OpenClaw’s core value is not just connecting to large language models. It turns an AI assistant into a sustainable engineering partner through SOUL.md, USER.md, AGENTS.md, and MEMORY.md. This approach solves three common pain points: repeatedly re-explaining preferences, losing context across sessions, and dealing with inconsistent behavior. Keywords: OpenClaw, personality engineering, long-term memory.
Technical specification snapshot
| Parameter | Description |
|---|---|
| Project Name | OpenClaw |
| Primary Language | TypeScript / JavaScript (ecosystem side), Markdown configuration |
| Interaction Protocol | OpenAI-compatible API, IM channel integration |
| GitHub Stars | 315K+ (as stated in the original source) |
| Deployment Methods | Tencent Cloud Lighthouse template, manual Linux installation |
| Core Dependencies | Node.js, systemd, model API, Markdown configuration files |
| Key Files | SOUL.md, USER.md, AGENTS.md, MEMORY.md, TOOLS.md |
OpenClaw’s key capability is turning prompts into a personality system
OpenClaw is not a single-turn chat tool. It is a deployable Agent framework that can connect to instant messaging platforms and preserve collaboration habits over the long term. The real challenge is not installation. The real challenge is making the AI maintain consistent behavior over time.
 AI Visual Insight: The image shows an OpenClaw-related interface or system entry point. It highlights that the framework is built around visual management and configuration-driven workflows, making it suitable for orchestrating models, memory, and channel capabilities in one place instead of staying inside a single chat window.
AI Visual Insight: The image shows an OpenClaw-related interface or system entry point. It highlights that the framework is built around visual management and configuration-driven workflows, making it suitable for orchestrating models, memory, and channel capabilities in one place instead of staying inside a single chat window.
Many developers fail not because the model is weak, but because they put every rule into one file. The result is that personality, collaboration constraints, and environment information contaminate each other. Once that happens, unstable AI behavior is inevitable.
The three-layer architecture makes personality engineering work
A practical approach is to split configuration into three layers: the personality layer defines who the AI is, the collaboration layer defines how it works with you, and the environment layer defines where the AI operates and which tools it can call. This separation is the foundation of maintainability.
| Layer | Files | Purpose | Change Frequency |
|---|---|---|---|
| Personality Layer | SOUL.md, IDENTITY.md |
Define personality, values, and expression style | Low |
| Collaboration Layer | USER.md, AGENTS.md |
Define working rules and memory protocols | Medium |
| Environment Layer | TOOLS.md, HEARTBEAT.md, MEMORY.md |
Define tools, tasks, and long-term memory | High |
## Splitting principles
- Put personality in SOUL.md # Define the behavioral baseline
- Put preferences in USER.md # Define your working habits
- Put loading rules in AGENTS.md # Control context assembly
- Put long-term indexes in MEMORY.md # Keep it as an index, not a document dumpThis configuration turns vague prompt tuning into modular governance.
Your Tencent Cloud deployment path determines startup cost
If your goal is rapid validation, the OpenClaw template on Tencent Cloud Lighthouse is the most beginner-friendly option. It packages the runtime, management panel, and initial onboarding flow so you can get online in minutes.
 AI Visual Insight: The image shows a cloud server purchase page or application template selection screen. The key point is that OpenClaw is packaged as a prebuilt image, so users can initialize the environment by simply selecting the AI Agent template, significantly reducing the Linux operations barrier.
AI Visual Insight: The image shows a cloud server purchase page or application template selection screen. The key point is that OpenClaw is packaged as a prebuilt image, so users can initialize the environment by simply selecting the AI Agent template, significantly reducing the Linux operations barrier.
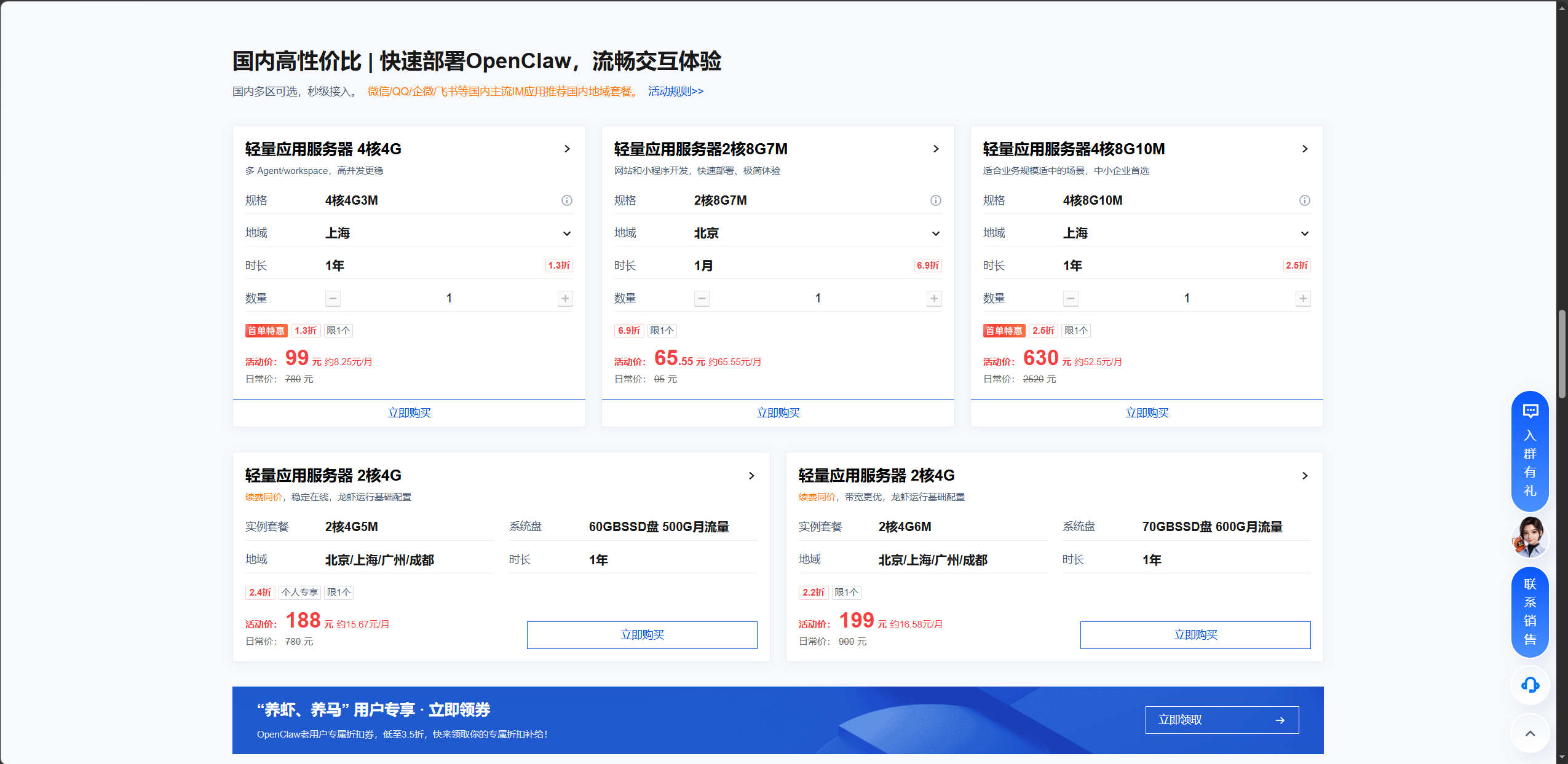 AI Visual Insight: The image presents server sizing or billing options, showing the tradeoff between CPU, memory, and budget when deploying OpenClaw. It suggests that 2 vCPU and 4 GB RAM is a safer production starting point, while 2 vCPU and 2 GB RAM is closer to a barely sufficient test setup.
AI Visual Insight: The image presents server sizing or billing options, showing the tradeoff between CPU, memory, and budget when deploying OpenClaw. It suggests that 2 vCPU and 4 GB RAM is a safer production starting point, while 2 vCPU and 2 GB RAM is closer to a barely sufficient test setup.
If you already have a Linux server, you can also install it manually. The essentials are simple: make sure Node.js, systemd user services, and network access are available.
# Official one-line installation script
curl -fsSL https://openclaw.ai/install.sh | bash
# Or install the Chinese distribution with npm
npm install -g openclaw-cn@latest
openclaw-cn onboard --install-daemon # Install and register the daemonThese commands perform the base installation and register the background service for OpenClaw.
Model and channel configuration determine whether the system is truly usable
After you enter the management panel, configure the model provider first. The original article mentions options such as the NVIDIA API, Alibaba Bailian Qwen3.5-Plus, and Tencent Cloud TokenHub, which map to free trials, cost efficiency, and ecosystem integration respectively.
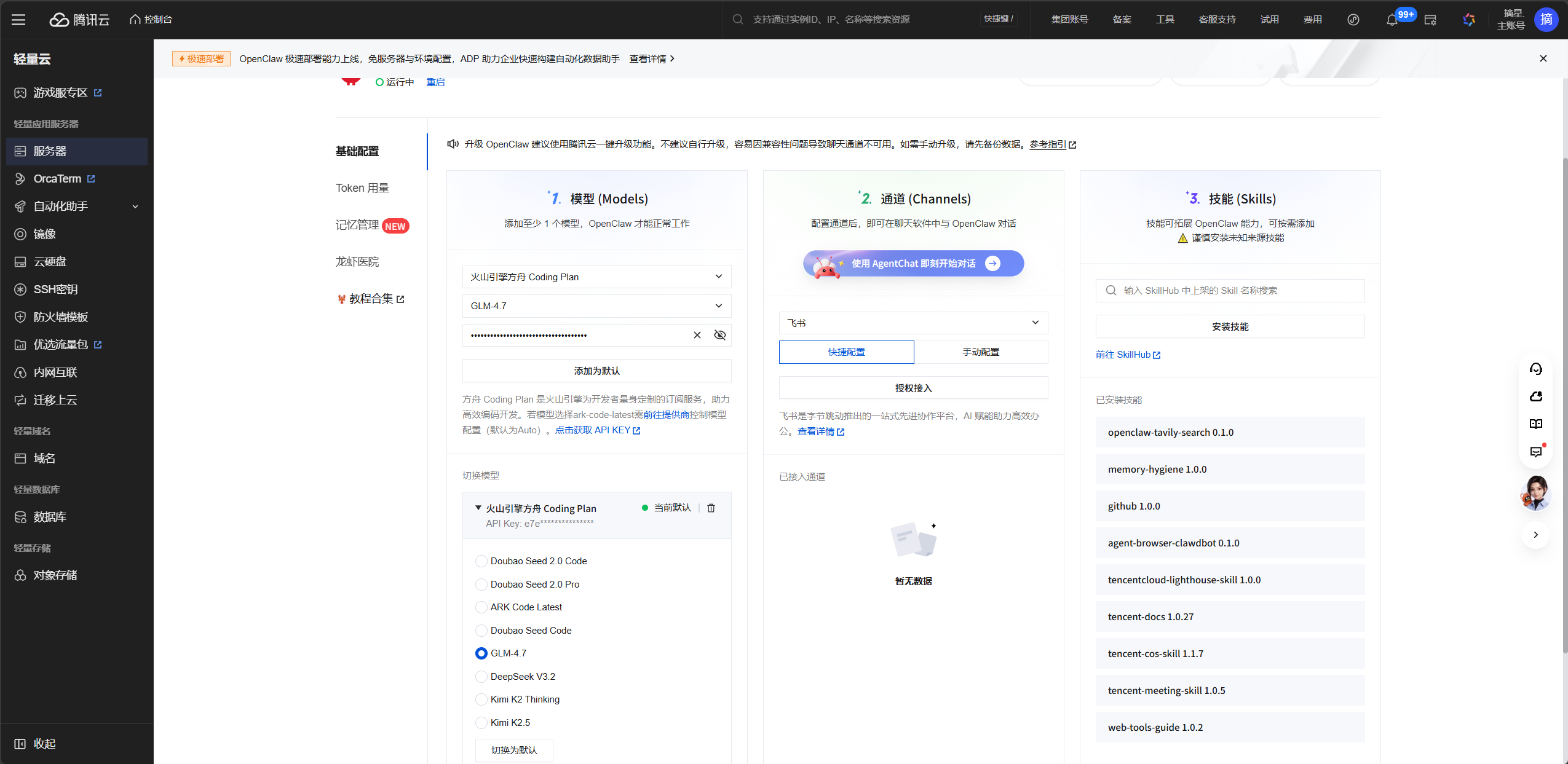 AI Visual Insight: The image shows a model configuration panel or provider selection area. It demonstrates that OpenClaw abstracts the underlying model as a pluggable
AI Visual Insight: The image shows a model configuration panel or provider selection area. It demonstrates that OpenClaw abstracts the underlying model as a pluggable provider + model structure, allowing developers to swap inference backends through a unified gateway without rewriting upper-layer personality configuration.
{
"models": {
"providers": {
"nvidia": {
"baseUrl": "https://integrate.api.nvidia.com/v1",
"apiKey": "nvapi-your-API-Key",
"api": "openai-completions",
"models": [
{
"id": "moonshotai/kimi-k2.5",
"name": "Kimi-K2.5",
"contextWindow": 200000,
"maxTokens": 8192
}
]
}
}
}
}This configuration registers a custom model provider in OpenClaw.
For IM channels such as Feishu, QQ, and Telegram, deployment region also affects connectivity. Use domestic regions first for China-based collaboration platforms, and overseas nodes such as Tokyo or Singapore first for global messaging platforms.
SOUL.md must describe behavior, not vague identity
Many default templates include only one sentence such as “You are a helpful assistant,” which provides almost no meaningful constraint. An effective SOUL.md should include at least three parts: Core Truths, Boundaries, and Vibe. These define principles, limits, and style.
# Soul Configuration
## Core Truths
- You are a pragmatic engineering assistant and should prioritize actionable solutions
- Identify risks proactively instead of waiting for the user to ask
- Communicate in Chinese while keeping technical terms in English
## Boundaries
- Do not modify code you have not read
- Confirm before taking irreversible actions
- Clarify ambiguous requirements before actingThis template establishes a stable and verifiable personality baseline.
USER.md builds stable working alignment instead of repeated explanations
If SOUL.md constrains the AI’s general behavior, USER.md should describe your personalized working style: language stack, naming preferences, commit conventions, and communication taboos. In practice, defining what not to do is often more effective than describing an ideal style.
# User Profile
## Preferences
- Prefer a functional style and avoid class inheritance chains
- Use camelCase for variables
- Write commit messages in Chinese: module-name: brief change summary
## Taboos
- Do not use emoji
- Do not rewrite code that was not requested for modification
- Do not pad responses with politeness fillerThis template turns personal coding habits into a reusable collaboration protocol.
AGENTS.md determines whether the memory system actually works
The core value of AGENTS.md is defining what loads at startup, when retrieval happens during conversation, and how information is flushed before compaction. If you ignore this file, SOUL.md and MEMORY.md may exist, but they will not reliably enter the context.
# Agent Configuration
## Memory Protocol
### Startup load order
1. SOUL.md
2. USER.md
3. MEMORY.md
4. TOOLS.md
### Conversation rules
- Retrieve relevant memory before answering
- Proactively suggest writing new key decisions to memoryThis configuration defines both context assembly order and memory retrieval rules.
Context compaction is a hidden risk that many teams ignore. Once the conversation grows too long, the system may trigger compaction. Without a pre-write mechanism, previously agreed API naming, pending tasks, and risk judgments can disappear.
### Pre-compaction Flush
- Write key decisions to MEMORY.md before compaction
- Save newly added preferences and taboos from the current round
- Record a summary of unfinished tasks
- reserveTokensFloor: 40000 # Reserve enough tokens to complete the flushThis configuration creates a safety net for critical context before compaction happens.
MEMORY.md should be an index, not a warehouse
A common long-term memory mistake is stuffing all content into one MEMORY.md file. The correct approach is to treat it as a directory: store only links, topics, and one-line descriptions there, then split detailed content into separate memory files.
# Memory Index
## Projects
- [Mall Refactor](memory/mall-refactor.md) — Migration from React to Next.js
- [Payment Module](memory/payment.md) — Dual-channel constraints and concurrency locks
## User Preferences
- [Code Style](memory/code-style.md) — ESLint and naming conventions
- [Git Conventions](memory/git-convention.md) — Branching and commit strategyThis template builds an extensible index for long-term memory.
Memory search determines whether the AI can actually remember
The original article mentions two approaches: for small-scale scenarios, local hybrid search is enough; for large team knowledge bases, you can connect a QMD backend. Individual developers usually do not need external retrieval infrastructure too early.
If you suspect context issues, run a diagnostic command to inspect the current load state directly.
/context list # Check which files and memory chunks are actually loaded into the current contextThis command helps diagnose why the AI forgot something discussed earlier.
TOOLS.md and HEARTBEAT.md complete environment awareness and automation
TOOLS.md is a good place to store project paths, common commands, migration script entry points, and other environment data, so you do not have to repeat them in every session. HEARTBEAT.md is more suitable for automation checks and scheduled tasks, and it makes more sense after your workflow matures.
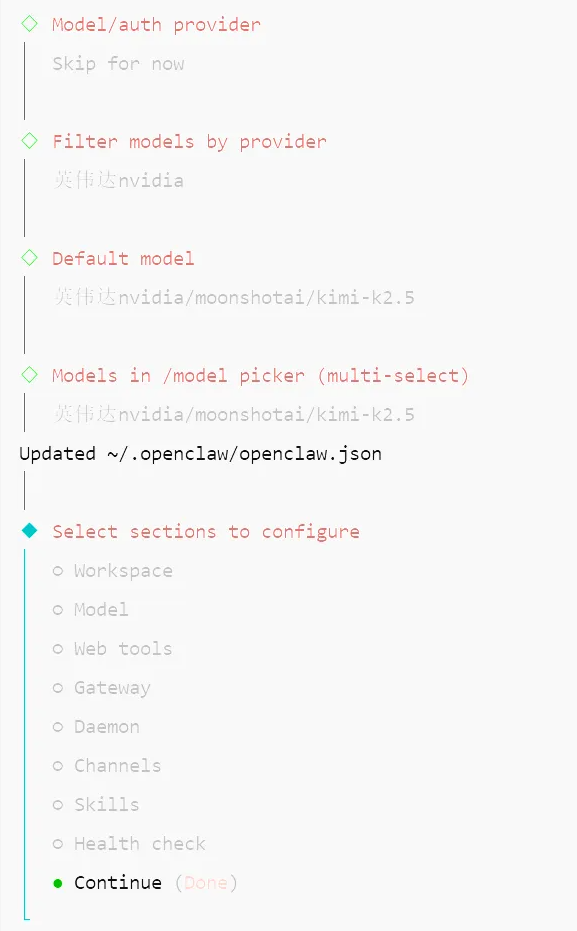 AI Visual Insight: The image shows an interactive installation wizard or initialization flow. It indicates that OpenClaw in QuickStart mode guides users through key parameters such as models, channels, and session persistence, making it a standardized onboarding path.
AI Visual Insight: The image shows an interactive installation wizard or initialization flow. It indicates that OpenClaw in QuickStart mode guides users through key parameters such as models, channels, and session persistence, making it a standardized onboarding path.
 AI Visual Insight: The image shows the process of accessing the management panel through an SSH tunnel or local port forwarding. It demonstrates that even on a headless Linux server, OpenClaw can still provide a browser-based management experience through port mapping.
AI Visual Insight: The image shows the process of accessing the management panel through an SSH tunnel or local port forwarding. It demonstrates that even on a headless Linux server, OpenClaw can still provide a browser-based management experience through port mapping.
Continuous iteration closes the loop in personality engineering
High-quality configuration is never finished in one pass. You improve it by correcting misjudgments, repeated clarification loops, and style drift over time. The most effective method is a lightweight iteration rhythm: update USER.md on the same day you discover a problem, prune stale memory weekly, and check /context list before anything else when behavior looks wrong.
FAQ
Q1: Why does the AI still drift even after I wrote SOUL.md?
A: Usually the issue is not missing content. The problem is often incorrect load order, an overly long SOUL.md that gets truncated, or an AGENTS.md configuration that does not reliably inject it into context. Check the loading chain first, then simplify the rules.
Q2: Why is it not recommended to turn MEMORY.md into a long document?
A: Because its job is indexing. If you pile too much content into it, retrieval precision drops and context contamination increases. A directory-style structure supports both precise loading and long-term maintenance.
Q3: Do solo developers need a vector database or external retrieval right away?
A: Usually not. If you have fewer than 100 memory files, local hybrid search is often sufficient. It is more important to get the file structure, naming, and memory protocol right than to add infrastructure too early.
AI Readability Summary
This article reconstructs OpenClaw personality engineering as a practical system. It covers Tencent Cloud deployment, clear responsibility boundaries for SOUL.md, USER.md, AGENTS.md, and MEMORY.md, protection against memory loss during context compaction, retrieval strategy selection, and a continuous improvement workflow. The goal is to help developers turn a general-purpose Agent into a stable, reusable, and personalized AI assistant.