identify the key layers and modules involved in factual recall.
AI Visual Insight: This figure illustrates a causal tracing experiment. It first perturbs the subject token representation with noise, then restores outputs from specific modules layer by layer and measures changes in the target answer probability, allowing the system to identify the key layers and modules involved in factual recall.
ROME’s key finding is that factual knowledge is concentrated mainly in middle-layer FFNs, especially in representations strongly associated with the subject’s final token. This makes locate first, then edit a practical engineering workflow.
ROME follows a very clear three-step process
The first step determines the key vector k, which is the internal representation of the subject at the target layer. The second step optimizes the value vector v so that the probability of the target answer is maximized while unrelated distribution drift is constrained. The third step applies a rank-one update to the down-projection matrix, inserting the mapping from k to v into the model.
# Simplified rank-one update in ROME
import numpy as np
def rome_update(W, k_star, v_star):
current_v = W @ k_star # Original mapping from the target key under current weights
delta_v = v_star - current_v # Target offset that must be compensated
denom = float(k_star.T @ k_star) + 1e-8 # Avoid division by zero and stabilize the update
delta_W = np.outer(delta_v, k_star) / denom # Construct the rank-one update matrix
return W + delta_WThis code shows that ROME uses a low-rank increment to write a new fact directly into the target weight matrix.
Model editing is becoming infrastructure for maintainable large language models
The three most direct applications of model editing are hot knowledge updates, right-to-be-forgotten enforcement, and AI safety governance. Compared with retraining, it is better suited for frequent online error correction and policy repair.
For knowledge updates, it can quickly fix brand ownership, time-sensitive facts, and product policies. In privacy scenarios, it can support targeted deletion of identifiable information. In safety settings, it can reduce tendencies toward toxicity, bias, and dangerous responses.
 AI Visual Insight: This figure shows emergency repair scenarios for real-world products and highlights the engineering value of model editing for rapid rollback or targeted correction of erroneous responses in online systems.
AI Visual Insight: This figure shows emergency repair scenarios for real-world products and highlights the engineering value of model editing for rapid rollback or targeted correction of erroneous responses in online systems.
Current limitations must also be addressed directly
First, complex multi-hop knowledge is still difficult to modify reliably in a single edit. Second, some methods work only with decoder-only architectures. Third, batch editing, rollback auditing, and long-term conflict management remain difficult engineering problems.
A mature large model is defined by being correctable, not only generative
Future competition will not depend only on whose model is larger. It will also depend on whose model is easier to update, audit, roll back, and govern. Model editing is pushing large language models from static training artifacts toward maintainable software systems.
FAQ
1. What is the fundamental difference between model editing and fine-tuning?
Model editing focuses on precise changes to a single fact or local behavior, with the goal of minimizing side effects. Fine-tuning usually affects a broader parameter range and is better suited for task transfer than targeted error correction.
2. Why is ROME better suited than direct fine-tuning for factual correction?
Because ROME first locates where the knowledge is stored and then writes a new mapping through a rank-one update. The scope of change is small, locality is strong, and interference with unrelated knowledge is usually lower.
3. Should an online system choose T-Patcher or ROME first?
If low intrusion and fast integration matter more, start with T-Patcher. If knowledge internalization, interpretability, and high-quality factual correction matter more, ROME usually has the advantage.
Core summary: Model editing is a key technique for targeted correction of incorrect knowledge, bias, and harmful outputs in large language models without full retraining. This article systematically explains the definition of model editing, evaluation metrics, mainstream technical paths, and two representative methods—T-Patcher and ROME—then summarizes their engineering value in knowledge updates, privacy deletion, and safety governance.