[AI Readability Summary]
This dual-backbone detection architecture is designed for object detection by splitting feature extraction into a detail branch and a semantic branch. It also enables early interaction across multiple scales, which helps address the limitations of single-backbone networks, including detail loss, semantic conflicts, and inefficient late-stage fusion in multimodal setups. Keywords: Dual Backbone, YOLO, Multimodal Detection.
Technical Specifications at a Glance
| Parameter | Details |
|---|---|
| Architecture Paradigm | Backbone-Neck-Head |
| Primary Language | Python |
| Task Type | Object Detection / Multimodal Detection |
| Distribution Protocol | GitHub repository distribution / standard PyTorch training workflow |
| Repository URL | https://github.com/tgf123/YOLOv8_improve |
| Stars | Not provided in the source |
| Core Dependencies | PyTorch, YOLO enhancement framework, convolution modules, attention modules |
| Core Capabilities | Dual-path collaboration for single-modal input, heterogeneous fusion for multimodal input, multi-scale interaction |
This Architecture Rewrites the Feature Extraction Logic in Object Detection
The core issue with traditional single-backbone models is not insufficient depth, but conflicting objectives. Shallow layers must preserve edges, textures, and local contrast, while deeper layers must abstract class semantics and contextual relationships. When both signals share a single backbone, the training objectives naturally compete with each other.
This directly leads to three practical engineering issues: missed detections for small objects, false positives in complex backgrounds, and fusion distortion in multimodal scenarios. In industrial defect inspection, nighttime surveillance, and medical lesion detection in particular, a single path struggles to balance localization precision and semantic discrimination at the same time.
The Design Goals of Dual-Path Collaboration Are Explicitly Separated
Rather than simply stacking two backbones, the author redefines the responsibilities of the two branches: one extracts high-level semantics, and the other preserves fine-grained details. At the same time, both branches interact lightly across multiple scales so they do not become isolated parallel encoders.
class DualBackboneDetector(nn.Module):
def __init__(self, semantic_backbone, detail_backbone, neck, head):
super().__init__()
self.semantic_backbone = semantic_backbone # Extracts high-level semantic features
self.detail_backbone = detail_backbone # Extracts detail and texture features
self.neck = neck # Fuses dual-path multi-scale features
self.head = head # Outputs classification and localization results
def forward(self, x):
s_feats = self.semantic_backbone(x) # Semantic branch features
d_feats = self.detail_backbone(x) # Detail branch features
fused = self.neck(s_feats, d_feats) # Fuse dual-path information scale by scale
return self.head(fused) # Generate bounding boxes and class predictionsThis code summarizes the minimal implementation framework of a dual-backbone detector.
The Dual-Path Homogeneous Design in Single-Modal Scenarios Emphasizes Division of Labor Rather Than Redundancy
With single-modal input, the two backbones can keep similar hierarchical structures, but use different supervision objectives and convolution strategies. The semantic branch focuses on class discrimination, global shape, and contextual understanding. The detail branch focuses on edges, micro-textures, and preserving low-contrast targets.
This “homogeneous structure with different responsibilities” essentially externalizes the internal conflict of a single backbone into collaboration between two branches. The benefit is not simply a wider network, but a parameter budget that truly serves different statistical feature types.
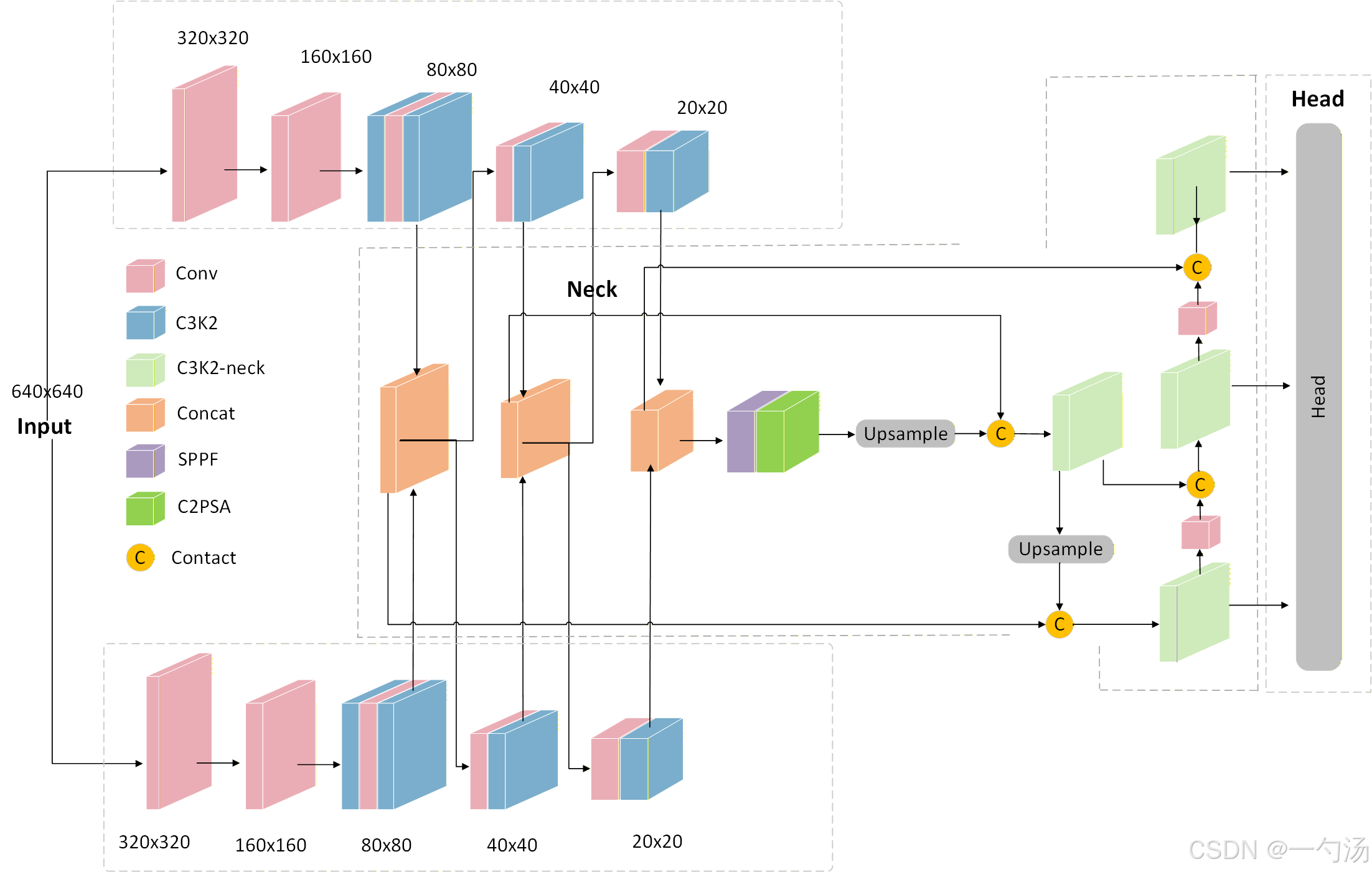 AI Visual Insight: The figure shows a single-modal dual-backbone structure. The input image is sent into two parallel backbone paths: the upper branch focuses on semantic representation, while the lower branch focuses on detail representation. Cross-branch connections appear at key scales such as 80×80, 40×40, and 20×20, which indicates that this is not a late-stage concatenation design, but a continuously interactive intermediate-layer architecture. A unified Neck then performs multi-scale fusion before sending features to the detection head.
AI Visual Insight: The figure shows a single-modal dual-backbone structure. The input image is sent into two parallel backbone paths: the upper branch focuses on semantic representation, while the lower branch focuses on detail representation. Cross-branch connections appear at key scales such as 80×80, 40×40, and 20×20, which indicates that this is not a late-stage concatenation design, but a continuously interactive intermediate-layer architecture. A unified Neck then performs multi-scale fusion before sending features to the detection head.
Shallow Multi-Scale Interaction Is the Main Source of This Design’s Gains
The original article emphasizes cross-branch information exchange at three scales: 80×80, 40×40, and 20×20. This allows the semantic branch to access local details earlier, while the detail branch receives class-oriented guidance, reducing the burden on later fusion in the Neck.
def cross_scale_interaction(semantic_feats, detail_feats):
outputs = []
for s, d in zip(semantic_feats, detail_feats):
mixed = torch.cat([s, d], dim=1) # Concatenate same-scale features from both branches
mixed = conv1x1(mixed) # Compress channels and align information
outputs.append(mixed + s + d) # Preserve residual information from the original branches
return outputsThis pseudocode illustrates the basic idea of scale-by-scale interaction: alignment, compression, and residual preservation.
The Heterogeneous Backbone Design in Multimodal Scenarios Solves Late-Fusion Misalignment
A common multimodal detection approach encodes RGB and infrared inputs separately and then concatenates them at the end. While this is easy to implement, different modalities have different statistical distributions and receptive field preferences. As a result, end-stage fusion often becomes simple information stacking rather than truly complementary integration.
This architecture naturally extends the dual-backbone design into a heterogeneous multimodal encoder. For example, the RGB branch preserves color, texture, and boundaries, while the infrared branch strengthens thermal contours and temperature-difference semantics. More importantly, it requires the outputs at each stage to remain strictly aligned in size, and introduces cross-modal interaction in intermediate layers.
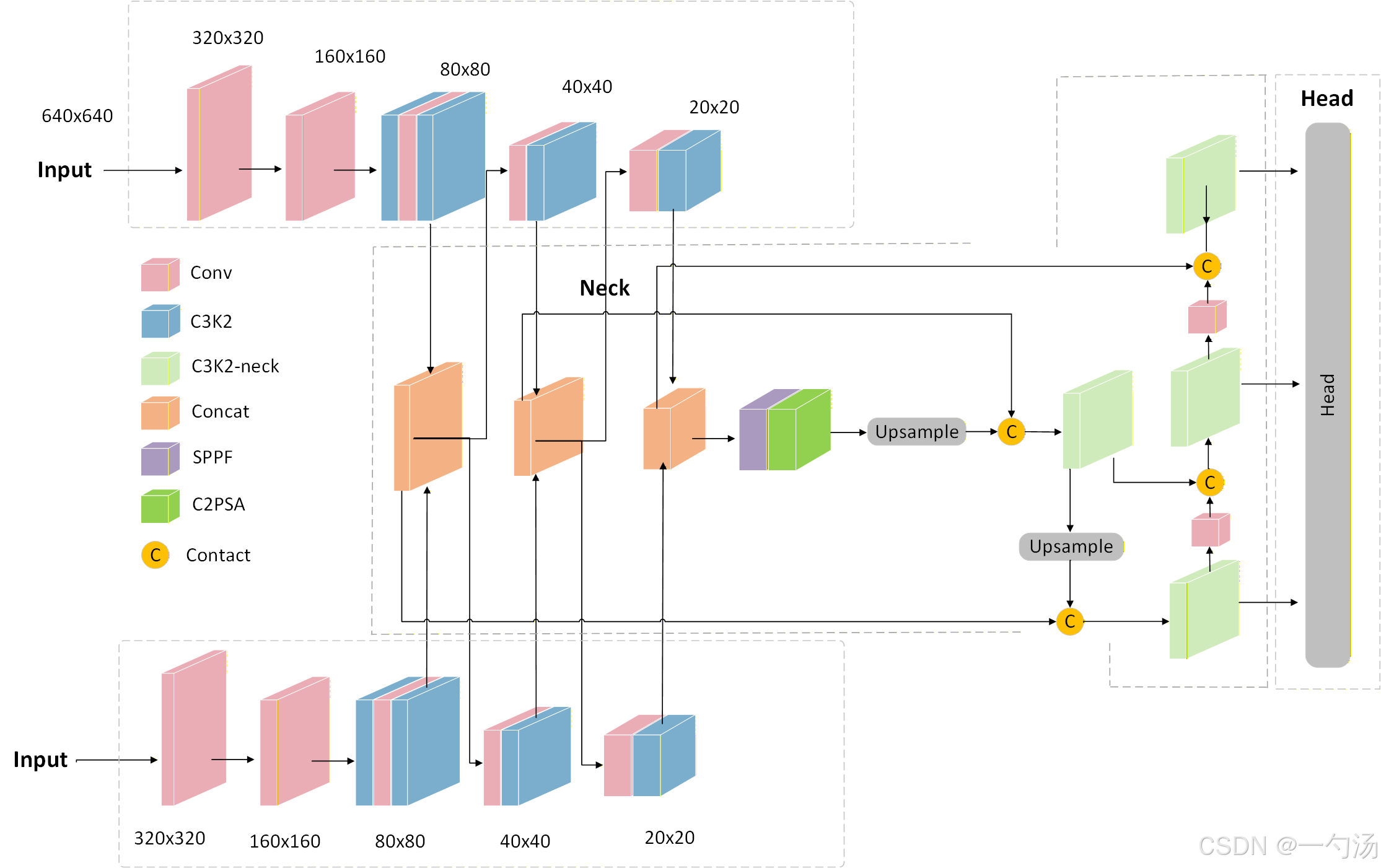 AI Visual Insight: This figure shows a heterogeneous dual-backbone design for multimodal input. Two different modalities are processed by customized backbone networks, and their feature maps are aligned and connected laterally across multiple resolution levels. This indicates that fusion happens inside the Backbone rather than only at the end of the Neck. The design reduces representation misalignment across modalities such as RGB and infrared or CT and MRI, and improves the use of complementary information.
AI Visual Insight: This figure shows a heterogeneous dual-backbone design for multimodal input. Two different modalities are processed by customized backbone networks, and their feature maps are aligned and connected laterally across multiple resolution levels. This indicates that fusion happens inside the Backbone rather than only at the end of the Neck. The design reduces representation misalignment across modalities such as RGB and infrared or CT and MRI, and improves the use of complementary information.
Heterogeneous Branches Are Better Suited to All-Weather and High-Interference Environments
In RGB + IR scenarios, the model can rely on RGB details during the day and infrared thermal features at night or in rain and fog. Because information exchange is moved forward into the Backbone, the intermediate layers already complete modality alignment. As a result, the final detection head receives a more stable joint representation.
class MultiModalStem(nn.Module):
def __init__(self):
super().__init__()
self.rgb_stem = Conv(3, 32, 3, 2) # RGB three-channel input
self.ir_stem = Conv(1, 32, 3, 2) # Infrared single-channel input
def forward(self, rgb, ir):
rgb_feat = self.rgb_stem(rgb)
ir_feat = self.ir_stem(ir)
return rgb_feat, ir_feat # Output aligned initial modality featuresThis code shows that in multimodal scenarios, the first step is not fusion, but separate encoding based on modality-specific characteristics.
The Real Value of This Architecture Appears in Four Difficult Application Scenarios
The first is industrial quality inspection. Defects such as micro-cracks, contamination, and cold solder joints are often extremely small. The detail branch reduces missed detections, while the semantic branch helps identify part context and category boundaries.
The second is medical imaging. Small lesions often combine local abnormal textures with global morphological cues, making a dual-path structure better suited to capture both fine-grained patterns and high-level medical semantics.
Autonomous Driving and Security Scenarios Depend More on Robustness Gains
The third is security surveillance. Occlusion, backlighting, nighttime conditions, and long-range targets can quickly degrade a single-backbone model, while dual-path collaboration or heterogeneous RGB+IR collaboration can significantly improve stability.
The fourth is autonomous driving perception. When distant small objects and nearby large objects coexist, a dual-backbone design can improve consistency in multi-scale perception, especially in adverse weather and complex road conditions.
This Is a Structural Upgrade Path for YOLO-Based Improvements
From an engineering perspective, this design fits naturally into YOLO-style detectors because it does not abandon the core Backbone-Neck-Head paradigm. Instead, it performs a structural reconstruction of the Backbone and Neck. That makes it a practical balance between architectural innovation and migration cost.
If you are working on improvements for YOLOv8, YOLO11, or YOLO26, this dual-path collaboration idea is more systematic than adding isolated attention modules. It changes the feature generation mechanism itself instead of simply reweighting features that already exist.
FAQ
1. Does a dual-backbone design always mean the parameter count doubles?
Not necessarily. If both branches use lightweight designs, share part of the Neck, or reduce channel widths, parameter growth can remain manageable. The main benefit comes from specialization and interaction, not just scaling up the model.
2. Is a dual-backbone design worth using for single-modal tasks?
If the task involves small objects, occlusion, complex backgrounds, or low-contrast targets, a dual-backbone design often provides clear value. For simple scenarios, you should evaluate the trade-off against the available compute budget.
3. Why should multimodal fusion move earlier into the Backbone?
Because end-stage concatenation only performs post hoc aggregation and cannot solve representation misalignment across modalities. Moving interaction into intermediate layers establishes cross-modal correspondence earlier and improves both fusion efficiency and robustness.
Core Summary: This article reconstructs and analyzes a custom dual-backbone collaborative detection architecture. It focuses on the bottlenecks of single-backbone networks in detail preservation, semantic representation, and multimodal fusion, breaks down the core mechanisms behind differentiated homogeneous design for single-modal tasks and heterogeneous collaborative design for multimodal tasks, and summarizes its practical value in industrial inspection, security, medical imaging, and autonomous driving.