Apache IoTDB is a native time-series database built for massive-scale time-series data. It fits high-frequency data collection scenarios such as Industrial IoT, energy and power systems, connected vehicles, and smart campuses. It addresses the bottlenecks that traditional databases face in high-concurrency writes, low-cost retention, and time-series semantic queries. Keywords: time-series database, Apache IoTDB, Industrial IoT.
The technical specification snapshot provides a quick overview
| Parameter | Details |
|---|---|
| Project Name | Apache IoTDB |
| Primary Language | Java |
| Protocol/License | Apache License 2.0 |
| Typical Protocol Capabilities | SQL-like queries, time-series write interfaces, ecosystem connectivity |
| GitHub Stars | Not provided in the source text; use the official repository for real-time numbers |
| Core Dependencies/Components | ConfigNode, DataNode, TsFile |
| Typical Ecosystem Integrations | Hadoop, Spark, Flink, Grafana |
| Applicable Scenarios | Industrial IoT, energy and power, transportation, smart campuses |
Time-series databases must be evaluated independently in big data environments
In the early stages, enterprises often use relational databases, NoSQL systems, or object storage to hold time-series data. When data volume is small, the limitations are not obvious. Once real production traffic arrives, the bottlenecks surface all at once: continuous append-heavy writes, concurrent ingestion from multiple sources, long-term retention, hot/cold tiering, and time-window analytics.
Time-series data is not just “a regular table with a timestamp.” It requires a database that is natively designed around the write path, compression format, time indexing, and query semantics. Otherwise, the application layer must compensate with large amounts of custom logic, and both system complexity and cost continue to rise.
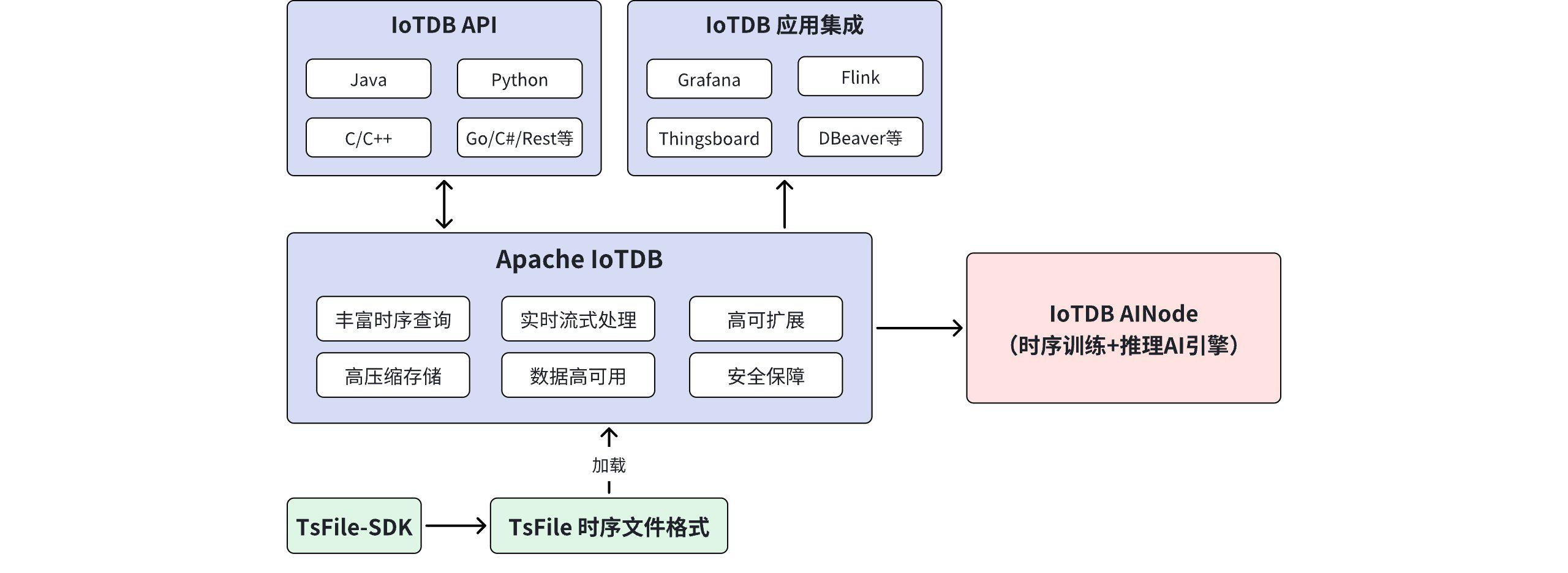
AI Visual Insight: This image is a conceptual illustration centered on time-series database selection. Its main purpose is to highlight IoTDB’s role in a big data architecture: it is not merely a point replacement for a generic database, but a dedicated infrastructure layer that connects device data ingestion, storage compression, analytical querying, and industry applications.
Time-series databases differ fundamentally from general-purpose databases
- Their write pattern centers on sequential appends and high-concurrency ingestion.
- Their query pattern centers on range queries, aggregation, alignment, and replay.
- Their lifecycle emphasizes long-term retention and low-cost compression.
- Their architecture depends more heavily on partitioning, replication, and hot/cold tiering strategies.
-- Aggregate device temperature data by time window
SELECT AVG(temperature)
FROM root.factory.device01
GROUP BY ([2026-04-01, 2026-04-02), 1h);This SQL example shows one of the most common native capabilities of a time-series database: window-based aggregation.
Enterprise evaluation should focus on six decision dimensions
Write throughput determines whether the system can absorb real data streams
As the number of devices grows and sampling intervals shrink, write pressure increases quickly. During evaluation, do not look only at peak TPS. You also need to assess stability under out-of-order writes, concurrent ingestion across many devices, and bulk retransmission over unreliable networks.
Storage compression capability directly determines long-term cost
In many systems, the real bottleneck after launch is not whether data can be written, but whether it can be retained affordably. A production-ready time-series database must provide mature capabilities in file formats, compression strategies, historical archiving, and hot/cold tiering.
Time-series query semantics determine development complexity
Time alignment, downsampling, window analysis, and latest-point queries are all common requirements. If the database does not support them natively, the application layer accumulates large amounts of patchwork logic, and maintenance cost becomes very high.
# Pseudocode: fetch the latest data point for a device
def query_latest_point(client, path):
sql = f"SELECT LAST * FROM {path}" # Core logic: query the latest point
return client.execute(sql) # Core logic: execute the query and return the resultThis example shows that a latest-point query is a typical native time-series capability.
Cluster scalability and high availability cannot be postponed until after launch
When a system moves from PoC to production, the database’s ability to scale smoothly from a single node to a cluster, along with its replication and fault-tolerance mechanisms, determines whether it can serve as a real data foundation.
Ecosystem interoperability determines platform integration cost
Enterprises do not deploy only one database. They usually need to connect Spark, Flink, Grafana, and other analytics or visualization components. A database therefore needs strong ecosystem compatibility.
Operational complexity directly affects delivery speed
Parameter tuning, incident troubleshooting, access control, and cross-environment migration all represent real delivery costs. Products that are technically advanced but operationally difficult often struggle to gain long-term adoption.
Apache IoTDB provides a more balanced engineering solution
IoTDB’s value does not come from being extremely ahead on a single isolated metric. Its value comes from covering the most critical capabilities required for real-world time-series database adoption: ingestion, storage, querying, scalability, and ecosystem integration.
From an architectural perspective, IoTDB supports both standalone and cluster deployment modes. The source text mentions typical forms such as lightweight 1C1D deployment and enterprise-grade 3C3D clusters. That indicates it is not a single-node utility, but a system designed for production-scale expansion.
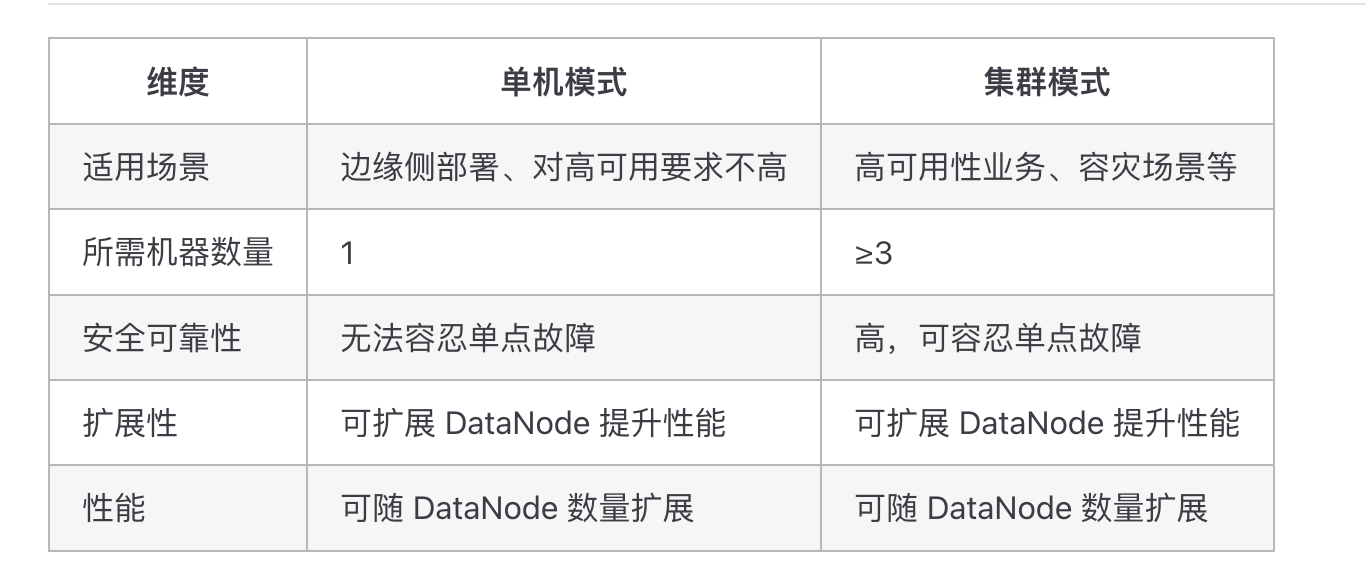
AI Visual Insight: This image presents an architectural view of IoTDB in distributed or enterprise environments. It typically highlights concepts such as ConfigNode, DataNode, partitions, and replicas, showing how control nodes and data nodes divide responsibilities for metadata management, data storage, and highly available scaling.
TsFile strengthens IoTDB’s native time-series foundation
IoTDB is not just a database service. It also includes Apache TsFile, a time-series file format. TsFile optimizes the underlying storage layer from the beginning around the compression, organization, and read patterns of time-series data. That is especially important for long-term retention of massive historical datasets.
Hierarchical modeling aligns better with industrial equipment structures
Industrial environments commonly use tree-shaped structures such as campus-line-device-measurement point. IoTDB’s hierarchical management model aligns more naturally with this type of data organization, which helps reduce metadata management cost and improves query targeting efficiency.
-- Create device measurements and write time-series data
CREATE TIMESERIES root.plant.line1.device1.temperature WITH DATATYPE=FLOAT, ENCODING=RLE;
INSERT INTO root.plant.line1.device1(timestamp, temperature) VALUES(1713974400000, 36.5);This SQL example shows the basic way IoTDB manages time-series data through a device-tree model.
IoTDB integrates with the big data ecosystem more effectively for enterprise platform building
The source text explicitly states that IoTDB can integrate with Hadoop, Spark, Flink, and Grafana. That means it can function not only as a time-series storage engine, but also as part of batch processing, stream processing, and visualization pipelines, reducing the cost of secondary integration inside the enterprise.
This matters even more for teams that already operate an existing data platform. During evaluation, the key question is whether the database can fit into the current architecture, not whether a standalone benchmark looks impressive.

AI Visual Insight: This image corresponds to the path from open-source capability to enterprise-grade adoption. It usually emphasizes the relationship between IoTDB’s open-source technology stack and its commercial extension path, highlighting areas such as visualized operations, industry solutions, service support, and production delivery.
A clear upgrade path exists from open-source trial to enterprise production
IoTDB is a strong starting point for enterprise time-series database pilots. Teams can first validate the data model, ingestion pipeline, and query semantics, and then decide whether to move into a more demanding formal production phase.
Once the system enters core business workflows, the focus shifts from “Can we use it?” to “Does it provide stronger SLAs, operational tooling, and vendor support?” Based on the source text, Timecho offers this enterprise continuation path, including a visual console, system monitoring, and technical support services.
The recommended rollout strategy is phased implementation
- Use the open-source edition to complete PoC work and validate the data model.
- Use real business traffic to validate ingestion, compression, and query performance.
- Evaluate high availability, monitoring, and service assurance before production.
- If the project has strong delivery requirements, then assess the supporting capabilities of the enterprise edition.
# Download the Apache IoTDB package
wget https://iotdb.apache.org/zh/Download/
# Core logic: first access the official distribution entry, then choose a version for your environment
# Core logic: during the PoC phase, prioritize validating the install-ingest-query loopThis command example shows that IoTDB trials typically begin from the official distribution entry point.
Choosing a time-series database is fundamentally a production-system decision
Choosing a time-series database is not about comparing which project is more popular. It is about determining which one can absorb data growth over the next several years with more stability. You must evaluate write capability, compression cost, time-series semantics, scalability, ecosystem interoperability, and operational complexity as a whole.
Based on the source text, Apache IoTDB stands out for its clear architecture, native time-series design, ecosystem friendliness, and continuous evolution path from open source to enterprise-grade deployment. For Industrial IoT and big data scenarios, it deserves priority consideration in any PoC shortlist.
Reference links
- Apache IoTDB open-source download: https://iotdb.apache.org/zh/Download/
- Apache IoTDB official website: https://iotdb.apache.org/zh/
- IoTDB product introduction: https://iotdb.apache.org/zh/UserGuide/latest-Table/IoTDB-Introduction/IoTDB-Introduction_apache.html
FAQ
FAQ 1: Why not use MySQL or a general-purpose NoSQL database directly for time-series data?
Because the core pressure of time-series data is not just storage. It also includes high-frequency append writes, long-term compressed retention, and time-oriented query semantics. General-purpose databases can store the data, but they usually struggle to balance cost, performance, and development complexity.
FAQ 2: Which scenarios are the best fit to evaluate Apache IoTDB first?
It is well suited to high-frequency data collection scenarios such as Industrial IoT, energy and power, connected vehicles, and smart campuses, especially where device-tree hierarchies are complex, historical data must be retained for long periods, and the business depends on time-window analytics.
FAQ 3: What is the relationship between the open-source IoTDB edition and the enterprise path?
The open-source edition is suitable for technical validation and foundational production capability building. When the project moves into a phase that requires higher SLAs, centralized operations, visual management, and vendor support, teams can further evaluate enterprise products and service systems built on IoTDB.
Core summary
This article reconstructs the evaluation logic for Apache IoTDB from the perspective of big data and Industrial IoT scenarios. It focuses on six dimensions: write throughput, compressed storage, time-series querying, cluster scalability, ecosystem interoperability, and operational cost. It also explains the enterprise evolution path from IoTDB to Timecho.