[AI Readability Summary] Claude Opus 4.7 is Anthropic’s new flagship model. Its biggest gains focus on code generation, image and chart understanding, self-verification for long-running tasks, and stricter instruction following. These improvements target three persistent enterprise pain points: instability in complex engineering work, insufficient precision on visual inputs, and agent workflows that still require heavy supervision. Keywords: Claude Opus 4.7, AI coding, model safety.
The technical specification snapshot highlights its product positioning
| Parameter | Details |
|---|---|
| Model | Claude Opus 4.7 |
| Vendor | Anthropic |
| Primary capabilities | Coding, visual understanding, agents, code review |
| Input pricing | $5 per million tokens |
| Output pricing | $25 per million tokens |
| Image support | Up to 2576 pixels on the long side, about 3.75 MP |
| Representative benchmarks | Vals Index, SWE-bench Pro, OSWorld, GPQA |
| Core dependencies | Claude Code, task budgets, auto mode, safety interception mechanisms |
| Protocols / interfaces | API calls, tool calling, agent workflows |
| GitHub stars | Not provided in the source |
| Languages | English / multilingual |
Claude Opus 4.7 turns “more capable” into “more deliverable”
Claude Opus 4.7 is not a routine tuning update. Its most important change is that the model now performs self-checks before returning outputs, reducing the uncertainty of a “finish and immediately ship” workflow. That matters most in long-chain development, automated remediation, and complex task agents.
The source material makes Anthropic’s direction clear: it is no longer optimizing only for leaderboard wins. Instead, it is aligning model capabilities directly with enterprise pain points, including complex repository fixes, chart reading, computer use, and low-supervision execution.
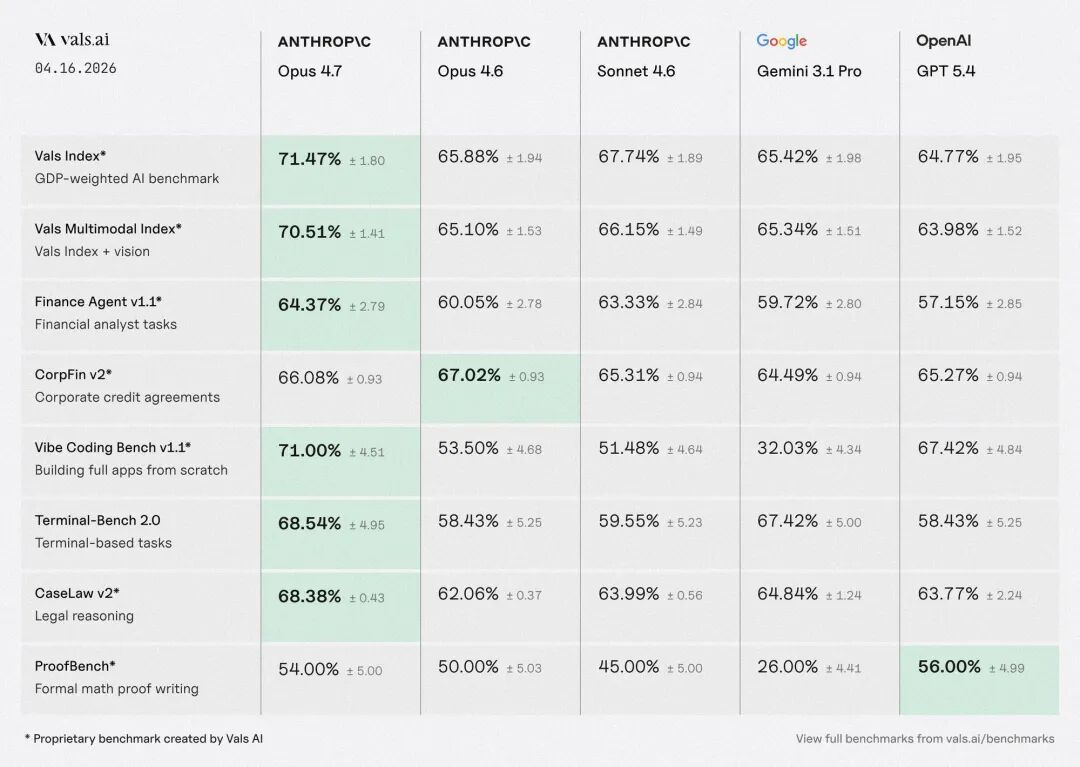 AI Visual Insight: The image shows Claude Opus 4.7 leading across several composite evaluations, with a particularly notable jump on benchmarks such as Vals Index. This suggests stronger consistency across tasks, better holistic reasoning, and improved engineering performance in real-world scenarios.
AI Visual Insight: The image shows Claude Opus 4.7 leading across several composite evaluations, with a particularly notable jump on benchmarks such as Vals Index. This suggests stronger consistency across tasks, better holistic reasoning, and improved engineering performance in real-world scenarios.
The coding jump is the most meaningful upgrade for engineering teams
On SWE-bench Pro, version 4.7 improves from 53.4% to 64.3%. This is not toy lab data. It reflects stronger bug-fixing performance on real GitHub projects with complex dependencies and messy codebases, which means the model is closer to a collaborative engineering assistant that can actually ship work.
SWE-bench Verified also rises from 80.8% to 87.6%. Combined with CodeRabbit’s test results, version 4.7 improves recall for hard-to-detect bugs by more than 10% without a meaningful increase in false positives. In practice, that makes it more reliable across review, repair, and refactoring tasks.
# Simulate a 4.7-style bug-fix workflow
def fix_bug(repo_context, issue):
plan = analyze_issue(repo_context, issue) # First analyze the issue and dependency relationships
patch = generate_patch(plan) # Then generate the patch
result = run_tests(patch) # Automatically run validation tests before submission
if not result["passed"]:
patch = revise_patch(patch, result) # If tests fail, revise the patch based on feedback
return patchThis example captures the core improvement in 4.7: generate first, verify next, then revise.
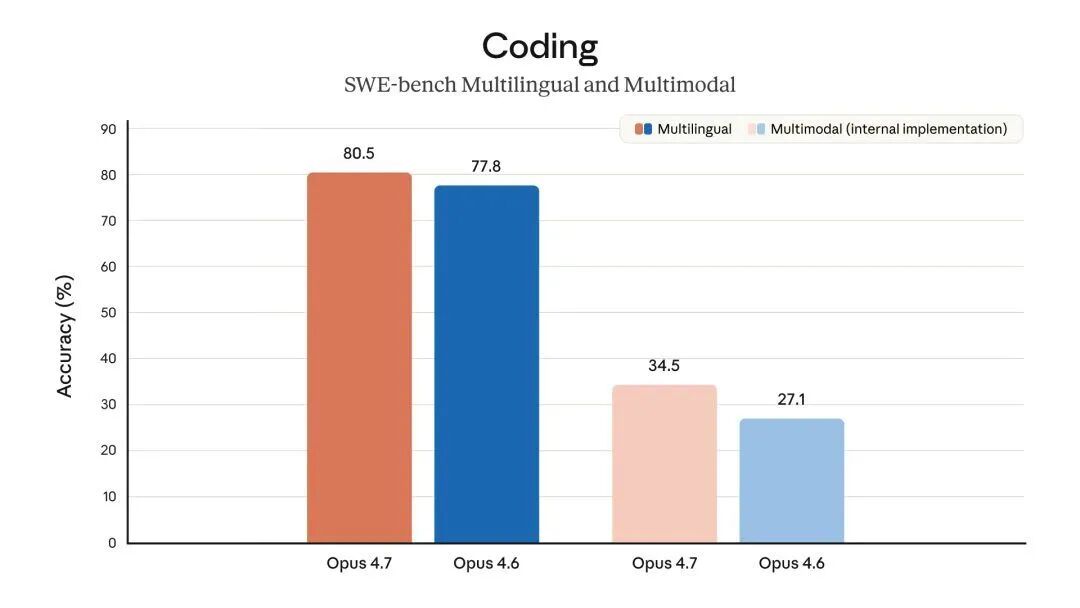 AI Visual Insight: The image compares 4.7 with 4.6 on software engineering benchmarks. It highlights 4.7’s gains in real-repository defect resolution, standard programming tasks, and overall engineering capability, indicating better performance on multi-step debugging in large codebases.
AI Visual Insight: The image compares 4.7 with 4.6 on software engineering benchmarks. It highlights 4.7’s gains in real-repository defect resolution, standard programming tasks, and overall engineering capability, indicating better performance on multi-step debugging in large codebases.
Instruction following is stronger, but older prompts may break
A major weakness in 4.6 was that it could be too “clever.” It often rewrote ambiguous instructions into what it believed was a better solution. Version 4.7 moves in the opposite direction: it follows instructions more literally and reduces unnecessary improvisation. For production systems, that is usually a net benefit because predictable behavior matters more than occasional flashes of creativity.
But the tradeoff is real. Many prompts optimized for 4.6 may stop working well. Prompt engineering will shift away from “leave room for the model to infer intent” and toward “define constraints explicitly, lock output structure, and specify acceptance criteria up front.”
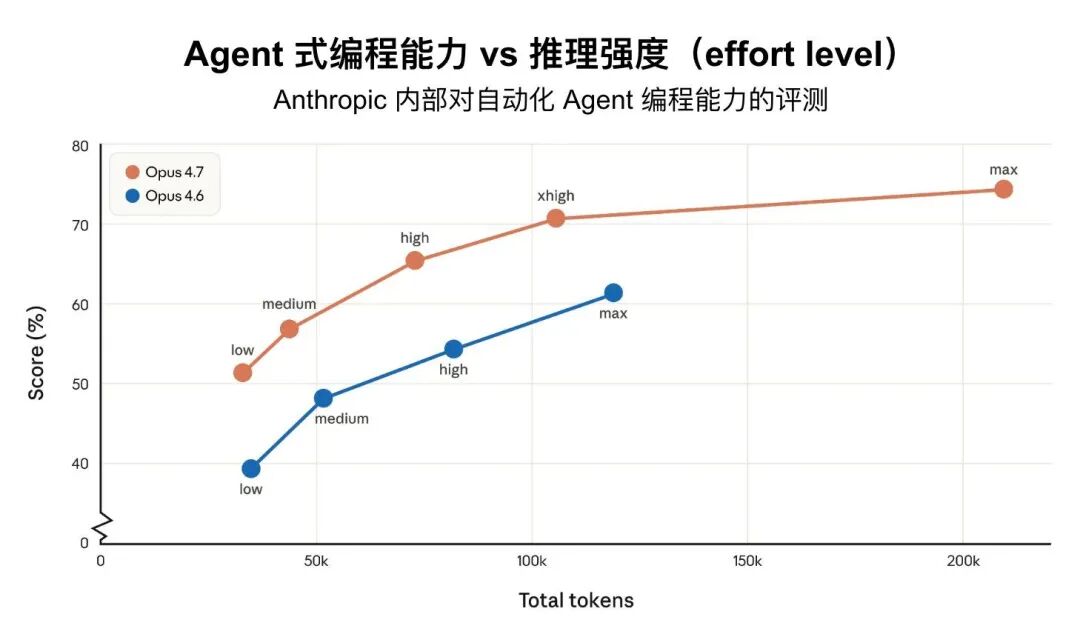 AI Visual Insight: The image emphasizes a behavioral shift in instruction execution: the model is moving away from inferring user intent and toward following constraints line by line. That implies workflow design now requires clearer input specifications and tighter output boundaries.
AI Visual Insight: The image emphasizes a behavioral shift in instruction execution: the model is moving away from inferring user intent and toward following constraints line by line. That implies workflow design now requires clearer input specifications and tighter output boundaries.
Improvements in vision and agent capabilities make it feel more like a true execution model
Version 4.7 supports image inputs up to 2576 pixels on the long side, and its visual reasoning score increases from 69.1% to 82.1%. That means screenshots of reports, UI mockups, and complex architecture diagrams are no longer just “visible” to the model. It can extract structure, identify anomalies, and participate in decision-making.
OSWorld increases from 72.7% to 78.0%, which indicates more stable performance in computer-use tasks such as browser clicking, form filling, and interface reading. When visual understanding and operational execution improve together, the model starts to resemble a more complete form of digital labor.
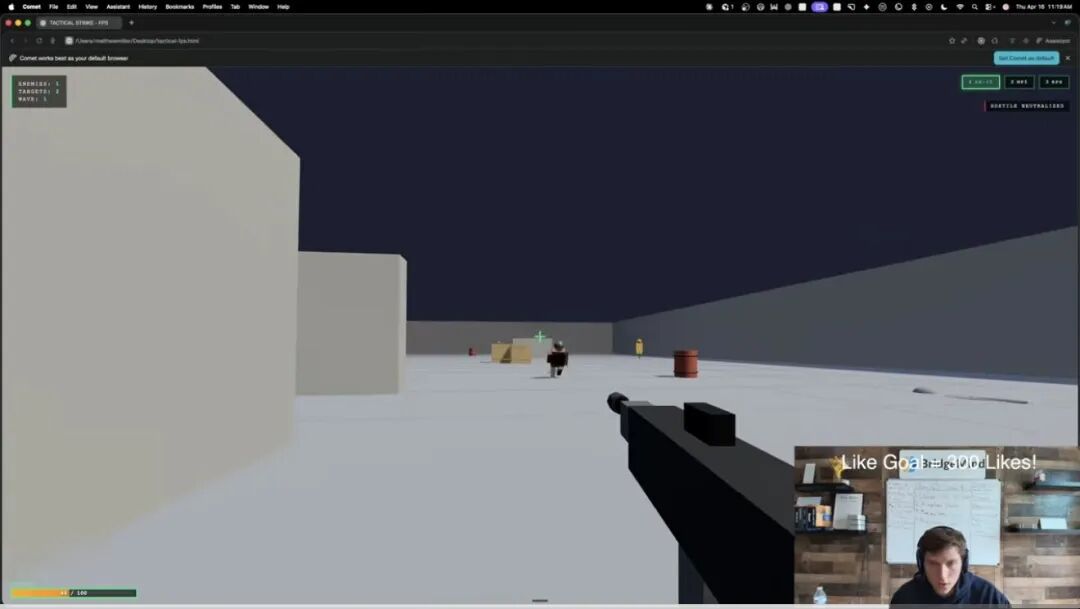 AI Visual Insight: The image shows an AI-generated interactive 3D/FPS game, including scene rendering, weapon systems, and enemy mechanics. It suggests that 4.7 can already translate natural language requirements into front-end graphics logic, game loops, and interaction code.
AI Visual Insight: The image shows an AI-generated interactive 3D/FPS game, including scene rendering, weapon systems, and enemy mechanics. It suggests that 4.7 can already translate natural language requirements into front-end graphics logic, game loops, and interaction code.
<!DOCTYPE html>
<html>
<body><script>
// Initialize a simple game scene based on a text prompt
const game = { weapon: "rifle", enemies: 5, score: 0 };
// Simulate an AI-generated core loop
function tick() { console.log("render", game); }
setInterval(tick, 1000);
</script>
</body>
</html>This example shows how the model can quickly assemble runnable prototypes in “vibe coding” scenarios.
The Claude Code update completes the developer workflow loop
The Claude Code release that arrived alongside 4.7 matters just as much. The new /ultrareview command targets deep code review and is useful for uncovering design flaws and hidden errors. At the same time, the default reasoning intensity moved from high to xhigh, creating a new balance point between cost and quality.
With task budgets entering public beta, long-running tasks finally become controllable. Developers can set token ceilings for agents and prevent unattended automation from generating runaway bills. That is one of the key requirements for enterprise adoption of AI coding tools.
 AI Visual Insight: The image reflects how Claude Code differs from competing products across large-scale codebases, benchmarks, and human-in-the-loop collaboration patterns. It especially highlights that Claude depends on high-quality operator orchestration rather than fully unsupervised execution.
AI Visual Insight: The image reflects how Claude Code differs from competing products across large-scale codebases, benchmarks, and human-in-the-loop collaboration patterns. It especially highlights that Claude depends on high-quality operator orchestration rather than fully unsupervised execution.
Tighter safety controls are not a regression but a governance signal on the road to AGI
One easy mistake when evaluating 4.7 is to interpret its slightly weaker performance on cybersecurity vulnerability reproduction as a loss of capability. The source explicitly says otherwise. Anthropic is intentionally experimenting with differential capability reduction and embedding automatic identification and interception mechanisms into the model.
That sends a strong signal. As the model keeps improving across coding, vision, and agent execution, the vendor is also applying finer-grained controls to high-risk capabilities. Project Glasswing and the Cyber Verification Program suggest that Anthropic is not taking a one-size-fits-all approach. Instead, it is tightening access for general users while preserving pathways for compliant research.
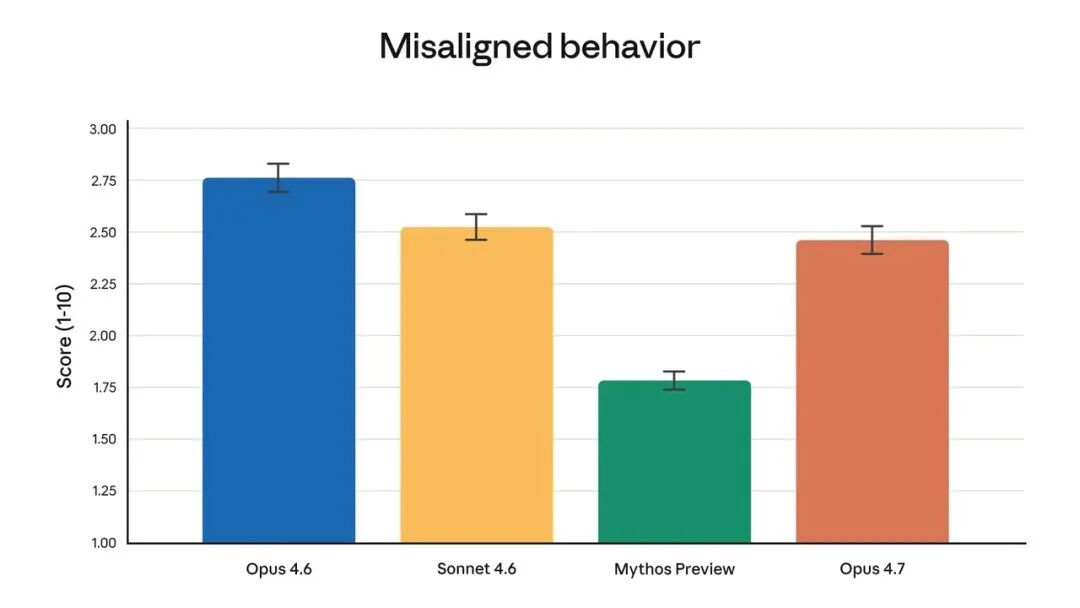 AI Visual Insight: The image presents Anthropic’s safety strategy or risk governance framework. Its core message is that the company uses model tiering, protection mechanisms, request interception, and verification programs to selectively control high-risk cybersecurity capabilities.
AI Visual Insight: The image presents Anthropic’s safety strategy or risk governance framework. Its core message is that the company uses model tiering, protection mechanisms, request interception, and verification programs to selectively control high-risk cybersecurity capabilities.
# Add explicit auditing and budget control for high-risk tasks
claude-code run audit-task \
--mode auto \
--budget 20000 \
--policy safe-reviewThese control parameters show that as model capability increases, engineering teams must introduce governance constraints at the workflow level as well.
Commercial growth shows that 4.7 is built for enterprise production environments
From traffic growth and enterprise payment penetration to annualized revenue, Anthropic has entered a phase of rapid expansion. The source notes that both its enterprise customer share and the number of high-spend customers are rising quickly. That helps explain why 4.7 is not primarily optimized to be “better at chatting,” but to be “better at delivering work.”
For team leaders, 4.7 is well suited to code generation, code review, chart parsing, automated agents, and complex document understanding. For workflows that depend heavily on web retrieval, however, you should run staged tests first because the BrowseComp metric declined.
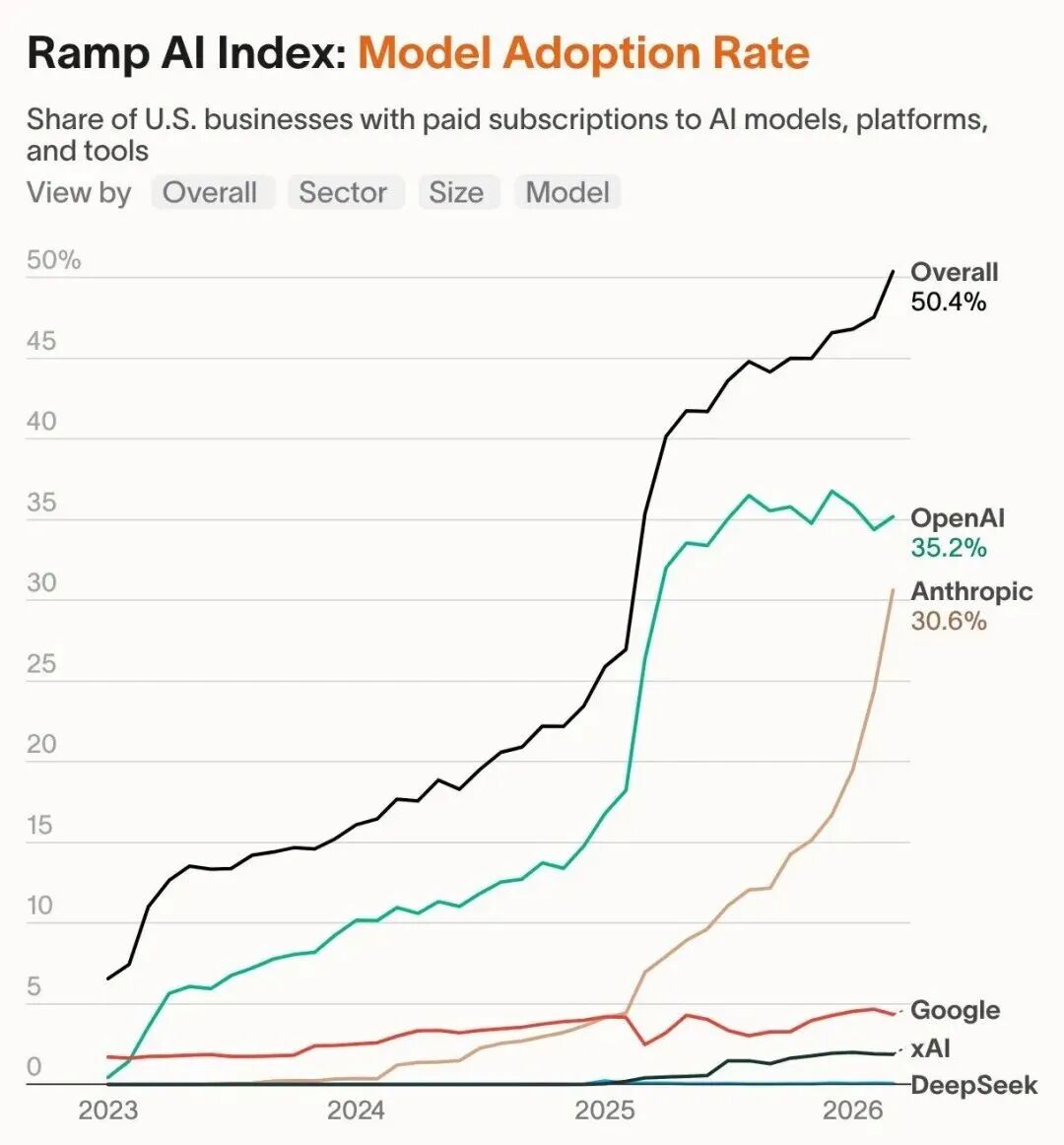 AI Visual Insight: The image likely shows enterprise adoption or revenue growth trends, emphasizing Anthropic’s increasing share in the enterprise market and the speed of its commercial expansion. It suggests that model improvements are already translating directly into SaaS purchases and developer platform spending.
AI Visual Insight: The image likely shows enterprise adoption or revenue growth trends, emphasizing Anthropic’s increasing share in the enterprise market and the speed of its commercial expansion. It suggests that model improvements are already translating directly into SaaS purchases and developer platform spending.
The practical conclusion for developers is to upgrade the workflow along with the model
If your core tasks involve writing code, fixing bugs, running agents, or reading charts, Claude Opus 4.7 deserves priority evaluation. If your workflow relies heavily on older prompts, web search, or highly open-ended speculative generation, you should run migration tests before rollout.
The real shift is not just that the model is stronger. It is that model vendors are now bundling capability, safety, cost, and verification into a new delivery framework. Claude Opus 4.7 is not only a stronger model release; it is also an early signal that AI software engineering is entering a governance-first era.
FAQ
Q1: Which scenarios justify upgrading to Claude Opus 4.7 first?
A1: The highest-priority scenarios are complex programming, real-repository fixes, code review, chart understanding, and computer-use agents. If your workflow emphasizes low-supervision execution, 4.7 delivers the clearest gains.
Q2: Why do some cybersecurity metrics decline even though 4.7 is stronger overall?
A2: Because Anthropic is deliberately constraining certain capabilities. The goal is to route high-risk cybersecurity operations through interception and verification mechanisms as the model approaches stronger general-purpose ability. This is a governance upgrade, not a simple performance regression.
Q3: What should teams watch for when migrating from 4.6 to 4.7?
A3: Review legacy prompts first. Version 4.7 follows literal instructions more strictly, so you should define output formats, boundary conditions, acceptance criteria, and retry logic explicitly. For long-running tasks, you should also configure budget and audit policies.
Core takeaway: Claude Opus 4.7 delivers meaningful gains in coding, visual understanding, and autonomous long-task execution, with measurable improvements on SWE-bench Pro, image reasoning, and computer-use benchmarks. At the same time, Anthropic is intentionally reducing some cybersecurity capabilities and adding verification mechanisms, signaling that safety is being treated as a first-class concern on the path toward AGI.