GPT-Image-2 is OpenAI’s next-generation image model for generative visual production. Its biggest advances focus on precise instruction following, multilingual text rendering, style consistency, and API integration, addressing the long-standing gap between images that look good and images that are actually usable in production. Keywords: GPT-Image-2, image generation API, multilingual rendering.
The technical specification snapshot is straightforward
| Parameter | Details |
|---|---|
| Model name | gpt-image-2 |
| Primary capabilities | Image generation, image editing, multilingual text rendering, visual reasoning |
| Access points | ChatGPT, Codex, OpenAI API |
| Supported aspect ratios | Approximately 3:1 to 1:3 |
| Maximum output | Up to 2K in the API |
| Knowledge cutoff | Through December 2025 |
| Official pricing summary | Image input $8, cached input $2, output $30; text input $5, cached input $1.25, output $10 |
| Core dependencies | HTTPS, JSON, OpenAI Images API |
| Source article signal | The original CSDN article shows roughly 986 views |
GPT-Image-2 has evolved from an image generation tool into a visual production system
The key change in GPT-Image-2 is not just that it creates better-looking images. It moves model capability closer to real production workflows. It can handle complex compositions, small text, UI elements, and style constraints more reliably, making the output feel closer to design assets that teams can actually deliver.
 AI Visual Insight: This hero image uses a cover-style layout for the model overview page and emphasizes three core themes: feature overview, usage methods, and API integration. It signals that the model is positioned not only for creative generation, but also for developer integration and engineering-focused workflows.
AI Visual Insight: This hero image uses a cover-style layout for the model overview page and emphasizes three core themes: feature overview, usage methods, and API integration. It signals that the model is positioned not only for creative generation, but also for developer integration and engineering-focused workflows.
The model improvements concentrate on four dimensions
First, instruction following is more precise, allowing the model to map structure, object relationships, and text content from the prompt into the image more accurately. Second, text rendering is significantly stronger, especially for posters, infographics, and interface mockups. Third, style fidelity is more stable, reducing the awkward “obviously AI-generated” look. Fourth, the model supports visual reasoning and sequential multi-image generation in thinking mode.
import requests
api_key = "YOUR_API_KEY" # Replace with your API key
url = "https://api.openai.com/v1/images/generations"
payload = {
"model": "gpt-image-2", # Specify the image model
"prompt": "Generate an infographic poster with a Chinese title and data icons in a technology-blue style", # Describe the target image
"size": "1024x1024" # Set the output size
}
headers = {
"Authorization": f"Bearer {api_key}", # Authentication header
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json()) # Print the API responseThis code demonstrates the most basic and cost-efficient way to call GPT-Image-2 for image generation.
GPT-Image-2 delivers a clear advantage in text-heavy and multilingual scenarios
The source material repeatedly emphasizes one fact: previous image models often distorted complex text outside English, while GPT-Image-2 closes that gap in a meaningful way. It supports non-Latin scripts such as Chinese, Japanese, Korean, Hindi, and Bengali, and it can treat text as part of the image structure rather than as decorative content layered on top.
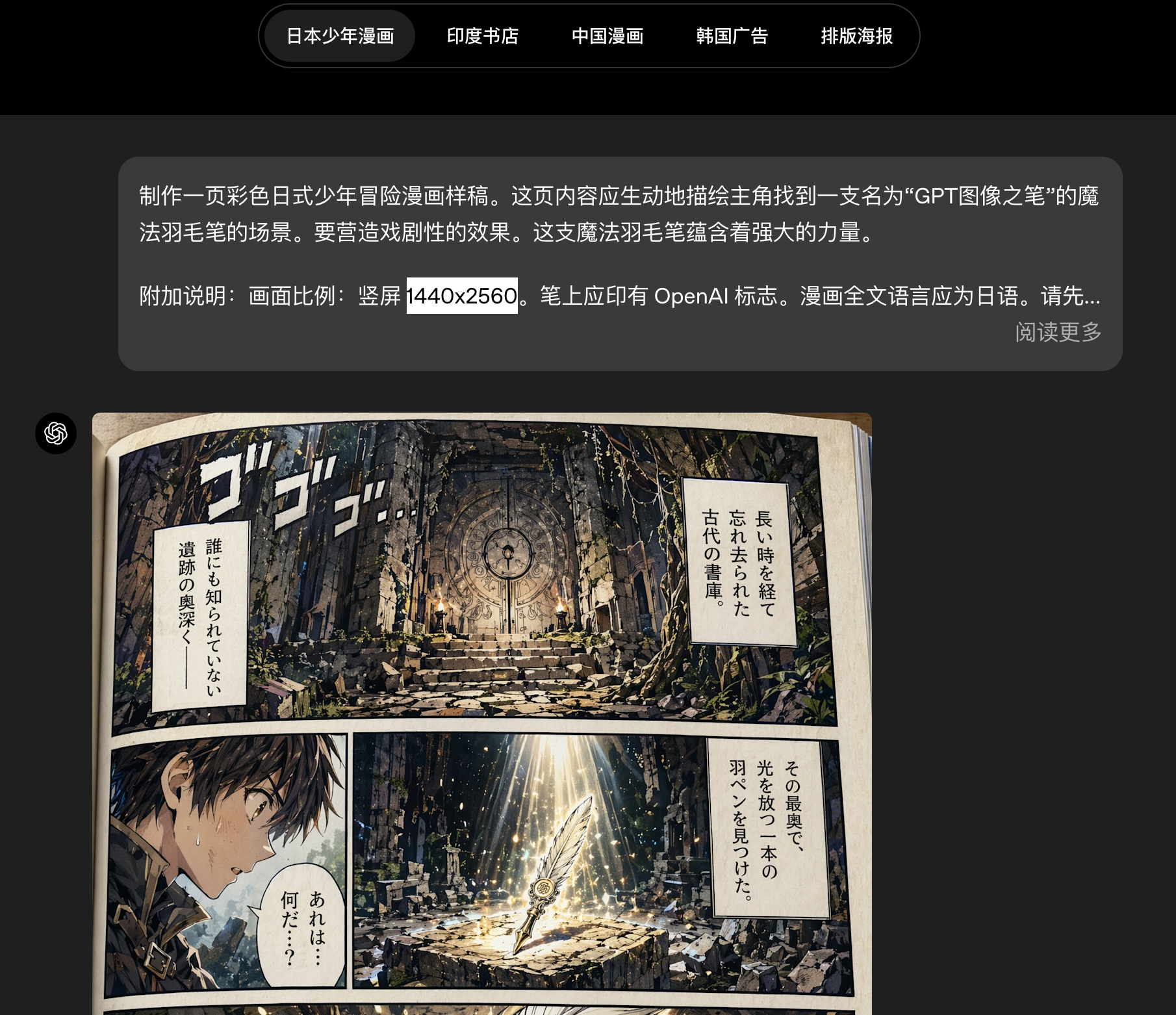 AI Visual Insight: This image corresponds to a multilingual rendering example. It highlights the model’s ability to balance text readability, glyph stability, and visual hierarchy within a layout, which makes it well suited for global marketing assets and localized explanatory graphics.
AI Visual Insight: This image corresponds to a multilingual rendering example. It highlights the model’s ability to balance text readability, glyph stability, and visual hierarchy within a layout, which makes it well suited for global marketing assets and localized explanatory graphics.
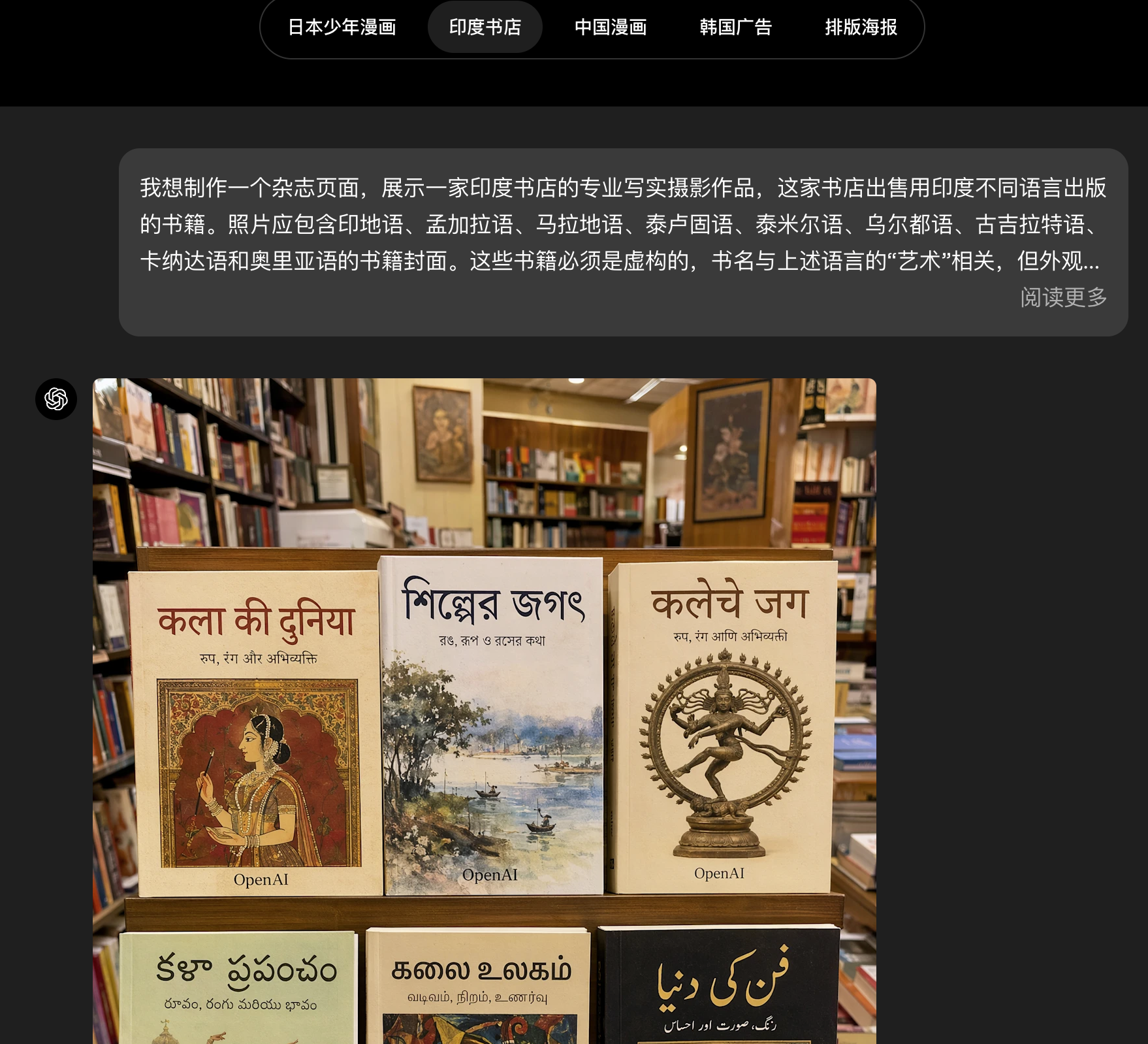 AI Visual Insight: This example emphasizes layout stability for non-English text against complex backgrounds. It is typically used to validate whether an image model can embed real, usable text rather than merely producing character-like textures.
AI Visual Insight: This example emphasizes layout stability for non-English text against complex backgrounds. It is typically used to validate whether an image model can embed real, usable text rather than merely producing character-like textures.
This makes it better suited for global content production
When design assets must satisfy brand consistency, language localization, and cross-platform distribution at the same time, traditional workflows often require repeated text reflow in design tools. GPT-Image-2 shortens the path from concept to publishable asset by improving text accuracy directly in the generated image.
Style control and realism have reached a practical threshold
The material showcases multiple style samples, including photorealism, cinematic stills, comics, and pixel art. That suggests the model has moved beyond simply mimicking style labels and is beginning to capture texture, lighting, composition, and grain as actual stylistic features. This is a practical upgrade for marketing, game prototyping, and visual storytelling.
 AI Visual Insight: This image represents a photorealistic sample. The key signals usually include consistent skin texture, depth of field, cinematic lighting, and environmental detail, which help validate the model’s texture control in realistic generation.
AI Visual Insight: This image represents a photorealistic sample. The key signals usually include consistent skin texture, depth of field, cinematic lighting, and environmental detail, which help validate the model’s texture control in realistic generation.
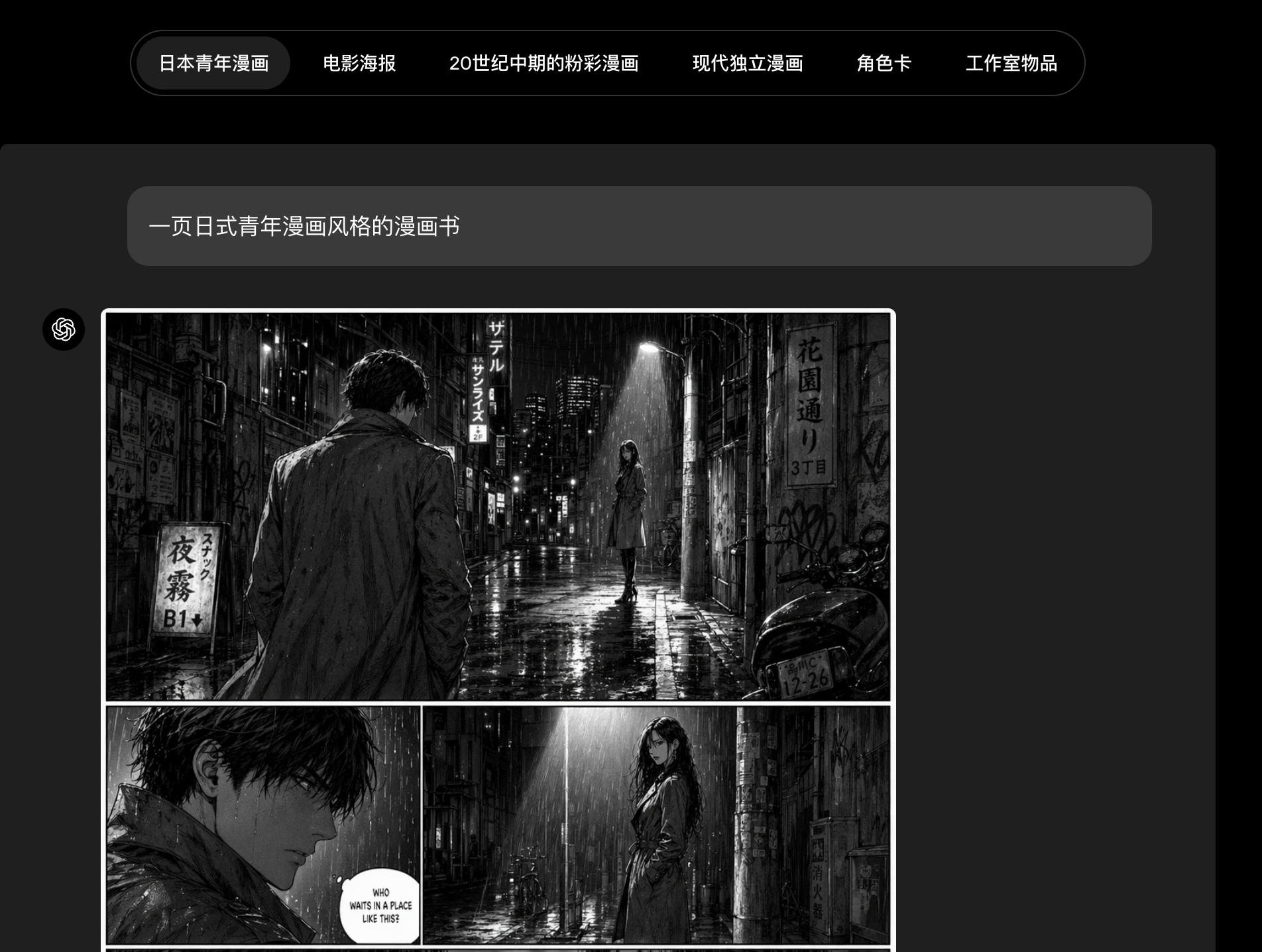 AI Visual Insight: This image corresponds to a stylized output sample and is better suited for observing how consistently the model reproduces a specific visual language, including contour organization, color systems, and simulated material texture.
AI Visual Insight: This image corresponds to a stylized output sample and is better suited for observing how consistently the model reproduces a specific visual language, including contour organization, color systems, and simulated material texture.
curl https://api.openai.com/v1/images/generations \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-image-2",
"prompt": "Generate a cinematic city night poster with a Chinese title",
"size": "1536x1024"
}'This command works well for quickly testing different style prompts in scripts, CI pipelines, or backend services.
Aspect ratio support and thinking mode make batch workflows more complete
GPT-Image-2 supports aspect ratios from 3:1 to 1:3, covering banners, slide decks, posters, mobile screens, and social media graphics. For teams, that means a single concept can be adapted more naturally into multiple delivery sizes instead of relying on post-generation cropping as a workaround.
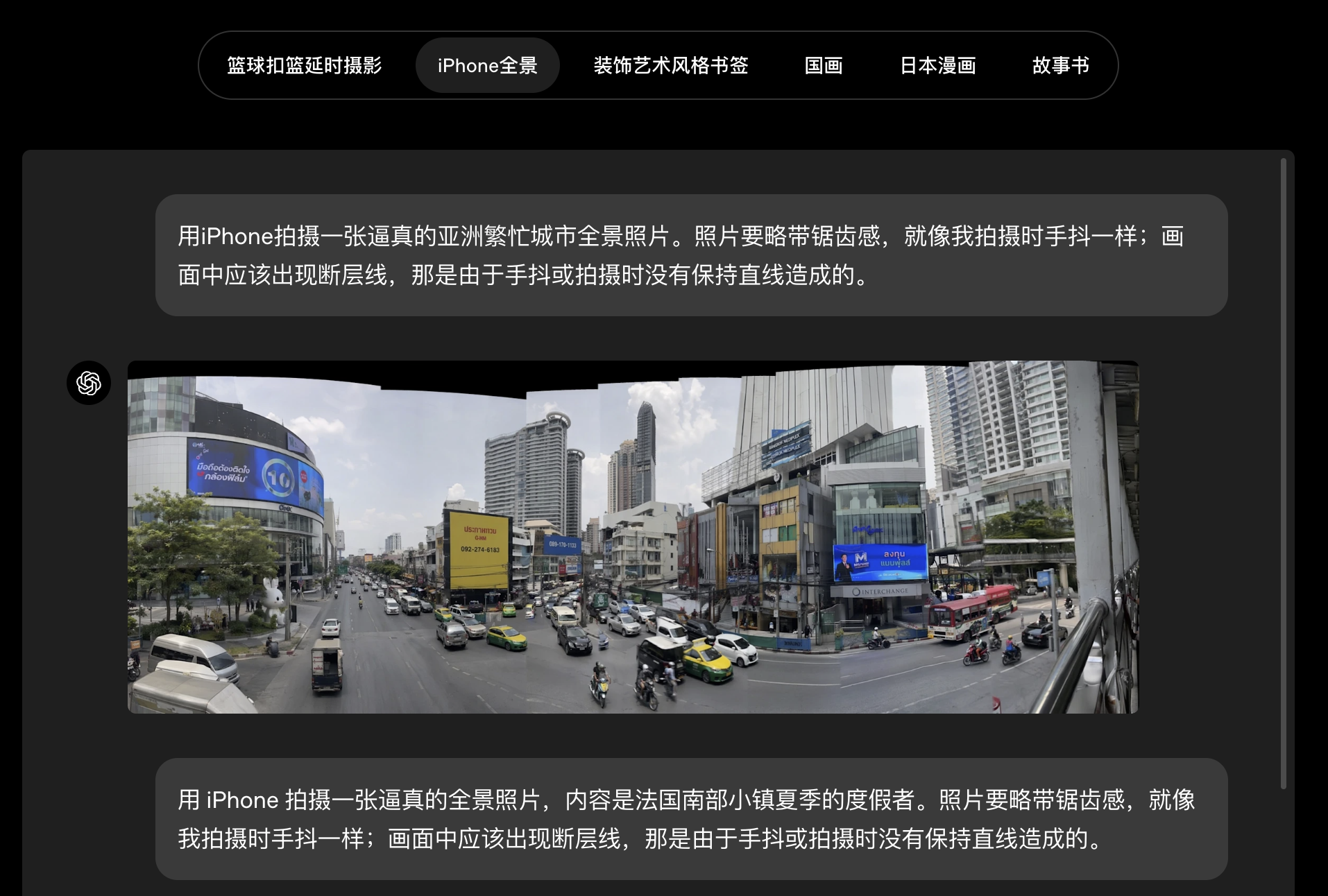 AI Visual Insight: This image demonstrates multi-aspect-ratio output. The core technical signal is that the main subject can be re-composed as the canvas changes, rather than simply cropped, which is useful for generating both landscape promotional graphics and portrait mobile covers from the same concept.
AI Visual Insight: This image demonstrates multi-aspect-ratio output. The core technical signal is that the main subject can be re-composed as the canvas changes, rather than simply cropped, which is useful for generating both landscape promotional graphics and portrait mobile covers from the same concept.
Thinking mode strengthens the visual reasoning pipeline
In ChatGPT thinking mode or pro mode, the model can first understand the task, retrieve real-time information from the web, plan the image structure, and then generate multiple outputs that are distinct yet coherent. The source article notes that up to eight sequential outputs can be requested at once, which is highly valuable for comic storyboards, room redesign concepts, and multilingual poster series.
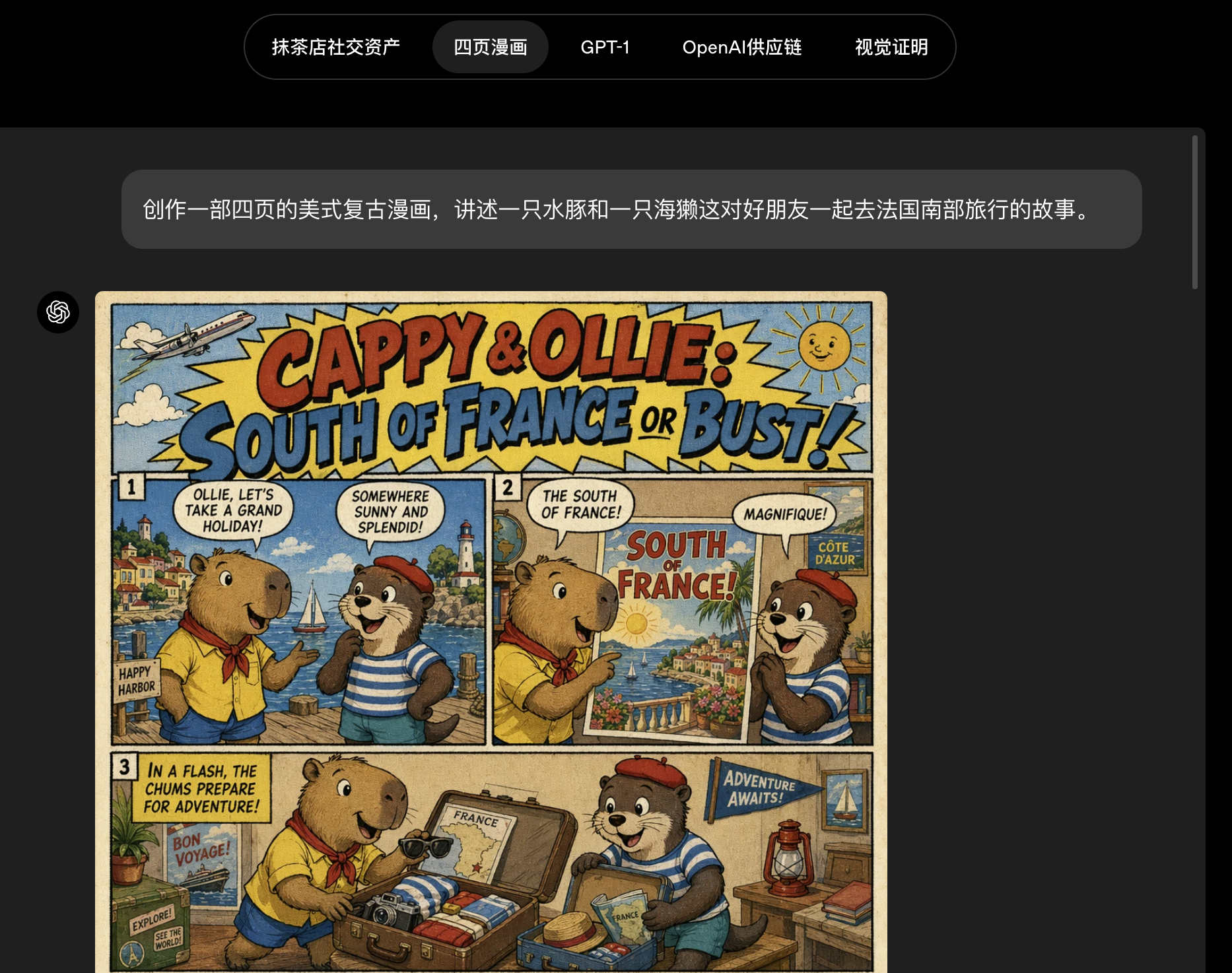 AI Visual Insight: This image corresponds to a sequential multi-image generation scenario. It is typically used to show consistency across characters, objects, and narrative order, indicating that the model now has a degree of project-level visual orchestration capability.
AI Visual Insight: This image corresponds to a sequential multi-image generation scenario. It is typically used to show consistency across characters, objects, and narrative order, indicating that the model now has a degree of project-level visual orchestration capability.
API and Codex integration reduce the cost of turning ideas into products
The source content clearly states that GPT-Image-2 is now available to ChatGPT, Codex, and API users. The value of Codex is that it places image generation and application development in the same workspace, which is useful for UI concept validation, page prototyping, and rapid iteration of marketing pages.
For developers, the API value is even more direct: it allows high-quality image generation to be embedded into localized ads, educational infographics, design tools, creative platforms, and website builder products. The more reliably the model can produce text, layout, and style, the higher its engineering integration value becomes.
import http.client
import json
conn = http.client.HTTPSConnection("api.openai.com")
payload = json.dumps({
"model": "gpt-image-2", # Specify the model
"prompt": "Generate a Chinese product promo image with a title, value propositions, and a button area", # Include text and layout requirements
"size": "1024x1024" # Output resolution
})
headers = {
"Authorization": "Bearer YOUR_API_KEY", # API authentication
"Content-Type": "application/json"
}
conn.request("POST", "/v1/images/generations", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8")) # Print the responseThis example is closer to the official calling style shown in the source material and works well as a backend integration template.
Pricing and limitations make it a better fit for high-value content production
Based on the pricing provided in the source article, image output costs are clearly higher than standard text calls. That makes GPT-Image-2 a better fit for high-value scenarios such as ad creatives, educational diagrams, visual summaries, UI sketches, and localized marketing assets rather than unconstrained, low-quality trial-and-error at massive scale.
At the same time, the model still has clear boundaries. Tasks involving complex physical structures, origami, Rubik’s Cubes, hidden-surface detail, ultra-dense textures, or precise arrow annotations still require human review. Output beyond 2K is also still in a testing phase in the API, so stability is not fully guaranteed.
FAQ provides structured answers
Which business scenarios is GPT-Image-2 best suited for?
It is best suited for scenarios that require text accuracy, style consistency, and multi-size distribution, such as marketing posters, educational infographics, product UI concept art, global localization assets, and visual summaries.
What is the core difference between GPT-Image-2 and a typical image model?
The core difference is usability. It does not just generate images that look acceptable. It handles text, layout, object relationships, and multi-image continuity more reliably, making it closer to a production tool than a demo model.
What should developers prioritize most when integrating the API?
Focus on three things first: cost control to avoid unnecessary retries at high resolution, structured prompting that clearly specifies text, layout, and style constraints, and a human review workflow, especially for charts, labels, and factual visual content.
[AI Readability Summary]
This article systematically breaks down the core capabilities of OpenAI GPT-Image-2, including API pricing, integration methods, and application boundaries. It covers text rendering, multilingual generation, aspect ratio control, visual reasoning, Codex integration, and developer examples to help teams quickly evaluate its real-world value in design, marketing, and product workflows.