This article focuses on the KingbaseES high availability stack, reframing three architecture options—KES primary-standby, read/write splitting, and MPP clusters—to address single points of failure, limited read scalability, and performance bottlenecks in large-scale analytics. Keywords: KingbaseES, high availability, read/write splitting.
Technical Specification Snapshot
| Parameter | Details |
|---|---|
| Database / Ecosystem | KingbaseES KES / KingbaseES |
| Core Languages | SQL, Java, Bash, Python, YAML |
| Key Protocols | TCP, JDBC, WAL log replication |
| Architecture Patterns | Primary-standby cluster, read/write splitting, MPP distribution |
| Core Dependencies | sys_stat_replication, connection pools, middleware, Prometheus |
| Source Material Characteristics | The original material is based on practical architecture and operations examples |
| Star Count | Not provided in the original article |
High availability in KingbaseES must be designed in layers by scenario
Enterprise database high availability is not as simple as “setting up primary-standby.” The real goal is to balance RPO, RTO, performance overhead, and operational complexity at the same time. The typical path with KingbaseES starts with KES primary-standby, then evolves to read/write splitting or MPP based on read pressure and analytical workload.
 AI Visual Insight: This diagram provides a high-level architectural map of the article, emphasizing the evolution path from basic primary-standby deployment to distributed clusters. It shows that database high availability is not a single product feature, but a layered system covering replication, routing, monitoring, and disaster recovery.
AI Visual Insight: This diagram provides a high-level architectural map of the article, emphasizing the evolution path from basic primary-standby deployment to distributed clusters. It shows that database high availability is not a single product feature, but a layered system covering replication, routing, monitoring, and disaster recovery.
KES primary-standby clusters are the lowest-cost entry point for foundational high availability
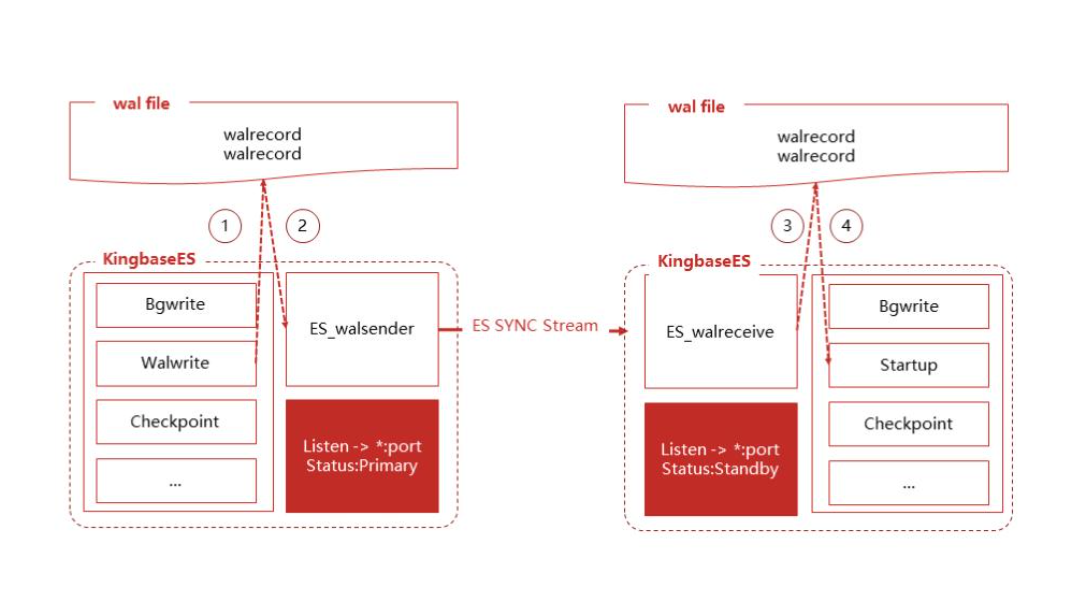
KES primary-standby relies on WAL physical replication. The primary node handles reads and writes, while the standby node replays logs to maintain data consistency. Its value lies in strong consistency, mature implementation, and a clear failover path, making it suitable for transaction systems, government platforms, and mission-critical business applications.
-- Enable synchronous commit on the primary so the standby confirms before commit completes
ALTER SYSTEM SET synchronous_commit = 'on'; -- Enable strong-consistency commits
ALTER SYSTEM SET synchronous_standby_names = 'standby1'; -- Specify the synchronous standby node
-- Check replication status to verify whether synchronous replication is active
SELECT application_name, sync_state, sync_priority
FROM sys_stat_replication;This code enables synchronous replication and verifies the primary-standby replication state.
Failover capability determines whether a primary-standby solution is truly usable
High availability does not mean simply “having a standby node”—it means “being able to switch automatically.” A production-ready failover process should include heartbeat detection, split-brain arbitration, standby candidate selection, VIP migration, and downstream reconnection. The core idea from the original material is straightforward: detect failures accurately first, then promote quickly.
# Example cluster heartbeat parameters
node_id=1
node_name='primary'
node_host='192.168.1.101'
heartbeat_interval=1s # Smaller intervals detect failures faster
heartbeat_timeout=3s # Mark the node as failed after timeout
max_failover_retries=3 # Limit repeated failover attemptsThis configuration defines the failure detection sensitivity and failover thresholds of the primary-standby cluster.
Replication lag monitoring is the core observability surface of a primary-standby architecture
To determine whether primary-standby replication is healthy, you cannot look only at whether the connection exists. You also need to track write_lag, flush_lag, and replay_lag. If latency remains high for an extended period, the usual causes are network jitter, disk bottlenecks, or improper WAL sender configuration.
SELECT
application_name,
EXTRACT(EPOCH FROM write_lag) AS write_delay_seconds, -- Write lag in seconds
EXTRACT(EPOCH FROM flush_lag) AS flush_delay_seconds, -- Flush lag in seconds
EXTRACT(EPOCH FROM replay_lag) AS replay_delay_seconds -- Replay lag in seconds
FROM sys_stat_replication;This SQL query quantifies the three key latency metrics in the primary-standby replication path.
Read/write splitting is better suited to read-heavy business models
When the bottleneck shifts from availability to read throughput, read/write splitting becomes the more natural next step. It preserves the primary database as the authoritative write node while distributing query traffic across multiple read-only replicas. This model fits high-concurrency read scenarios such as portals, reporting systems, and order lookup services.
The routing layer must manage read/write semantics explicitly
The essence of read/write splitting is not multiple data sources, but request-aware routing. A common approach is to use annotations, AOP, or SQL rules in Spring or middleware to pin write requests to the primary and direct read requests to replicas.
public class DbContextHolder {
private static final ThreadLocal
<String> CTX = new ThreadLocal<>();
public static void usePrimary() {
CTX.set("PRIMARY"); // Force write requests to the primary
}
public static void useReplica() {
CTX.set("REPLICA"); // Prefer read-only replicas for read requests
}
public static String current() {
return CTX.get() == null ? "PRIMARY" : CTX.get(); // Fall back to the primary by default
}
}This code implements thread-level context switching for read/write data sources.
The consistency window is the most commonly overlooked risk in read/write splitting
After a transaction commits on the primary, a replica may not have replayed the change yet. As a result, an immediate read after write can return stale data. The original material recommends maintaining a session consistency window: after a user performs a write, force subsequent reads to the primary for a short period.
public boolean shouldReadFromPrimary(long lastWriteTime) {
long consistencyWindow = 5000; // 5-second consistency window
long delta = System.currentTimeMillis() - lastWriteTime;
return delta < consistencyWindow; // Read from the primary within the window to avoid stale reads
}This logic preserves session-level read consistency when replication lag exists.
MPP distributed clusters target massive data volumes and complex analytical workloads
When data size, complex aggregations, and parallel computing requirements exceed the limits of a single-node database, MPP becomes the right direction. Through sharded storage and parallel execution, it distributes queries across multiple data nodes. This makes it suitable for data warehousing, BI, subject-area analytics, and large-scale statistical workloads.
 AI Visual Insight: This diagram highlights the difference between MPP and primary-standby architectures. It typically shows the coordinator node, data nodes, and the parallel execution pipeline. The key technical concerns are data distribution strategy, inter-node redistribution, and the execution model in which the coordinator aggregates results.
AI Visual Insight: This diagram highlights the difference between MPP and primary-standby architectures. It typically shows the coordinator node, data nodes, and the parallel execution pipeline. The key technical concerns are data distribution strategy, inter-node redistribution, and the execution model in which the coordinator aggregates results.
Distribution strategy matters more than machine count for query scalability
In MPP design, table distribution directly determines whether load remains balanced across nodes and whether joins trigger data movement. Fact tables often use hash distribution, small dimension tables fit replicated distribution, and time-series workloads benefit from combining distribution with partitioning to reduce scan scope and cross-node cost.
CREATE TABLE distributed_sales (
sale_id BIGSERIAL,
customer_id INT NOT NULL,
sale_date DATE NOT NULL,
amount DECIMAL(10,2) NOT NULL
) DISTRIBUTED BY (customer_id); -- Hash distribute by customer to balance parallel loadThis CREATE TABLE statement defines a hash distribution strategy suited to parallel queries.
MPP operations shift the focus from failover to balance and maintenance
Unlike primary-standby architectures, MPP risks come more often from data skew, stale statistics, node recovery, and rebalancing. The more nodes you have, the more you need automation to handle ANALYZE, VACUUM, metadata backup, and distribution checks.
#!/bin/bash
# Periodic maintenance script
psql -h coord1 -U kingbase -d mydb << EOF
ANALYZE VERBOSE; # Refresh statistics to help the optimizer choose the right plan
VACUUM ANALYZE; # Reclaim space and synchronize statistics
EOFThis script helps maintain query plan quality and storage health in an MPP cluster.
Architecture selection must balance consistency, scalability, and complexity
If your primary goal is strong consistency and fast disaster recovery, choose KES primary-standby first. If your main problem is heavy query traffic, prioritize read/write splitting. If you need TB-scale analytics and complex aggregations, then MPP is the right option. Do not use a distributed system to solve a problem that a single-node database can already handle.
 AI Visual Insight: This summary diagram usually serves as the architectural wrap-up. It communicates the capability gradient across the three approaches, from foundational disaster recovery to scalable analytics, and emphasizes that enterprises should evolve architecture according to business growth rather than layering complexity all at once.
AI Visual Insight: This summary diagram usually serves as the architectural wrap-up. It communicates the capability gradient across the three approaches, from foundational disaster recovery to scalable analytics, and emphasizes that enterprises should evolve architecture according to business growth rather than layering complexity all at once.
A progressive evolution path is the recommended approach
In practice, the safer path is to establish primary-standby replication and backup recovery first, then add monitoring and alerting, introduce read/write splitting when read pressure increases, and finally extend to MPP after analytical workloads become independent. This approach reduces migration risk and aligns better with how database architectures actually grow over time.
FAQ
1. Which high availability solution should I choose first for KingbaseES?
If your workload is primarily OLTP and is sensitive to RPO and RTO, KES primary-standby should be your first choice. It is simple to implement, offers a clear failover path, and provides the best data consistency, making it the default option for most production systems.
2. Can read/write splitting completely replace primary-standby high availability?
No. Read/write splitting mainly solves read scalability. It still depends on the primary database as the authoritative write node and on the replication path beneath it. Without a primary-standby foundation, read/write splitting cannot provide complete disaster recovery capability.
3. When is an MPP cluster truly necessary?
You should consider MPP only when a single database can no longer handle massive scans, complex aggregations, and parallel analysis across multiple tables, and when the business can accept higher architectural complexity. Otherwise, operational costs may outweigh the benefits.
Core Summary: This article systematically reconstructs KingbaseES high availability strategies around three architectures: KES primary-standby clusters, read/write splitting, and MPP distributed clusters. It explains replication mechanisms, failover, monitoring optimization, backup and recovery, and architecture selection strategies to help developers build an enterprise database platform that balances consistency, performance, and operational maintainability.