The core of Linux IPC is not simply “moving data.” It starts by making the same resource visible to multiple processes, then enabling data exchange, event notification, synchronization, and mutual exclusion. This article covers five mechanisms: anonymous pipes, named pipes, System V shared memory, message queues, and semaphores, to address process coordination, performance, and isolation. Keywords: Linux IPC, shared memory, pipe communication.
This article provides a technical snapshot of Linux IPC
| Parameter | Value |
|---|---|
| Topic | Linux Inter-Process Communication (IPC) |
| Language | C / C++ |
| Runtime Environment | Linux / UNIX-like |
| Protocols and Standards | UNIX Pipe, FIFO, System V IPC, POSIX IPC |
| Stars | Not provided in the original content |
| Core Dependencies | unistd.h, sys/types.h, sys/wait.h, sys/stat.h, fcntl.h, sys/shm.h |
| Typical Scenarios | Parent-child process communication, cross-process messaging, shared data, high-performance synchronization |
The essence of IPC is that multiple processes first share visibility into the same resource
Processes naturally have isolated address spaces, so they cannot directly read or write each other’s memory. In practice, communication means the kernel provides an intermediate resource that allows different processes to access the same object in a controlled way.
That resource may be a kernel buffer, a FIFO file, a shared memory segment, a message queue, or a semaphore. Data transfer, event notification, synchronization, and mutual exclusion all fall within the scope of IPC.
Linux IPC has evolved into a clearly layered model
Early UNIX primarily provided anonymous pipes, named pipes, and signals to solve basic data flow and asynchronous notification. System V later added message queues, shared memory, and semaphores to complete multi-process coordination on a single machine.
POSIX IPC then standardized the interfaces and improved portability. Modern Linux continues to extend IPC in containers, zero-copy workflows, and event-driven frameworks to improve both performance and isolation.
 AI Visual Insight: This animation introduces the IPC topic as a whole and emphasizes the knowledge map of multiple communication mechanisms coexisting. It works best as an entry point for end-to-end learning rather than as a demonstration of a single API.
AI Visual Insight: This animation introduces the IPC topic as a whole and emphasizes the knowledge map of multiple communication mechanisms coexisting. It works best as an entry point for end-to-end learning rather than as a demonstration of a single API.
Pipe mechanisms are ideal for building the lightest-weight data stream communication
A pipe is the oldest form of IPC. You can think of it as a byte-stream channel connecting two processes. Anonymous pipes usually appear between parent and child processes, while named pipes support communication between unrelated processes through a filesystem path.
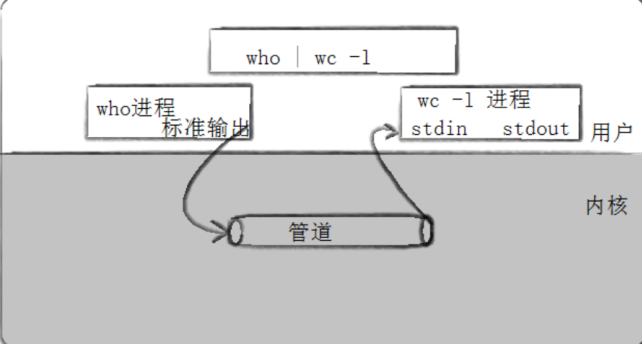 AI Visual Insight: The image shows the classic pipe topology of “write end → kernel buffer → read end.” The key detail is that data must pass through the kernel buffer, which gives pipes natural synchronization semantics but also introduces context-switch overhead.
AI Visual Insight: The image shows the classic pipe topology of “write end → kernel buffer → read end.” The key detail is that data must pass through the kernel buffer, which gives pipes natural synchronization semantics but also introduces context-switch overhead.
Anonymous pipes depend on file descriptor inheritance after fork()
An anonymous pipe is created with pipe(), which returns two file descriptors: fds[0] for reading and fds[1] for writing. It only works for related processes because both sides must share the opened descriptors.
#include
<iostream>
#include <unistd.h>
#include
<cstring>
#include <sys/wait.h>
int main() {
int fds[2] = {0};
if (pipe(fds) < 0) return 1; // Create an anonymous pipe
pid_t id = fork();
if (id == 0) {
close(fds[0]); // Child closes the read end
const char* msg = "hello from child";
write(fds[1], msg, strlen(msg)); // Child writes data into the pipe
close(fds[1]);
return 0;
}
close(fds[1]); // Parent closes the write end
char buffer[64] = {0};
ssize_t n = read(fds[0], buffer, sizeof(buffer) - 1); // Parent reads data
if (n > 0) std::cout << buffer << std::endl;
close(fds[0]);
waitpid(id, nullptr, 0); // Wait for the child process to exit
return 0;
}This code shows the smallest complete example of one-way communication between a parent and child process through an anonymous pipe.
Anonymous pipes have five key properties: they only work for related processes, provide built-in synchronization semantics, operate as byte streams, support one-way communication, and terminate with the lifetime of the processes that hold them.
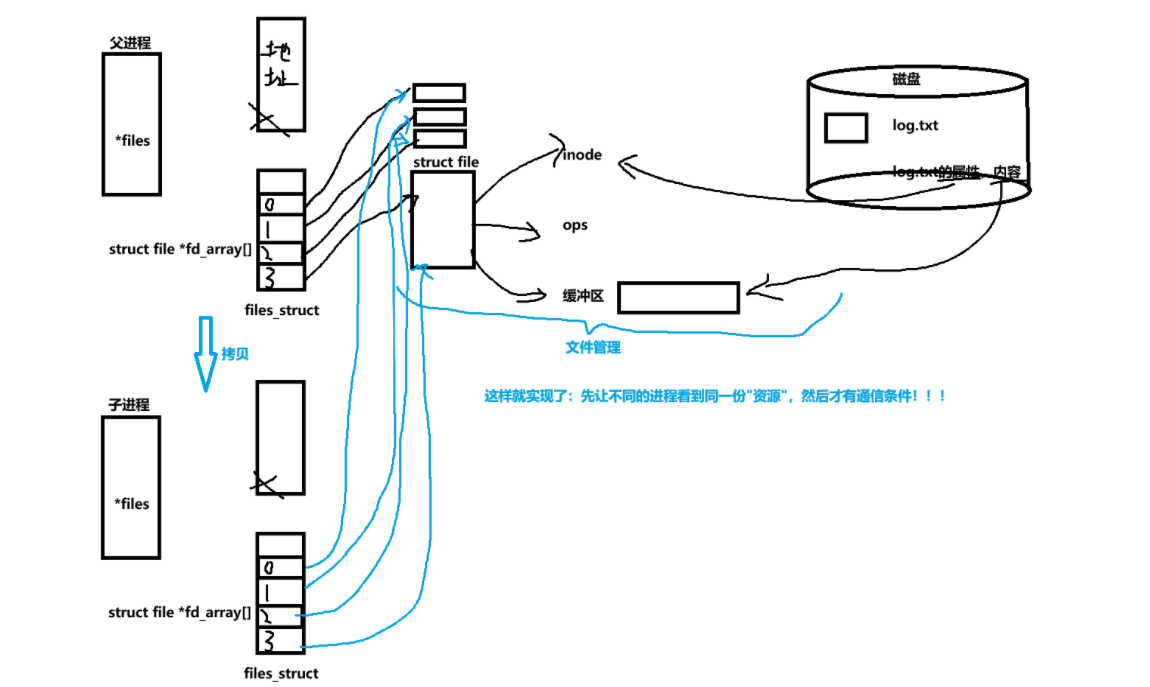 AI Visual Insight: This image highlights that parent and child processes share the same file table entries after
AI Visual Insight: This image highlights that parent and child processes share the same file table entries after fork(). The root cause of anonymous pipe communication is not that the processes are “special,” but that both hold references to the same kernel pipe object.
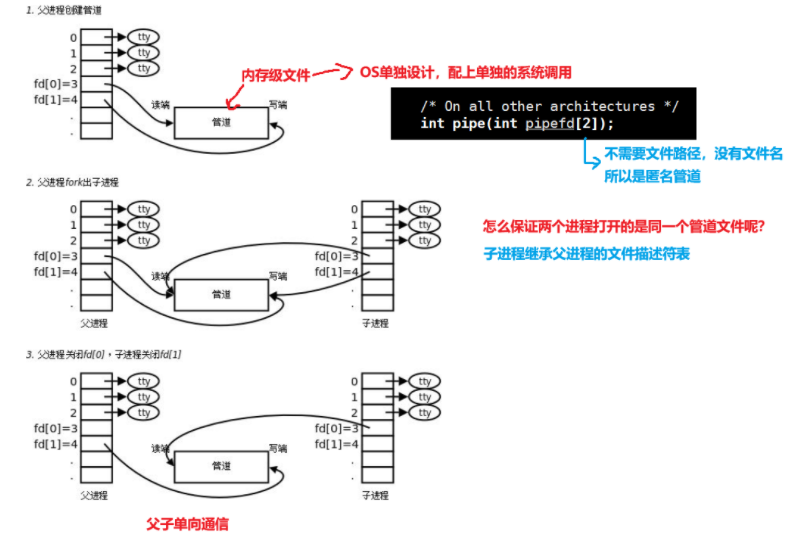 AI Visual Insight: This figure further breaks down the strategy for closing the read and write ends. It emphasizes that you must close irrelevant ends to establish a stable one-way data flow; otherwise, EOF and blocking behavior can be misleading.
AI Visual Insight: This figure further breaks down the strategy for closing the read and write ends. It emphasizes that you must close irrelevant ends to establish a stable one-way data flow; otherwise, EOF and blocking behavior can be misleading.
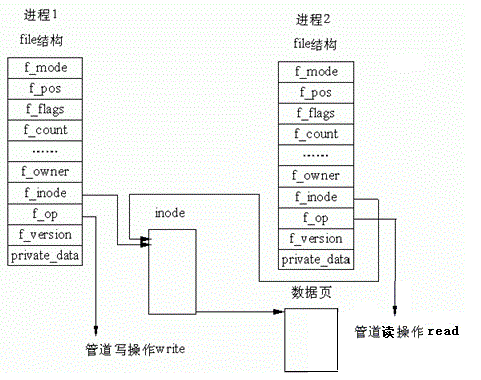 AI Visual Insight: This image should show the runtime state where the parent reads and the child writes, typically including buffer flow, scheduling switches, and descriptor inheritance. It serves as a helpful visual companion to the sample code.
AI Visual Insight: This image should show the runtime state where the parent reads and the child writes, typically including buffer flow, scheduling switches, and descriptor inheritance. It serves as a helpful visual companion to the sample code.
Pipe blocking semantics define the behavioral boundaries of your program
When the writer is slow and the reader is fast, read() blocks until data arrives. When the writer is fast and the reader is slow, write() blocks after the buffer becomes full. If the write end closes, the reader receives 0, which indicates EOF. If the read end closes and the writer continues writing, the writer receives SIGPIPE.
 AI Visual Insight: This image focuses on four typical pipe boundary states: read blocking, write blocking, reading EOF, and writing triggering
AI Visual Insight: This image focuses on four typical pipe boundary states: read blocking, write blocking, reading EOF, and writing triggering SIGPIPE. These states are essential when debugging IPC hangs and unexpected process exits.
#include <unistd.h>
#include
<cstdio>
void test_pipe_capacity(int wfd) {
char c = 'x';
int cnt = 0;
while (true) {
write(wfd, &c, 1); // Write 1 byte each time to approach the pipe capacity limit
printf("written=%d\n", ++cnt);
}
}This example continuously writes single bytes so you can directly observe the blocking behavior after the pipe buffer becomes full.
Named pipes extend the communication object from file descriptors to filesystem paths
A named pipe, or FIFO, is a special file that allows unrelated processes to communicate. Compared with an anonymous pipe, the biggest difference is not the semantics but the way you create and open it.
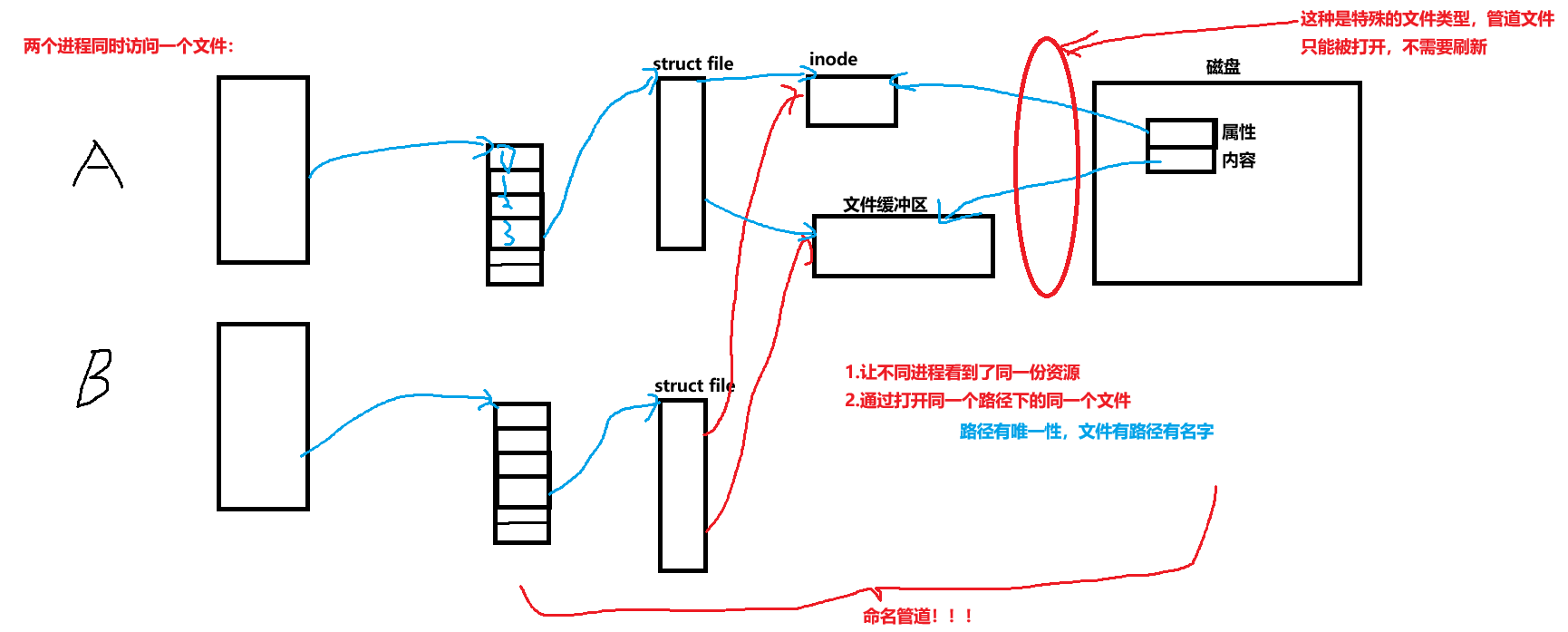 AI Visual Insight: This image should show a FIFO attached to a filesystem path. It illustrates how the communication medium evolves from an inherited descriptor into a mutually agreed file name, which enables independently launched server/client patterns.
AI Visual Insight: This image should show a FIFO attached to a filesystem path. It illustrates how the communication medium evolves from an inherited descriptor into a mutually agreed file name, which enables independently launched server/client patterns.
FIFO creation and open rules directly affect deployment patterns
From the command line, you can create a FIFO with mkfifo filename. In code, you use mkfifo(const char *filename, mode_t mode). A blocking open on the read side waits for a writer, and a blocking open on the write side waits for a reader. A non-blocking write open returns ENXIO if no reader exists.
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
mkfifo("./demo_fifo", 0666); // Create a named pipe file
int fd = open("./demo_fifo", O_WRONLY); // Open the FIFO for writing
write(fd, "ping", 4); // Send data to another process
close(fd);
return 0;
}This code demonstrates the basic flow of a named pipe, from file creation to cross-process writing.
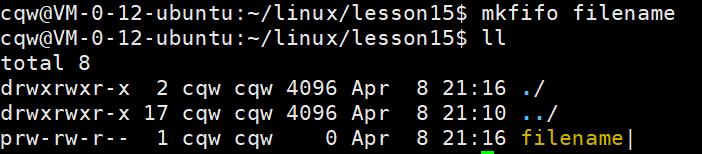 AI Visual Insight: This image usually corresponds to the shell output after creating a FIFO. It helps distinguish the file type marker from a regular file and reinforces the idea that a FIFO is a special file.
AI Visual Insight: This image usually corresponds to the shell output after creating a FIFO. It helps distinguish the file type marker from a regular file and reinforces the idea that a FIFO is a special file.
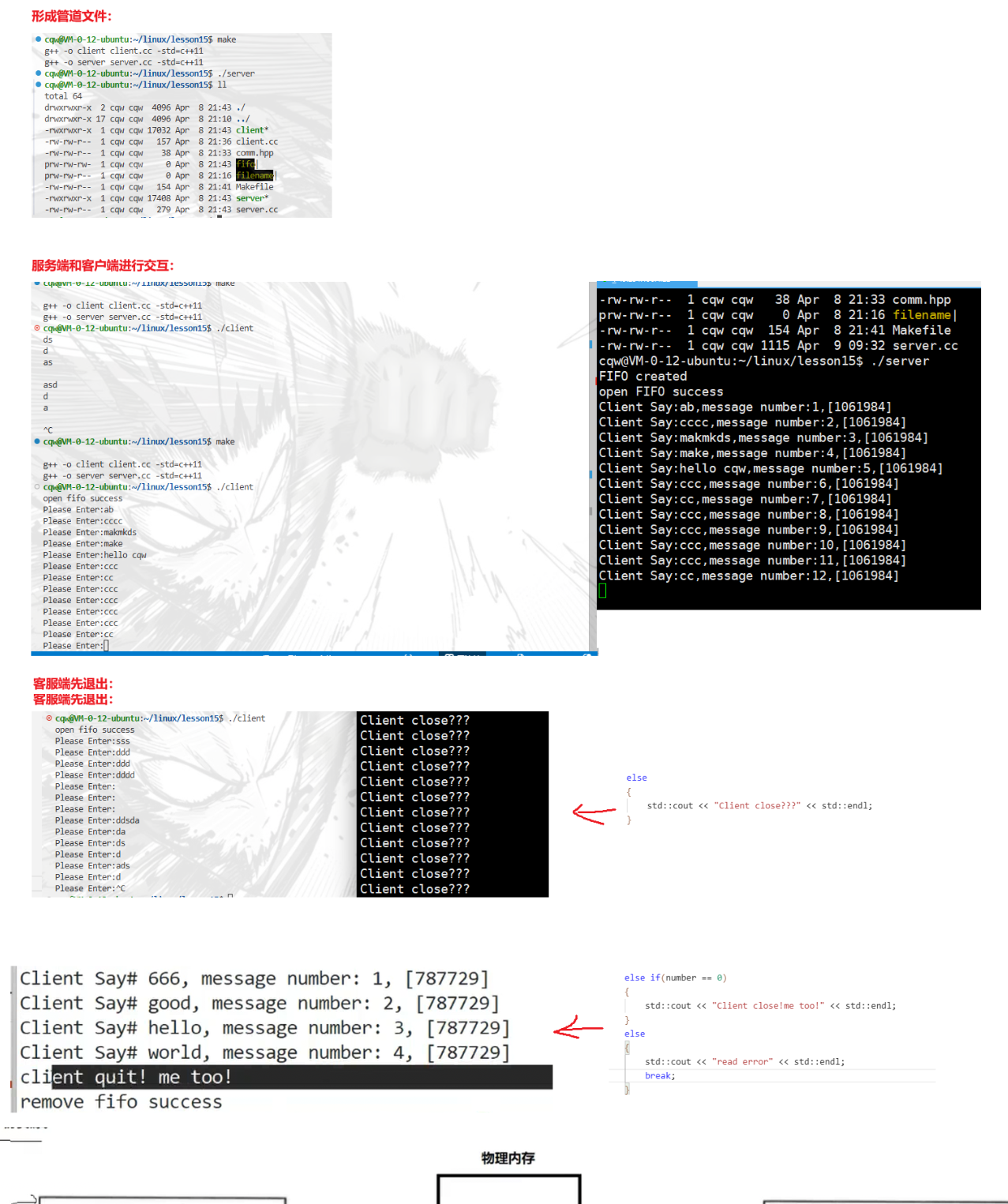 AI Visual Insight: This figure should show actual communication where a server reads and a client writes. It demonstrates how named pipes support unrelated processes and how the one-way message flow behaves at runtime.
AI Visual Insight: This figure should show actual communication where a server reads and a client writes. It demonstrates how named pipes support unrelated processes and how the one-way message flow behaves at runtime.
System V shared memory is the fastest IPC mechanism on a single machine
Shared memory maps the same physical memory region into multiple process address spaces. As a result, data exchange no longer requires repeated copying through a kernel buffer, so both throughput and latency are usually better than pipes and message queues.
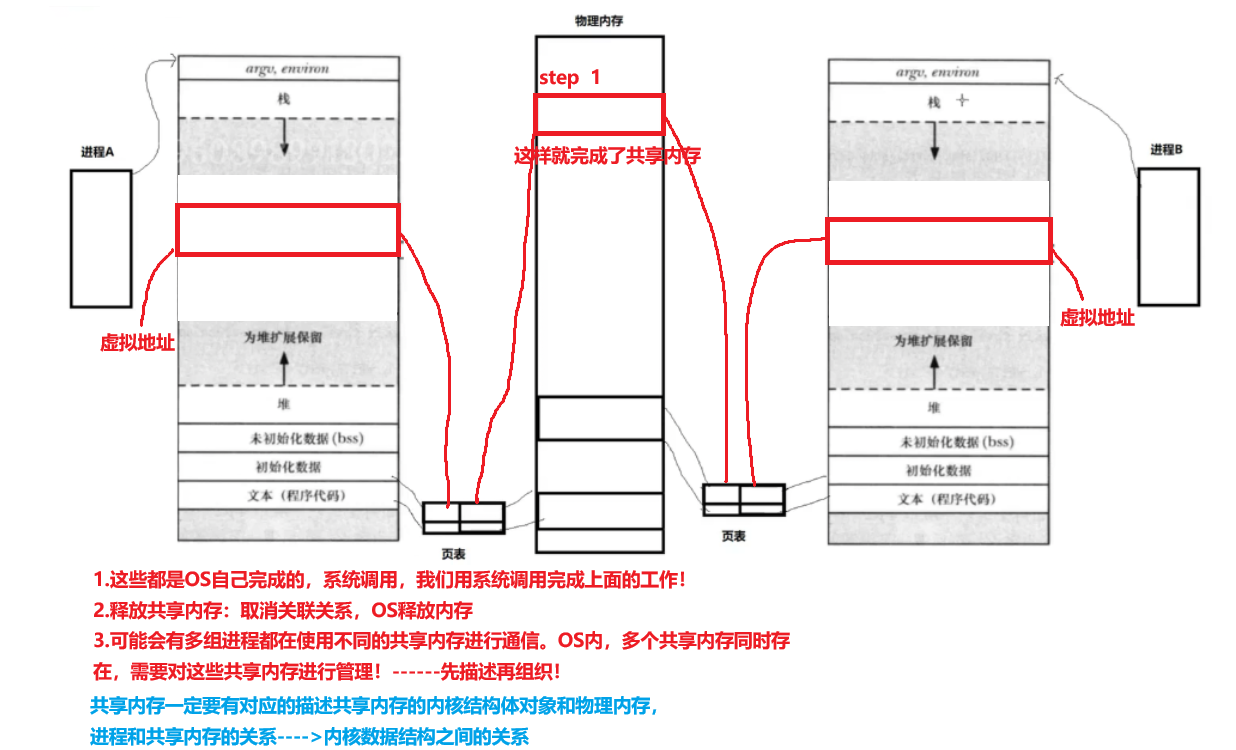 AI Visual Insight: This image shows a shared memory segment mapped into multiple processes at the same time. The technical focus is “the same physical pages, multiple virtual address mappings,” which is the fundamental reason shared memory delivers high IPC performance.
AI Visual Insight: This image shows a shared memory segment mapped into multiple processes at the same time. The technical focus is “the same physical pages, multiple virtual address mappings,” which is the fundamental reason shared memory delivers high IPC performance.
The shared memory API follows a four-step pattern: create, attach, detach, and control
shmget() creates or retrieves a shared memory identifier, shmat() attaches the segment to the current process, shmdt() detaches the mapping, and shmctl() handles state queries and deletion control.
#include <sys/shm.h>
#include
<cstring>
#include
<iostream>
int main() {
int shmid = shmget(0x1234, 1024, IPC_CREAT | 0666); // Create a shared memory segment
char* mem = static_cast<char*>(shmat(shmid, nullptr, 0)); // Attach it to the process address space
strcpy(mem, "shared hello"); // Write directly into shared memory
std::cout << mem << std::endl;
shmdt(mem); // Detach the shared memory
shmctl(shmid, IPC_RMID, nullptr); // Mark the shared memory resource for deletion
return 0;
}This code demonstrates the full lifecycle of shared memory, from allocation to cleanup.
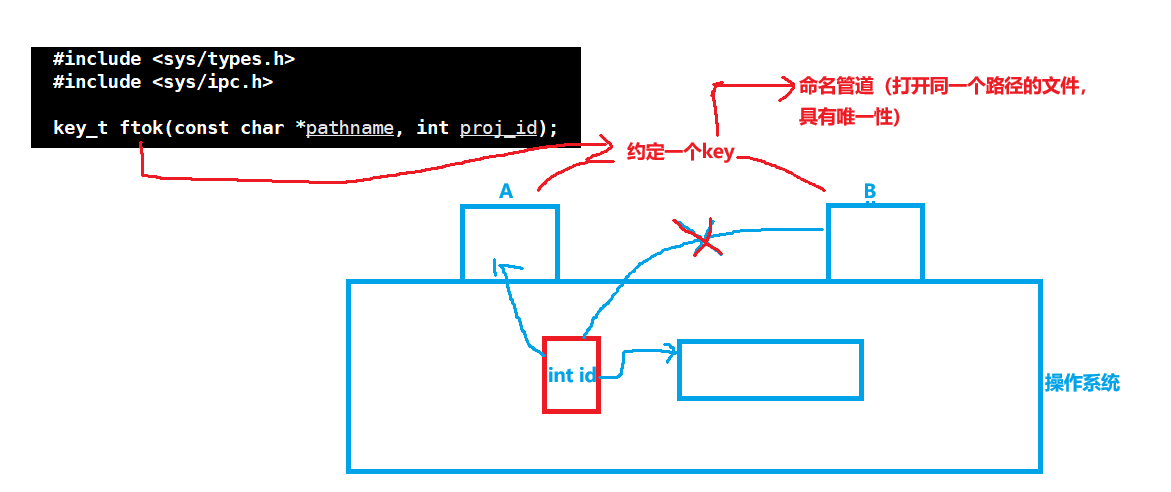 AI Visual Insight: This image should correspond to the creation logic of
AI Visual Insight: This image should correspond to the creation logic of shmget, highlighting the three key input parameters: key, size, and flags, as well as the effect of IPC_CREAT and IPC_EXCL on resource existence checks.
 AI Visual Insight: This figure explains the control operations of
AI Visual Insight: This figure explains the control operations of shmctl, typically including attribute queries, permission changes, and resource deletion. It helps explain why shared memory can outlive a process and persist as a kernel-managed resource.
 AI Visual Insight: This image should show the result of
AI Visual Insight: This image should show the result of shmat, where the shared segment is mapped into user virtual address space. It helps explain why the returned pointer feels similar to one returned by malloc.
 AI Visual Insight: This figure focuses on
AI Visual Insight: This figure focuses on shmdt detachment and emphasizes that detaching does not mean deleting. A System V resource is only truly released after explicit deletion control or a system reboot.
System V message queues are better for discrete messages than for large shared data blocks
Message queues allow processes to send structured data by message type, and the receiver can selectively read only specific message types. They are better suited than pipes for discrete workloads such as commands, tasks, and events, but their performance is usually lower than shared memory.
 AI Visual Insight: This image shows a message queue as a kernel-managed chained message container. The key point is that each message carries a type field, so the receiver can filter by category instead of consuming a raw byte stream in strict order.
AI Visual Insight: This image shows a message queue as a kernel-managed chained message container. The key point is that each message carries a type field, so the receiver can filter by category instead of consuming a raw byte stream in strict order.
System V semaphores protect critical sections rather than moving data
A semaphore is fundamentally a counter used for synchronization and mutual exclusion. A P operation acquires resources and decrements the count, while a V operation releases resources and increments the count. It solves the problem of who may enter a critical section, not how data should be transported.
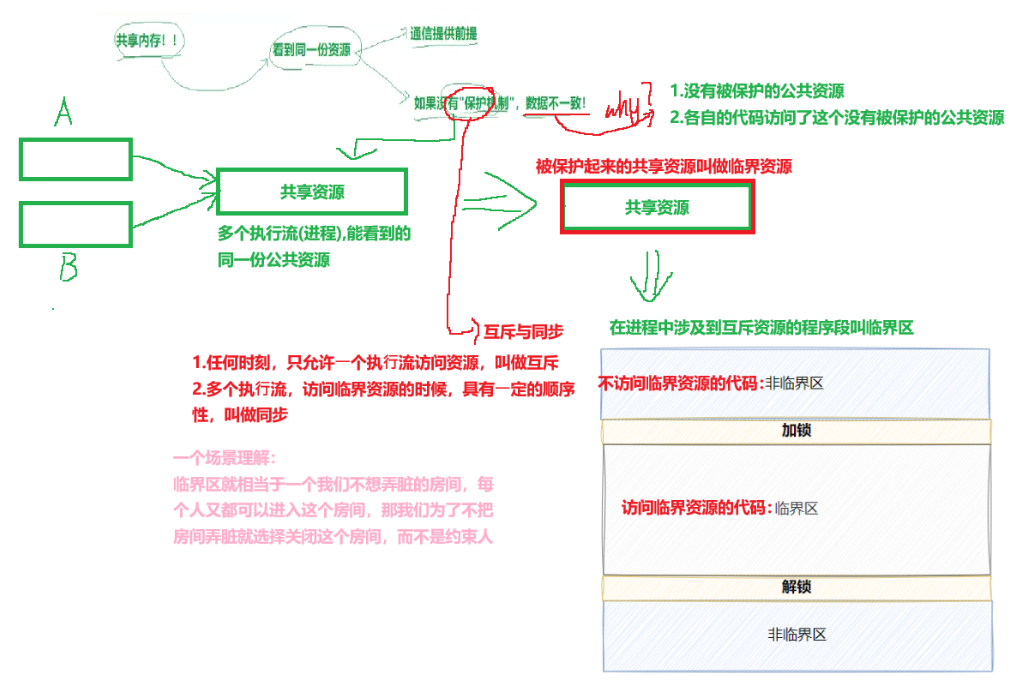 AI Visual Insight: This image should show multiple processes competing for a shared resource while a semaphore determines access order. The technical key is that it turns concurrency conflicts into a controllable resource quota problem.
AI Visual Insight: This image should show multiple processes competing for a shared resource while a semaphore determines access order. The technical key is that it turns concurrency conflicts into a controllable resource quota problem.
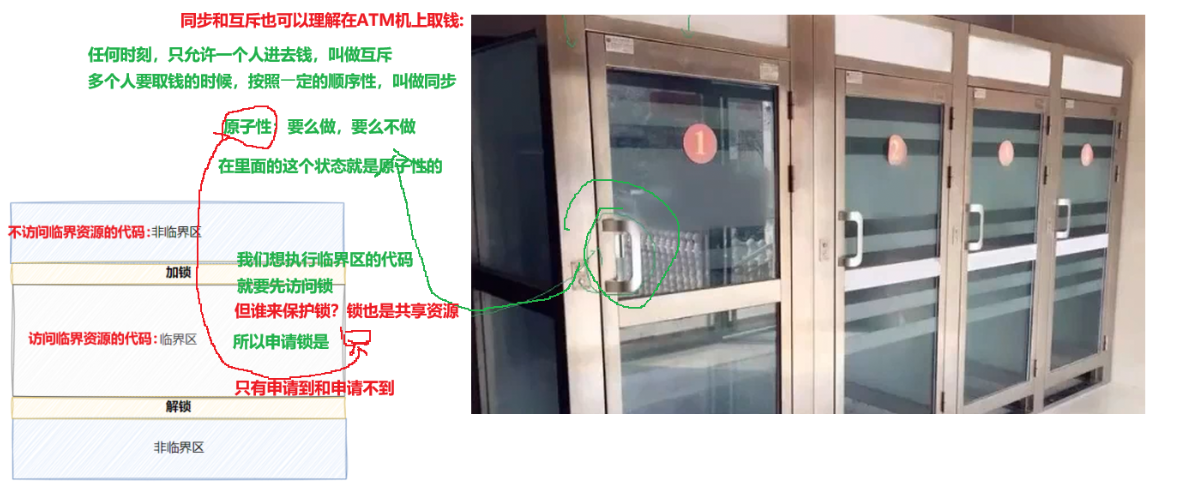 AI Visual Insight: This figure focuses on atomicity and shows why semaphore operations must be indivisible. Otherwise, race conditions can still occur between checking, modifying, and using the resource.
AI Visual Insight: This figure focuses on atomicity and shows why semaphore operations must be indivisible. Otherwise, race conditions can still occur between checking, modifying, and using the resource.
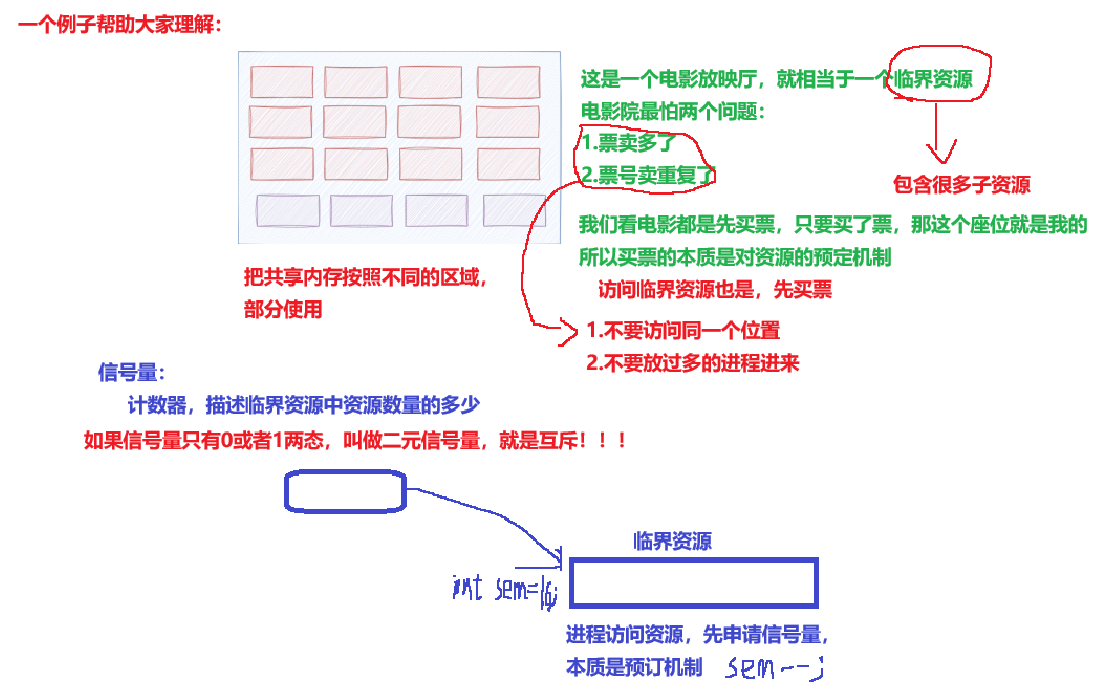 AI Visual Insight: This image further explains the relationship between P/V operations and the resource reservation model. It helps clarify that a semaphore is not just another word for a lock, but a lower-level resource counting mechanism.
AI Visual Insight: This image further explains the relationship between P/V operations and the resource reservation model. It helps clarify that a semaphore is not just another word for a lock, but a lower-level resource counting mechanism.
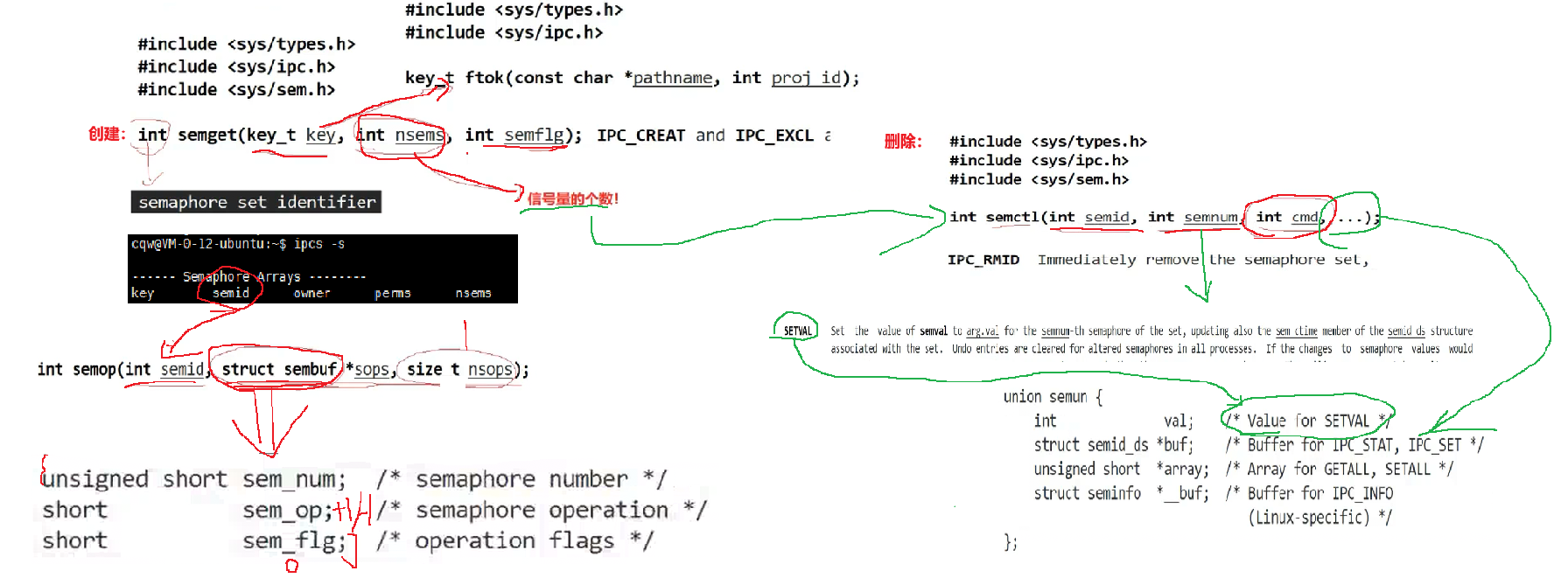 AI Visual Insight: This figure emphasizes that semaphores are also part of IPC, because synchronization, notification, and mutual exclusion are all forms of cross-process coordination. IPC should not be narrowly understood as data transfer alone.
AI Visual Insight: This figure emphasizes that semaphores are also part of IPC, because synchronization, notification, and mutual exclusion are all forms of cross-process coordination. IPC should not be narrowly understood as data transfer alone.
IPC selection must be based on process relationships, throughput, and semantics
If you need simple one-way byte-stream communication between parent and child processes, prefer an anonymous pipe. If the processes are unrelated and require lightweight local communication, prefer a named pipe. If you need the highest throughput and the lowest copy cost, prefer shared memory, but always pair it with a synchronization mechanism.
If the workload is typed task dispatch, use a message queue. If the core problem is concurrent access control, you must introduce semaphores or other synchronization primitives. In real systems, communication and synchronization usually require a combined design instead of a single standalone mechanism.
FAQ
1. Why is shared memory usually faster than a pipe?
Because a pipe must transfer data through a kernel buffer, while shared memory maps the same physical memory directly into multiple process address spaces. That reduces both data copying and system call overhead.
2. What is the most important difference between anonymous pipes and named pipes?
Anonymous pipes rely on file descriptor inheritance after pipe() and are typically used only between related processes. Named pipes rely on a filesystem path, so unrelated processes can open them independently and communicate.
3. If shared memory is already very fast, why do we still need semaphores?
Shared memory only solves the problem of making the same data visible to multiple processes. It does not prevent concurrent write conflicts. If multiple processes modify the shared region at the same time, race conditions still occur, so you must protect critical sections with semaphores or similar synchronization mechanisms.
Core Summary: This article systematically reconstructs the Linux IPC knowledge framework. It covers anonymous pipes, named pipes, System V shared memory, message queues, and semaphores, and explains the essence of communication, blocking semantics, typical APIs, and practical code examples to help developers quickly build IPC selection and implementation skills.