LangChain’s InMemoryVectorStore is ideal for quickly building RAG prototypes and reducing the cost of validating small-scale semantic search and temporary knowledge bases. This article focuses on its architecture, retrieval flow, persistence alternatives, and comparisons with Chroma and FAISS. Keywords: LangChain, vector store, RAG.
Technical specifications at a glance
| Parameter | Description |
|---|---|
| Core language | Python |
| Primary framework | LangChain |
| Retrieval mechanism | Vector similarity search, cosine similarity |
| Storage model | In-memory storage, disk persistence |
| Representative implementations | InMemoryVectorStore, Chroma |
| Core dependencies | langchain_core, langchain_community, langchain_google_genai, tiktoken |
| Protocol / interface | Python SDK |
| Best-fit scenarios | RAG prototypes, semantic search, document Q&A |
| Star count | Not provided in the source material |
 AI Visual Insight: This animated image introduces the concept of vector stores by emphasizing the dynamic relationship between document embedding, index organization, and retrieval output. It works well as an entry-point illustration for RAG data flow, although it does not show specific field structures or index parameters.
AI Visual Insight: This animated image introduces the concept of vector stores by emphasizing the dynamic relationship between document embedding, index organization, and retrieval output. It works well as an entry-point illustration for RAG data flow, although it does not show specific field structures or index parameters.
Vector stores are the core infrastructure of the RAG retrieval pipeline
In LangChain, documents are not sent directly to the LLM for full-text matching. They are first split into chunks, embedded, and then written into a vector store. During retrieval, the query is also encoded into a vector, and distance calculations are used to find the semantically closest chunks.
This solves a core limitation of traditional keyword search: it struggles to understand content that is semantically similar but phrased differently. For Q&A systems, knowledge assistants, and the external memory layer of agents, vector stores are almost the default configuration.
The vector database workflow can be broken down into five steps
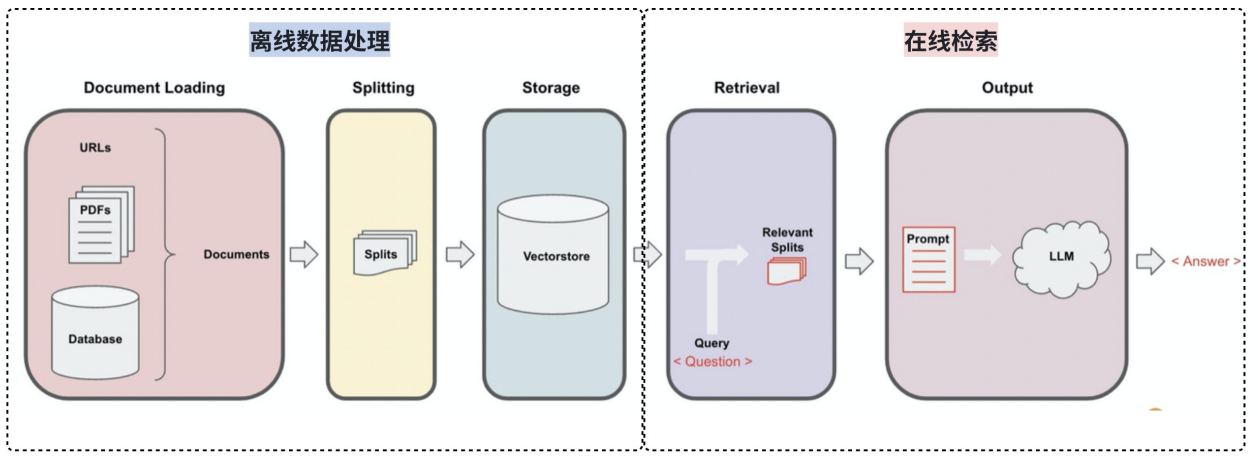 AI Visual Insight: This diagram shows a typical RAG pipeline: raw documents are converted into high-dimensional vectors through embeddings, then indexed in a vector database. A user query is encoded by the same embedding model, matched against stored vectors by similarity, and the Top-K documents are returned for the generation model to consume.
AI Visual Insight: This diagram shows a typical RAG pipeline: raw documents are converted into high-dimensional vectors through embeddings, then indexed in a vector database. A user query is encoded by the same embedding model, matched against stored vectors by similarity, and the Top-K documents are returned for the generation model to consume.
- Split documents and generate embeddings.
- Write vectors and metadata into the storage layer.
- Encode the query into a vector with the same dimensionality.
- Run similarity search through the retriever.
- Return the most relevant document chunks to the upper-layer chain.
from langchain_core.vectorstores import InMemoryVectorStore
# embeddings converts text into vectors
vector_store = InMemoryVectorStore(embeddings) # Initialize the in-memory vector storeThis code initializes a minimal viable vector store.
InMemoryVectorStore is suitable for prototyping, not long-running online services
The biggest advantages of InMemoryVectorStore are zero deployment, low complexity, and fast integration. It stores vectors directly in process memory, which makes it especially useful for tutorials, local experiments, and small-scale data validation.
The trade-off is equally clear: once the program exits, the data is lost. It also cannot naturally handle large-scale datasets, cold-start recovery, or cross-process sharing. In practice, this makes it more of a development-time tool than a production foundation.
Similarity search depends on both embedding quality and the distance metric
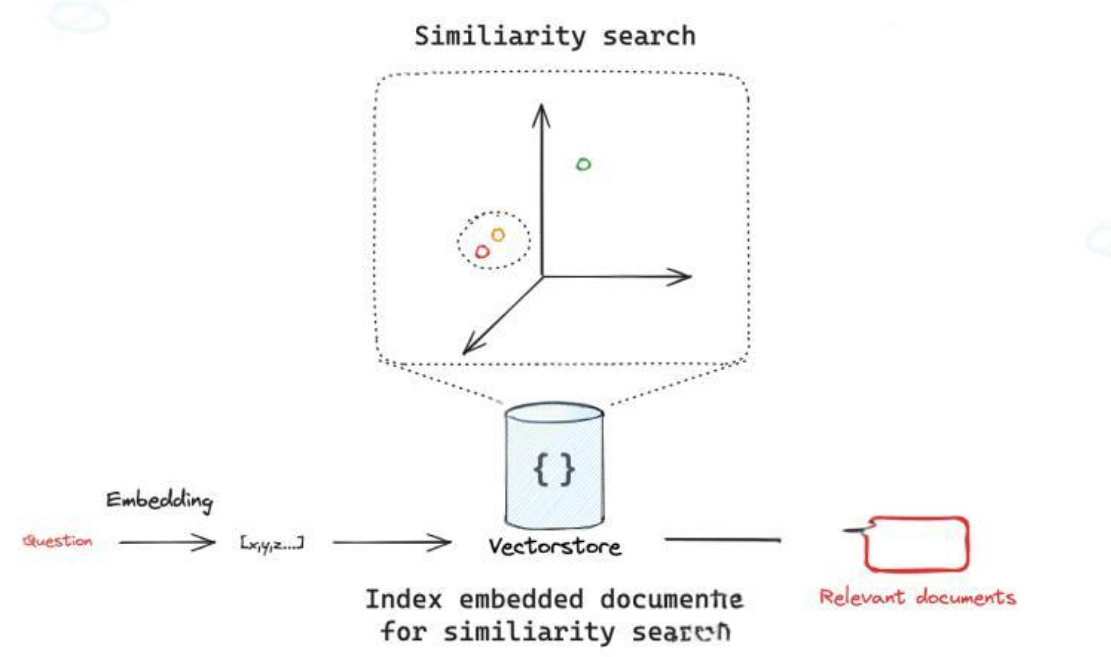 AI Visual Insight: This figure highlights how query vectors and document vectors are compared within the same vector space. It illustrates the core technical pattern of “normalize representation first, then run nearest-neighbor search,” which is essential for understanding cosine similarity and ANN retrieval.
AI Visual Insight: This figure highlights how query vectors and document vectors are compared within the same vector space. It illustrates the core technical pattern of “normalize representation first, then run nearest-neighbor search,” which is essential for understanding cosine similarity and ANN retrieval.
Semantic retrieval usually does not focus on exact lexical matches. Instead, it focuses on proximity in vector space. In text applications, cosine similarity is more common because it emphasizes directional alignment rather than vector magnitude itself.
docs = vector_store.similarity_search(
query="What is Claude Skills?", # Query text
k=4 # Return the 4 most similar results
)This code automatically vectorizes the query and returns the most relevant documents.
High-performance vector retrieval depends on index structures, not brute-force scanning
As data volume grows, comparing every vector one by one quickly becomes unmanageable. That is why approximate nearest neighbor (ANN) algorithms are required. Solutions such as FAISS, RedisSearch, and Pinecone all fundamentally optimize the same question: how to approach the best nearest neighbors much faster.
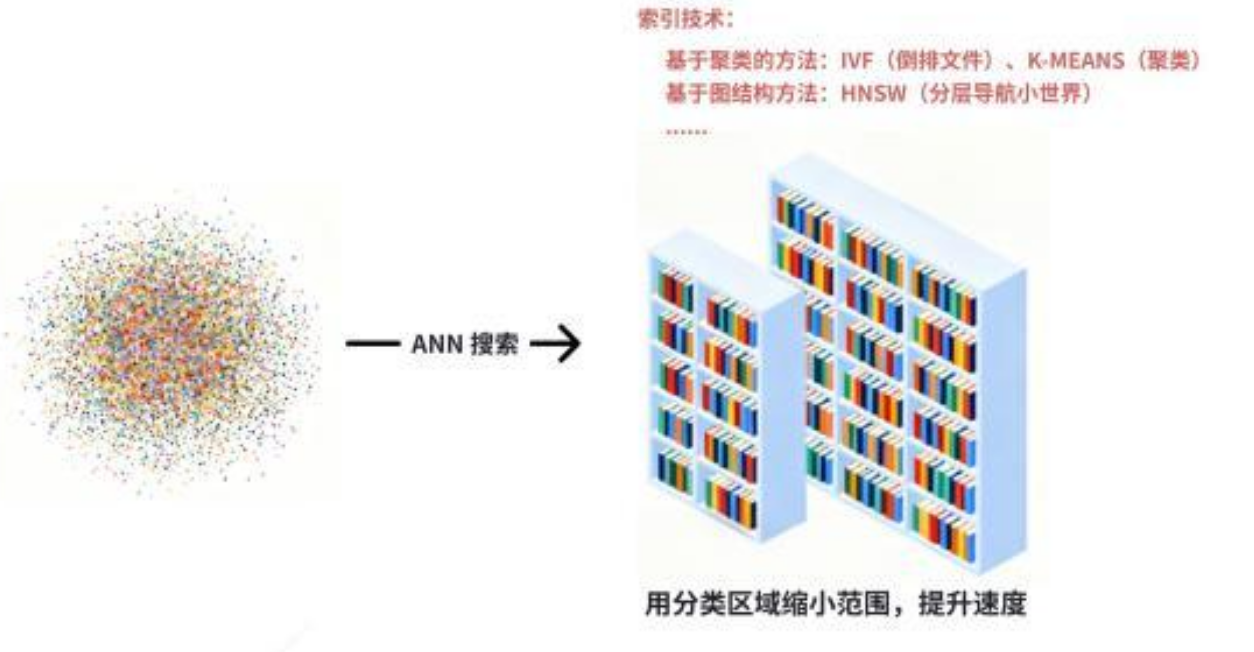 AI Visual Insight: This image is intended to explain the HNSW hierarchical graph structure: upper layers are sparse, lower layers are dense, and the query first performs coarse positioning at higher layers before drilling down step by step toward the nearest neighbors. This trades a tiny amount of accuracy for significantly lower latency at scale.
AI Visual Insight: This image is intended to explain the HNSW hierarchical graph structure: upper layers are sparse, lower layers are dense, and the query first performs coarse positioning at higher layers before drilling down step by step toward the nearest neighbors. This trades a tiny amount of accuracy for significantly lower latency at scale.
The value of HNSW lies in hierarchical navigation. It first locates the search region quickly in sparse upper layers, then performs a more precise search in denser lower-layer graphs, balancing recall and speed. Indexes like this are the performance core of production-grade vector databases.
SIMD optimization explains why vector computation can be fast enough
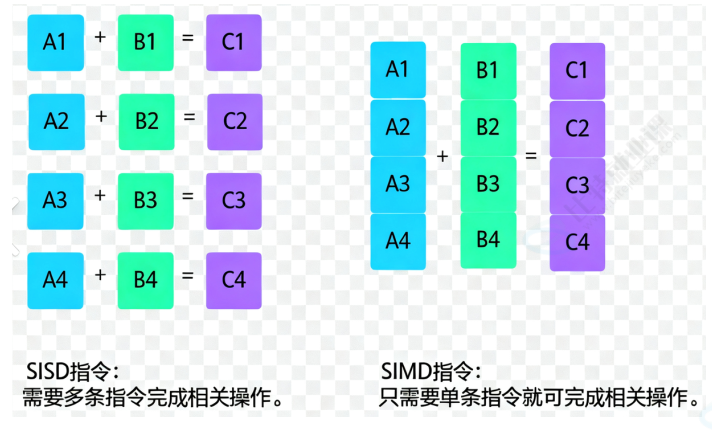 AI Visual Insight: This diagram uses color vector dot products to explain SIMD parallelism: the CPU does not process one candidate at a time in sequence. Instead, it performs batched vector multiply-accumulate operations, improving similarity computation throughput. This is critical to low-level performance during the Top-K retrieval stage.
AI Visual Insight: This diagram uses color vector dot products to explain SIMD parallelism: the CPU does not process one candidate at a time in sequence. Instead, it performs batched vector multiply-accumulate operations, improving similarity computation throughput. This is critical to low-level performance during the Top-K retrieval stage.
Common forms of similarity computation include dot product, Euclidean distance, and cosine distance. Under the hood, optimized libraries use SIMD parallel instructions to process floating-point arrays in batches, so one comparison is no longer a serial operation on a single document but a parallelized pass across multiple candidates.
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_core.vectorstores import InMemoryVectorStore
loader = UnstructuredMarkdownLoader("test.md", mode="elements") # Load Markdown by structure
documents = loader.load()
splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=120, # Control the length of each chunk
chunk_overlap=50 # Preserve contextual overlap
)
chunks = splitter.split_documents(documents) # Split documents into chunks
embeddings = GoogleGenerativeAIEmbeddings(model="gemini-embedding-001")
vectorstore = InMemoryVectorStore(embeddings) # Create an in-memory vector store
ids = vectorstore.add_documents(chunks) # Insert documents and return IDsThis code connects the four core stages: loading, splitting, embedding, and ingestion.
Metadata filtering upgrades retrieval from merely relevant to controllable
Vector similarity alone may return results that are semantically close but still outside business constraints. Metadata filtering lets you add boundaries such as source, time, author, or tenant, forming a hybrid retrieval pattern of “semantic recall + structural constraints.”
def filter_by_source(doc):
return doc.metadata["source"] == "test.md" # Keep only documents from the specified source
docs = vectorstore.similarity_search(
query="What is Claude Skills?",
k=2,
filter=filter_by_source # Apply metadata filtering
)This code shows how to further narrow the result set after semantic retrieval.
Persistence is a necessary upgrade path from experimentation to production
If you want to avoid rebuilding the index every time, the most direct upgrade path is Chroma. It supports local persistence, preserves a relatively low adoption barrier, and fills in the critical capability of writing vector data to disk.
from langchain_community.vectorstores import Chroma
vector_store = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db" # Directory for persisting vector data
)
results = vector_store.similarity_search("What is Claude Skills?", k=3)This code creates a persistent vector store and performs a basic retrieval operation.
The differences between vector databases are fundamentally trade-offs across performance, operations, and cost
| Solution | Persistence | Performance | Suitable scale | Typical scenarios |
|---|---|---|---|---|
| InMemoryVectorStore | No | Fast | Small | Prototyping, testing |
| Chroma | Yes | Moderate | Medium | Local development, lightweight applications |
| FAISS | Yes | Very fast | Large | Local high-performance retrieval |
| Pinecone | Yes | Fast | Large | Cloud production environments |
| RedisSearch | Yes | Very fast | Medium to large | Real-time retrieval, unified cache and search |
Performance alone is not enough when selecting a solution. You should also evaluate whether you need a managed service, whether metadata filtering is required, whether you already have Redis infrastructure, and whether your team can absorb the complexity of index tuning.
FAQ
1. Why is InMemoryVectorStore only suitable for testing scenarios?
Because the data resides in process memory, all vectors are lost when the service stops, and it is difficult to support large-scale indexing or multi-instance sharing.
2. What is the difference between similarity_search and similarity_search_with_score in LangChain?
The former returns only a list of documents. The latter returns both documents and their corresponding scores, which is useful for threshold filtering, ranking explainability, and retrieval quality evaluation.
3. What should you prioritize when upgrading from InMemoryVectorStore to production?
First confirm whether you need persistence and multi-instance access. For small to medium workloads, Chroma is a practical choice. For high-performance local retrieval, choose FAISS. For managed cloud deployment, choose Pinecone. If your stack already relies on Redis, RedisSearch is often the most natural option.
Core summary
This article systematically reconstructs the LangChain vector store landscape, with a focus on the working mechanism of InMemoryVectorStore, the similarity search flow, the Chroma persistence path, and the selection trade-offs across mainstream vector databases. It is designed to help developers building RAG and semantic retrieval systems quickly understand the key implementation patterns.