andrej-karpathy-skillsuses aCLAUDE.mdfile to constrain AI coding behavior. Its core goal is to solve common LLM failure modes in software development, including blind assumptions, overengineering, unrelated code changes, and lack of validation. Keywords: AI coding, Karpathy principles, Claude Code.
Technical specifications show the project at a glance
| Parameter | Details |
|---|---|
| Project Name | andrej-karpathy-skills |
| Primary Language | Markdown |
| Core Protocol | CC 4.0 BY-SA (source article); project practice depends on GitHub/Claude Code workflows |
| Star Count | The source mentions roughly 30k+ to 55.5k+, with variation across different snapshots in time |
| Core Dependencies | CLAUDE.md, Claude Code, test frameworks, code review workflows |
| Core Objective | Improve the controllability, interpretability, and verifiability of AI coding |
This project turns AI coding problems into behavioral constraints
andrej-karpathy-skills is not a new model and not a new framework. It is a set of behavioral rules for LLM coding assistants. Its core form is intentionally minimal: write the principles into a single CLAUDE.md file so Claude Code follows engineering discipline before executing tasks.
This design addresses the most practical pain points in AI coding. Models often fill in missing requirements on their own, prefer complex abstractions, casually modify unrelated code, and claim a task is complete without validation. The project’s value does not come from stronger generation capability. It comes from a lower error rate.
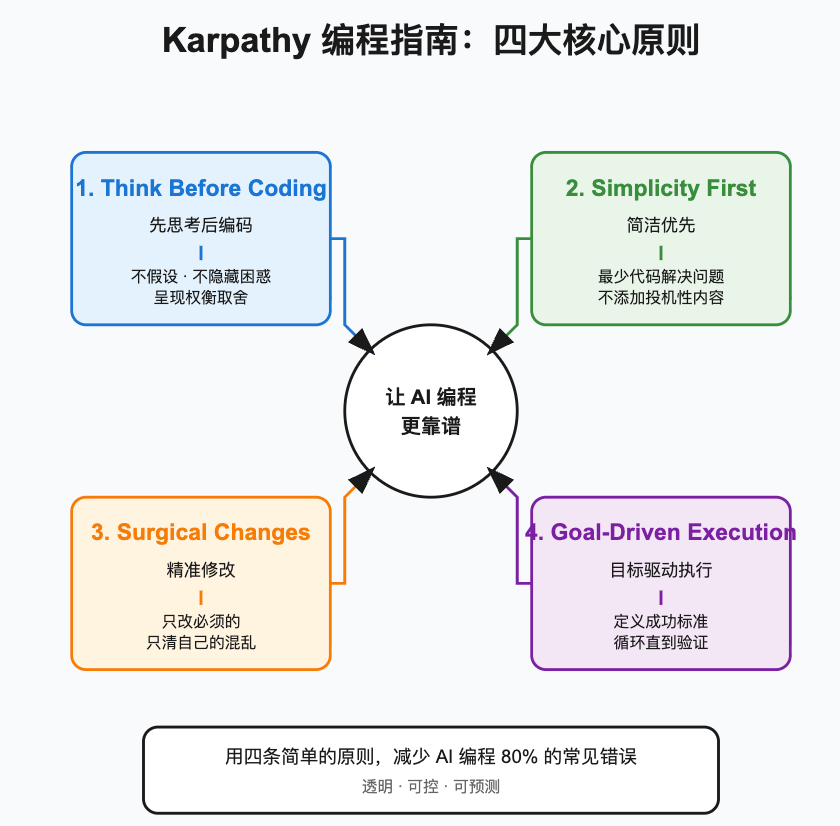 AI Visual Insight: This diagram presents the overall structure of the four behavioral principles as information cards. It emphasizes the full chain from requirement understanding, to complexity control, to scoped code changes, to validation closure, making it a useful overview of an AI coding governance framework.
AI Visual Insight: This diagram presents the overall structure of the four behavioral principles as information cards. It emphasizes the full chain from requirement understanding, to complexity control, to scoped code changes, to validation closure, making it a useful overview of an AI coding governance framework.
The four principles define the boundaries of reliable AI collaboration
First, Think Before Coding requires the model to state assumptions and ambiguities explicitly before writing code. Second, Simplicity First requires it to deliver the minimum viable implementation first. Third, Surgical Changes limits the scope of modifications. Fourth, Goal-Driven Execution emphasizes implementation guided by tests and success criteria.
# CLAUDE.md
1. Think Before Coding: Clarify requirements and assumptions first
2. Simplicity First: Prefer the simplest solution
3. Surgical Changes: Modify only necessary code
4. Goal-Driven Execution: Define validation criteria firstThis configuration turns abstract engineering discipline into the smallest executable rule set an AI assistant can follow.
The four principles map directly to four common AI coding failure modes
Thinking before coding can dramatically reduce rework
The biggest problem with LLMs is not that they cannot write code. It is that they start writing too quickly. If a user says, “Add user authentication,” the model may immediately assume email and password, tack on OAuth, and also include remember-me logic and password-strength checks, ending up far from the actual requirement.
The correct approach is to expose uncertainty first and then ask for confirmation. This converts implicit assumptions into explicit constraints and significantly reduces the probability of implementing the wrong thing.
# Ask the user clarifying questions instead of generating an implementation immediately
questions = [
"Do you need email/password, SMS verification, or third-party login?", # Clarify the authentication method
"Do you need two-factor authentication?", # Clarify the security level
"Should password recovery and remember-me be included?" # Clarify additional features
]
for q in questions:
print(q)This code demonstrates a minimal interaction template for clarifying requirements before development begins.
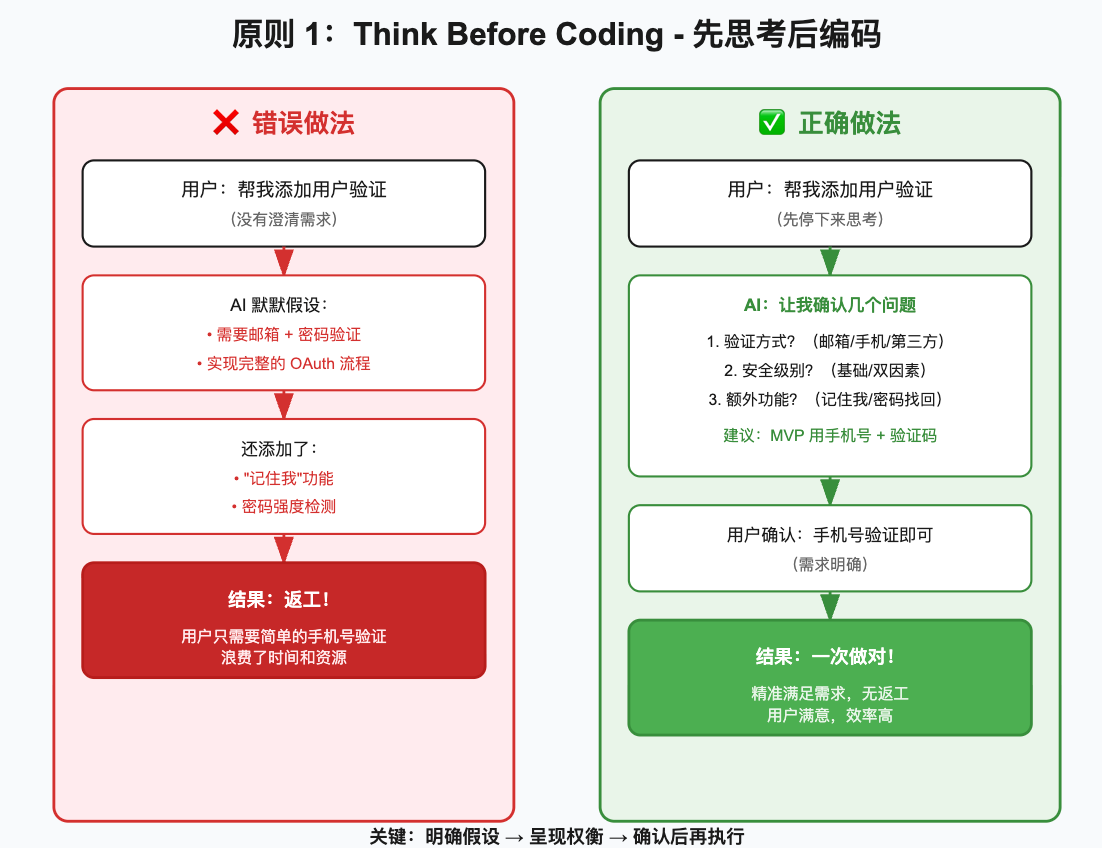 AI Visual Insight: This image focuses on the requirement clarification flow. It emphasizes layered confirmation of authentication method, security level, and additional features before coding, showing an engineering approach that breaks vague requirements into structured decision points.
AI Visual Insight: This image focuses on the requirement clarification flow. It emphasizes layered confirmation of authentication method, security level, and additional features before coding, showing an engineering approach that breaks vague requirements into structured decision points.
Simplicity first suppresses the model’s tendency to overengineer
Many AI-generated code problems are not about correctness. They are about being “too smart.” For a simple validation function, a model might introduce a configuration system, a strategy pattern, a caching layer, and observer interfaces. It looks professional on the surface, but it increases maintenance cost.
Karpathy’s key judgment is simple: do not prepay complexity for future requirements that may never happen. If the current task only needs basic validation, deliver a direct, short, readable function instead of introducing a heavyweight architecture.
def validate_user(email: str, password: str) -> bool:
# Core logic: the email must contain @
if not email or "@" not in email:
return False
# Core logic: the password must be at least 8 characters long
if not password or len(password) < 8:
return False
return TrueThis code completes basic user input validation with the minimum amount of code.
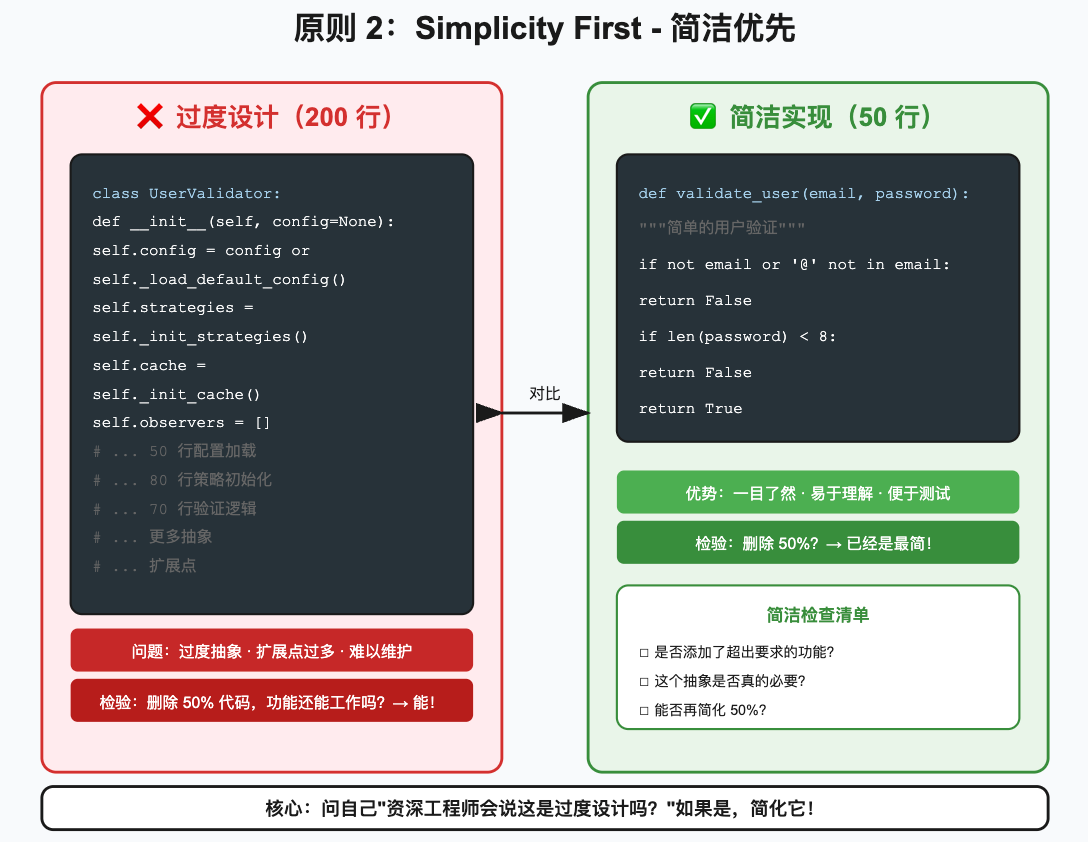 AI Visual Insight: The image highlights the contrast between a complex implementation and a minimal one. It communicates that reducing abstraction layers, lowering state management overhead, and removing unnecessary extension points are core techniques for controlling AI code quality.
AI Visual Insight: The image highlights the contrast between a complex implementation and a minimal one. It communicates that reducing abstraction layers, lowering state management overhead, and removing unnecessary extension points are core techniques for controlling AI code quality.
Surgical changes determine whether AI-generated code deserves to be merged
An AI fixes one bug, then refactors nearby functions, standardizes comment style, and deletes variables it does not understand. This is one of the fastest ways to destroy trust in AI coding. The user asked for a fix, not a rewrite.
At its core, surgical changes constrain the diff boundary. Every changed line must map back to a clear goal. If the model discovers dead code or style issues, it can mention them, but it should not address them without being asked.
- total = price * count
+ total = price * quantity # Fix the incorrect variable reference and change only the bug-related lineThis diff shows a minimal fix that touches only the root cause of the defect.
 AI Visual Insight: This image emphasizes the audit value of small-scope changes. In version control and code review scenarios, localized diffs make it easier to verify causality, identify regression risk, and build developer trust.
AI Visual Insight: This image emphasizes the audit value of small-scope changes. In version control and code review scenarios, localized diffs make it easier to verify causality, identify regression risk, and build developer trust.
Goal-driven execution turns AI from a generator into a closed-loop executor
Weak goals such as “make it work” rarely drive consistent outcomes. Strong goals define inputs, outputs, edge cases, and validation methods explicitly, such as “invalid email returns an error, empty password fails, valid input passes.”
Once success criteria are written as tests, the AI can work inside a fail-fix-retest loop instead of declaring success through language alone. This is also the key leap from “can write code” to “can deliver results.”
import pytest
def validate_user(email: str, password: str) -> bool:
# Core logic: validate email format and password length
return bool(email and "@" in email and password and len(password) >= 8)
def test_validate_user():
assert validate_user("[email protected]", "12345678") is True # Valid input should pass
assert validate_user("invalid", "12345678") is False # Invalid email should fail
assert validate_user("[email protected]", "123") is False # Short password should failThis code turns the “input validation” task into automatically verifiable success criteria.
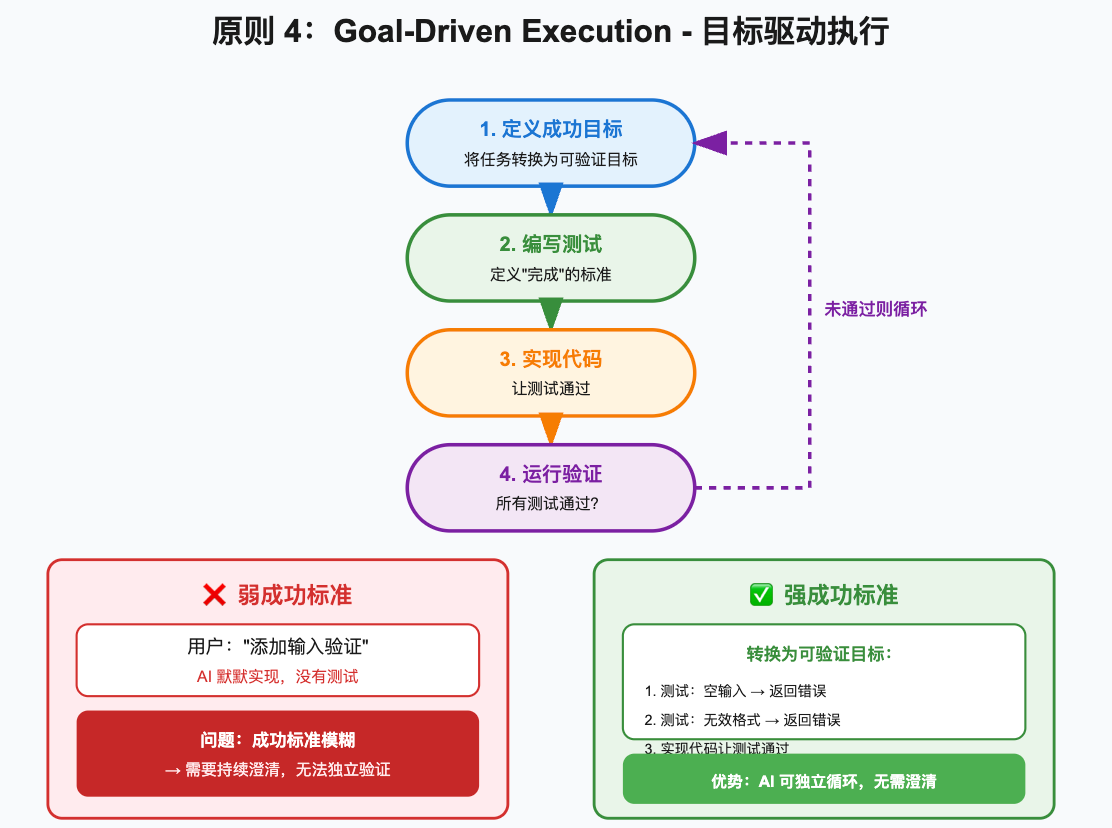 AI Visual Insight: The diagram shows the execution path from goal breakdown, to test writing, to validation closure. It emphasizes that AI development should not stop at code generation. It should enter a reproducible, testable, and regression-friendly engineering workflow.
AI Visual Insight: The diagram shows the execution path from goal breakdown, to test writing, to validation closure. It emphasizes that AI development should not stop at code generation. It should enter a reproducible, testable, and regression-friendly engineering workflow.
These rules work best when embedded in team development workflows
In new feature development, you can first ask the AI to output assumptions and compare solution options, then confirm the minimum implementation path. In bug fixing, require it to reproduce the issue first, then provide the smallest fix, and finally add a regression test. In code review, turn the four principles into a pull request checklist.
A reusable pull request template can strengthen execution consistency
## AI Coding Checklist
- [ ] Key assumptions and ambiguities are explained
- [ ] The simplest implementation for the current task is used
- [ ] The change scope covers only the target requirement
- [ ] Tests or validation steps are providedThis template embeds the four principles directly into the team review workflow and creates a shared acceptance standard.
The real significance of this kind of project is higher trust density in AI coding
The brilliance of andrej-karpathy-skills is that it does not try to make the model more “free.” It makes the model more disciplined. For engineering teams, reliability is often more valuable than creativity.
When AI asks clarifying questions first, writes less, changes only what matters, and can prove correctness, it stops being just a code completion tool. It becomes an auditable, collaborative engineering partner that teams can authorize incrementally. That is the foundation required for production-grade AI coding.
FAQ
1. Which AI coding tools are a good fit for andrej-karpathy-skills?
It fits Claude Code and also works well with tools such as Cursor and Copilot Chat that support system prompts, project rules, or repository-level policy files. The key is not the tool name. The key is whether the tool can continuously read and follow behavioral constraints.
2. Will the four principles slow development down?
They may add a small amount of upfront confirmation cost for trivial tasks, but in real projects they usually reduce rework, rollbacks, and review time significantly. In practice, they trade a small amount of upfront discipline for much higher delivery certainty.
3. How can you tell whether an AI actually followed these principles?
The most practical method is to check three things: whether it clarified requirements explicitly, whether it introduced unnecessary abstraction, and whether it included tests or validation steps. If the diff is large but the goal is small, that usually means it did not follow the rules.
Core Summary: This article reconstructs the core ideas behind andrej-karpathy-skills and systematically explains Karpathy’s four principles for LLM coding: Think Before Coding, Simplicity First, Surgical Changes, and Goal-Driven Execution. It also provides practical prompt patterns, code examples, and team integration methods.