This is an intelligent workflow designed for financial research: Dify orchestrates the process, GLM-5.1 on Lanyun MaaS handles task decomposition and conclusion distillation, and Tavily delivers high signal-to-noise retrieval. Together, they solve the common problems of shallow one-shot search, heavy noise, and poor traceability. Keywords: Dify, GLM-5.1, Tavily.
The technical specification snapshot outlines the stack at a glance
| Parameter | Description |
|---|---|
| Workflow platform | Dify |
| Reasoning model | Lanyun MaaS / GLM-5.1 |
| Retrieval engine | Tavily |
| Primary language | Python |
| Interface protocols | OpenAI-Compatible API, HTTP |
| Core mechanisms | Iterative loops, variable aggregation, result distillation |
| Article popularity | 6.3k views (visible on the original article page) |
| Typical dependencies | Dify workflow nodes, Python nodes, LLM nodes, HTTP/plugin nodes |
This architecture upgrades financial analysis from linear retrieval to spiral deep research
Traditional AI-powered financial Q&A usually follows a three-step pattern: ask, search, summarize. The problem is that once the first search goes off track, the downstream output gets pulled off course by low-quality pages and surface-level news.
The key improvement in this design is the addition of a finite-depth iterative loop in Dify. Each round continues decomposition based on the clues discovered in the previous round, then launches a more precise retrieval step. After the workflow reaches the configured depth, it aggregates everything into a final output.
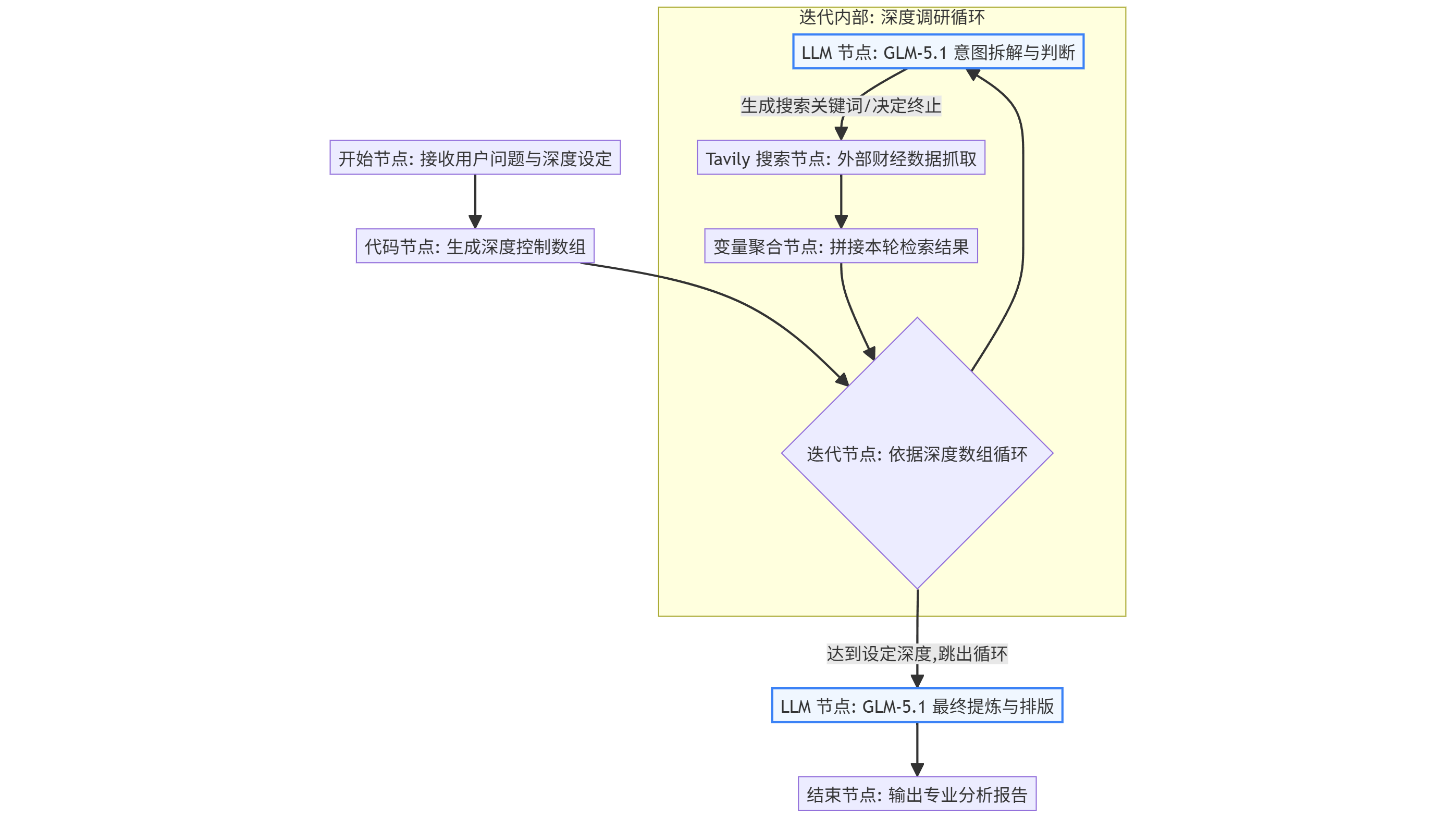 AI Visual Insight: This diagram shows the closed-loop flow from input, reasoning, retrieval, and aggregation to final output. The emphasis is not on a single search, but on continuously refining the problem through loop nodes to form a research chain of think, retrieve, validate, and summarize.
AI Visual Insight: This diagram shows the closed-loop flow from input, reasoning, retrieval, and aggregation to final output. The emphasis is not on a single search, but on continuously refining the problem through loop nodes to form a research chain of think, retrieve, validate, and summarize.
Iteration depth acts as the cost-quality balancer for the entire system
If you do not define boundaries for the AI, the system will keep searching indefinitely, leading to token waste, runaway API costs, and context pollution. That is why you should define a depth variable first and keep the exploration capability within a controllable budget.
In Dify, the start node can pass in a default depth such as 3, and then a Python node converts that integer into an array that the iteration node can consume.
def main(depth: int) -> dict:
depth = depth or 3 # Default to 3 rounds if no depth is provided
array = list(range(depth)) # Convert depth into an iteration array
return {
"array": array,
"depth": depth
}This code converts an abstract round-count configuration into executable iterative input for Dify while also preserving the depth parameter for downstream nodes.
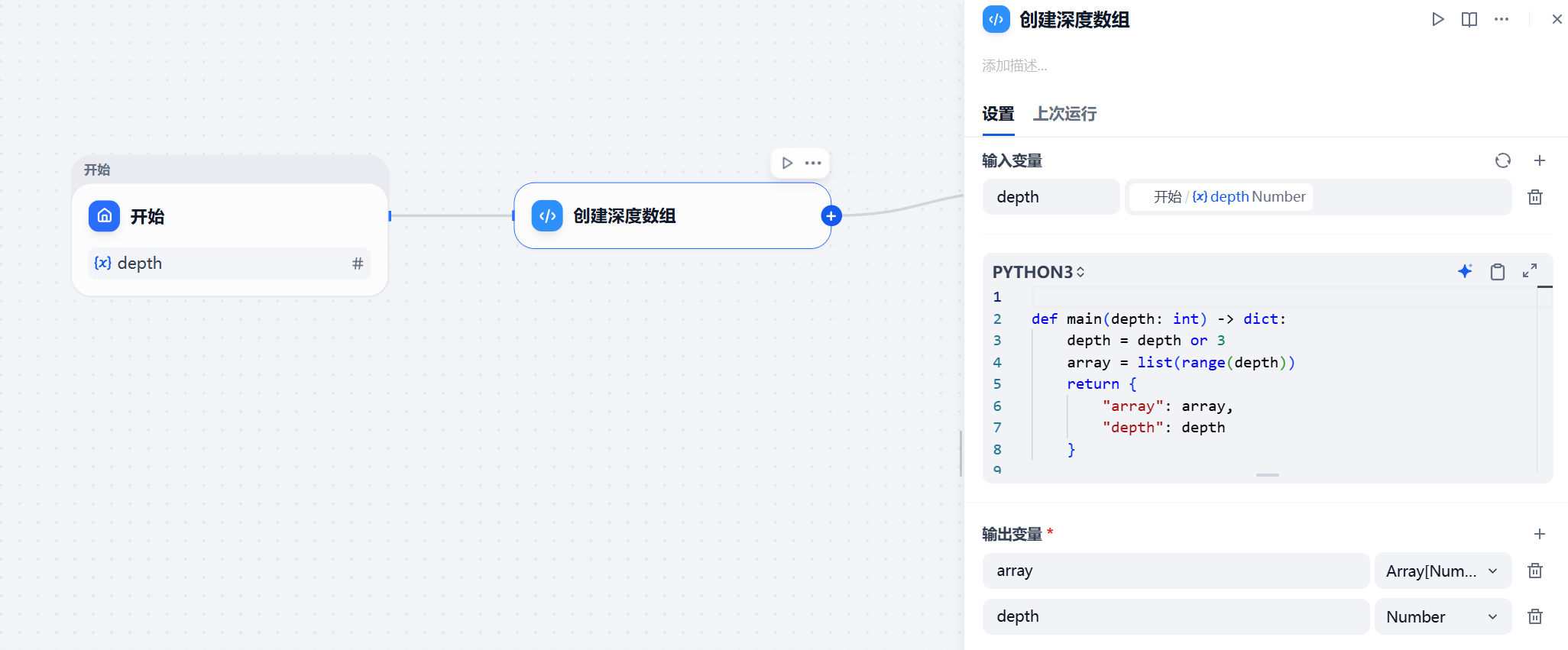 AI Visual Insight: This diagram shows how the start node connects to the Python node. The core idea is converting
AI Visual Insight: This diagram shows how the start node connects to the Python node. The core idea is converting depth into an array that drives the iterator, so the workflow has explicit round control instead of relying on unconstrained model behavior.
The inner loop should explicitly separate reasoning, retrieval, and memory into three layers
Inside the loop, the first step should not be search. The model should first break the problem down. For example, if the task is to analyze supply chain risk for an automaker, you should not search the entire sentence directly. You should first split it into sub-questions such as suppliers, upstream raw materials, substitution options, and financial statement signals.
GLM-5.1 handles this step. Its value is not just text generation. It can also keep task decomposition stable under long-context conditions, which makes it well suited for multi-factor reasoning scenarios such as financial research.
 AI Visual Insight: This diagram reflects the orchestration of multiple subnodes inside the iteration node. It shows that each loop is not a single action, but a miniature agent cycle composed of model analysis, tool calls, and result write-back.
AI Visual Insight: This diagram reflects the orchestration of multiple subnodes inside the iteration node. It shows that each loop is not a single action, but a miniature agent cycle composed of model analysis, tool calls, and result write-back.
 AI Visual Insight: This diagram further illustrates the execution order of nodes inside the loop, highlighting the sequence of reason first, retrieve second, aggregate third. This helps prevent Tavily from receiving overly vague queries.
AI Visual Insight: This diagram further illustrates the execution order of nodes inside the loop, highlighting the sequence of reason first, retrieve second, aggregate third. This helps prevent Tavily from receiving overly vague queries.
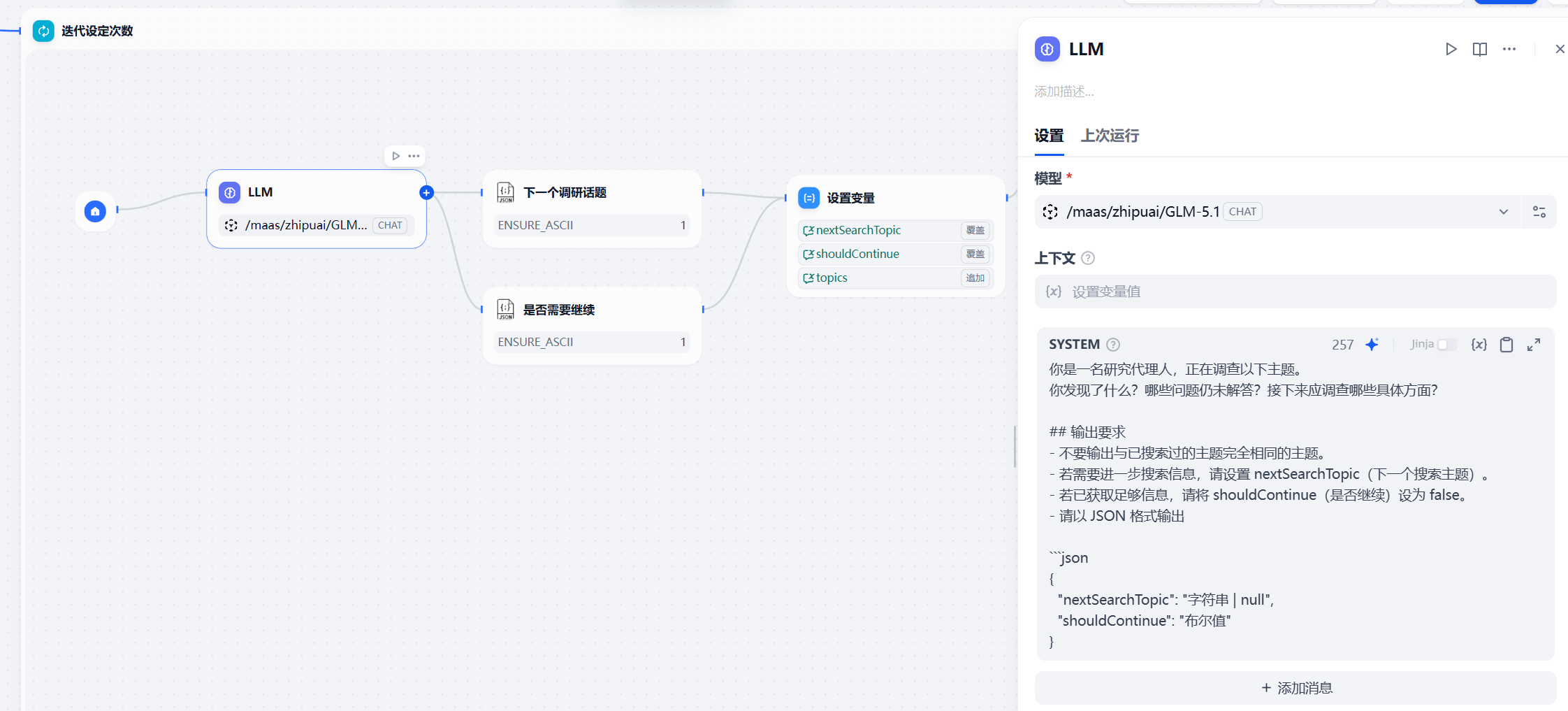
GLM-5.1 handles intent decomposition and final conclusion distillation
In Dify, you can connect to GLM-5.1 provided by the Lanyun MaaS platform through an OpenAI-Compatible interface. The model first decomposes a large question into searchable instructions, then compresses the multi-round evidence into a structured analytical conclusion.
prompt = {
"role": "system",
"content": "You are a financial research assistant. Break the question into searchable sub-questions and propose the search direction for the next round." # Explain the model's role
}The purpose of this kind of system prompt is to shift the model from directly answering the question to first generating a retrieval strategy.
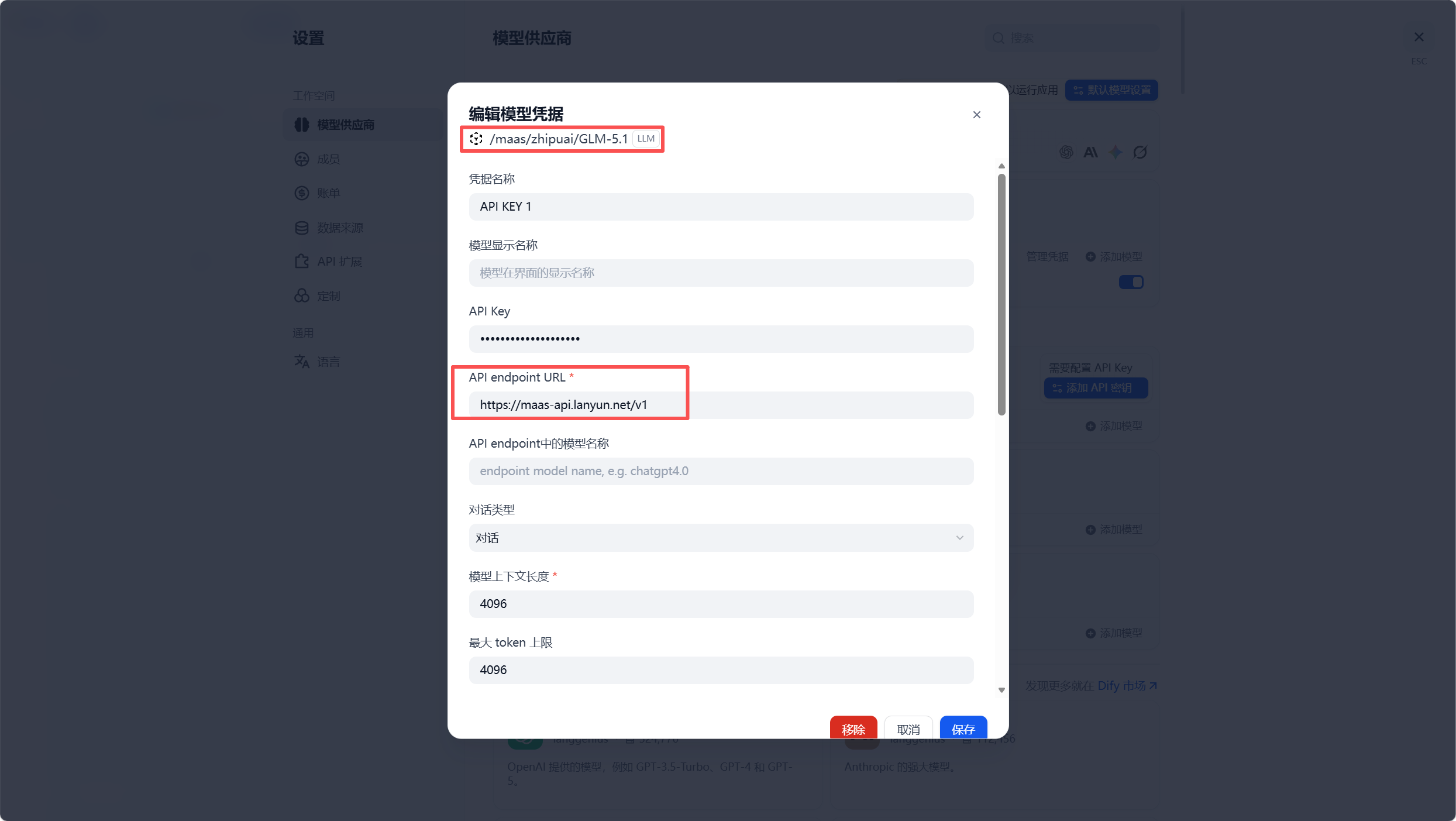 AI Visual Insight: This diagram shows the model provider configuration interface. The key technical point is that GLM-5.1 is mounted into Dify through an OpenAI-compatible interface, allowing the workflow to preserve platform orchestration while reusing external MaaS model capabilities.
AI Visual Insight: This diagram shows the model provider configuration interface. The key technical point is that GLM-5.1 is mounted into Dify through an OpenAI-compatible interface, allowing the workflow to preserve platform orchestration while reusing external MaaS model capabilities.
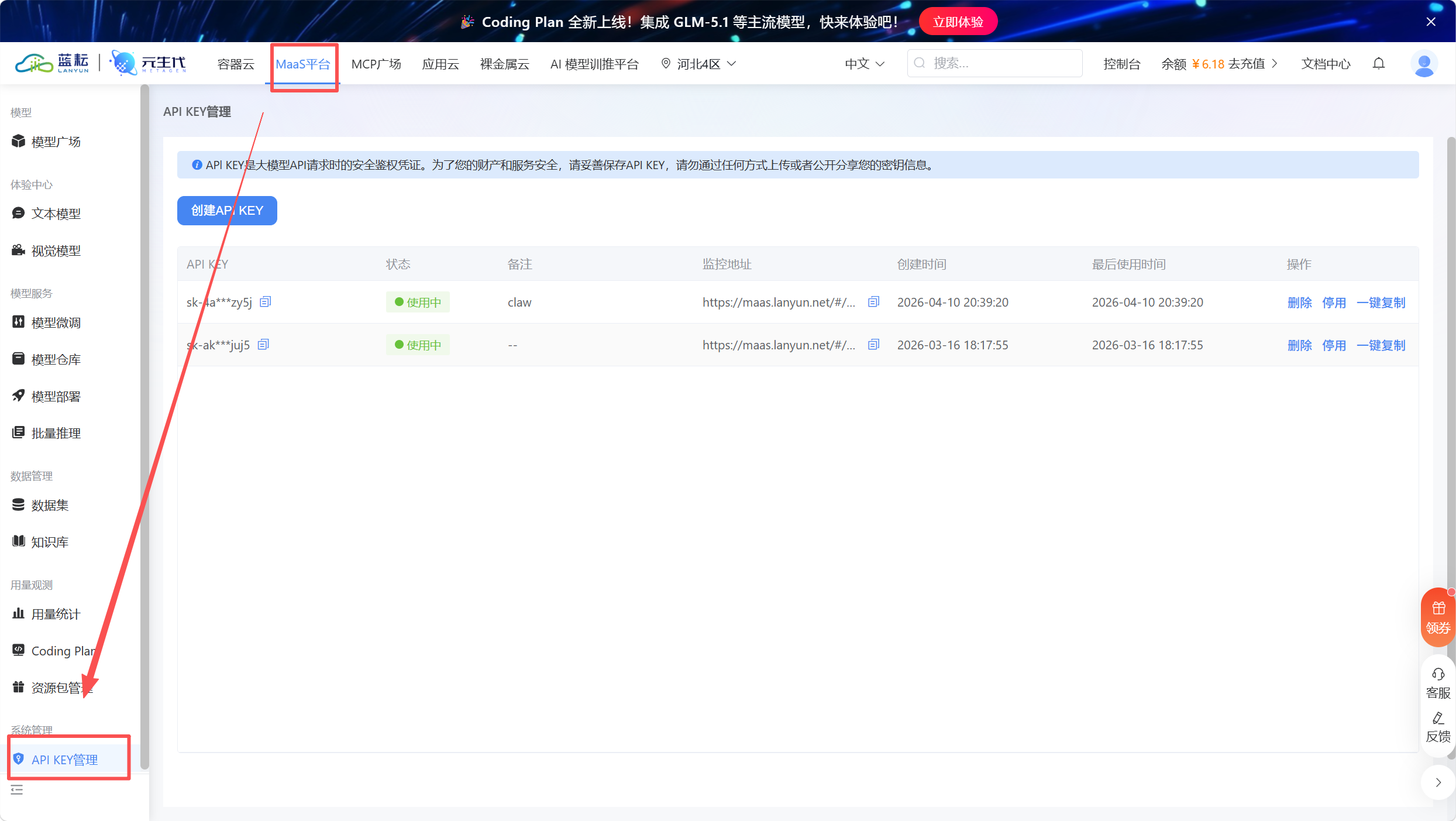 AI Visual Insight: This diagram shows where API key management is located, indicating that the integration barrier is low. Once the key is configured, Dify can invoke the external reasoning service.
AI Visual Insight: This diagram shows where API key management is located, indicating that the integration barrier is low. Once the key is configured, Dify can invoke the external reasoning service.
Tavily provides high signal-to-noise web discovery and content denoising
Tavily does more than return links. It is designed to provide web summaries and structured results that an agent can consume directly. This matters even more in financial analysis, where ordinary search results are often mixed with forum noise and secondhand commentary.
With Tavily, each iteration can launch retrieval around a narrower and more precise topic, such as a company’s lithium carbonate procurement dependency, alternative supplier announcements, or inventory impairment signals in financial statements.
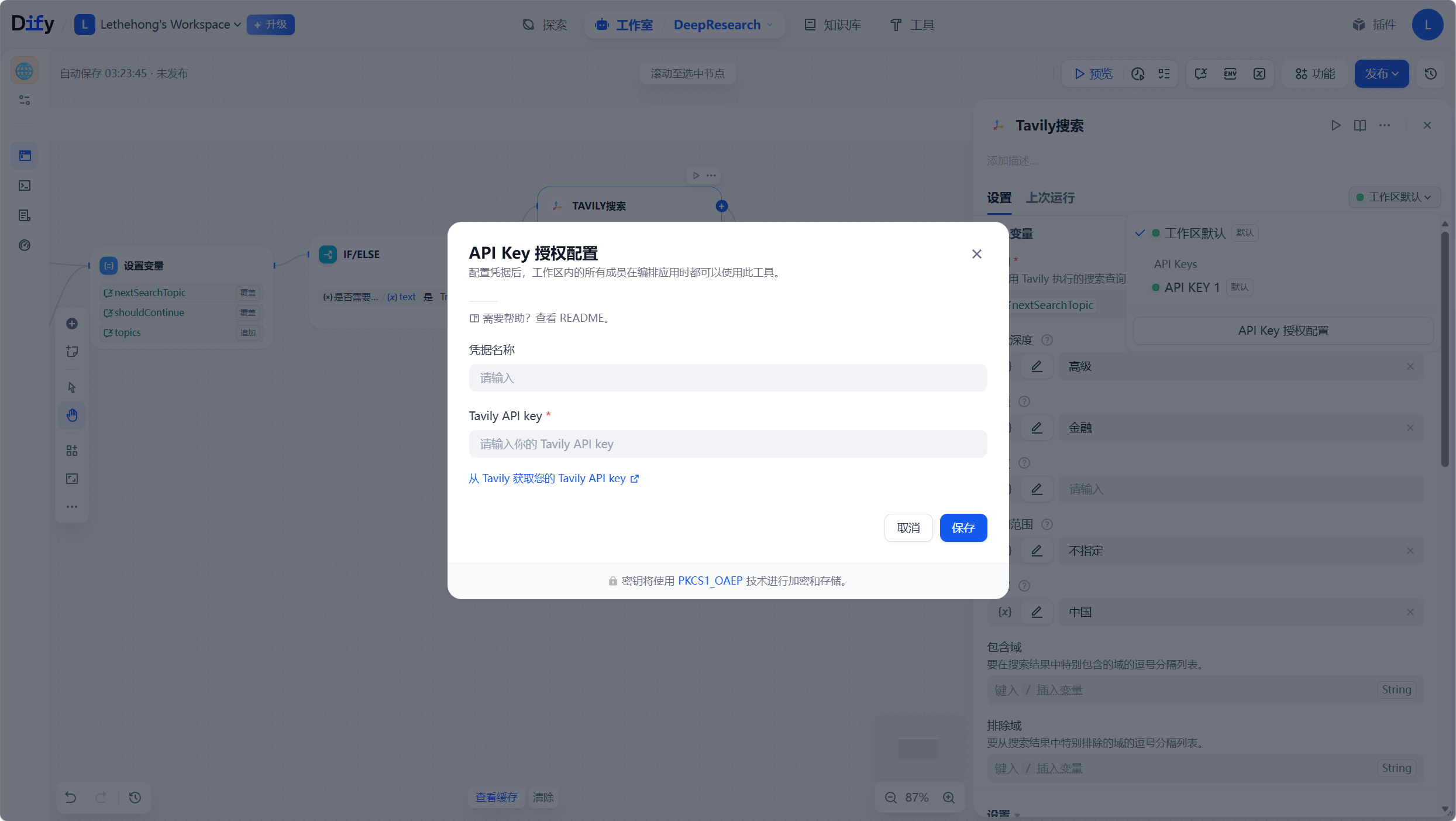 AI Visual Insight: This diagram shows how Tavily is integrated into the workflow. The focus is on turning search behavior into a controllable tool through API keys and parameter configuration, rather than leaving it as an external manual action.
AI Visual Insight: This diagram shows how Tavily is integrated into the workflow. The focus is on turning search behavior into a controllable tool through API keys and parameter configuration, rather than leaving it as an external manual action.
 AI Visual Insight: This diagram indicates that Tavily provides a directly accessible key, reducing the integration cost of bringing a search engine into an agent workflow.
AI Visual Insight: This diagram indicates that Tavily provides a directly accessible key, reducing the integration cost of bringing a search engine into an agent workflow.
The variable aggregation mechanism determines whether the system truly preserves context across rounds
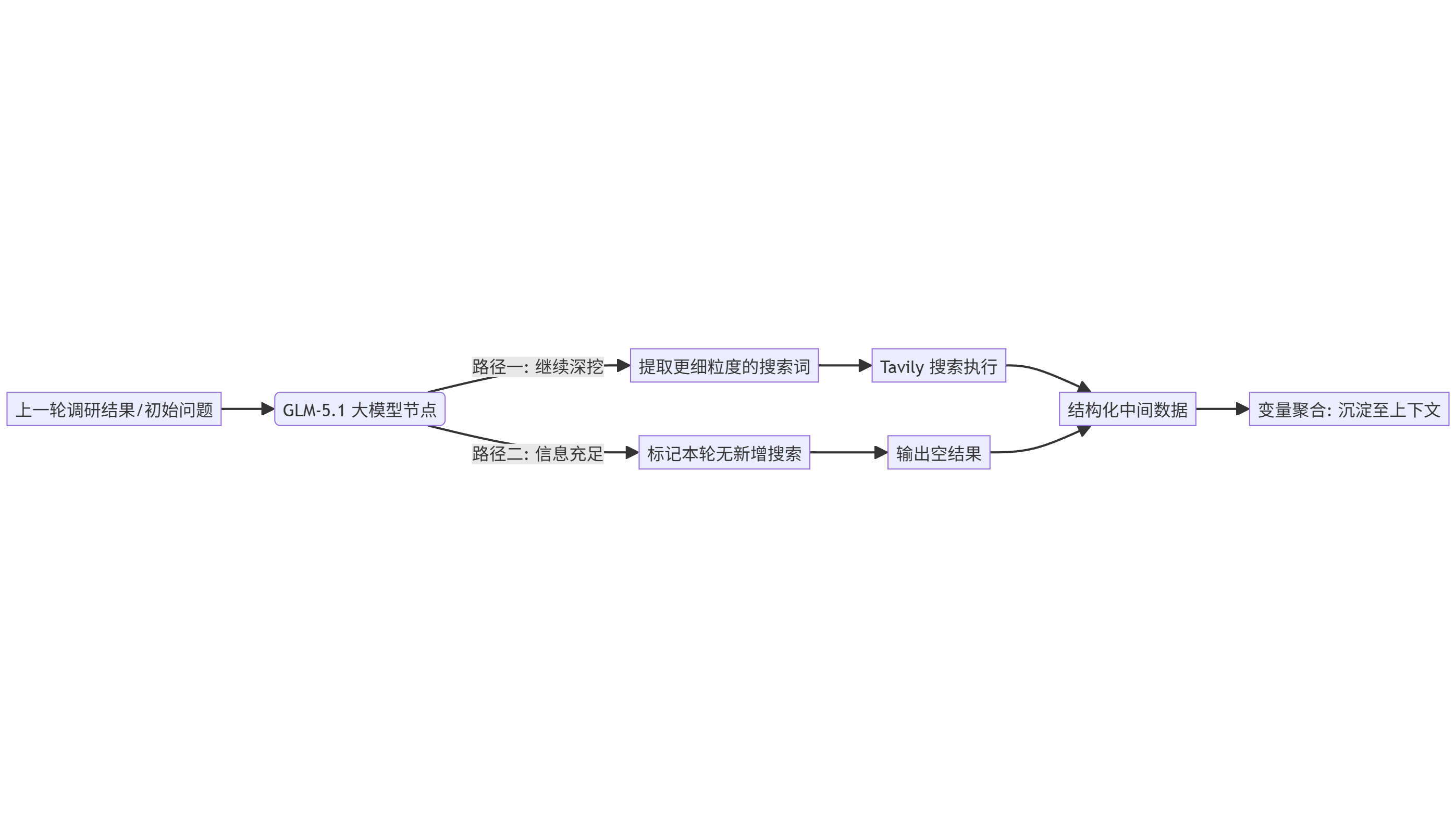
If the retrieval results from each round remain isolated, the system is just running three independent searches. That is not reasoning. The effective design is to concatenate the current round’s result with prior intermediate results, then pass that combined context back to GLM-5.1 so it can decide the next search direction.
This allows the AI to keep moving forward along the evidence it has already uncovered. For example, if the first round identifies battery supply risk, the second round can investigate raw material prices and alternative suppliers, and the third round can validate whether financial statements already show impairment or inventory anomalies.
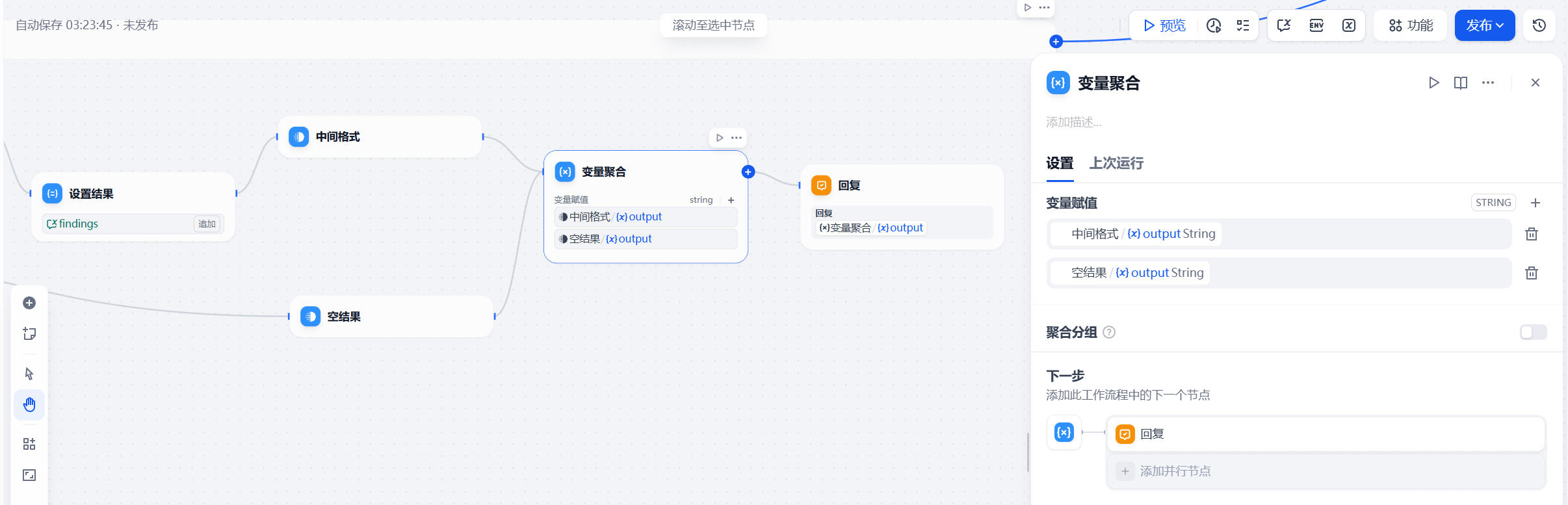 AI Visual Insight: This diagram shows the multi-round result aggregation logic, explaining how the system preserves the investigation trail through variable concatenation and prevents the model from reasoning from scratch in every round.
AI Visual Insight: This diagram shows the multi-round result aggregation logic, explaining how the system preserves the investigation trail through variable concatenation and prevents the model from reasoning from scratch in every round.
def merge_context(history: str, current: str) -> str:
history = history or "" # Handle empty history safely
return history + "\n\n" + current # Append this round's retrieval result to build continuous contextThe purpose of this logic is to accumulate an evidence chain so the model can see what is already known and what it should investigate next.
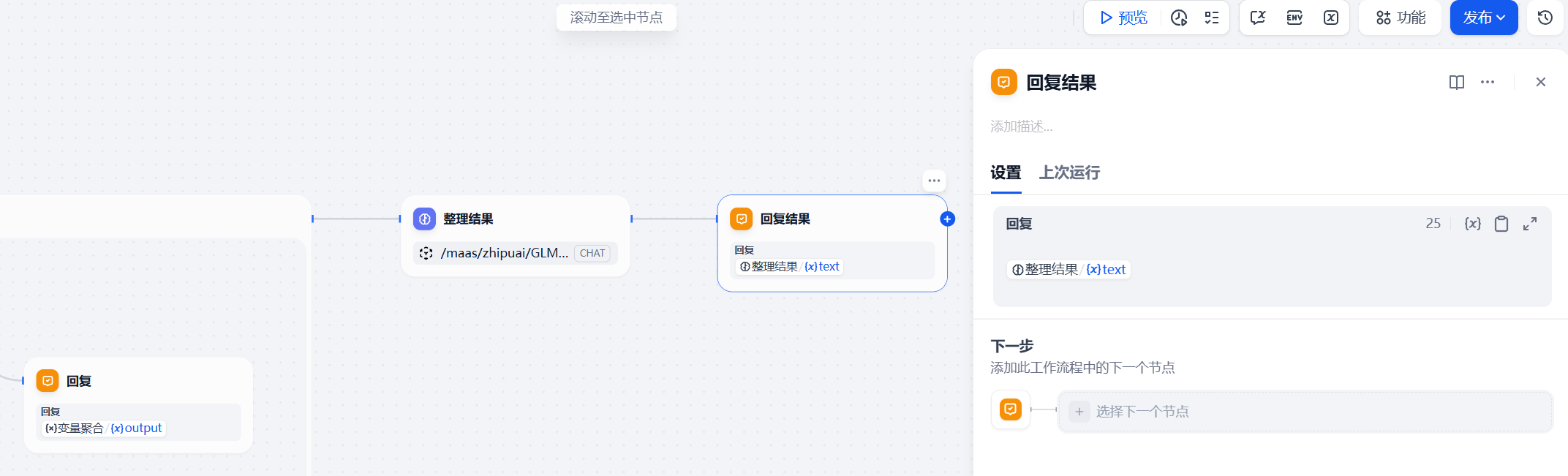 AI Visual Insight: This diagram shows the closing node after iteration completes. Once the configured depth is reached, the system exits the loop and uses a final LLM node to organize all multi-round material into a readable report.
AI Visual Insight: This diagram shows the closing node after iteration completes. Once the configured depth is reached, the system exits the loop and uses a final LLM node to organize all multi-round material into a readable report.
The final output stage must shift from raw evidence accumulation to structured investment-research expression
After multi-round retrieval finishes, what you have is still a raw evidence set, not a report. The last LLM node should play the role of an editor: remove duplication, validate the logic, rearrange the material into an investment research framework, and preserve key source links for manual review.
A recommended output structure is: observed anomaly, core contradiction, cross-validation, potential risk, and conclusion with recommendations. This format works well for analysts and also makes it easier to connect downstream systems such as RAG, financial statement databases, or enterprise knowledge graphs.
 AI Visual Insight: This diagram shows the textual shape of the final report, reflecting that the system has already moved beyond raw retrieval fragments into readable analytical conclusions.
AI Visual Insight: This diagram shows the textual shape of the final report, reflecting that the system has already moved beyond raw retrieval fragments into readable analytical conclusions.
 AI Visual Insight: This diagram shows how multidimensional evidence is integrated in the final expression, emphasizing that the conclusion is not a retelling of a single news item but a judgment built on multi-source cross-validation.
AI Visual Insight: This diagram shows how multidimensional evidence is integrated in the final expression, emphasizing that the conclusion is not a retelling of a single news item but a judgment built on multi-source cross-validation.
 AI Visual Insight: This diagram shows that the final output has report-like characteristics and can directly support research, risk control, or investment decision support scenarios.
AI Visual Insight: This diagram shows that the final output has report-like characteristics and can directly support research, risk control, or investment decision support scenarios.
The core value of this solution lies in controlled iteration rather than one-shot LLM answers
It combines Dify’s workflow orchestration, GLM-5.1’s task decomposition ability, and Tavily’s high-quality retrieval into an interpretable financial research agent. Compared with single-turn Q&A, it more closely resembles how real analysts work.
As a next step, you can integrate financial statement APIs, disclosure databases, and enterprise knowledge graphs to connect public web signals with structured financial data and build a more complete financial research infrastructure.
FAQ structured Q&A
1. Why not use a regular search engine and let an LLM summarize the results directly?
Regular search engines return many links, but they also introduce a lot of noise. Once the first round goes off topic, correction becomes difficult. Tavily is better suited for agent scenarios because it provides higher signal-to-noise results, while the iterative mechanism allows the workflow to self-correct round by round.
2. What is the best value for depth?
In most cases, 3 rounds provide the best balance between cost and effectiveness. If the problem requires cross-validation across supply chains, policy, and financial statements, you can increase it to 4 or 5 rounds, but you should also control token usage and API cost accordingly.
3. Is this workflow only suitable for financial analysis?
No. It works for any scenario that requires decomposition, retrieval, aggregation, and summarization, such as industry research, competitive analysis, policy intelligence, and enterprise knowledge Q&A. You only need to replace the prompts and data sources.
[AI Readability Summary]
This article reconstructs a financial analysis workflow based on Dify, Lanyun GLM-5.1, and Tavily. Through depth control, iterative retrieval, context aggregation, and final distillation, it upgrades AI from a one-shot summarizer into a research assistant with multi-round reasoning and traceability.