The core goal of AI application architecture is to build an engineering foundation that is scalable, maintainable, and easy to split later—without introducing unnecessary complexity. This article focuses on three practical areas: modular monoliths, Spring layering conventions, and external LLM integration governance. Together, they address common pain points such as runaway coupling, thread blocking, and high future decomposition costs.
Keywords: Modular Monolith, Spring Boot, LLM Integration
The technical specification snapshot is straightforward
| Parameter | Description |
|---|---|
| Language | Java |
| Frameworks | Spring Boot, MyBatis-Plus, Vue |
| Communication Protocols | HTTP, SSE |
| Build Approach | Maven multi-module |
| External Models | OpenAI, Claude, Gemini, Ollama |
| Fault Tolerance Components | Resilience4j |
| GitHub Stars | Not provided in the source |
| Core Dependencies | Spring MVC, SseEmitter, MyBatis-Plus, Resilience4j |
This class of AI applications is better suited to a modular monolith than microservices
For AI applications that integrate Agents, RAG, Workflows, MCP, and multiple model vendors, the technical complexity is already significant. If the team starts with just one developer and the first release serves roughly 50 users, adopting microservices from day one is usually not “advanced”—it is overload.
A more practical path is to run the business on a single Spring Boot application while using Maven multi-module boundaries for code-level isolation. This preserves the low operational cost of monolithic deployment while leaving clear boundaries for future service decomposition.
The recommended modular monolith split is based on capability domains
hify/
├── hify-app/ # Bootstrap module
├── hify-provider/ # Model provider management
├── hify-agent/ # Agent management and configuration
├── hify-chat/ # Conversation engine
├── hify-mcp/ # MCP tool management and invocation
├── hify-workflow/ # Workflow orchestration and execution
├── hify-knowledge/ # Knowledge base and RAG
├── hify-common/ # Shared common capabilities
├── hify-web/ # Frontend project
└── deploy/ # Deployment configurationThe value of this structure is not that it “looks neat.” Its value is that it supports future decomposition. Split modules by business capability first, and if you later extract hify-chat into an independent service, the main change will be in the invocation method rather than a full rewrite of business logic.
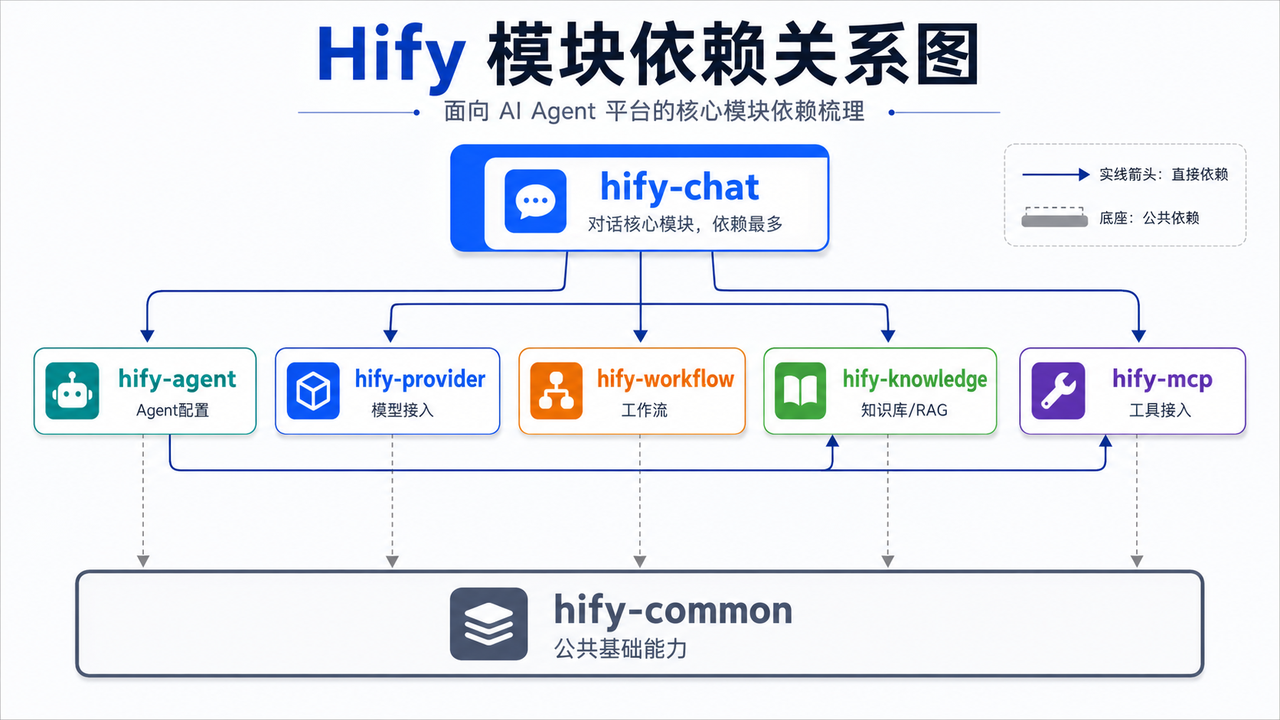 AI Visual Insight: The diagram shows a module dependency topology, not just a directory tree. The conversation engine sits at the center of the dependency graph and calls Agent, Provider, Workflow, Knowledge, and MCP modules, while the common module serves as the shared foundation underneath. This one-way dependency graph helps identify high-coupling hotspots and prioritize future service extraction.
AI Visual Insight: The diagram shows a module dependency topology, not just a directory tree. The conversation engine sits at the center of the dependency graph and calls Agent, Provider, Workflow, Knowledge, and MCP modules, while the common module serves as the shared foundation underneath. This one-way dependency graph helps identify high-coupling hotspots and prioritize future service extraction.
Module dependencies must remain one-way to control complexity
In this architecture, hify-chat is usually the most dependency-heavy module because it must read Agent configuration, call models, trigger workflows, access the knowledge base, and execute tools. Meanwhile, hify-agent may depend on hify-mcp and hify-knowledge to configure tools and knowledge sources.
Every business module can depend on hify-common, but modules must not freely reference one another in reverse. The rule is simple: dependencies must be one-way, and circular dependencies are forbidden. If A depends on B and B also depends on A, your boundaries have failed. Move the shared capability down into the common module instead.
The standard for evaluating module boundaries is simple
public interface AgentQueryService {
// Expose only the query capabilities required across modules
AgentConfigDTO getAgentConfig(Long agentId);
}
@Service
public class ChatAppService {
private final AgentQueryService agentQueryService; // Depend on the Agent module through an interface
public ChatAppService(AgentQueryService agentQueryService) {
this.agentQueryService = agentQueryService;
}
public AgentConfigDTO loadAgent(Long agentId) {
return agentQueryService.getAgentConfig(agentId); // Cross-module calls should go only through Service interfaces
}
}The point of this example is not syntax. It is boundary design: the chat module may depend on service interfaces exposed by the Agent module, but it must not directly reference its Mapper or database entities.
Spring layering conventions must be written as AI-executable rules
When a large portion of code is generated with AI assistance, “shared assumptions” do not exist by default. If you do not write the rules down, AI may place transactions in Controllers, put query logic into DTOs, or directly manipulate another module’s Mapper across boundaries. That is how architecture quickly loses control.
For that reason, the internal module structure should be standardized, and the guidance should be specific down to the directory level: controller, service, service/impl, mapper, entity, dto, config, exception, and constant. A unified structure directly improves the consistency of generated code.
Each layer should have responsibilities that cannot be crossed
- Controller: validate parameters and invoke Services only.
- Service: carry business logic, transactions, and rule orchestration.
- Mapper: handle database reads and writes only.
- Entity: map to database tables and remain internal.
- DTO: handle requests and responses and isolate internal data structures.
@RestController
@RequestMapping("/agents")
public class AgentController {
private final AgentService agentService;
public AgentController(AgentService agentService) {
this.agentService = agentService;
}
@GetMapping("/{id}")
public AgentDetailDTO detail(@PathVariable Long id) {
return agentService.getDetail(id); // The Controller forwards requests only and does not orchestrate business logic
}
}This example demonstrates the “thin controller” principle, which makes testing, refactoring, and future service extraction much easier.
External LLM integration must be designed as a high-latency system
In AI applications, the most dangerous part is usually not CRUD. It is the external model call. LLM requests are slow, volatile, and highly vendor-specific. If you treat them as ordinary HTTP calls, you can easily overload your thread pools, timeout chains, and user experience all at once.
At a minimum, your external invocation design should include four elements at the same time: thread-pool isolation, circuit breaking, timeout control, and exception-aware retry policies. Remove any one of them, and the system can still collapse under high-concurrency streaming workloads.
Thread-pool isolation is the first protection mechanism to implement
@Configuration
public class LlmExecutorConfig {
@Bean("llmExecutor")
public Executor llmExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(16); // Core threads handle stable concurrent load
executor.setMaxPoolSize(32); // Allow elastic expansion during peak traffic
executor.setQueueCapacity(200); // Prevent unbounded request buildup
executor.setThreadNamePrefix("llm-");
executor.initialize();
return executor;
}
}The main purpose of this configuration is to isolate slow LLM calls from regular management requests, so conversation endpoints do not exhaust business threads.
SSE streaming is already practical enough in Spring MVC
If your current architecture uses Spring MVC, you do not need to introduce WebFlux solely for SSE. For scenarios with concurrency in the tens and a single connection lasting from several dozen seconds to two minutes, SseEmitter + a dedicated thread pool is already sufficient.
Your timeout strategy should not use a single fixed value, either. Standard synchronous calls can be capped at 60 seconds, connectivity checks can use 10 seconds, and streaming SSE calls should be relaxed to 120 seconds. Otherwise, you will terminate healthy long-running conversations by mistake.
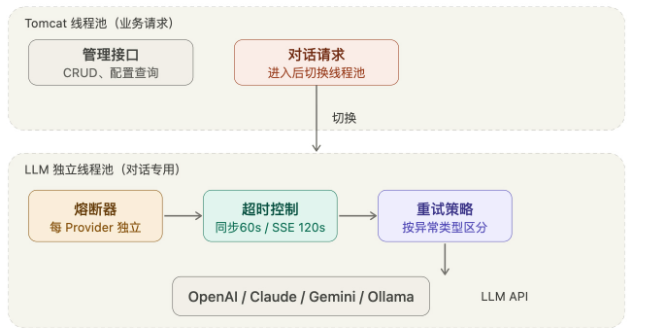 AI Visual Insight: The diagram emphasizes resource-governance priorities in external call chains and streaming interaction scenarios. It implies a three-part path: long-lived frontend connections, asynchronous server-side emission, and slow model-side responses. That is why thread isolation, layered timeout policies, and failure circuit breaking must be designed together rather than by simply increasing timeout values.
AI Visual Insight: The diagram emphasizes resource-governance priorities in external call chains and streaming interaction scenarios. It implies a three-part path: long-lived frontend connections, asynchronous server-side emission, and slow model-side responses. That is why thread isolation, layered timeout policies, and failure circuit breaking must be designed together rather than by simply increasing timeout values.
Failure handling should vary by exception type
- Network jitter: allow limited retries.
- Authentication failure: fail fast with no retry.
- Rate limiting response: retry with backoff.
- Repeated failures: trigger provider-level circuit breaking.
This approach is much closer to production reality than “retry everything three times,” and it also reduces wasted threads and quota consumption.
These architecture decisions should be captured as team rules
The most practical approach is to write module boundaries, dependency direction, layering constraints, timeout policies, and retry strategies into CLAUDE.md or an engineering standards document. That way, AI can consistently follow the same architectural constraints as it continues generating code.
The real value of a rules document is not that it records knowledge. Its value is that it constrains the future. It turns personal experience into reusable generation boundaries so that the next hundreds of code outputs remain consistent.
The FAQ section answers the most common architecture questions
Q: Why not prioritize microservices here?
Because the early-stage team is small and the user base is limited. Microservices significantly increase the cost of deployment, configuration, monitoring, and troubleshooting. A modular monolith offers a better balance between complexity control and future extensibility.
Q: Why should cross-module access avoid another module’s Mapper or Entity directly?
Because doing so exposes internal implementation details and welds module boundaries shut. If you later split services, you will need broad changes across the call chain, which is far more expensive than isolating access through Service interfaces from the start.
Q: Is WebFlux mandatory for SSE scenarios?
Not necessarily. If concurrency remains controllable, Spring MVC with SseEmitter, a dedicated thread pool, and well-designed timeout settings is enough. Consider WebFlux only when you need higher throughput and true end-to-end non-blocking behavior.
The core summary is practical and production-oriented
This article outlines an architecture approach for Hify-like AI applications that works well for solo developers and small teams. It uses a Maven multi-module modular monolith, defines clear Spring Boot layering responsibilities and cross-module invocation boundaries, and applies thread-pool isolation, circuit breaking, timeout control, and retry strategies for external LLM integrations with OpenAI, Claude, Gemini, and Ollama.