This is an enterprise-grade requirements management tool built on Flask. Its core capabilities cover requirement creation, state transitions, dependency analysis, traceability matrices, and multi-project collaboration. It addresses common problems such as scattered requirement documents, coarse-grained permissions, and poor change traceability. Keywords: Flask, RBAC, requirements traceability.
The technical specification snapshot provides a quick overview
| Parameter | Description |
|---|---|
| Programming Language | Python 3.10+ |
| Web Framework | Flask 3.0.0 |
| ORM | Flask-SQLAlchemy 3.1.1 |
| Database | SQLite 3.x |
| Graph Analysis Protocol/Capability | NetworkX-based dependency graph analysis |
| Frontend Templating | Jinja2 3.1.x |
| UI Framework | Bootstrap 5.3.x |
| Current Version | v0.3.2 |
| Star Count | Not provided in the source material |
| Core Dependencies | Flask, Flask-SQLAlchemy, NetworkX |
The system is designed for full lifecycle requirements management
This system is positioned as an enterprise-grade requirements management platform. Its focus is not merely to “record requirements,” but to place requirements, goals, scenarios, testing, and project collaboration into a unified workflow. It fits small and mid-sized teams that want standardized engineering management, and it also works well as a prototype foundation for a future open source project.
The completed modules include requirements management, project management, goal management, scenario management, dependency analysis, traceability matrices, import/export, and RBAC-based access control. Its value lies in consolidating requirement data scattered across Excel files, wikis, and chat logs into a single auditable data structure.
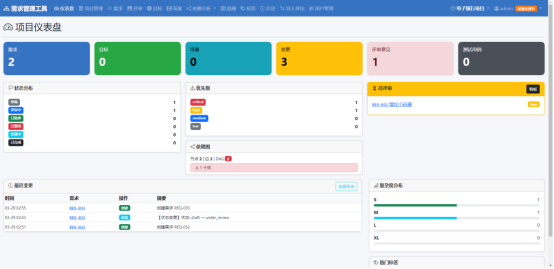 AI Visual Insight: This interface shows a typical administrative dashboard with left-side navigation, a top action bar, and a central content panel. It reflects a multi-module navigation structure that supports seamless switching across requirements, projects, members, and analytics views.
AI Visual Insight: This interface shows a typical administrative dashboard with left-side navigation, a top action bar, and a central content panel. It reflects a multi-module navigation structure that supports seamless switching across requirements, projects, members, and analytics views.
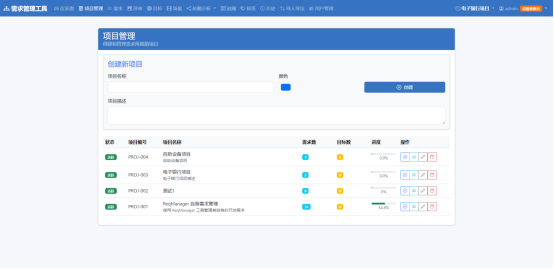 AI Visual Insight: This screenshot looks like a requirements list or detail management page. It likely presents fields such as status, priority, and owner, which indicates that the system already supports structured requirement presentation instead of plain-text entry alone.
AI Visual Insight: This screenshot looks like a requirements list or detail management page. It likely presents fields such as status, priority, and owner, which indicates that the system already supports structured requirement presentation instead of plain-text entry alone.
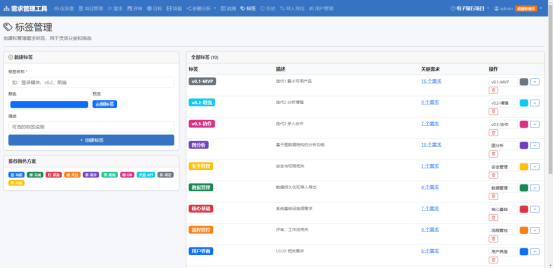 AI Visual Insight: This image highlights traits of a graphical relationship view or Kanban-style board. It suggests that the project attempts to visualize requirement dependencies, hierarchies, or traceability paths to help teams identify blockers and critical paths.
AI Visual Insight: This image highlights traits of a graphical relationship view or Kanban-style board. It suggests that the project attempts to visualize requirement dependencies, hierarchies, or traceability paths to help teams identify blockers and critical paths.
The requirement state machine enables controlled change governance
The system defines requirement states as draft, under_review, approved, implementing, done, and rejected, and it allows rejected items to return to draft for revision. This design gives requirement reviews and execution a verifiable process boundary.
Draft (draft) -> Under Review (under_review) -> Approved (approved)
-> Implementing (implementing) -> Done (done)
Rejected (rejected) -> Return for Revision -> Draft (draft)This state machine constrains the valid transition paths for requirements and prevents unauthorized promotion or implementation without review.
The system uses MVC layering and Blueprint-style modular organization
From an architectural perspective, the presentation layer consists of templates/ and static/, the control layer is handled by app.py and auth.py, the business layer is split across rbac.py, graph_engine.py, and export_import.py, and the data layer is centered in models.py and SQLite.
The benefits of this separation are straightforward: permission logic, graph computation logic, and import/export capabilities are not tightly coupled to routes. That lowers the cost of future migration to PostgreSQL, a REST API, or a fully decoupled frontend-backend architecture.
# Main request handling flow
@app.route('/requirements/<int:req_id>/transition', methods=['POST'])
@login_required # Perform authentication first
@require_permission('req_edit') # Then enforce fine-grained permission checks
def transition_requirement(req_id):
req = Requirement.query.get_or_404(req_id)
req.status = 'approved' # Update the requirement state
db.session.commit() # Persist changes to the database
return redirect(f'/requirements/{req_id}')This code summarizes the core execution path from authentication and authorization to state update.
The core components have clear responsibility boundaries
app.py handles routing and request orchestration, auth.py manages user authentication, rbac.py carries role-to-permission mapping, graph_engine.py performs dependency analysis, cycle detection, and critical path calculation, and export_import.py handles CSV/JSON import and export.
This responsibility split is important for team collaboration. Backend engineers can divide development around business capabilities, and testers can establish more stable unit test boundaries by module.
The data model is organized around projects, requirements, and dependencies
The database structure centers on users, projects, requirements, and dependencies, then extends many-to-many relationships through project_members and requirement_tags. This model is sufficient to cover the primary data flows involved in project initiation, decomposition, tracking, and acceptance within an engineering team.
Among them, the requirements table defines the requirement identifier, title, type, priority, status, complexity, source, goal association, and project ownership. It serves as the factual center of the entire system. The dependencies table structures prerequisite and blocking relationships between requirements so graph algorithms can process them efficiently.
class Requirement(db.Model):
id = db.Column(db.Integer, primary_key=True)
req_id = db.Column(db.String(20), unique=True, nullable=False) # Business-side requirement identifier
title = db.Column(db.String(200), nullable=False)
status = db.Column(db.String(20), default='draft') # Current state machine node
project_id = db.Column(db.Integer, db.ForeignKey('projects.id'))
goal_id = db.Column(db.Integer, db.ForeignKey('goals.id'))This model definition shows that the system treats requirements as traceable, relational, and auditable data objects.
RBAC and project membership enforce the principle of least privilege
The roles include admin, pm, po, developer, tester, and viewer. Among them, admin has full access, pm focuses on project governance, po focuses on requirement editing, and developer and tester receive scoped permissions aligned with execution responsibilities.
This design is much closer to real enterprise scenarios than a model where any logged-in user can edit data, especially when multiple projects run in parallel and require permission isolation.
class Permission(Enum):
REQ_CREATE = 'req_create' # Create requirements
REQ_EDIT = 'req_edit' # Edit requirements
REQ_DELETE = 'req_delete' # Delete requirements
IMPORT = 'import' # Import data
EXPORT = 'export' # Export dataThis permission enum provides a unified semantic layer for decorator-based validation and role mapping.
Graph analysis is the differentiating capability of this tool
Compared with a conventional requirements ledger, this system introduces a NetworkX-based graph analysis engine that can perform cycle detection, impact analysis, priority consistency checks, and critical path analysis. That means it manages not only “items” but also understands “relationships.”
In complex projects, if a high-priority requirement depends on multiple low-priority prerequisites, the system can surface scheduling conflicts early. For architects, product managers, and project managers, this provides more decision-making value than a simple list view.
import networkx as nx
def detect_cycles(edges):
graph = nx.DiGraph()
graph.add_edges_from(edges) # Build a directed dependency graph
return list(nx.simple_cycles(graph)) # Detect circular dependenciesThis function identifies whether closed-loop dependencies exist between requirements and helps prevent non-executable delivery plans.
The deployment and startup path keeps the barrier to entry low
The development environment only requires Python 3.10+, pip, and Git. The initialization sequence is init_db.py, init_rbac.py, and app.py. This indicates that the project prioritizes fast startup over heavy infrastructure dependencies.
The production environment supports Gunicorn and Docker. For small and mid-sized teams, this combination is sufficient for internal deployment, demo environments, and lightweight production systems.
# Initialize the database
python init_db.py
# Initialize the permission model
python init_rbac.py
# Start the development server
python app.pyThese commands complete local environment initialization and the first startup.
Production deployment can switch directly to Gunicorn
pip install gunicorn # Install the production WSGI server
gunicorn -w 4 -b 0.0.0.0:5000 app:app # Start with 4 workersThis approach works well for quickly deploying the system to a Linux server or container environment.
The scope and limits of this tool are clearly defined
If your team needs a full ALM platform, automated test orchestration, or a large-scale enterprise workflow engine, this project is still relatively lightweight. But if the goal is to quickly establish a standardized requirements asset center with traceability, authorization, and analytical capabilities, it already offers strong prototype value.
This is especially true for private deployment, training demos, internal tool incubation, or future secondary open source scenarios, where this Flask architecture remains simple, direct, and easy to extend or refactor.
FAQ provides structured answers to common evaluation questions
What is the core advantage of this system compared with managing requirements in Excel or a wiki?
Answer: Its advantages lie in the structured state machine, RBAC permissions, dependency analysis, and traceability matrix. It upgrades requirement handling from simple “record keeping” to actual “governance,” making change management, approval, relationship tracking, and impact analysis actionable and auditable.
Why choose Flask instead of a heavier enterprise framework?
Answer: Flask is lightweight enough for rapid prototyping and internal tools. Combined with Blueprint-style modularity, SQLAlchemy, and Jinja2, it can deliver modular design, access control, and data modeling at relatively low complexity.
What capabilities are most worth enhancing next in this project?
Answer: The highest-priority improvements should be PostgreSQL support, a RESTful API, audit logs, frontend-backend separation, and stronger automated test coverage. These enhancements would help the project evolve from a prototype into a sustainably maintainable internal enterprise platform.
Core summary captures the implementation value
This is an enterprise-grade requirements management system built with Flask and SQLAlchemy. It covers the full requirements lifecycle, RBAC permissions, multi-project collaboration, dependency analysis, and traceability matrices. This article reconstructs its architecture, data model, interfaces, and deployment workflow to help teams quickly evaluate its practical viability.