Kafka is moving away from its ZooKeeper-dependent dual control-plane architecture to KRaft, a mode with built-in Raft consensus. This shift solves slow metadata synchronization, consistency risks caused by dual controllers, and the high operational cost of running two systems. Keywords: Kafka, ZooKeeper, KRaft.
Technical specification snapshot
| Parameter | Details |
|---|---|
| Project/Topic | Apache Kafka control-plane architecture evolution |
| Core Languages | Scala, Java |
| Protocols/Mechanisms | ZooKeeper coordination, Raft consensus, Leader Epoch |
| Metadata Storage | ZooKeeper / __cluster_metadata |
| Typical Number of Control Nodes | 3 or 5 |
| Community Status | Newer Kafka releases fully embrace KRaft |
| Core Dependencies | Kafka Broker, Controller Quorum, ZooKeeper (legacy mode) |
Kafka’s move away from ZooKeeper is a control-plane redesign
In Kafka’s early architecture, metadata management was delegated to ZooKeeper. Broker state, topics, partitions, replica ISR sets, and other cluster metadata all relied on an external coordination system. This design worked well at first, but in large-scale clusters, the control plane gradually became a scalability bottleneck.
Under the ZooKeeper model, the Kafka Controller must read the full metadata set from an external system and then synchronize it to every broker. As the number of topics and partitions grows, this “centralized read plus broadcast distribution” path directly increases recovery time.
The core problem in the ZooKeeper model is not missing functionality
The real issue is that the architectural boundary runs too deep. Kafka owns the data plane, ZooKeeper owns the control plane, and the Controller acts as the middle-layer coordinator. Once the system is split into two centers of authority, state propagation paths become longer and failure scenarios become more complex.
# Common dependency relationships in the ZooKeeper era
Kafka Broker -> ZooKeeper # Register brokers and watch metadata
Controller -> ZooKeeper # Election and state management
Broker <- Controller # Receive metadata broadcastsThis relationship shows that metadata changes are not agreed on directly by brokers. Instead, they are first written to an external coordination layer and then propagated by the Controller.
Metadata synchronization bottlenecks amplify recovery costs in large clusters
When a Controller failover occurs, the new Controller must first pull the complete metadata set from ZooKeeper and then broadcast the latest state to brokers across the cluster. If the cluster contains hundreds of thousands of partitions, this step can significantly delay service recovery.
The root problem is not simply “slow reads.” It is that control-plane recovery depends on full metadata loading. The more centralized the controller is, the higher the switchover cost becomes; the larger the metadata set is, the slower fault recovery becomes.
Consistency risk comes from having two centers of authority at the same time
When ZooKeeper and the Kafka Controller both hold critical cluster state, any network jitter, GC pause, or heartbeat delay can create a brief split-brain condition. The most typical case is when the old Controller has not fully failed, but a new Controller has already been elected.
If the old Controller recovers from a Full GC and still believes it is valid, it may continue sending leader-switch commands to brokers. In that situation, different producers may be routed to different leaders, which ultimately leads to write inconsistency and uncertain consumption behavior.
# Pseudocode illustrating the dual-controller risk
old_controller_alive = True # Old controller recovers from GC
new_controller_elected = True # ZooKeeper has already elected a new controller
if old_controller_alive and new_controller_elected:
send_command("broker2", "become leader for old epoch") # Old controller keeps issuing commands
send_command("broker2", "become leader for new epoch") # New controller also issues commandsThis pseudocode shows the root cause of split brain: both controllers can issue commands that appear legitimate.
KRaft unifies the control plane with built-in Raft consensus
The key change in KRaft is not simply removing ZooKeeper. It is that Kafka formally takes metadata management back into its own architecture. Kafka uses a Controller Quorum to maintain the control plane and relies on the Raft protocol for leader election and log replication.
In this model, cluster nodes can be divided into two categories: the Controller Quorum and Broker Nodes. The former maintains metadata and elections, while the latter focuses on message read and write traffic. This preserves the separation between the data plane and control plane, but without depending on an external coordination system.
KRaft turns metadata into a replicated log
KRaft internally maintains a special topic named __cluster_metadata. Every cluster change, such as topic creation, partition reassignment, or leader switch, is written to this metadata log as an event.
Other nodes no longer passively wait for the Controller to broadcast updates. Instead, they perceive state changes through log replication and log consumption. This model replaces “control command distribution” with “metadata event stream synchronization,” which provides stronger consistency and better recoverability.
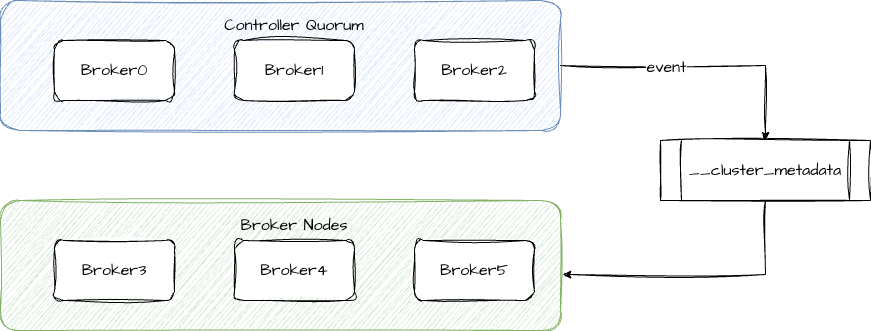
AI Visual Insight: This diagram shows KRaft’s dual-role architecture. The upper layer is the Controller Quorum, which elects a leader through majority voting and reaches agreement around the metadata log. The lower layer is the Broker Nodes, which handle business data ingestion and delivery. The image highlights the separation between the control plane and data plane, while metadata is no longer externalized to ZooKeeper and is instead consolidated into Kafka’s internal replication path.
# Example of key KRaft role configuration
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@node1:9093,2@node2:9093,3@node3:9093
controller.listener.names=CONTROLLERThis configuration declares node roles, a unique node ID, and the controller voter set. It is the foundational entry point for a KRaft deployment.
KRaft supports two deployment models for different scales
Combined mode lets a single process take both the Broker and Controller roles at the same time, using process.roles=broker,controller. This approach is easy to deploy and fits test environments, small clusters, and feature validation.
Isolated mode places Brokers and Controllers on different machines. Controllers no longer absorb the impact of business traffic, failure domains become clearer, and overall stability improves. This model is better suited for production environments.
Monotonically increasing Epoch values are the key to KRaft consistency
Each Controller leader term carries a unique Epoch. When processing metadata commands, nodes accept only control commands with a higher Epoch. In effect, the protocol forcibly eliminates the lingering impact of an old leader.
As a result, even if an old node briefly recovers, it cannot override metadata changes already committed by the new leader. Compared with the ZooKeeper model’s combination of external coordination and internal broadcast, KRaft converges authority into a single metadata log sequence.
ZooKeeper mode: ZooKeeper + Controller dual authority
KRaft mode: Controller Quorum single authority + metadata log
Result: shorter recovery paths, stronger consistency, lower operational costThis comparison summarizes the essence of Kafka’s control-plane evolution: moving from external coordination to internal consensus.
The differences between ZooKeeper and KRaft already show up in scalability and operations
From a capability perspective, the ZooKeeper model requires an additional independent cluster, separates metadata storage, and makes recovery heavier. KRaft removes the external dependency, keeps metadata self-contained, and makes control-plane failover faster.
In large-scale partition scenarios, KRaft is more scalable by design. Its goal is not only to replace ZooKeeper, but also to pave the way for million-partition clusters, faster recovery, and unified operations.
FAQ
1. Should new Kafka clusters still use ZooKeeper?
No. New Kafka releases have fully adopted KRaft. Unless a legacy system has strong dependencies or migration windows are constrained, KRaft should be the default choice for new clusters.
2. How should I choose between combined mode and isolated mode?
Use combined mode for testing, development, and small environments. For production, isolated mode is the better choice because it isolates failures between the control plane and the data plane.
3. Why can KRaft avoid dual-controller split brain?
Because controller election and metadata commits are both based on a unified Raft log and Epoch mechanism. Even if an old controller recovers, commands with a lower Epoch cannot overwrite the new state.
Core Summary: This article systematically reconstructs the logic behind Kafka’s migration from ZooKeeper to KRaft. It explains metadata bottlenecks, consistency risks, and operational complexity, then walks through KRaft’s role separation, metadata topic, deployment models, and architectural benefits to help developers quickly understand the design of Kafka’s next-generation control plane.