[AI Readability Summary] The core story of DeepSeek V4 is not a one-time increase in parameter count. It is a three-front upgrade across long-term memory, trillion-scale training stability, and domestic AI compute adaptation. The model appears designed to address three major pain points in large language models: forgetting over long contexts, instability in ultra-large-scale training, and dependence on the CUDA ecosystem. Keywords: Engram ECM, mHC, CANN.
The technical specification snapshot highlights the current picture
| Parameter | Details |
|---|---|
| Model Name | DeepSeek V4 (compiled from public information) |
| Primary Languages | Python, C++, and low-level CUDA/CANN-related stacks |
| Architecture Type | MoE sparse expert model |
| Estimated Parameter Scale | About 1T |
| Active Parameters | About 37B |
| Context Window | Up to 1M tokens |
| Coding Benchmark | SWE-bench Verified > 80% (pending official confirmation) |
| Runtime Protocol / Ecosystem | Migrating from CUDA to CANN, adapted for the Ascend ecosystem |
| Open Source Status | Expected to continue the open-source path |
| Star Count | Not provided in the source |
| Core Dependencies | Transformer, MoE, sparse attention, CANN, Ascend chips |
DeepSeek V4 matters because its roadmap is changing, not just its metrics
DeepSeek V4 has drawn attention not only because it approaches the trillion-parameter range, but because it appears to make structural changes across memory mechanisms, training stability, and chip ecosystem support at the same time. For domestic large models in particular, that matters more than simply posting a higher benchmark score.
The source material suggests that V4 may close capability gaps in long-term memory, multimodality, AI search, and engineering-grade coding, while continuing DeepSeek’s low-price strategy. That means it is not targeting a single benchmark. It is targeting the practical usability boundary of a general-purpose model.
 AI Visual Insight: This image serves as the article’s hero visual. It emphasizes DeepSeek V4’s positioning as a next-generation foundation model teaser, typically used to signal a version transition, release window, and market attention rather than specific architectural details.
AI Visual Insight: This image serves as the article’s hero visual. It emphasizes DeepSeek V4’s positioning as a next-generation foundation model teaser, typically used to signal a version transition, release window, and market attention rather than specific architectural details.
A simple configuration object helps explain its focus areas
v4_focus = {
"memory": "Engram ECM", # Long-term memory to reduce forgetting over long contexts
"stability": "mHC", # Improved stability for trillion-parameter training
"compute": "CANN", # Migration from CUDA to a domestic compute stack
"coding": "SWE-bench > 80%" # Major improvement in coding ability
}This code snippet summarizes the four core dimensions to watch in DeepSeek V4.
Engram ECM is decoupling knowledge storage from reasoning
The core limitation of a traditional Transformer is that it compresses most knowledge into model parameters, while long-context handling still depends on attention allocation. As the context grows, attention weights assigned to distant tokens decay, and important facts become easier to lose. That is the familiar form of model forgetfulness.
The source makes a clear claim: Engram ECM is not just about extending the context window. It is about redesigning how the model accesses knowledge. It separates static knowledge from dynamic reasoning so the model behaves more like a system taking an open-book exam than one relying entirely on memorization.
AI Visual Insight: This figure shows the standard attention formula. The key idea is that the relevance between Query and Key is normalized by softmax and then applied to Value. In extremely long contexts, distant tokens are often weakened because their scores become too low, which hurts retrieval quality.
 AI Visual Insight: This diagram shows the collaboration between external conditional memory and the main reasoning backbone. The key point is not parameter expansion, but enabling the model to access memory units on demand during generation, reducing both long-context information washout and the cost of knowledge updates.
AI Visual Insight: This diagram shows the collaboration between external conditional memory and the main reasoning backbone. The key point is not parameter expansion, but enabling the model to access memory units on demand during generation, reducing both long-context information washout and the cost of knowledge updates.
According to the source data, in Needle-in-a-Haystack scenarios, Engram ECM can still maintain about 94% recall at the 1M-token scale, clearly outperforming a standard Transformer. The most important point here is not the absolute number. It is the slower degradation curve.
The difference between Engram and RAG can be simplified like this
def compare_memory(mode: str) -> str:
if mode == "Engram":
return "An external memory mechanism deeply integrated during training" # Lower latency, more native to the architecture
if mode == "RAG":
return "An engineering enhancement based on temporary retrieval during inference" # Flexible, but with a longer pipeline
return "Unknown mode"This snippet shows the distinction clearly: Engram behaves more like an architectural capability, while RAG behaves more like an inference-time add-on.
mHC hyper-connections matter because they make trillion-scale models less likely to collapse during training
Once a model reaches the 1T scale, engineering problems quickly begin to outweigh algorithmic ones. As depth increases and the gradient path gets longer, the probability of vanishing and exploding gradients rises sharply. Training stability becomes a hard requirement, not an optimization target.
The source notes that mHC introduces cross-layer hyper-connections and manifold constraints to add fast paths through deep networks, so information does not rely entirely on a fragile layer-by-layer propagation chain. In practice, this design acts like stability insurance for ultra-deep networks.
AI Visual Insight: This figure describes the chain-like way gradients propagate from higher layers back to lower layers in deep networks. If the local derivative at any layer becomes too large or too small, repeated multiplication across many layers can amplify the problem into training instability.
 AI Visual Insight: This diagram shows cross-layer connections, hierarchical context, and stability constraints working together. The technical goal is to shorten signal paths, reduce deep error accumulation, and preserve convergence quality and training reproducibility at extreme parameter scales.
AI Visual Insight: This diagram shows cross-layer connections, hierarchical context, and stability constraints working together. The technical goal is to shorten signal paths, reduce deep error accumulation, and preserve convergence quality and training reproducibility at extreme parameter scales.
The source claims that mHC reduces the training collapse rate of trillion-parameter models from about 23% to below 1%, with only about 6.7% additional overhead. If those formal results hold, this would be a more meaningful engineering breakthrough than a few extra benchmark points.
Pseudocode makes the role of mHC easier to understand
def mhc_forward(x, layers):
hidden = x
skip_bank = []
for i, layer in enumerate(layers):
hidden = layer(hidden) # Standard forward pass for the current layer
if i % 4 == 0:
skip_bank.append(hidden) # Periodically cache cross-layer states
if skip_bank:
hidden = hidden + 0.1 * skip_bank[-1] # Improve stability through hyper-connections
return hiddenThis code demonstrates how reusing cross-layer states can shorten the information propagation path.
Migrating from CUDA to CANN means more than a routine backend adaptation
One of the most important signals in the source is that DeepSeek V4 is described as undergoing a deep migration to Huawei Ascend and the CANN stack. This is not just about supporting one more backend. It is about rebinding the model to a new training and inference foundation.
If a model depends on CUDA over the long term, then compute supply, toolchains, operator optimization, and deployment frameworks all become tied to a single ecosystem. Moving to CANN is difficult not only because operators must be rewritten, but because numerical precision, performance consistency, and full-stack optimization all need to be revalidated.
From an industry perspective, this suggests that a domestic large model is trying, perhaps for the first time at the trillion scale, to prove that iteration can continue outside Nvidia’s primary ecosystem. It may not deliver an immediate performance advantage, but it could redefine the upper bound of technological self-reliance.
The coding gains suggest V4 is moving closer to a software engineering agent
If the reported SWE-bench Verified score above 80% is confirmed, then DeepSeek V4’s capability boundary has moved beyond code completion into real issue resolution. The value of this benchmark is that it requires the model to understand repository context, fix bugs, and pass tests.
At the same time, the combination of DSA and Lightning Indexer suggests that V4 is not optimizing only for whether it can write code. It is also reducing the cost of handling extremely long engineering context efficiently. That matters a great deal for repository-scale tasks.
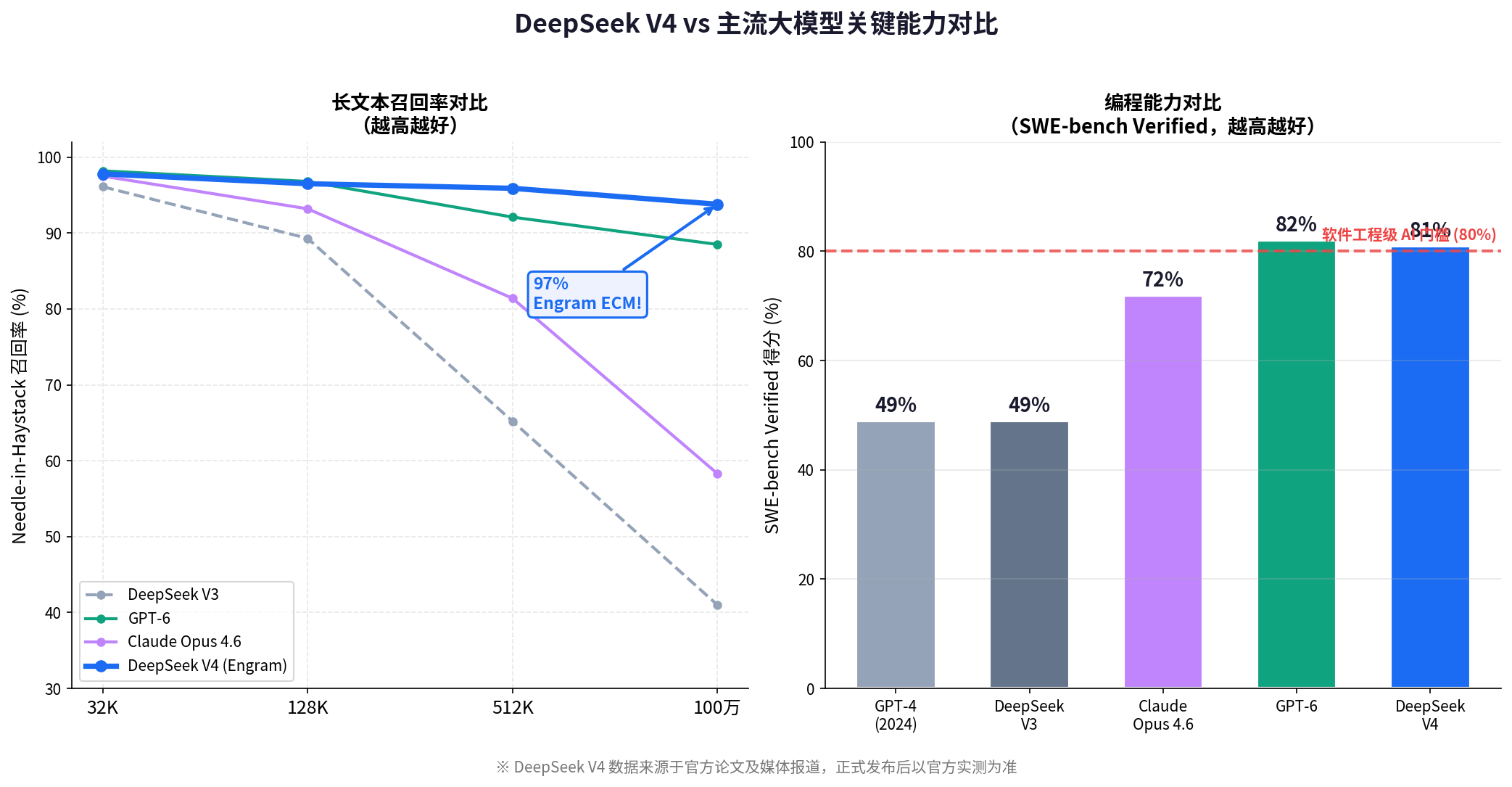 AI Visual Insight: This figure compares multiple models across parameter scale, context window, long-text recall, coding ability, and chip ecosystem support. Technically, it is trying to show that DeepSeek V4’s competitiveness comes from multidimensional balance rather than absolute leadership in just one metric.
AI Visual Insight: This figure compares multiple models across parameter scale, context window, long-text recall, coding ability, and chip ecosystem support. Technically, it is trying to show that DeepSeek V4’s competitiveness comes from multidimensional balance rather than absolute leadership in just one metric.
A simple complexity comparison explains why sparse attention matters
def attention_cost(n: int, k: int) -> dict:
return {
"full_attention": n * n, # Standard attention is approximately O(n^2)
"sparse_attention": n * k # Sparse attention is approximately O(n*k)
}This snippet shows why sparse attention is a prerequisite for million-token feasibility.
DeepSeek V4’s moat comes from three stacked layers
The first layer is cost efficiency. A low price makes it easier for the model to enter search, customer support, knowledge systems, and enterprise API scenarios. But this moat is not durable on its own, because global vendors can respond with price competition.
The second layer is technical originality. If Engram and mHC are validated in practice, that would show DeepSeek moving from being an efficient engineering implementer to being a contributor of architectural innovation. That would significantly raise its weight in citation and reproduction.
The third layer is its binding to the domestic chip ecosystem. Once the model, framework, operators, and chips are optimized together, the competitive barrier is no longer just papers or parameter counts. It becomes a software-hardware co-optimization asset, which is the deepest moat of the three.
DeepSeek V4 looks more like a system-level upgrade than a bigger model
Taken together, the central narrative of DeepSeek V4 is not simply bigger. It is more stable, remembers more over long contexts, writes code better, and is more technologically independent. It is trying to answer three difficult questions at once: long-context memory, trillion-scale training viability, and the practicality of domestic AI compute.
For developers, the most important things to watch are not teaser-stage numbers, but three concrete validations: the real recall stability of Engram, inference efficiency on the CANN stack, and whether the SWE-bench results can be reproduced in real repositories.
FAQ structured Q&A
Q1: Which is better for enterprise knowledge Q&A, Engram ECM or traditional RAG?
Engram is better suited to model-level memory designs that prioritize low latency and deep integration. RAG is better suited to fast integration with existing knowledge bases. The former is an architectural upgrade, while the latter is an engineering deployment strategy.
Q2: Why does mHC matter more than simply adding more parameters?
Because a trillion-scale model has to train stably before anything else. mHC addresses convergence and training collapse. Without stability, neither larger parameter counts nor stronger benchmark results can be sustained.
Q3: What practical impact does moving from CUDA to CANN have on developers?
In the short term, migration costs go up and teams need to learn a new toolchain. In the long term, it opens new opportunities in domestic inference deployment, compute substitution, and software-hardware co-optimization.
Core Summary: This article reconstructs the key innovations behind DeepSeek V4: Engram ECM for long-term memory, mHC for stable trillion-scale training, migration from CUDA to CANN for domestic AI infrastructure, and the engineering significance behind its leap in coding ability. The goal is to help developers quickly assess both its technical value and the depth of its competitive moat.