LangChain is a development framework that connects large language models to real business applications. Its core value lies in turning LLMs from “good at generating” into workflows that are callable, orchestrated, and production-ready. This article focuses on LLMs, prompt engineering, API integration, and embeddings. Keywords: LangChain, Prompt Engineering, RAG.
The technical specification snapshot provides a quick overview
| Parameter | Details |
|---|---|
| Topic | LangChain fundamentals and AI application development |
| Language | Primarily Python |
| License | Not provided in the source; LangChain commonly uses MIT |
| GitHub Stars | Not provided in the source |
| Core Dependencies | openai, LangChain, vector databases, embedding models |
| Integration Methods | HTTP API / SDK / local inference services |
LangChain serves as the bridge between model capabilities and business workflows
LangChain is not a model itself. It is the middleware layer that connects LLMs, prompts, tools, retrieval, and workflows. The core problem it solves is upgrading one-off conversation capability into orchestrated application capability.
For developers, LLMs are good at generation, while LangChain is good at orchestration. The former handles understanding and output; the latter chains together context, external knowledge, tool usage, and execution steps.
Understanding the boundary between models and LLMs
At its core, a model is a function that learns patterns from data. Traditional models usually specialize in narrow tasks such as classification or prediction. Large language models, by contrast, can handle general language tasks such as question answering, summarization, translation, code generation, and reasoning.
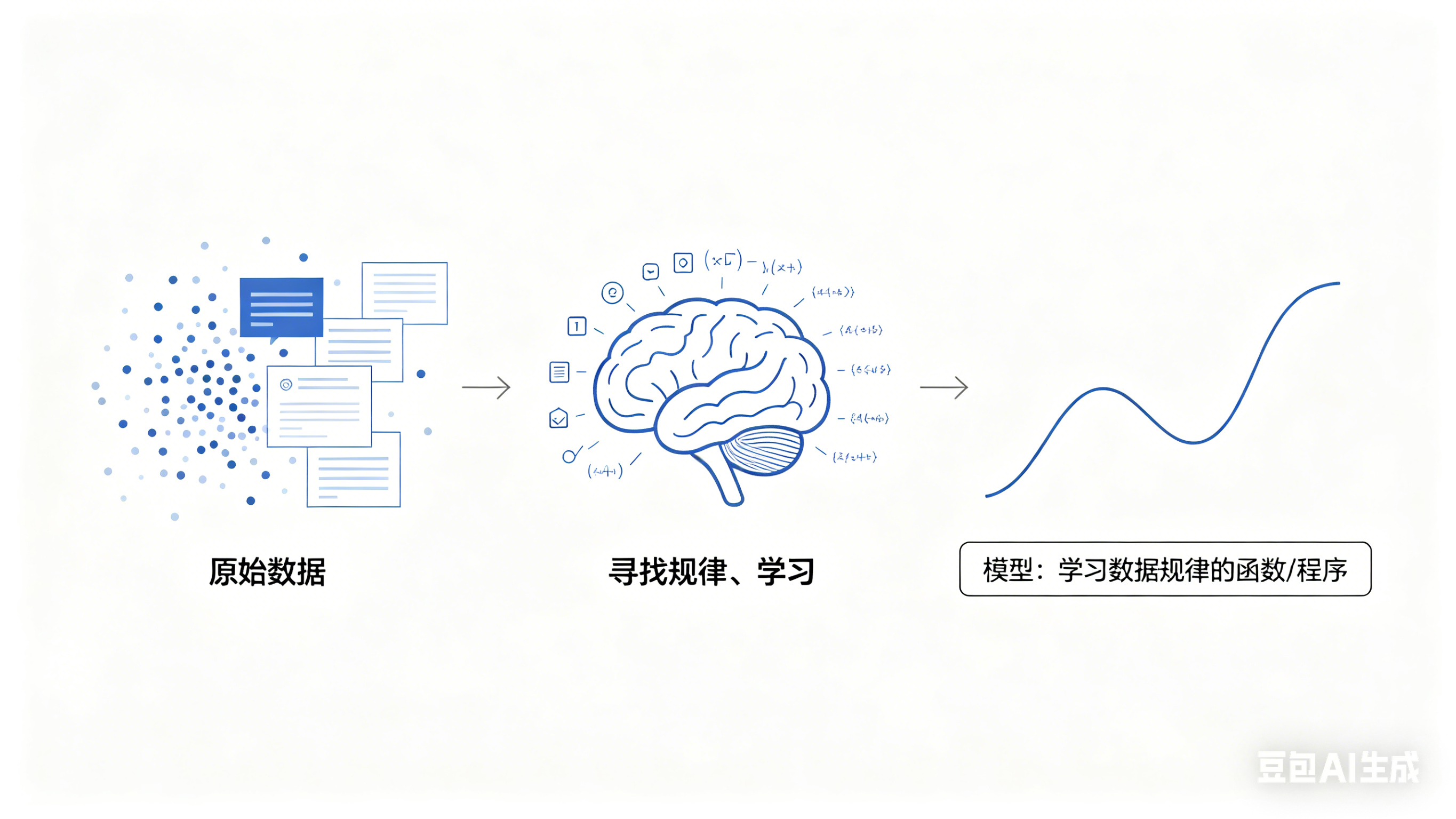 AI Visual Insight: This image illustrates model cognition or the high-level structure of a large language model. It emphasizes how LLMs learn semantics, grammar, knowledge, and contextual relationships from massive text corpora and transform them into general-purpose language capabilities.
AI Visual Insight: This image illustrates model cognition or the high-level structure of a large language model. It emphasizes how LLMs learn semantics, grammar, knowledge, and contextual relationships from massive text corpora and transform them into general-purpose language capabilities.
The strengths of LLMs can be summarized in four categories: language generation, knowledge compression, logical processing, and multimodal expansion. An LLM is not just a “Wikipedia-style Q&A engine”; it is better understood as a collaborative software capability layer.
# Use pseudocode to describe a typical LLM invocation flow in an application
user_input = "Summarize this technical document"
context = "This is an internal product design spec" # Add business context to improve answer relevance
prompt = f"Answer based on the context: {context}\nQuestion: {user_input}"
result = llm.invoke(prompt) # Call the model to generate a result
print(result)This code shows the minimal closed loop of an LLM call: input, context composition, and inference output.
Prompt engineering determines output stability
Prompts are not rhetorical tricks. They are task specifications. The source material highlights CoSTAR, few-shot prompting, chain-of-thought, zero-shot CoT, Auto-CoT, and self-critique iteration. These methods share the same goal: reducing ambiguity.
CoSTAR turns vague requests into structured task briefs
CoSTAR can be broken down into Context, Objective, Style, Tone, Audience, and Response. It works especially well for high-constraint output scenarios such as marketing copy, technical writing, and analytical reports.
Context: You are an enterprise knowledge base architect
Objective: Generate a technology selection recommendation for RAG
Style: Professional and concise
Tone: Objective
Audience: Technical leads
Response: Output a Markdown table and a conclusionThis prompt clearly constrains the role, objective, style, and output format in one pass.
Chain-of-thought and few-shot prompting improve accuracy on complex tasks
Few-shot prompting shows the model what a correct answer should look like through examples. Chain-of-thought prompting encourages step-by-step reasoning. Both are useful for tasks involving math, logic, rule evaluation, and multi-step decision-making.
Zero-shot CoT is often activated with phrases such as “Let’s think step by step.” Auto-CoT goes further by having the model generate example reasoning first, then using those examples to support subsequent reasoning. In practice, this usually improves stability.
 AI Visual Insight: This image shows the typical output state of a model without structured prompting. Common issues include overly generic answers, loose structure, or incomplete alignment with the task objective, reflecting insufficient prompt constraints.
AI Visual Insight: This image shows the typical output state of a model without structured prompting. Common issues include overly generic answers, loose structure, or incomplete alignment with the task objective, reflecting insufficient prompt constraints.
 AI Visual Insight: This image shows the output after adding structured prompting. It highlights clearer hierarchy, better field completeness, and stronger alignment with the task.
AI Visual Insight: This image shows the output after adding structured prompting. It highlights clearer hierarchy, better field completeness, and stronger alignment with the task.
 AI Visual Insight: This image further illustrates the details of prompt-guided generation, likely showing more consistent formatting, tighter focus, and clearer action recommendations.
AI Visual Insight: This image further illustrates the details of prompt-guided generation, likely showing more consistent formatting, tighter focus, and clearer action recommendations.
Model integration choices determine cost, flexibility, and security
In engineering practice, there are three main ways to connect to an LLM: remote APIs, local deployment, and SDK wrappers. These are not mutually exclusive. They are often combined at different stages of a project.
Remote API calls are the fastest way to validate a product idea
The benefits of remote APIs include fast integration, low maintenance overhead, and timely model updates. The typical process includes registering with a platform, obtaining an API key, enabling a model, configuring request headers and payloads, and then sending a request to validate the response.
{
"model": "your-model-id",
"messages": [
{
"role": "user",
"content": "Hello, introduce yourself"
}
]
}This request body is a typical minimal example for an OpenAI-compatible interface.
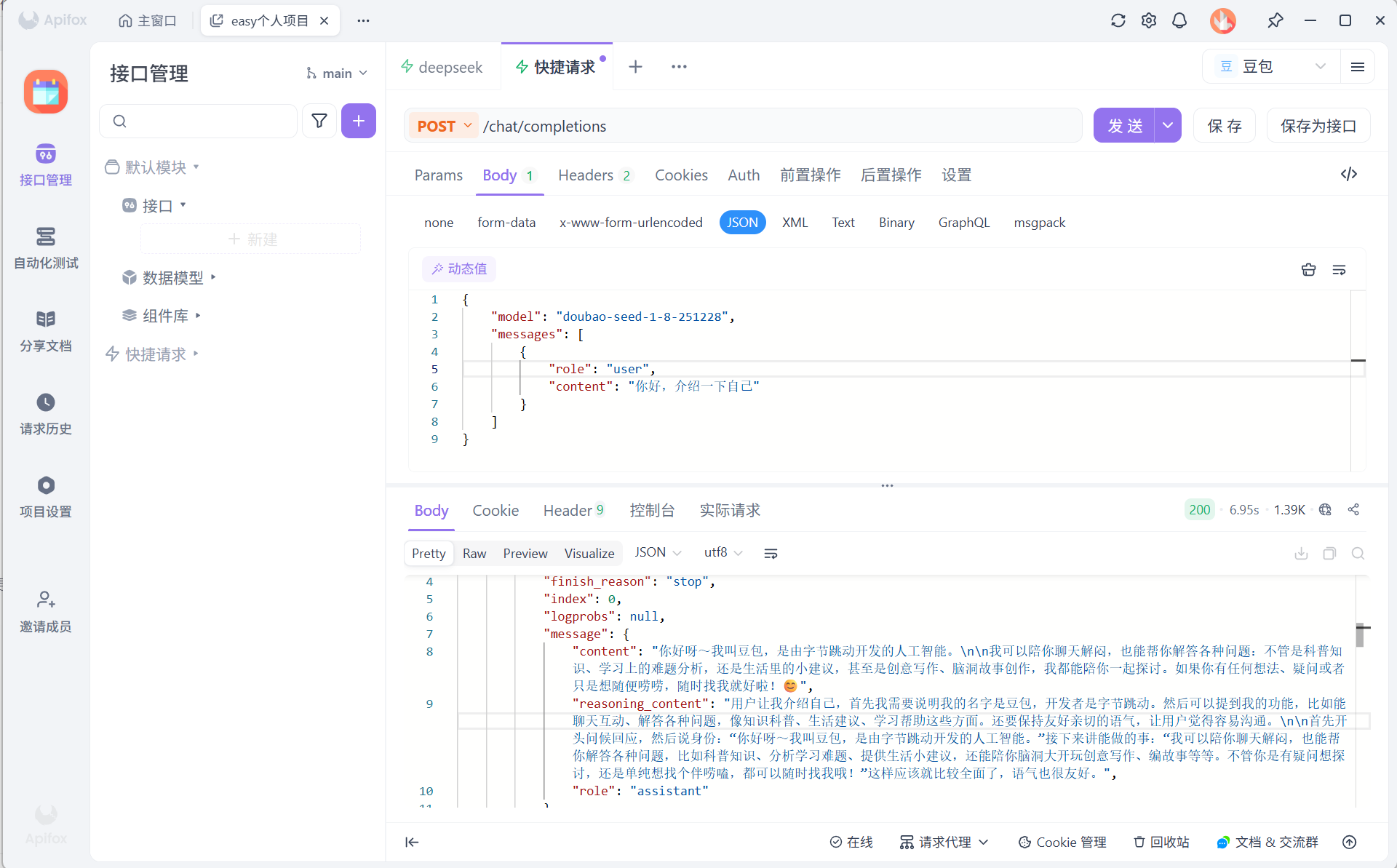 AI Visual Insight: This image shows a successful API call in an API debugging tool. You can typically see request parameters, authentication headers, response output, and status codes, indicating that the model integration path is working end to end.
AI Visual Insight: This image shows a successful API call in an API debugging tool. You can typically see request parameters, authentication headers, response output, and status codes, indicating that the model integration path is working end to end.
SDK wrappers are better for maintainable application code
An SDK is essentially a language-level wrapper around HTTP requests. Compared with manually assembling requests, an SDK improves readability, reduces boilerplate code, and standardizes error handling.
from openai import OpenAI
client = OpenAI(api_key="your-api-key") # Initialize the official client
response = client.responses.create(
model="gpt-5", # Specify the target model
input="Introduce yourself."
)
print(response.output_text) # Print the model output textThis code demonstrates the standard way to call a model through an SDK.
Local deployment is better for sensitive data and large-scale usage
If data cannot leave a private network, or if call volume is large enough, local deployment becomes more attractive. Common inference frameworks include vLLM, TGI, Ollama, and LM Studio. They are typically optimized for high throughput, standardized serving, ease of use, and graphical experience, respectively.
The selection logic is straightforward: choose local deployment for sensitive data, APIs when resources are limited, and SDKs or LangChain wrappers when fast development matters most.
Embeddings provide the foundation for RAG and semantic retrieval
Embedding models are not designed to answer questions directly. They map text into vectors. Because vectors can be compared mathematically, systems can measure semantic distance between pieces of text and use that capability for retrieval, recommendation, clustering, and anomaly detection.
In one sentence: LLMs generate answers, while embeddings find the evidence. Without high-quality vector retrieval, RAG struggles to work reliably in real enterprise knowledge bases.
High-value embedding use cases are already well established
The first major use case is RAG-based question answering: chunk documents, convert them into vectors, retrieve relevant passages, and then pass those passages to an LLM to generate an answer. The second is semantic search: matching by meaning rather than exact keywords. The third is recommendation and clustering: organizing content by semantic similarity.
 AI Visual Insight: This image shows output generated with few-shot prompting absent or weakly applied. Common symptoms include blurry task boundaries, inconsistent formatting, or poor transfer from examples.
AI Visual Insight: This image shows output generated with few-shot prompting absent or weakly applied. Common symptoms include blurry task boundaries, inconsistent formatting, or poor transfer from examples.
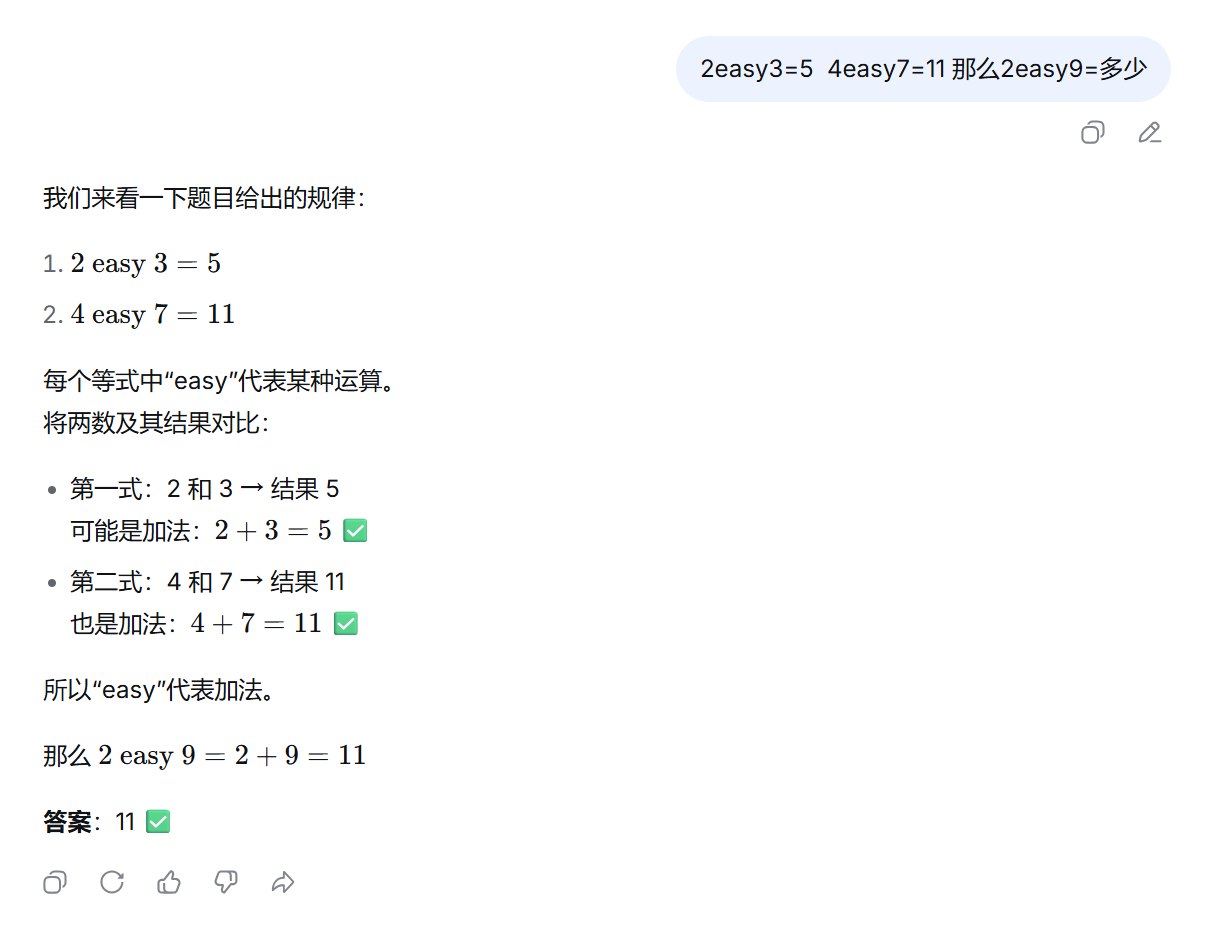 AI Visual Insight: This image shows the model response after examples are added, demonstrating how few-shot prompting can significantly improve formatting consistency, semantic alignment, and task completion quality.
AI Visual Insight: This image shows the model response after examples are added, demonstrating how few-shot prompting can significantly improve formatting consistency, semantic alignment, and task completion quality.
Mainstream embedding selection should focus on accuracy, speed, and deployment constraints
The source material mentions representative models such as Microsoft Harrier, Gemini Embedding 2, the e5 family, Qwen3-VL-2B, and NVIDIA Llama-embed-nemotron-8B. When selecting a model, prioritize multilingual support, vector dimensionality, inference latency, and whether local deployment is supported.
For most Chinese-language business scenarios, a practical starting point is an API service or a mature open-source model. As retrieval scale grows, introduce a vector database such as Milvus, Pinecone, or Qdrant to optimize indexing and recall.
# Pseudocode: main RAG retrieval flow
query = "What is the accommodation reimbursement standard for business travel?"
query_vec = embedding.embed_query(query) # Convert the query into a vector
chunks = vectordb.similarity_search(query_vec, k=3) # Retrieve the most relevant document chunks
answer = llm.invoke(f"Answer based on the following materials: {chunks}") # Generate an answer from retrieved context
print(answer)This code captures the core execution path of a knowledge-base question answering system.
LangChain’s real value lies in unified abstractions and rapid composition
LangChain shows its real value when a project evolves from “one question, one answer” into systems that connect tools, knowledge, workflows, and evaluation. It gives prompts, models, retrievers, memory, agents, and workflow components a unified interface.
That allows developers to focus more on business orchestration instead of repeatedly rebuilding plumbing. For AI application development, this abstraction layer is itself a productivity multiplier.
FAQ structured Q&A
What is the difference between LangChain and the LLM itself?
An LLM provides generation and reasoning capabilities. LangChain provides engineering orchestration capabilities. The former is like the engine; the latter is like the full vehicle system that organizes context, tools, retrieval, and workflows.
Should beginners learn LangChain first or prompt engineering first?
Start with prompt engineering, then move to LangChain. Without clear task definitions and prompt constraints, even a well-integrated framework will struggle to produce stable output. LangChain is an amplifier, not a substitute for thinking.
Why is understanding embeddings essential for building an enterprise knowledge base?
Because knowledge-base question answering is not fundamentally about generating first. It is about retrieving first, then answering. Embeddings determine retrieval quality, and retrieval quality directly determines the final answer’s accuracy and explainability.
AI Readability Summary: This article systematically explains LangChain’s role, LLM fundamentals, prompt engineering methods, model integration patterns, and embedding applications. It helps developers quickly build a complete mental model that spans from LLM invocation to RAG-based retrieval.